《Read Ten Lines at One Glance: Line-Aware Semi-Autoregressive Transformer for Multi-Line Handwritten Mathematical Expression Recognition》论文翻译
文章目录
- 《Read Ten Lines at One Glance: Line-Aware Semi-Autoregressive Transformer for Multi-Line Handwritten Mathematical Expression Recognition》论文翻译
- ABSTRACT
- 1 INTRODUCTION
- 2 RELATED WORK
- 2.1 手写的数学表达式识别
- 2.2 非自回归和半自回归解码
- 2.3 数学表达式数据集
- 3 PROPOSED METHOD
- 3.1 Overview
- 3.2 Line-wise Dual-end Decoding
- 3.3 Line-partitioned Dual-end Mask
- 3.4 Line-aware Positional Encoding
- 3.5 Shared-task Optimization
- 4 THE M2E DATASET
- 5 EXPERIMENT
- 5.1 Implementation Details
- 5.2 Evaluation Metrics
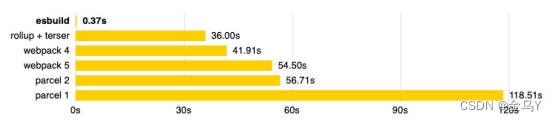
- 5.3 Comparisons with State-of-the-arts
- 5.4 Ablation Study
- 6 VISUALIZATION
论文地址: https://dl.acm.org/doi/pdf/10.1145/3581783.3612499
代码地址: https://github.com/HCIILAB/LAST
ABSTRACT
我们提出了一种具有线感知能力的半自回归变换器(LAST),它将多线数学表达式序列视为二维双端结构。该LAST利用线向双端解码策略并行解码多线数学表达式,并在每行内执行双端解码。具体地说,我们引入了一个线感知位置编码模块和一个行分区双端掩码,以赋予LAST线顺序感知和方向性。
1 INTRODUCTION
人类很难一次阅读长串的文本。同样,随着序列长度的增加,基于注意力的自回归编-解码器模型也会出现误差积累。当自回归识别多行手写的数学表达式时,我们观察到注意机制有时会将当前的行与其他行混淆,使这些行无法被识别,称为跨行混淆。如下图:

基于上述思想,我们将多行数学表达式序列视为二维双端结构,并进一步提出了一种线感知半自回归变换器(LAST)模型来实现对该二维序列的解码。具体来说,我们提出的LAST采用了行的双端解码策略,并行解码多行数学表达式,并在每行内执行双端解码。此外,我们提出了一个行感知的位置编码模块和一个行分区的双端掩模,以赋予模型的行顺序感知和方向性。此外,为了结合半自回归任务和自回归任务的优势,我们采用了一种共享任务优化策略来共同训练这两个任务。
综上所述,我们的工作有以下贡献:
- 我们提出了一个LAST模型,该模型结合了行级双端解码策略和行感知位置编码模块,以半自回归地识别多行数学表达式,减轻了跨行混淆和缓慢的解码速度。
- 我们提出了一个包含约10万幅图像的多行数学表达式数据集,以更好地评估模型在实际应用场景中的性能。
- LAST模型具有最先进的性能,更快的解码速度
2 RELATED WORK
2.1 手写的数学表达式识别
略
2.2 非自回归和半自回归解码
略
2.3 数学表达式数据集
略
3 PROPOSED METHOD
3.1 Overview

如图所示,我们提出的行感知半自回归变换器(LAST)遵循编解码器框架。在Dense-WAP之后,一个Densenet提取输入图像的视觉特征。然后将用二维位置信息编码的视觉特征作为交叉注意的查询输入到变压器解码器。二维位置编码与BTTR 相同。通过行感知位置编码和一个可学习的行指数向量和两个逆正弦位置编码,使模型具有行序感知和方向性。在行感知自注意中,将行分区掩模应用于注意映射,以忽略尚未生成的令牌。在推理过程中,根据行双端解码策略对输出序列进行解码,得到当前时间步长生成的每一行的左到右和右到左字符。解码结果可以看作是一个二维序列,然后重新排列成一个一维序列,作为下一个时间步长的输入。
3.2 Line-wise Dual-end Decoding
我们将一个具有多行的完整表达式序列视为一个二维双端结构。显式的二维结构建模增强了模型的行序感知,从而保证了解码过程中多行结构的完整性。此外,我们还采用了双端解码策略来缩短行内字符的长度。
