📟作者主页:慢热的陕西人
🌴专栏链接:Linux
📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言
本博客主要内容讲解了从磁盘的硬件结构,再到操作系统内部是如何组织文件系统的包括软硬连接的介绍!
文章目录
- 1.磁盘的结构
- 2.CHS定位法
- 3.逻辑抽象
- 4.文件系统
- 4.1从硬件向软件过度
- 4.2软硬件链接
- 4.3软硬连接:
- 4.3.1制作软硬链接,对比差别:
- ①硬连接:
- ②软连接
我们目前所了解到的,都是被打开的文件!如果文件没有被打开呢??在哪里?
一定不是在内存中!只能在磁盘等外设中静静的存储着!
磁盘文件,如果没有被打开,如何理解这些文件呢? 没有被打开的文件,有什么问题?
1.如何合理存储的问题
2.主要是为了解决:快速定位,快速读取和写入—磁盘文件也是如此!!
pre:标识一个文件:文件名(目前)
a.如何定位一个文件
b.如果对文件进行读取和写入
所以我们来了解以下磁盘的结构:
1.磁盘的结构
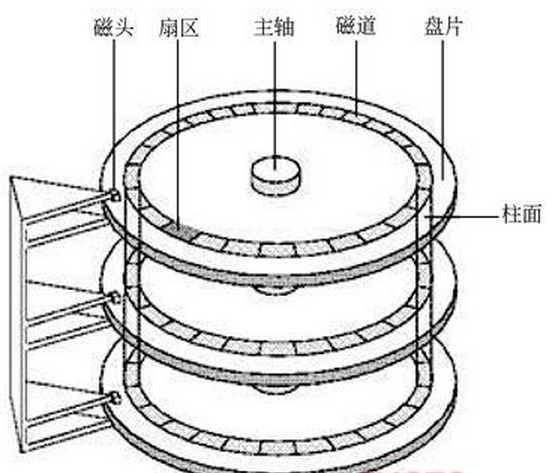
磁盘是我们计算机上唯一的一个机械设备!同时它还是外设(作为外设来说他们的速度都是相对CPU和内存来说比较慢的)。
一个剖面图:
磁盘中的存储的基本单元:扇区,512字节or4kb字节
一般的磁盘所有的扇区都是512字节。
磁道:同半径的所有扇区;
柱面:所有盘片上的对应相同半径的磁道共同部分被称为柱面

那么磁盘是如何寻找磁盘上的文件的?
2.CHS定位法
C:cylinder柱面(磁道)
H:head 磁头
S:sector扇区
①首先我们要定位在哪一个面:
只需要确定用哪一个磁头读取,盘片的编号,来确定在哪一个面。
②确定在盘片的哪一个扇区:
a.先定位在哪一个磁道—由半径决定
b.在确定在该磁道,在哪一个扇区—根据扇区的编号,定位一个扇区
一个普通的文件(属性+数据)->都是数据(0,1)->无非就是占用一个或者多个扇区,来进行自己的数据存储的!!!
我们既然能够用CHS来定位任意一个扇区,我们就可以定位多个扇区,从而将文件从硬件的角度,进行读取或者写入!!!
3.逻辑抽象
①根据我们之前的了解,如果OS能够知道任意一个CHS地址,就能访问任意一个扇区。
②那么OS内部是不是直接使用的CHS地址呢?答案是不是的。
③为什么?
