Learning to Rank 的实践
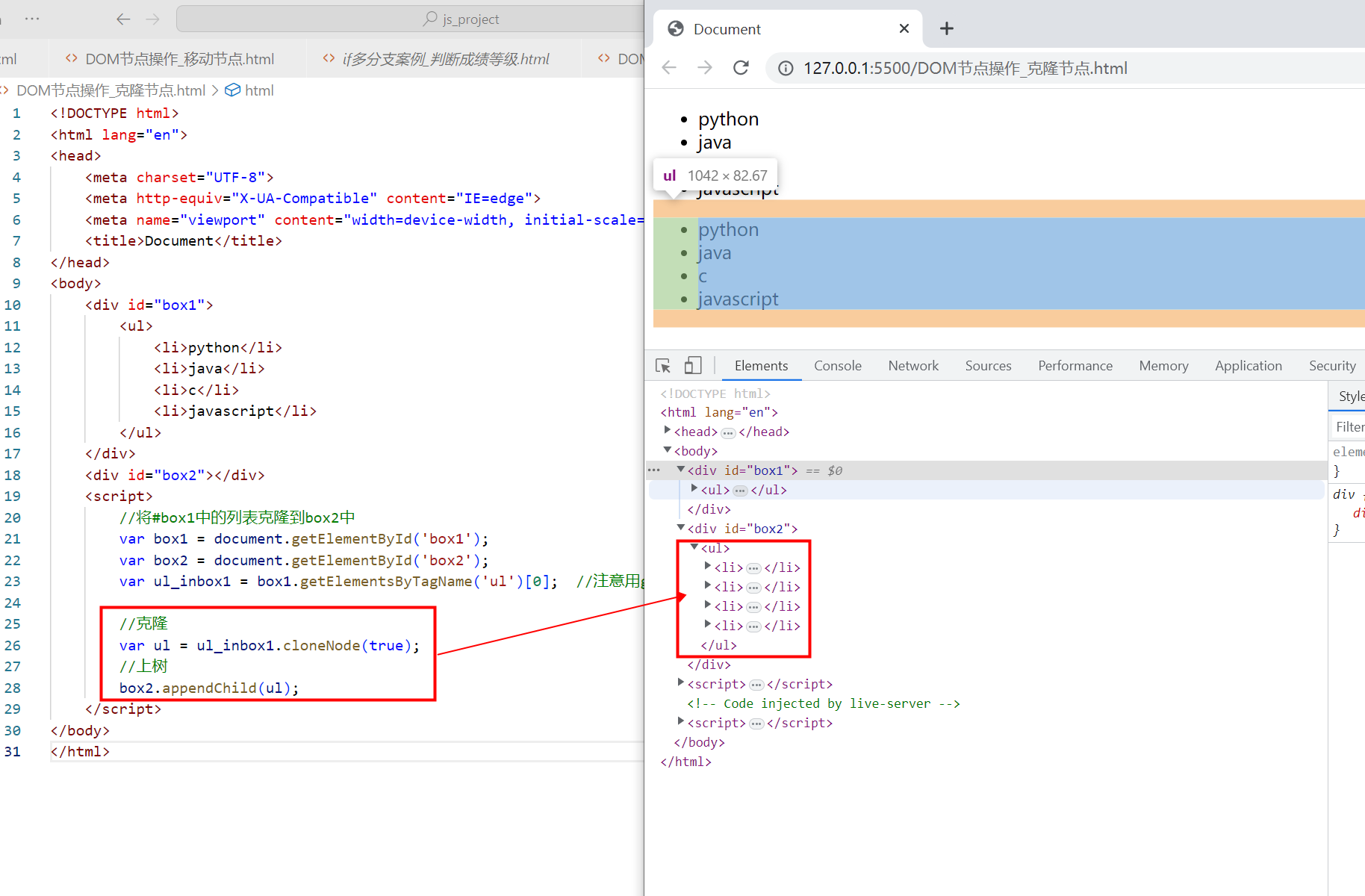
文档列表方法
Listwise 算法相对于 Pointwise 和 Pairwise 方法来说,它不再将排序问题转化为一个分类问题或者回归问题,而是直接针对评价指标对文档的排序结果进行优化,如常用的 MAP、NDCG 等。应用 Listwise 的模型有 ListNet、ListMLE、SVM MAP、AdaRank、SoftRank、LambdaRank、LambdaMART。其中 LambdaMART(对 RankNet 和 LambdaRank 的改进)在 Yahoo Learning to Rank Challenge 表现出最好的性能。
