1. NVIDIA DALI简介
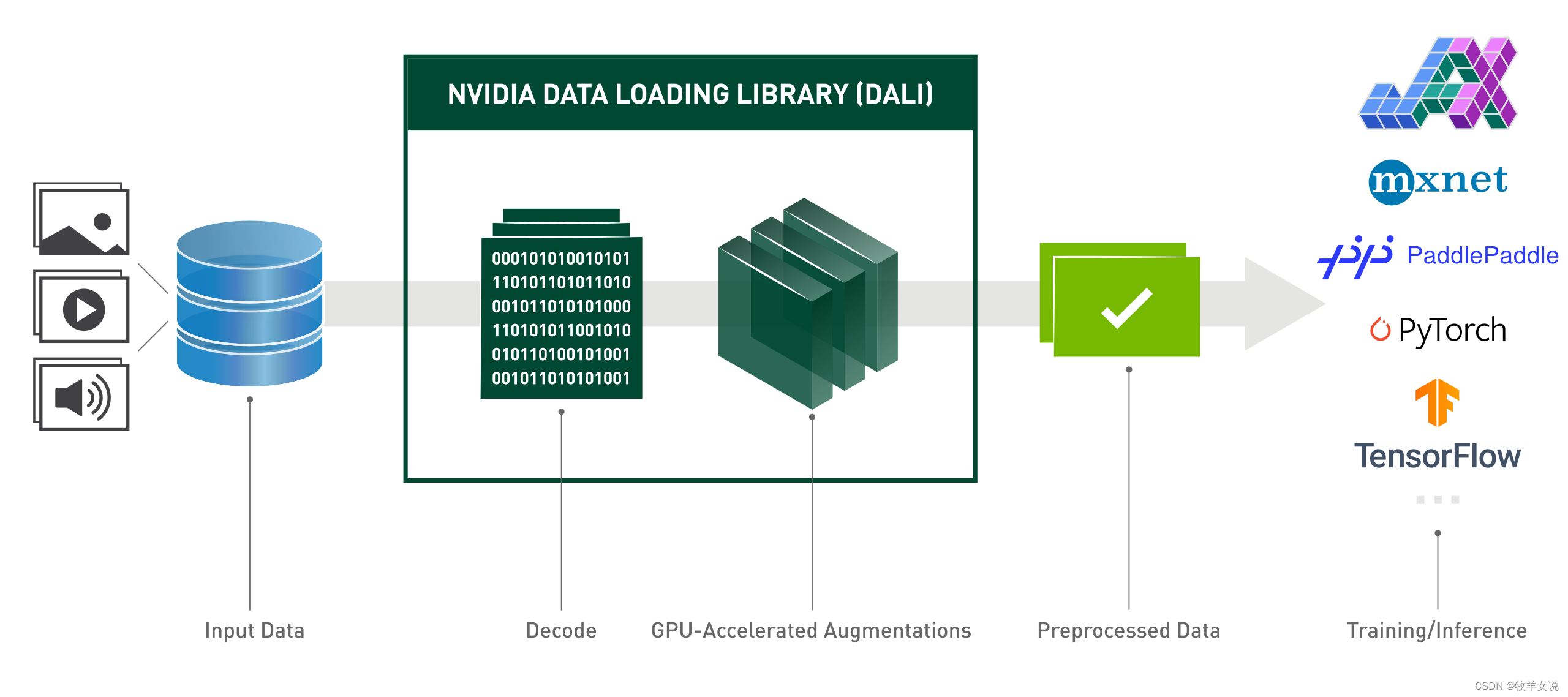
NVIDIA DALI全称是NVIDIA Data Loading Library,是一个用GPU加速的数据加载和预处理库,可用于图像、视频和语音数据的加载和处理,从而为深度学习的训练和推理加速。
NVIDIA DALI库的出发点是,深度学习应用中复杂的数据处理pipeline,如数据加载、解码、裁剪、Resize等功能,在CPU上处理已经成为瓶颈,限制了深度学习训练和推理的性能及可扩展性。DALI库通过使用GPU来处理这些功能,并封装了pre-fetch、并行执行、批处理等功能,降低用户的编程难度。
NVIDIA可适配于多种深度学习框架,如TensorFlow、PyTorch、MXNet和PaddlePaddle。
2. NVIDIA DALI安装
目前NVIDIA DALI只支持Linux x64系统,且CUDA版本在CUDA 11.0以上。
对于CUDA 11.X版本,安装命令行:
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist --upgrade nvidia-dali-cuda110对于CUDA 12.X版本,安装命令行如下:
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist --upgrade nvidia-dali-cuda1203. 读取视频帧
在深度学习应用中,我们常常需要从视频文件或者图像序列构建数据库。这一节就通过一个小例子说明如何用NVIDIA DALI从视频文件中读取指定数量视频帧。
最简单的使用方式,是通过@pipeline_def修饰符来定义nvidia dali pipeline,如下例,我们定义一个从视频文件(通过filenames指定视频文件列表)读取指定数量视频帧(通过sequence_length指定)的pipeline。
# Define a video pipeline
@pipeline_def
def video_pipeline(filenames, sequence_length):
videos = fn.readers.video(device='gpu', filenames=filenames, sequence_length=sequence_length, name='Reader')
return videos然后对以上定义的pipeline实例化:
sequence_length = 25
video_directory = r'/home/grace/BSVD/datasets/DAVIS-training-mp4'
video_files = [video_directory + '/' + f for f in os.listdir(video_directory)]
# Build the video pipeline
pipe = video_pipeline(batch_size=1, num_threads=2, device_id=0, filenames=video_files, sequence_length=sequence_length, seed=123456)
pipe.build()实例化过程中,可以传入其他pipeline参数,如batch_size、num_threads等。
构建完成后,通过pipeline.run()来实现视频帧的输出,默认为RGB类型。
for i in range(0,20):
pipe_out = pipe.run()
sequence_out = pipe_out[0].as_cpu().as_array()
print('i = {}, sequence shape = {}'.format(i, sequence_out.shape))
# show_sequence(sequence_out[0])
save_images(i, sequence_out[0]) # 保存读取到的图像序列4. 读取图像序列
除了从视频文件中读取视频帧,NVIDIA DALI还提供从图像序列读取数据的功能。
参考nvidia dali官方说明文档中的一个示例,亲测有效。
from nvidia.dali import pipeline_def
import nvidia.dali.fn as fn
import nvidia.dali.types as types
# Define a function for showing output image
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
%matplotlib inline
def show_images(image_batch):
columns = 4
rows = (max_batch_size + 1) // (columns)
fig = plt.figure(figsize = (24,(24 // columns) * rows))
gs = gridspec.GridSpec(rows, columns)
for j in range(rows*columns):
plt.subplot(gs[j])
plt.axis("off")
plt.imshow(image_batch.at(j))
# image sequence dir
image_dir = "data/images"
max_batch_size = 8
# Define an image sequence reading pipeline
@pipeline_def
def simple_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir)
images = fn.decoders.image(jpegs, device='cpu')
return images, labels
# Build the pipeline
pipe = simple_pipeline(batch_size=max_batch_size, num_threads=1, device_id=0)
pipe.build()
# Run the pipeline and show output
pipe_out = pipe.run()
images, labels = pipe_out
show_images(images)输出结果如下:

除了以上基础用法,nvidia dali还集成了很多数据增广方法,如旋转、剪切、resize等等,今天由于时间关系,下次再继续补充吧。