因为adult数据集没有列名,先设置列名
df = pd.read_csv('adult.csv', header = None, names =
['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race',
'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income'])查看是否有缺失值,结果是没有
print(df.tail())
for col in df. columns:
if type(df[col][0]) is str:
print ("unknown value count in "+ col +" is "+ str(df[df[col]=='unknown']['income'].count()))现在观察每列有几种可能,方便进行哑编码或者独热编码。adult数据集一共有以下14个数据特征,其中数字类型的特征不需要进行处理。
图片出自http://t.csdnimg.cn/uIe5s

因为人口普查员序号和预测任务没有关系,所以删掉fnlwgt列。又因为75%以上的人是没有资本收益和资本输出的,所以capital-gain和capital-loss也不需要。所以,删掉这三列。
df.drop('fnlwgt', axis = 1, inplace = True)
df.drop('capital-gain', axis = 1, inplace = True)
df.drop('capital-loss', axis = 1, inplace = True)age、education-num、hours-per-week这三列都是数值,不需要更改。
对缺失值进行众数填充,以及把二分类问题转换成0和1
df.replace(" ?", pd.NaT, inplace = True)
df.replace(" >50K", 1, inplace = True)
df.replace(" <=50K", 0, inplace = True)
df.replace(" Male", 1, inplace = True)
df.replace(" Female", 0, inplace = True)
trans = {'workclass' : df['workclass'].mode()[0], 'occupation' : df['occupation'].mode()[0], 'native-country' : df['native-country'].mode()[0]}
df.fillna(trans, inplace = True)接下来查看字符型的特别有几种可能。
首先是workclass列
counts = df['workclass'].value_counts()
print(counts)有8种可能

education有16种可能
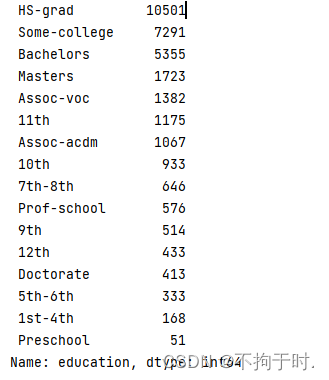
婚姻状况有7种可能

职业有种可能14种可能

社会角色有6种可能
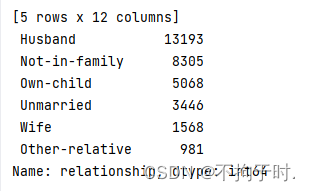
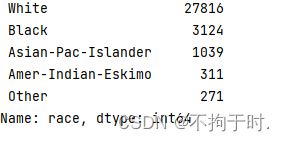
种族有5种可能
性别显然有两种可能
国籍有41种可能(太多了不截图了)
所以'workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'native-country'这7列数据需要进行独热编码
可以看到进行独热编码后一共有103列,32561.
正常adult数据集一共有14个数据特征,其中删除三列,另有7个特征需要进行独热编码,这7个特征一共会产生97个列。
所以最终列数应该是14-3+97-7=101,但是实际有103列是包含了序号列和收入列。

所有预处理编码如下所示
import pandas as pd
import random
df = pd.read_csv('adult.csv', header = None, names =
['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race',
'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income'])
print(df.tail())
for col in df. columns:
if type(df[col][0]) is str:
print ("unknown value count in "+ col +" is "+ str(df[df[col]=='unknown']['income'].count()))
df.replace(" ?", pd.NaT, inplace = True)
df.replace(" >50K", 1, inplace = True)
df.replace(" <=50K", 0, inplace = True)
df.replace(" Male", 1, inplace = True)
df.replace(" Female", 0, inplace = True)
trans = {'workclass' : df['workclass'].mode()[0], 'occupation' : df['occupation'].mode()[0], 'native-country' : df['native-country'].mode()[0]}
df.fillna(trans, inplace = True)
print(df.describe())
df.drop('fnlwgt', axis = 1, inplace = True)
df.drop('capital-gain', axis = 1, inplace = True)
df.drop('capital-loss', axis = 1, inplace = True)
print(df.head())
# 对指定列进行独热编码
encoded_cols = pd.get_dummies(df[['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'native-country']])
# 将独热编码后的列与原始数据进行合并
df = pd.concat([df, encoded_cols], axis=1)
# 删除原始的 'job', 'contact', 'marital' 列
df = df.drop(['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'native-country'], axis=1)
# counts = df['native-country'].value_counts()
# print(counts)
# 将 'y' 列移动到最后一列
y_column = df.pop('income') # 移除 'y' 列并返回该列
df['income'] = y_column # 将 'y' 列添加到 DataFrame 的最后一列
df.to_csv('processed_data.csv', index=True)参考文章:
【精选】Adult数据集分析(一)_云隐雾匿的博客-CSDN博客
Adult数据集分析及四种模型实现-CSDN博客