行解码: 对于多行数学表达式,我们可以根据视觉特征将标签序列分割成行。我们使用n行 y = ( y 1 1 , y 2 1 , y 3 1 , … , y k 1 1 , y 1 2 , y 2 2 , y 3 2 , … , y k 2 2 , … , y 1 n , y 2 n , y 3 n , … , y k n n ) y=(y^{1}_{1},y^{1}_{2},y^{1}_{3},\dots,y^{1}_{k_{1}},y^{2}_{1},y^{2}_{2},y^{2}_{3},\dots,y^{2}_{k_{2}},\dots,y^{n}_{1},y^{n}_{2},y^{n}_{3},\dots,y^{n}_{k_{n}}) y=(y11,y21,y31,…,yk11,y12,y22,y32,…,yk22,…,y1n,y2n,y3n,…,yknn)数学表达式序列。其中 k i k_{i} ki表示第i行中的第k个字符。逐行解码的目的是在当前时间同时解码所有行中的第一个字符。在时间步长𝑡,解码器预测一个字符序列 ( y t 1 , y t 2 , … , y t n ) (y^{1}_{t},y^{2}_{t},\dots,y^{n}_{t}) (yt1,yt2,…,ytn)。
双向解码: 除了按行解码外,我们还提出了一种双向解码策略来解决跨线混淆问题和加快解码速度。与BTTR 和ABM ,采用完整的双向解码的整个序列,我们的双向解码策略停止在中间的序列,引入两个更具有挑战性的任务: 1)从两端同时检测行结构,2)与相反方向的解码序列进行交互,以确定解码何时完成。
对于每一行𝑖,我们的双向解码策略在时间步长𝑡时同时预测了从左到右和从右到左的字符 y t i y^{i}_{t} yti和 y k i − t i y^{i}_{k_{i}-t} yki−ti。对于普通的自回归预测[,添加了额外的标签和作为开始和结束条件。同样,对于双向解码,我们使用(左开始)和(左中间)作为从左到右解码序列的起始和终止标记,使用和作为从右到左解码序列的起始和终止标记。即,对于每一行𝑖,我们的输入序列为 y i = ( < S O L i > , y 1 i , y 2 i , … , y K i − 1 i , y k i i , < S O R i > ) y^{i}=(<SOL_{i}>,y^{i}_{1},y^{i}_{2},\dots,y^{i}_{K_{i}-1},y^{i}_{k_{i}},<SOR_{i}>) yi=(<SOLi>,y1i,y2i,…,yKi−1i,ykii,<SORi>)以及相应的输出序列 y i = ( y 1 i , y 2 i , … , y K i / 2 i , < M O L i > , < M O R i > , y k i / 2 + 1 i , … , y k i i ) y^{i}=(y^{i}_{1},y^{i}_{2},\dots,y^{i}_{K_{i/2}},<MOL_{i}>,<MOR_{i}>,y^{i}_{k_{i/2+1}},\dots,y^{i}_{k_{i}}) yi=(y1i,y2i,…,yKi/2i,<MOLi>,<MORi>,yki/2+1i,…,ykii)。
对于输入序列长度为奇数的情况,我们在序列中间插入一个额外的中间终止标记,将输出从左到右和从右到左对齐,以便在同一时间步长停止。这种奇偶性预测任务进一步促进了两个双向序列之间的语义交互。在推理过程中,通过双向移动每行的输出,将预测的字符添加到输入序列中,称为对行感知的位移输出。
3.3 Line-partitioned Dual-end Mask
由于Transformer的注意力是全局的,所以Transformer 解码器利用三角矩阵防止向左的信息流,以保持自回归特性,如下图所示。为了实现所提出的行向双端解码策略,我们的LAST中的行感知注意采用了行分区双端掩模来调节不同标记之间的回归关系。

行分区Mask: 在行解码中,我们对不同的行并行自动回归解码。对于每一行𝑖,掩模
m
⃗
i
\vec{m}^{i}
mi是一个类似于Transformer中的三角形矩阵。蓝色掩模如上图c所示,我们的线分区掩模
M
⃗
\vec{M}
M将每条线的三角形矩阵对角线连接起来,以实现并行性:
M
⃗
=
[
m
⃗
1
0
…
0
0
m
⃗
2
…
0
⋮
⋮
⋱
⋮
0
0
⋮
m
⃗
n
]
\vec{M} = \begin{bmatrix} \vec{m}^{1} &0 &\dots &0 \\ 0 &\vec{m}^{2} &\dots &0 \\ \vdots &\vdots &\ddots &\vdots \\ 0 &0 &\vdots &\vec{m}^{n} \end{bmatrix}
M=
m10⋮00m2⋮0……⋱⋮00⋮mn
双端掩码: 双端解码需要从左到右和从右到左的解码。为了在不改变序列顺序的情况下实现单线的右向自回归,我们将下三角矩阵改为上三角,如上图b所示。
双端掩模
m
i
↔
\overleftrightarrow{m_{i}}
mi
是从左到右和从右到左的自回归掩模的组合,如上图e所示的两个蓝色矩阵所示。双端掩模
m
i
↔
\overleftrightarrow{m_{i}}
mi
的数学表达式为:
m
i
↔
=
{
0
p
<
k
2
a
n
d
p
<
1
<
k
−
p
+
1
0
p
>
k
2
a
n
d
k
−
p
+
1
<
q
<
p
1
o
t
h
e
r
w
i
s
e
\overleftrightarrow{m_{i}} = \left\{\begin{matrix} 0 & p<\frac{k}{2} and p<1<k-p+1\\ 0 & p> \frac{k}{2} and k-p+1<q<p\\ 1 & otherwise \end{matrix}\right.