a. OS是软件,磁盘是硬件,硬件定位一个地址,CHS,但是如果OS直接用了这个地址,万一硬件变了呢?OS也要发生变化,OS要和硬件做好解耦工作:也就是说硬盘内部有一套自己的定位系统,和操作系统内部是不一样的,但是两者是可以相互转换的。
b.即便是扇区,512字节,单位IO的基本数据量也是很小的!硬件:512字节,OS实际进行IO,基本单位是4kB(可以调整的) — 磁盘:是一种块设备。所以,OS需要有一套新的地址,进行块级别的访问。
接下来我们从硬件层面上深入的理解磁盘是和操作系统如何协作的:
我们把磁道展开,展开的磁道就是一个一个的小扇区:这些小扇区好像一个一个的数组,非常适合操作系统去做管理:
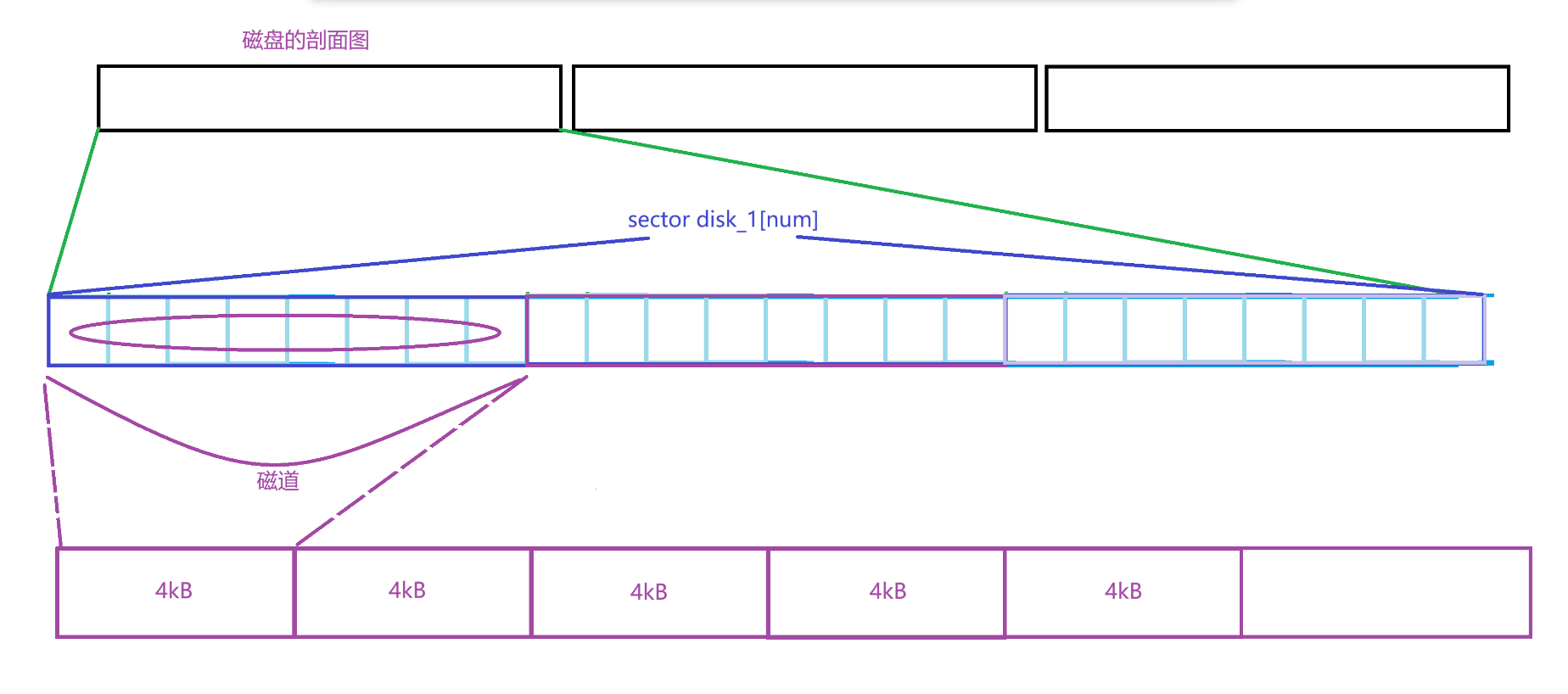
初步完成了一个从物理逻辑到系统逻辑的过程!数组不是天然有下标!此时,定位一个扇区,只需要一个数组下标是不是就可以定位一个扇区了。而其中我们的OS是以4kB为单位进行IO的,故一个OS级别的文件块要包括8个扇区!甚至,在OS的角度,其实它是不关心扇区的!
计算机常规的访问方式:起始地址+偏移量的方式(语言+数据类型) 只需要知道数据块的起始地址(第一个扇区的下标地址) + 4KB(块的类型)我们把数据块看作一种类型!
所以块的地址,本质就是数组一个下标,N,以后我们表示一个块,我们可以采用线性下标的N的方式,定位一个任何一个块了。
OS -> N -> LBA -> 逻辑块地址!
可是我们的磁盘只认识CHS地址!
