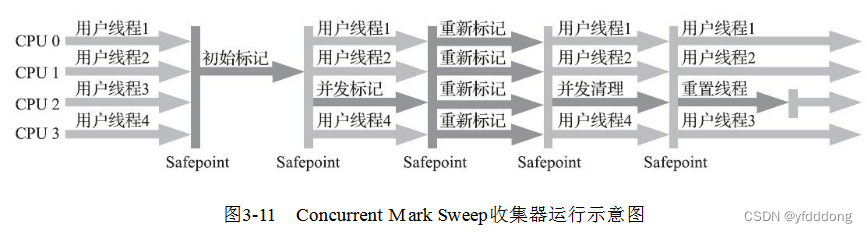
先分别写一下流程
Deformable DETR(2020)的Deformable Attention
解释:
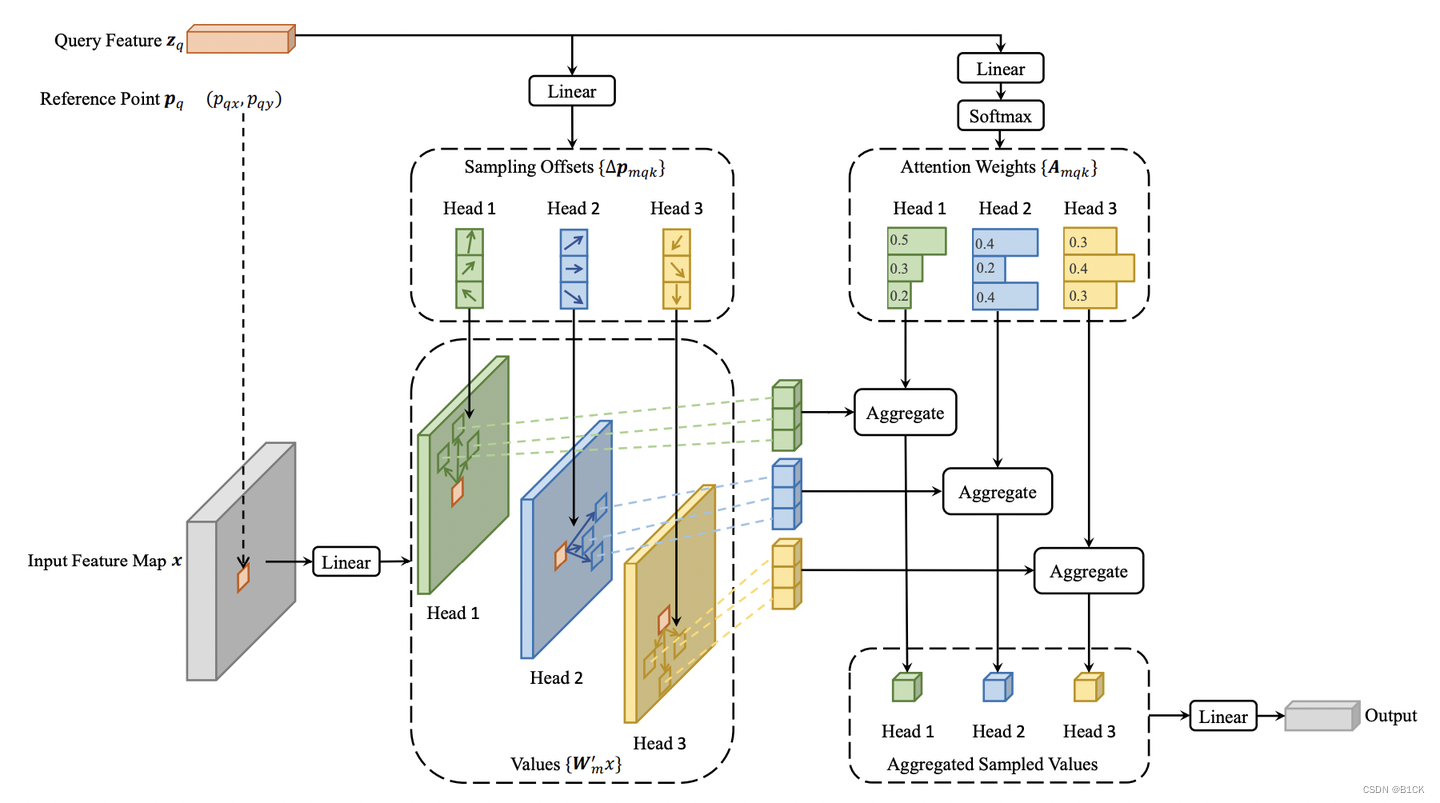
Deformable Attention如下图所示K=3, M=3K是指每个zq会和K个offset算attention,M是指M个head,
z
q
z_q
zq有N=HW个:
参考点:reference points,各个特征层上的点,(0.5,0.5)x 4,(0.5,1.5)x 4,…(H-0.5,W-0.5)x 4 ,再除以H或W进行归一化;
偏移量:offsets,网络自己学习的偏移量;
采样点:reference points + offsets,每个特征点都会学习得到4个采样点,然后只计算这个特征点和这四个采样点的相似度即可,不需要学习和所有特征点的相似度;
reference point确定方法为用了torch.meshgrid方法,调用函数(get_reference_points)。 对于每一层feature map初始化每个参考点中心横纵坐标,加减0.5是确保每个初始点是在每个pixel的中心,例如[0.5,1.5,2.5, …]
在Decoder中,参考点的获取方法为object queries通过一个nn.Linear得到每个对应的reference point。
初始的采样点位置相当于会分布在参考点3x3、5x5、7x7、9x9方形邻域
- Z Z Z :输入特征 ,[HW,C]
- z q z_q zq :query ,N个[1,C]
- p q p_q pq :参考点Reference Point,就是zq在特征图x上的坐标,是2d向量( P q x , P q y Pqx,Pqy Pqx,Pqy)(0和1之间)
- ▲ P m q k ▲Pmqk ▲Pmqk :offsets,由每个 query z q z_q zq经过一个Linear得到,每个head会生成K个offset,一共M个head,即,在每个head中采样K个位置
- W ′ m x W'm_x W′mx :Transformation Matrix,就是过一个Linear
- (query z q z_q zq送进通道数为3MK的Linear,前2MK个通道编码 ▲ P m q k ▲Pmqk ▲Pmqk,剩下的MK过softmax得到对应的 A m q k Amqk Amqk)
- Values : p q p_q pq+ ▲ P m q k ▲Pmqk ▲Pmqk获取在特征图上的值,通常是小数,因此从特征图上索引特征时采用双线性插值的方式,之后乘上 W ′ m x W'm_x W′mx
