Neo4j的全文索引是基于Lucene实现的,但是Lucene默认情况下只提供了基于英文的分词器,下篇文章我们在讨论中文分词器(IK)的引用,本篇默认基于英文分词来做。我们前边文章就举例说明过,比如我要搜索苹果公司?首先我们要做的第一步在各个词条上创建全文索引,第二步我们根据苹果公司进行全文检索,把匹配度高的按顺序输出。下边我们一步步讲解怎么做。
# Neo4j的全文索引采用Lucene,能够对neo4j中string类型的属性建立全文索引。
- 1. 能够同时为node和relationship的属性建立索引。而neo4j内嵌的索引仅能够对node的属性建立索引。
- 2. 至于字符串如何被切分和索引,取决于为lucene配置的analyzer。支持自定义Analyzer,包括lucene中没有提供的。
- 3. 能够用lucene查询语句进行查询;
- 4. 能够返回相似度score;
- 5. 能够随着节点和关系的添加、移除、修改进行自动的更新;
- 6. 自动检查一致性,如果有不一致的问题自动重建;
- 7. 在单个索引中,能够支持任意数目的文档;
- 8. 创建、删除、更新都是事务的,能够在集群中自动进行副本;
- 9. 能够通过cypher语句访问.
- 10. 能够配置为满足最终一致性。即,索引更新在提交路径中被移除,转为后台线程。利用此特性,对于性能要求高的场景,能够消除主要的写瓶颈。
# 相比于Neo4j内嵌的索引,采用Lucene索引具有如下优势:
- 1. neo4j的内嵌索引采用b树,其仅能够对STARTS WITH、ENDS WITH、完全相等三种条件起作用。而lucene建立的全文索引能够对任意片段的字符串进行查询。
- 2. lucene索引能够对多个label建立.
- 3. lucene索引能够对一到多个关系建立.
- 4. 能够同时应用于多个属性。与内嵌索引的Composite Index不同。Composite Index仅对满足label且同时具有所有属性的实体起作用,而全文索引则对至少满足一个label、关系类型、属性的节点或关系起作用.
1. call和yield的用法
首先看看这两个词的用方法。CALL语句用于调用数据库中的过程(Procedure),YIELD子句用于显示的选择返回结果集中的哪些部分并绑定到一个变量以供后续查询引用。简单说就是用call来调用函数,用yield来接收函数返回的结果。我们举个例子
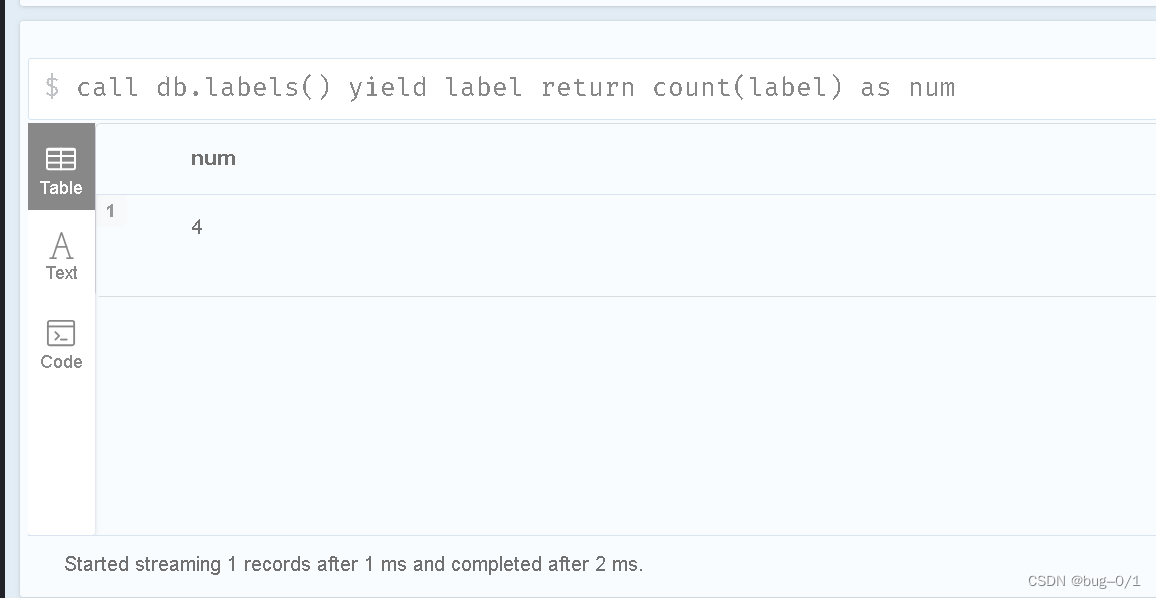
call db.labels() yield label
return count(label) as num
这里是调用数据库中内嵌的过程db.labels()计算数据库中的总标签数。返回结果
2. 索引