所以我们的LBA <--------->CHS是可以相互转化的—>简单的数学运算就可以做到:
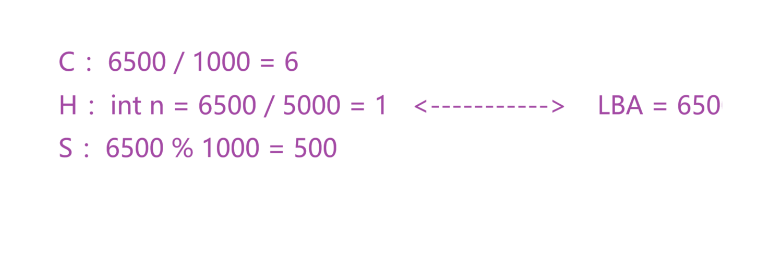
OS要管理磁盘,就将磁盘看做一个大数组,对磁盘的管理,变成了对数组的管理!!我们的先描述,在组织:
//硬盘
struct block
{
//...
}
//区
struct part
{
int lba_start;
int lba_end;
//组
struct part group [100];
}
4.文件系统
4.1从硬件向软件过度
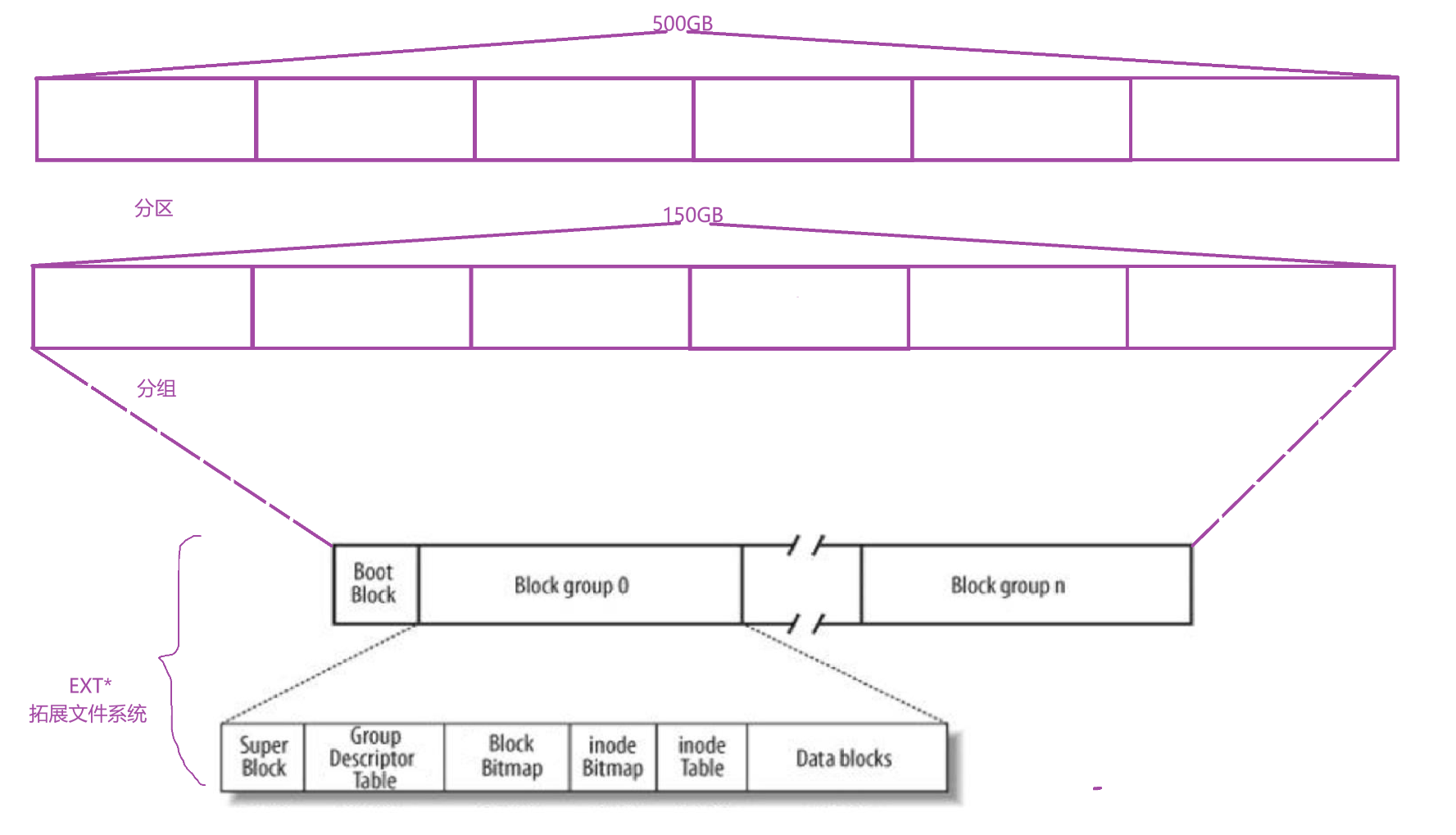
前面我们提到了块的概念,对于磁盘系统来说整个磁盘太大了,那么将磁盘先分组—>分区,到最后最小的部分(这里说的是管理的,物理结构最小的是扇区)就是块。
struct disk
{
struct part[4];
//....