- A m q k Amqk Amqk :Attention Weights,也一样,直接由query
- z q z_q zq经过linear和softmax得到,也是每个head生成K个Attention weight,和(因此,在DeformableDETR的Deformable Attention里,没有真的key query乘积计算,更像DCN)
DAT(2022)的的Deformable Attention
文章可视化画的是针对最重要的key,我现在见过对attention map,query做可视化的,想怎么解释就怎么解释
流程:
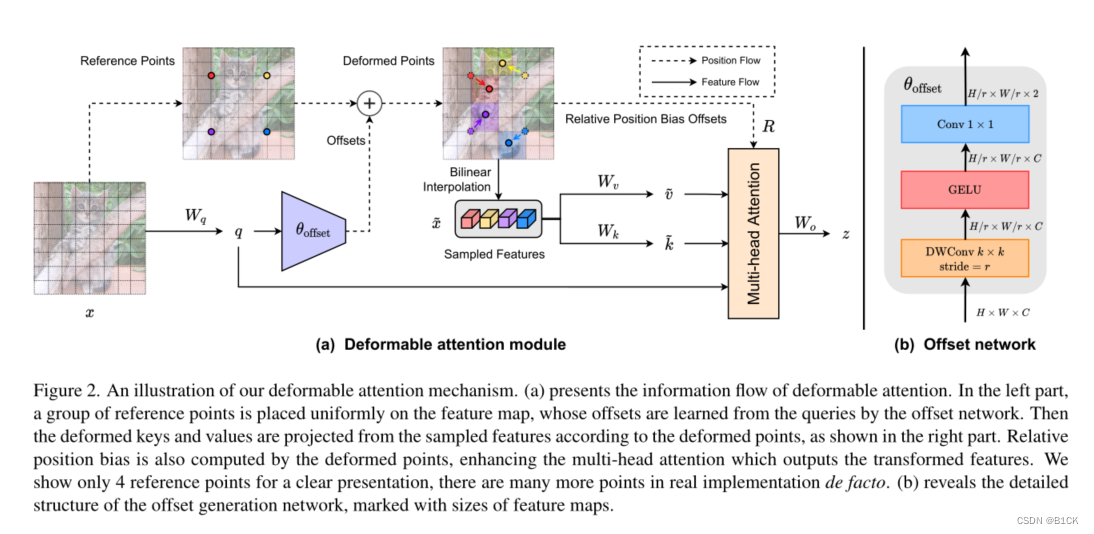
- 特征图 x x x [H,W,C]
- 根据feature map生成参考点reference point,这里不是网格中心而是网格的交接点(整){(0, 0), . . . , (HG − 1, WG − 1)}
- 将reference point norm到(-1,1)之间,坐标(-1,-1)代表左上角,坐标(1,1)代表右下角
- Δ P ΔP ΔP由以query为输入的offset Network得到,并将得到的 Δ P ΔP ΔP与reference points的坐标相加,从而得到偏移后位置信息。 Δ P ΔP ΔP幅度受超参数s控制防止过大。
- 对变形后的reference points使用双线性插值方法进行采样从而得到x:sampled features
- 过两个线性层分别得到v和k
- bias offset:我们计算归一化范围[−1,+1]中的相对位移,然后通过连续相对位移在参数化偏置表ˆB∈R(2H−1)×(2W−1)中插值φ(ˆB;R),以覆盖所有可能的偏移值。
8.多头输出: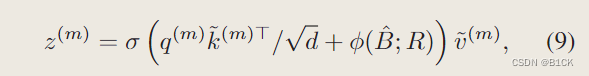
总的来说在小地方进行了修改,offset network这么设计只说了要和transformer保持相同大小的感受野,但至少证明了deformable attention 是通用的。
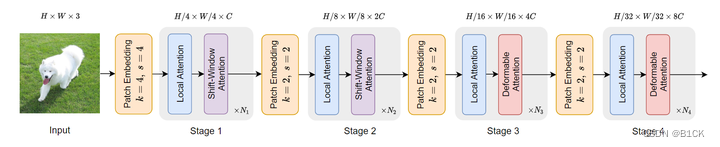
为什么DAT要在stage3 stage4才使用deformable attention?
因为stage1 和 stage2 基本上是在提取局部信息,deformable attention 效果不如swin attention。而且前两个stage中,key和value对太多了,会大大增大因为点积和双线性插值带来的计算复杂度。