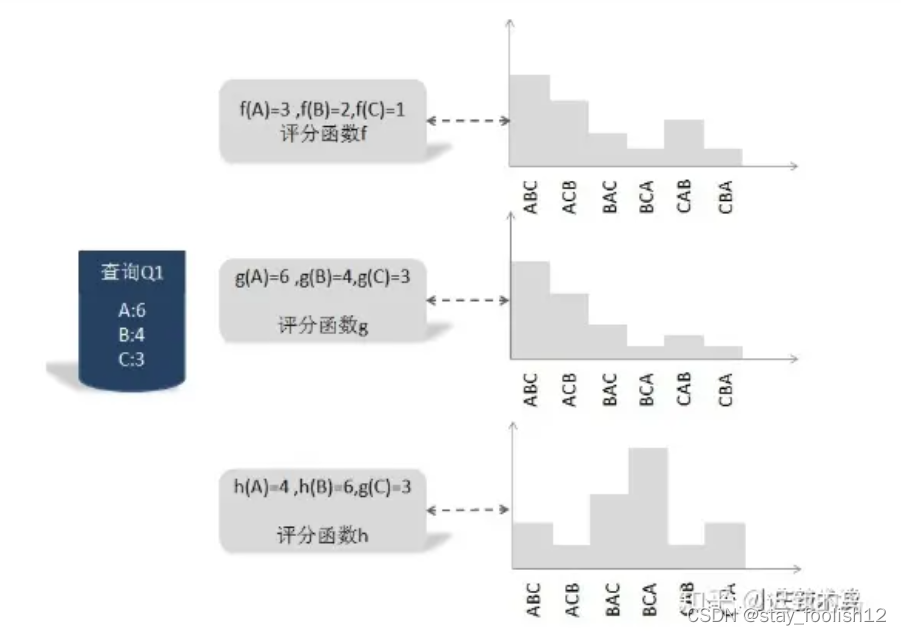
该方法特定Query,文档集合,输出所有文档的打分或者排列顺序。评价指标如 NDCG、MAP 等。由于此种方法是针对评价指标直接进行优化,所以它往往表现出不错的效果。
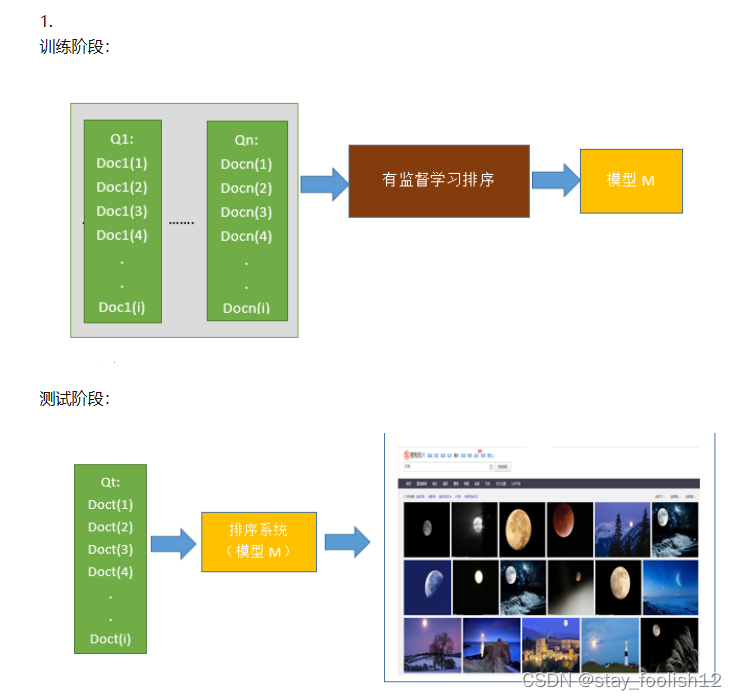
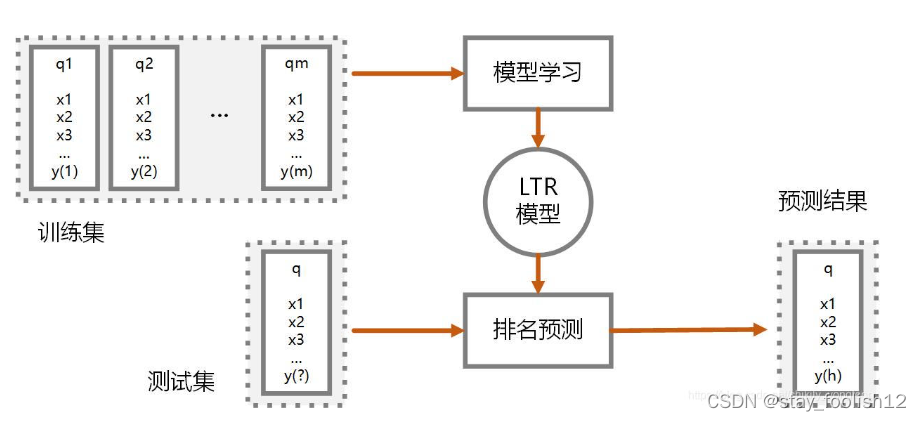
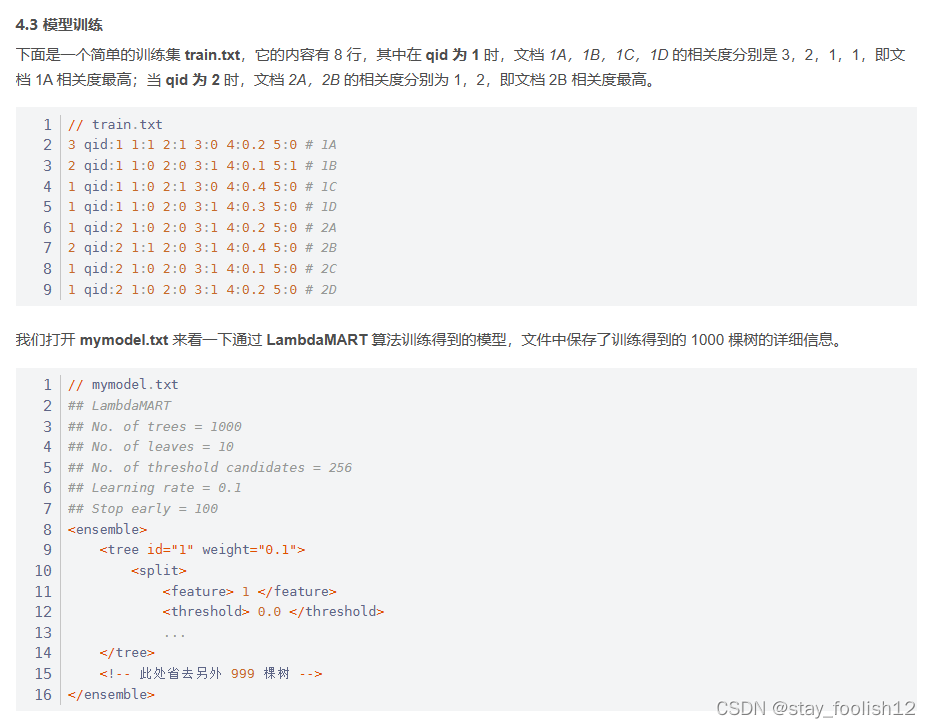