}
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的 。
接下来我们介绍这些参数:
superBlock:存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,
未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。广义来说:文件系统的所有的信息:1.文件系统的类型;2.整个分组的情况;
并且SB在各个分组里面可能都会存在,而且是统一更新的,而是为了防止SB域坏掉,如果出现故障,整个分区不可以被使用!所以我们要时常做好备份。
GDT,Group Descriptor Table:组描述符—该组内的详细统计等详细信息。
块位图(Block Bitmap): Block Bitmap中记录着Data block中那个数据块已经被占用了,那个数据块没有被占用。
inode位图(inode Bitmap):每个bit位表示一个innode是否空闲可用。
i节点表(inode Table):存放文件属性。如:文件大小,所有者,最近修改时间等。
数据区(data Blocks):存放文件内容。
block bitmap: 每一个bit表示datablock是否空闲可用!
一般来说:
①一个文件,内部所有属性的集合—>inode节点(128字节),一个文件,一个inode
②其中,即便是一个分区,内部也会存在大量的文件即会存在大量的inode节点,一个group,需要有一个区域,来专门保存该group内的所有文件的inode节点—>inode Table , innode表。
③分组内部,可能会存在多个inode,需要将inode区分开来,每一个inode都会有自己的inode编号!!
④inode编号,也属于对应文件的属性id;