在Neo4j中,有两种不同的索引类型:B-树和全文索引
可以使用Cypher创建和删除B-树索引。用户通常不必知道索引就可以使用它,因为Cypher的查询计划器会决定在哪种情况下使用哪个索引。B-树索引擅长于对所有类型的值进行精确查找,以及范围扫描,完整扫描和前缀搜索。比如(=,>,start with,contains)等
全文索引与B-树索引不同,它们针对索引和搜索文本进行了优化。它们用于需要理解语言的查询,并且仅索引字符串数据。还必须通过过程明确查询它们。全文索引需要手动去创建它,查询的时候也是手动去调用。
在理解了索引的两种概念后,我们着手看看全文索引怎么创建。
3. 创建全文索引
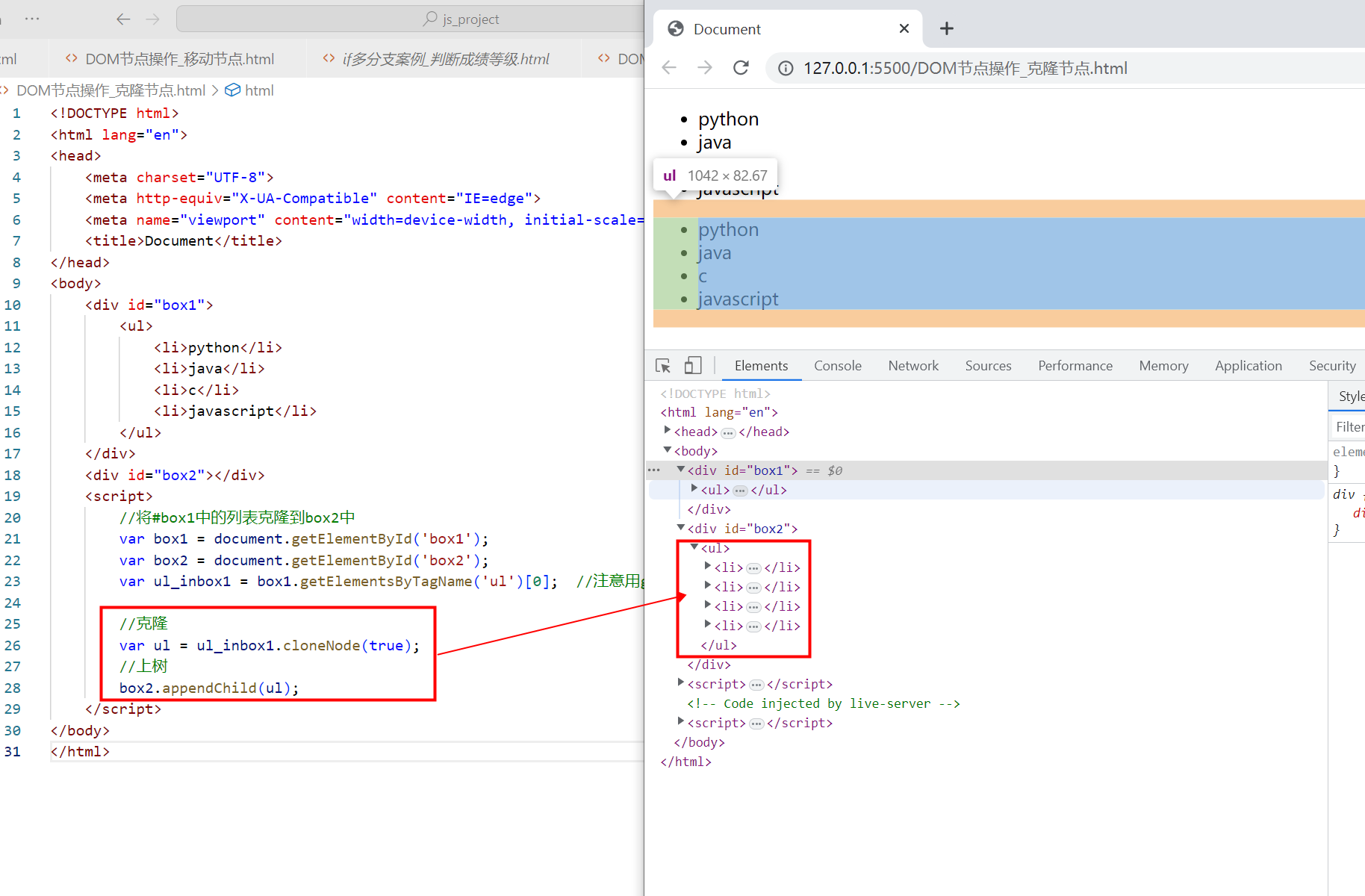
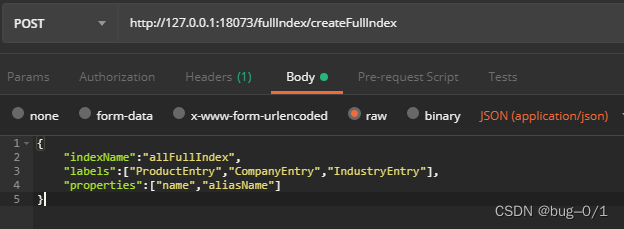
在第一节中用到了db.labels()的过程,那有没有内置创建全文索引的过程呢。答案当然是有了。会发现有db.index.fulltext.createNodeIndex(),那就用这个过程来开始创建一个全文索引。在Dao层代码如下,其中创建索引的名称,标签和字段通过动态传参传过去的,比如在公司,产品上创建公司名称,产品名称的全文索引名称为allFullIndex
可以手动从CQL查询界面进行创建
比如从GoodDes标签的name上创建全文索引, 并使用cjk分词器
CALL db.index.fulltext.createNodeIndex("FT_GOODDES",["GoodDes"],["name"],{analyzer:"cjk", eventually_consistent:"true"}) CALL db.index.fulltext.queryNodes("FT_GOODDES", "气体导流管(旧)") YIELD node, score WHERE score > 0.6 MATCH (node)-[:GoodAndCode]->(goodCode:GoodCode) RETURN ID(node) AS nodeId, node.name AS goodDesName, score, ID(goodCode) AS goodCodeId, goodCode.code AS goodCodeCode;
@Repository
public interface FullIndexRepository extends Neo4jRepository<CompanyEntryNode, String> {
/**
* 创建索引
*
* @param indexName 索引名称
* @param labels 标签名称
* @param properties 属性
*/