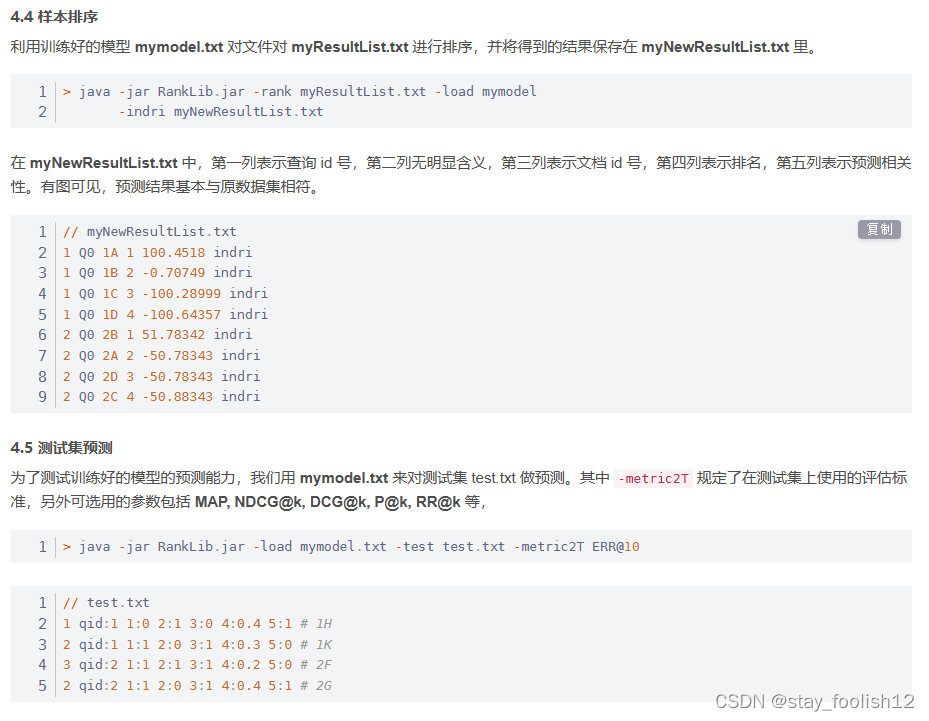
在训练阶段输入是n个query对应的doc集合,通常数据来源有两种,一种是人工标注,即通过对实际系统中用户query返回的doc集合进行相关性标注,标签打分可以是三分制(相关,不相关,弱相关),也可以是更细的打分标准。另外一种是点击日志中获取,通过对一段时间内的点击信息进行处理获得优质的点击数据。这些输入的doc的表示形式是多个维度的特征向量,特征的设计也尤其重要,对网页系统检索而言,常用的有查询与文档匹配特征,其中细化了很多角度的匹配,比如紧密度匹配,语义匹配,精准匹配等等,还有通过将文档分为不同域后的各个域的匹配特征,关键词匹配特征,bm系列特征, 以及通过dnn学习得到的端到端的匹配特征。对各个垂直领域比如图像搜索而言,在网页搜索特征的基础上,需要利用图片相关性特征,图片标签等一系列垂直特征去加强学习效果。
通过排序模型的不断迭代,当一个用户输入一个query之后,排序系统会根据现有模型计算各个doc在当前特征下的得分,并根据得分进行排序返回给用户。




![[ 云计算 | AWS ] AI 编程助手新势力 Amazon CodeWhisperer:优势功能及实用技巧](https://img-blog.csdnimg.cn/cdbefd85b421411bb232db0cdc91a0c5.png)