⑤而文件的内容:是变化的,我们是用数据块来进行文件内容的保存的,所以一个有效文件,要保存内容,就需要[1, n]数据块,如果有多个文件呢?需要更多的数据块,Data Blocks。
⑥Linux查找一个文件,是要根据inode编号,来进行文件查找的,包括读取内容!!
⑦一个inode对应一个文件,而改文件inode属性和改文件对应的数据块,是有映射关系的!
⑧在Linux内部是将内容和属性分离的,都要以块的形式,被保存在磁盘的某个位置!
4.2软硬件链接
①inodevs文件名:
Linux系统只认inode号,文件的inode属性中,并不存在文件名!文件名,是给用户用的。
②重新认识目录:
目录是文件么?是的,目录有inode吗?是。
有内容吗?有内容是什么?
③任何一个文件,一定在一个目录内部,所以目录的内容是什么呢?需要数据块,目录的数据块里面保存的是该目录下文件名和文件inode编号对应的映射关系,而且,在目录内部,文件名和inode互为key值。
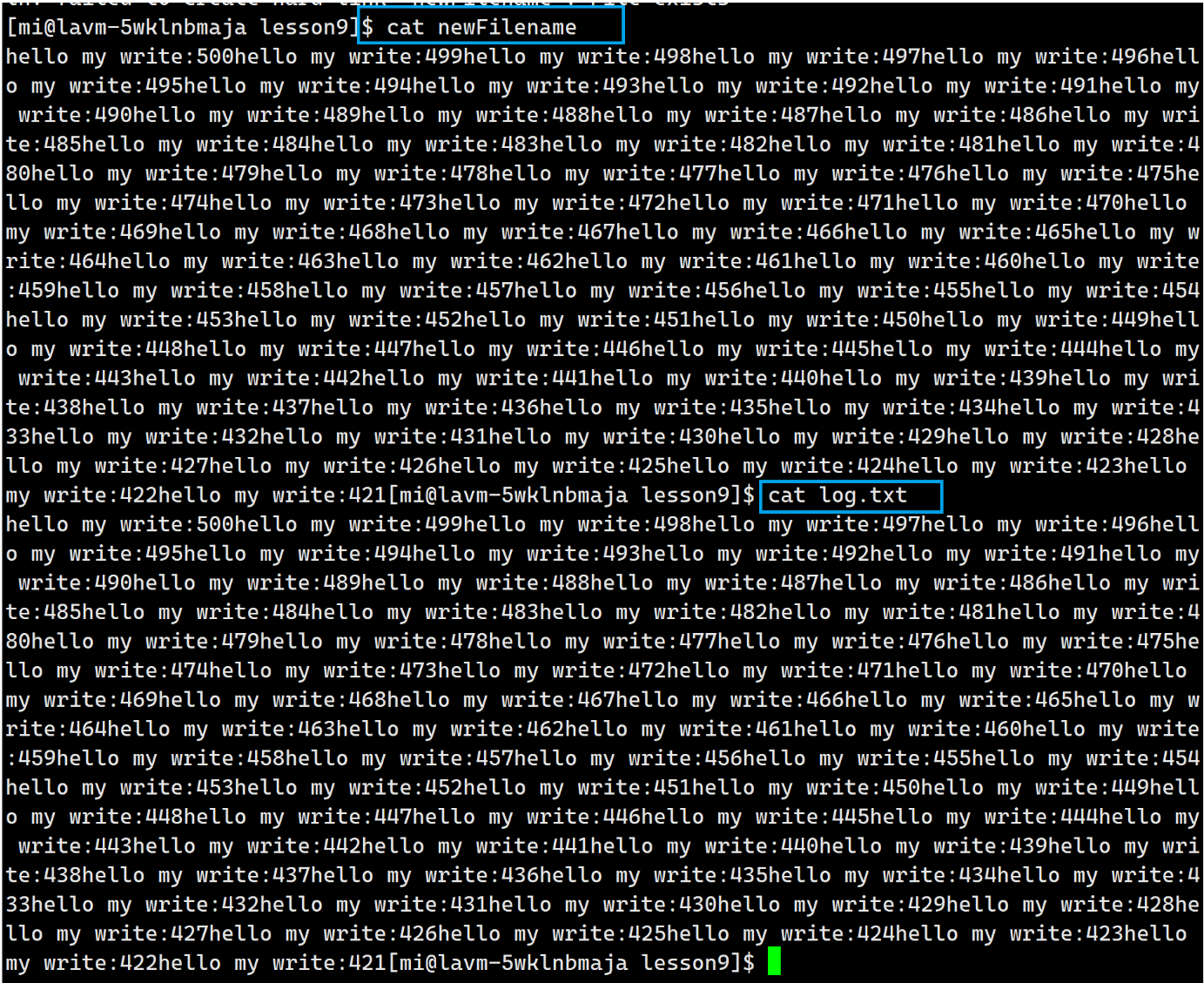
④当我们访问一个文件的时候,我们是在特定目录下访问的,cat log.txt
a.先要在当前目录下,找到log.txt的inode编号
b.一个目录也是一个文件,也一定隶属于一个分区,结合inode,在该分区中找到分组,在该分组中inode table中,找到文件的inode
c.通过inode和对应的datablock的映射关系,找到该文件的数据块,并加载到OS,并完成显示到显示器
⑤如何理解文件的增删查改:
a.根据文件名—> inode number
b.inode number —>inode 属性中的映射关系,设置block bitmap 对应的比特位,置0即可。
c.inode number 设置inode bitmap 对应的比特位设置为0
所以总结一下,删文件,只需要修改位图即可!
所以这就是为什么有那些文件恢复软件的存在!
⑥细节补充:
a.如果文件被误删了,我们该怎么办?