@Query("call db.index.fulltext.createNodeIndex({indexName},{labels},{properties})")
void createFullIndex(String indexName, String[] labels, String[] properties);
/**
* 删除索引
*
* @param indexName 索引名称
*/
@Query("call db.index.fulltext.drop({indexName})")
void deleteFullIndexByName(String indexName);
}
service层和controller层就不写了,直接调用我们创建的过程,就成功创建了一个名称为allFullIndex的全文索引。
4. 查询索引
同样的有创建索引的过程,也有查询全文索引的过程db.index.fulltext.queryNodes(),那我们在dao层做如下定义。这里结果中返回了node和score。score就是按照相似度给出的一个分值,分词器会影响这个分值,node就是创建索引的节点信息。结果默认是按照score数值从高到低返回。
@Repository
public interface BaseSearchRepository extends Neo4jRepository<CompanyEntryNode, String> {
/**
* 查询全文检索数据
*
* @param searchWord
* @return
*/
@Query("call db.index.fulltext.queryNodes('allFullIndex',{searchWord}) yield node,score " +
"return node.name as name,score")
List<BaseSearchDto> fullTextSearch( String searchWord);
}
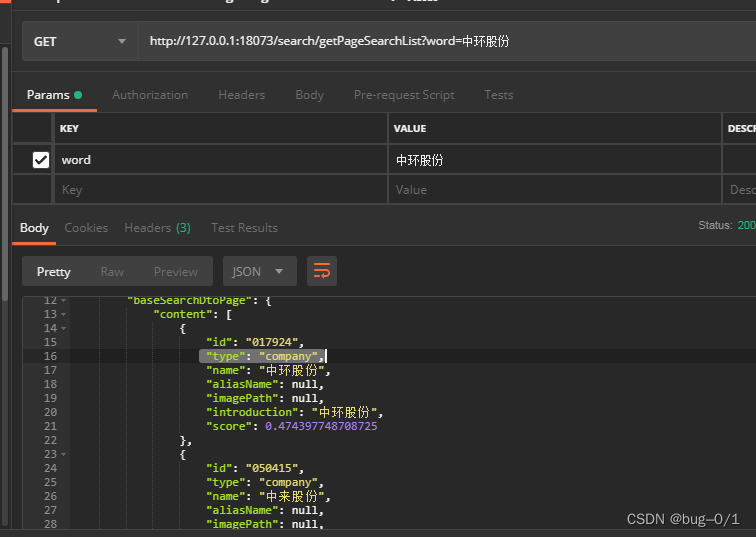
在controller层中我们调用会返回如下结果
这样整个全文索引的创建和查询就完成了。
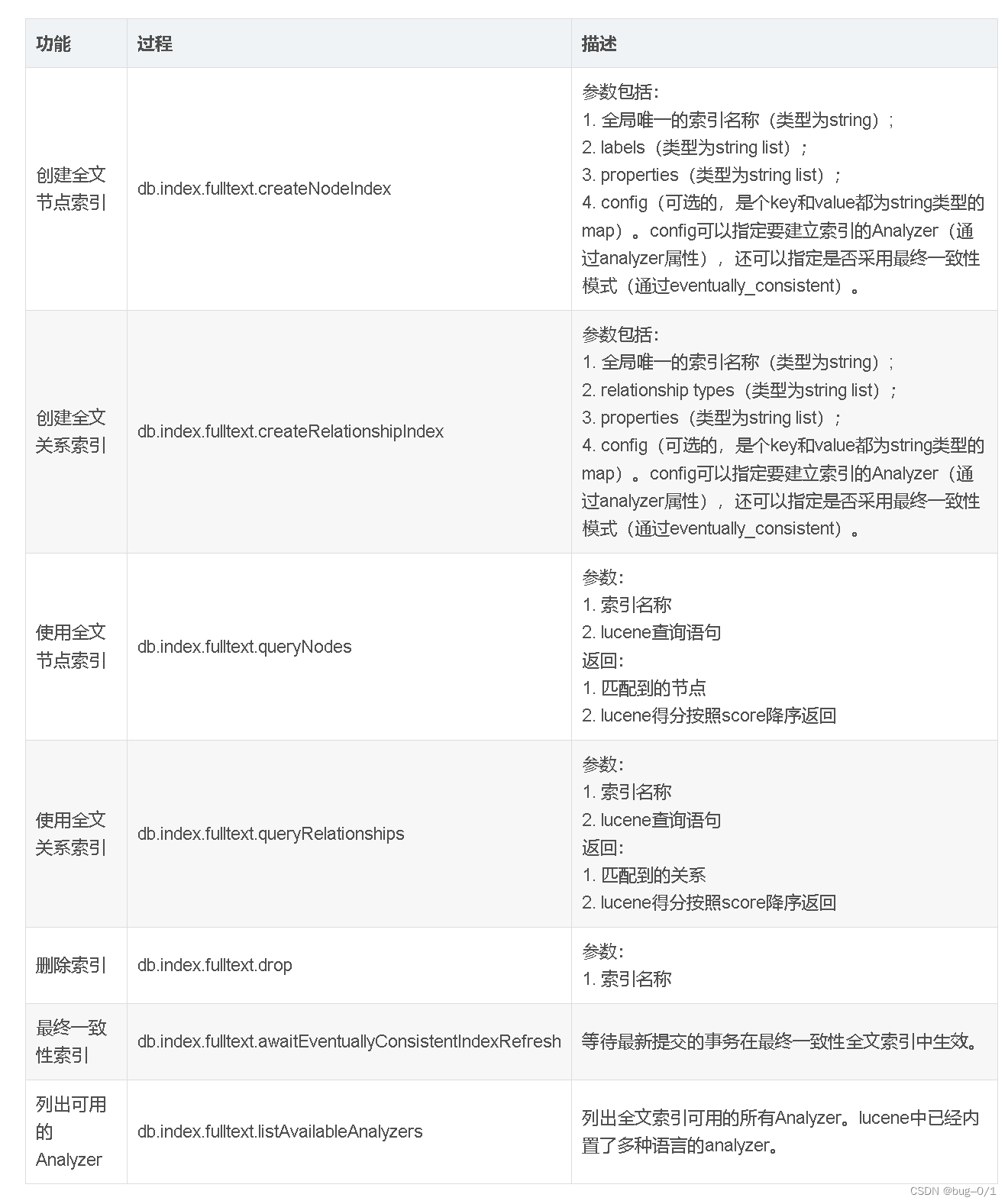
5. 其他调用过程 [一]
db.index.fulltext.drop()
| 描述 | 删除指定的索引。 |
|---|---|
| 用法 | db.index.fulltext.drop(indexName :: STRING?) :: VOID |
db.index.fulltext.createNodeIndex()