我们只需要通过文件日志查看误删的文件的inode然后找到对应的inode bitmap将其置1(非常简单的说法,实际的操作非常复杂);
b. inode,确定分组,inode number是在一个分区内唯一有效的,不能跨分区
c. 上面我们学到的分区,分组,填写系统属性 —> 谁做的呢? OS做的。什么时候做的呢?分区完成后,后面要让分区能够被正常使用,我们需要对分区做格式化,格式化的过程,其实就是OS向分区写入文件系统的管理属性信息。
d.我们如果inode只是单单的用数组建立和datablock的映射关系,15 * 4kB = 60KB 那么是不是意味着一个文件内容最多放入:60KB不是的,原因是我们存在直接索引,也存在二级索引(所指向的数据块里面的内容,不是直接的数据,而是其他数据块的编号),和三级索引(相当于两层的多叉树)。
struct inode { int inode number; int ref_count; mode_t mode; int uid; int gid; int size; data; ... int datablock[NUM]; }
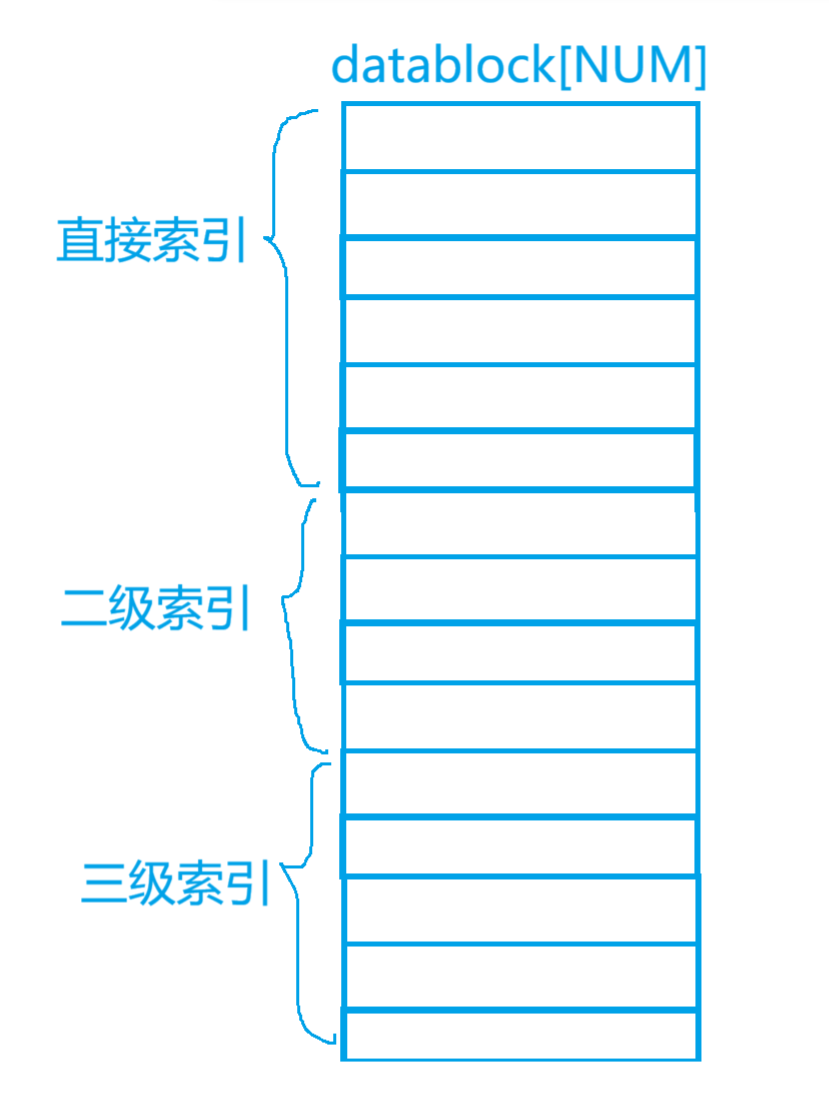
⑦有没有可能,一个分组,数据块没用完,inode没了,或者inode没用完,datablock用完了?
这种情况是存在的就是一个分组中全是空文件的时候,存在inode没了但是datablock还有冗余的情况,但是在操作系统内部很少出现这种情况。
4.3软硬连接:
我们有了以上之前的认识,那么我们认识软硬链接,就是顺水推舟的事情。