| 描述 | 为给定的标签和属性创建节点全文索引。可选的“ config”映射参数可用于为索引提供设置。支持的设置是“分析器”,用于指定在建立索引和查询时要使用的分析器。使用以下db.index.fulltext.listAvailableAnalyzers步骤查看可用的选项。可以将’eventually_consistent’设置为’true’,以使该索引最终保持一致,从而将来自提交事务的更新应用于后台线程。 |
|---|---|
| 语法 | db.index.fulltext.createNodeIndex(indexName :: STRING?, labels :: LIST? OF STRING?, properties :: LIST? OF STRING?, config = {} :: MAP?) :: VOID |
db.index.fulltext.createRelationshipIndex()
| 描述 | 查询给定的全文索引。返回匹配关系及其Lucene查询分数,按分数排序。选项映射的有效键是:'skip’跳过前N个结果;'limit’限制返回的结果数。 |
|---|---|
| 用法 | `db.index.fulltext.queryRelationships(indexName :: STRING?, queryString :: STRING?, options = {} :: MAP?) :: (relationship :: RELATIONSHIP?, score :: FLOAT?)``` |
db.index.fulltext.queryRelationships()
| 描述 | 为给定的关系类型和属性创建一个关系全文本索引。可选的“ config”映射参数可用于为索引提供设置。支持的设置是“分析器”,用于指定在建立索引和查询时要使用的分析器。使用以下db.index.fulltext.listAvailableAnalyzers步骤查看可用的选项。可以将’eventually_consistent’设置为’true’,以使该索引最终保持一致,从而将来自提交事务的更新应用于后台线程。 |
|---|---|
| 用法 | db.index.fulltext.createRelationshipIndex(indexName :: STRING?, relationshipTypes :: LIST? OF STRING?, properties :: LIST? OF STRING?, config = {} :: MAP?) :: VOID |
db.index.fulltext.queryNodes()
| 描述 | 查询给定的全文索引。返回匹配的节点及其Lucene查询分数,按分数排序。选项映射的有效键是:'skip’跳过前N个结果;'limit’限制返回的结果数。 |
|---|---|