4.3.1制作软硬链接,对比差别:
①硬连接:
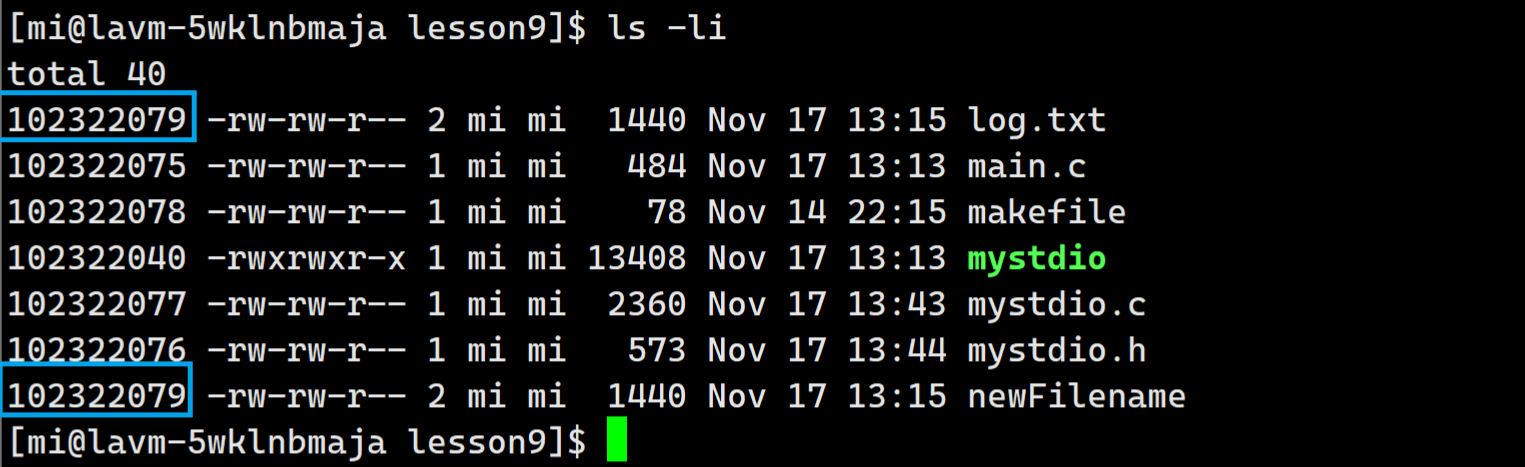
我们用
ls -li命令查看:可以发现两个文件的inode是相同的,那么实际上的意思就是两个文件在硬件上是同一个文件:
不信的话我们cat一下查看一下内容是否相同:
硬链接和目标文件公用同一个inode number,意味着,硬链接一定是和目标文件使用同一个inode的!
硬链接没有独立的inode。
那么硬链接干了什么?建立了新的文件名和老的inode的映射关系!之前我们提到一个inode的结构体:内部有一个参数叫ref_count,这个参数就代表的是引用次数!所以当我们每次建立一个硬链接的时候,对应的ref_count就自加1;所以本质是一种引用计数,代表的是有多少个文件名指向我,也就是硬链接数。
struct inode { int inode number; int ref_count; mode_t mode; int uid; int gid; int size; data; ... int datablock[NUM]; }
②软连接
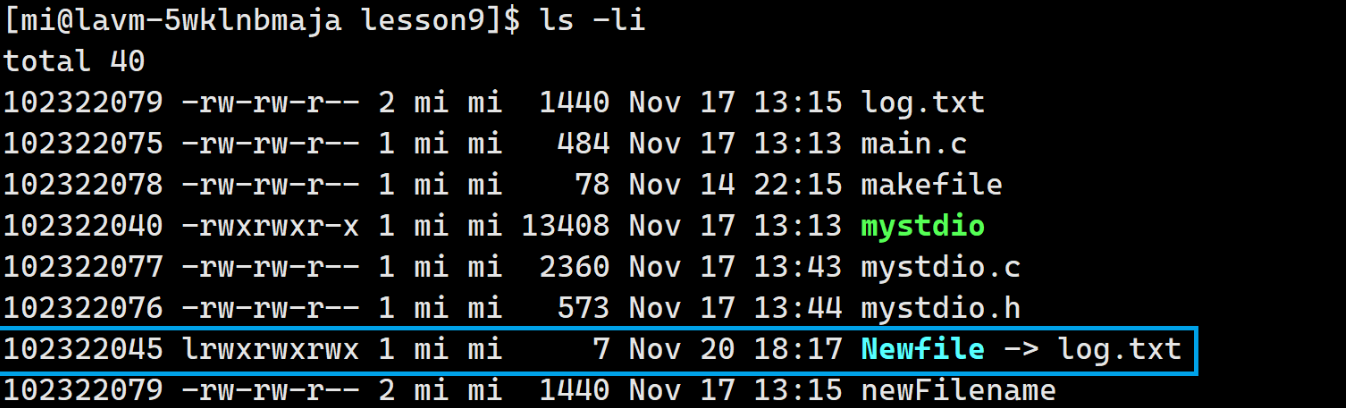
使用
ln -s log.txt Newfile创建一个软链接我们发现inode是不相同,软链接内部放的是自己所指向的文件的路径类似于windows中的快捷方式
到这本篇博客的内容就到此结束了。
如果觉得本篇博客内容对你有所帮助的话,可以点赞,收藏,顺便关注一下!
如果文章内容有错误,欢迎在评论区指正