| 用法 | db.index.fulltext.queryNodes(indexName :: STRING?, queryString :: STRING?, options = {} :: MAP?) :: (node :: NODE?, score :: FLOAT?) |
db.index.fulltext.listAvailableAnalyzers()
| 描述 | 列出可以配置全文本索引的可用分析器。 |
|---|---|
| 用法 | db.index.fulltext.listAvailableAnalyzers() :: (analyzer :: STRING?, description :: STRING?, stopwords :: LIST? OF STRING?) |
6. 其他调用过程 [二]
https://blog.csdn.net/xiaqingyin/article/details/105567306
7. 举例 - 创建和配置、查询、删除全文索引
使用全文索引进行创建
例如,想要对于Label为Movie和Book的节点创建索引,索引的字段包括title和description。则采用如下cypher语句。
CALL db.index.fulltext.createNodeIndex("titlesAndDescriptions",["Movie", "Book"],["title", "description"])
想要使用以上索引搜索标题或者描述中包含“matrix”的节点,调用如下cypher语句。
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "matrix") YIELD node, score
RETURN node.title, node.description, score
创建关系索引,以及可选参数config的使用。
CALL db.index.fulltext.createRelationshipIndex("taggedByRelationshipIndex",["TAGGED_AS"],["taggedByUser"], { analyzer: "url_or_email", eventually_consistent: "true" })
使用全文索引进行查询
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "Full Metal Jacket") YIELD node, score
RETURN node.title, score
可以用Lucene的全文检索语法,例如,如果需要完全匹配,则加双引号
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "\"Full Metal Jacket\"") YIELD node, score
RETURN node.title, score
可以使用逻辑操作符,例如AND OR
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", 'full AND metal') YIELD node, score
RETURN node.title, score
还可以对指定的属性进行查询。
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", 'description:"surreal adventure"') YIELD node, score
RETURN node.title, node.description, score
删除全文索引
CALL db.index.fulltext.drop("taggedByRelationshipIndex")
8. 全文检索之中文分词器
其实用了这么久,我感觉用不用中文的全文索引影响不是很大
说说二种方式实现中文全文索引的创建。
1). 利用系统自带的分词器
我们在创建全文索引函数的时候是可以指定索引的分词器的,他的分词器可用下边的方式查询:
call db.index.fulltext.listAvailableAnalyzers
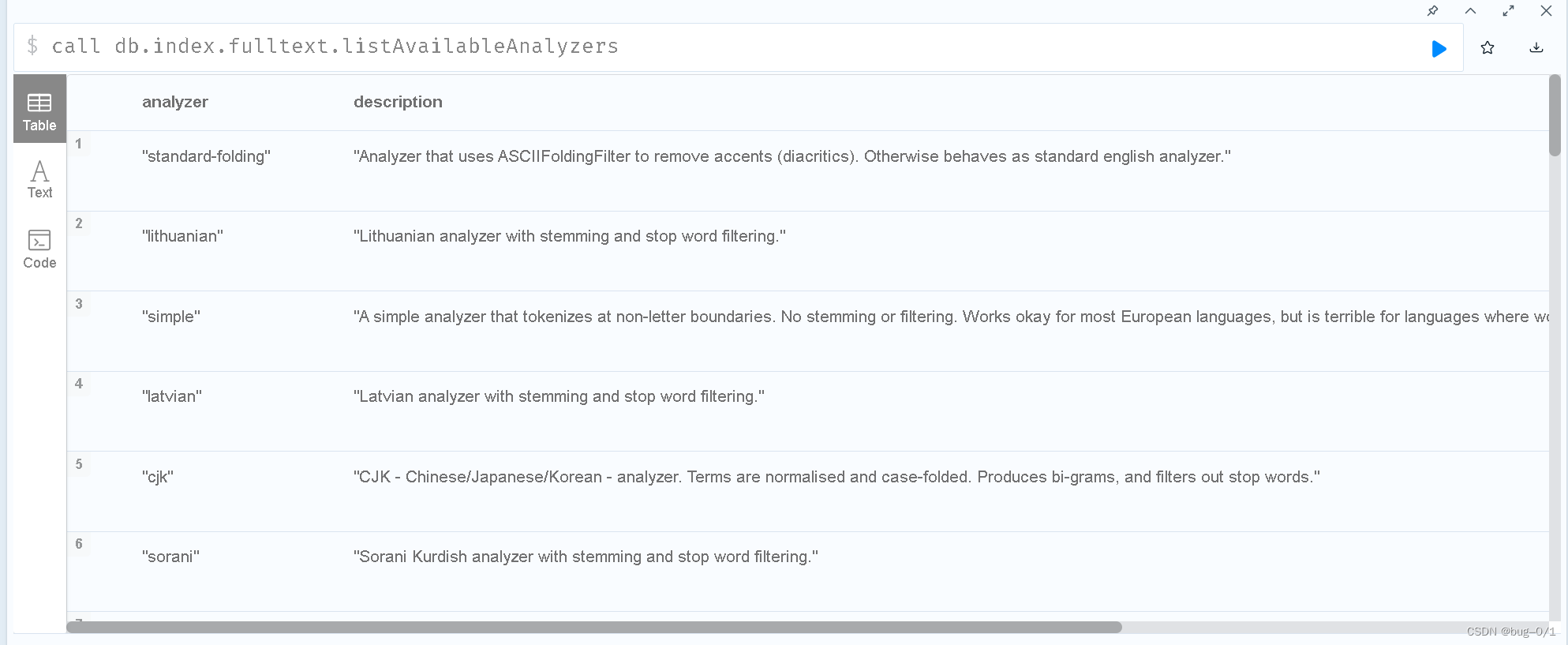
查到很多系统自带的分词器,其中有一个是“cjk”是针对中国,日本,韩国做的分词器,所以说是支持中文分词的。所以可以这样建索引,像下边指定analyzer的类型为“cjk”就指定的分词器的类型。
CALL db.index.fulltext.createNodeIndex("companyFullIndex",["CompanyEntry"],["name"], { analyzer: "cjk"}
2). 通过第三方库来创建全文索引
参考https://zhuanlan.zhihu.com/p/364927850
未验证
通过查找有第三方库neo4j-graph-plugin-1.0.1.jar,这个不确定是不是官方的还是别人提供的,git下载地址:
https://github.com/crazyyanchao/ongdb-lab-apoc
下载neo4j-graph-plugin-1.0.1.jar文件,放到neo4j的plugins目录下,该插件对应的ik版本为:IKAnalyzer-5.0,支持LUCENE-5.5.0。修改配置文件,然后重启neo4j服务。
dbms.security.procedures.unrestricted=apoc.*,zdr.*
安装好后执行,如果不报错,表示安装成功。初次会失败!
RETURN zdr.apoc.hello("你好") as greeting
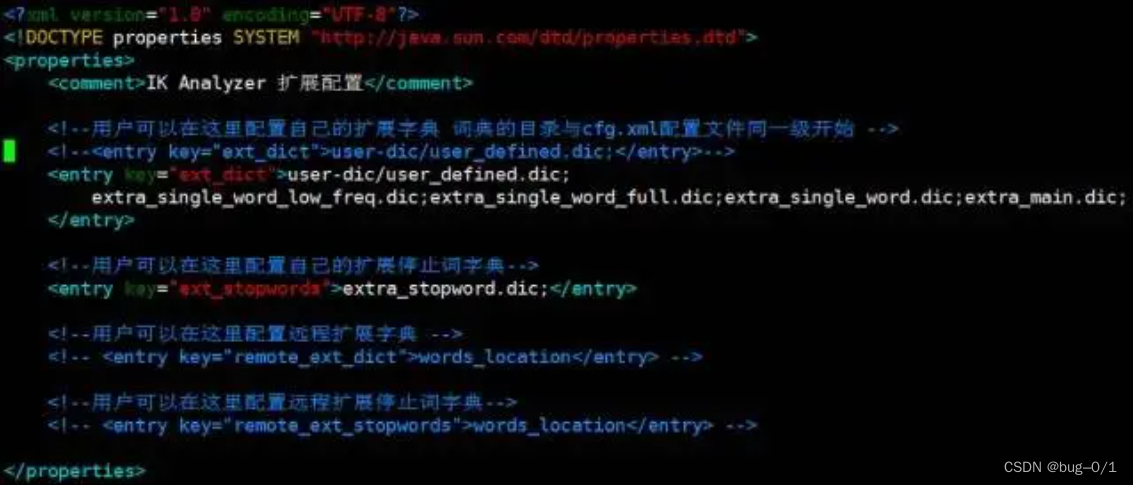
运行函数zdr.index.iKAnalyzer会报莫名其妙的错误,经过测试需要继续从https://github.com/crazyyanchao/neo4j-graph-plugin下载neo4j-graph-plugin-master.zip文件,解压缩后取出其中的dic目录拷贝到neo4j根目录下,否则一直运行失败,因为他需要找分词文件目录,和java中引用IK分词一样。dic目录下的分词文件user_defined.dic可以添加自定义的分词。如果想修改用户自定义词典的位置,可以修改配置文件:
vim dic/dic-cfg/IKAnalyzer.cfg.xml
以上配置好了之后创建中文索引,CompanyFullIndex是索引名称,CompanyEntry是节点。
CALL zdr.index.addChineseFulltextIndex('CompanyFullIndex', ["name"], 'CompanyEntry') YIELD message RETURN message
这里的语法和系统库里的稍微参数位置不一样,其他逻辑都是一样的。查询的方法如下。
CALL zdr.index.chineseFulltextIndexSearch('CompanyFullIndex', 'name:测试~') YIELD node RETURN node





![[ 云计算 | AWS ] AI 编程助手新势力 Amazon CodeWhisperer:优势功能及实用技巧](https://img-blog.csdnimg.cn/cdbefd85b421411bb232db0cdc91a0c5.png)