mi
=⎩
⎨
⎧001p<2kandp<1<k−p+1p>2kandk−p+1<q<potherwise
3.4 Line-aware Positional Encoding
行感知位置编码: 为了对当前解码行的位置进行编码,我们采用了一个可学习的行索引编码向量:
p
l
(
i
)
=
E
m
b
(
W
i
∣
i
,
W
)
p_{l}(i) = Emb(W_{i}|i,W)
pl(i)=Emb(Wi∣i,W)
其中,
W
∈
R
n
×
D
W\in R^{n \times D}
W∈Rn×D为可学习参数,𝑛为最大线数,𝑖为要编码的线索引,
W
i
∈
R
D
W_{i}∈R^{D}
Wi∈RD为嵌入索引𝑖in𝑊得到的线索引编码向量。多行数学表达式的阅读顺序可能相当复杂,而我们的行感知位置编码隐式地模拟了这种阅读顺序的学习
双端位置编码: 在双端解码中,感知解码方向是必不可少的。因此,我们设计了两个逆正弦编码:
p
x
→
(
x
,
i
)
=
{
s
i
n
(
x
T
m
/
D
)
i
=
2
m
c
o
s
(
x
T
m
/
D
)
i
=
2
m
+
1
p_{\overrightarrow{x}}(x,i) = \begin{cases} sin(\frac{x}{T^{m/D}}) & i=2m \\ cos(\frac{x}{T^{m/D}}) & i=2m+1 \end{cases}
px(x,i)={sin(Tm/Dx)cos(Tm/Dx)i=2mi=2m+1
p x ← ( x , i ) = { s i n ( k − x − 1 T m / D ) i = 2 m c o s ( k − x − 1 T m / D ) i = 2 m + 1 p_{\overleftarrow{x}}(x,i) = \begin{cases} sin(\frac{k-x-1}{T^{m/D}}) & i=2m \\ cos(\frac{k-x-1}{T^{m/D}}) & i=2m+1 \end{cases} px(x,i)={sin(Tm/Dk−x−1)cos(Tm/Dk−x−1)i=2mi=2m+1
上述两个公式分别表示从左到右和从右到左的位置编码,其中𝑘表示当前行中的标记数,𝑥∈[0,𝑘𝑖/2),𝐷为嵌入维度,𝑇为在Transformer后设置为1000的常量。
最后,为了得到我们的行感知位置编码,将相同的行索引编码向量赋给同一行中的所有标记,然后加上两个双端位置编码:
p
l
a
=
C
o
n
c
a
t
(
p
x
→
;
p
x
←
)
+
p
l
p_{la} = Concat(p_{\overrightarrow{x}}\space ; \space p_{\overleftarrow{x}})+p_{l}
pla=Concat(px ; px)+pl
3.5 Shared-task Optimization
虽然Transformer具有并行输出的潜力,但将Transformer直接应用于半自回归任务的性能通常是次优的。我们提出了一种简单而有效的联合优化策略,它弥补了半自回归模型缺乏上下文依赖性的不足,同时也提高了自回归模型的性能。具体来说,有三个任务可以同时进行优化。与BTTR和ABM一样,我们采用了从左到右和从右到左的预测任务,即将多行表达转录标记为单行,并带有行中断。第三个任务是本文提出的半自回归任务。这三个任务在彼此之间共享部分相同的字符序列。这种训练策略可以加强该模型在直线结构之间的区别。我们利用每批样本的三个任务的交叉熵损失来同时优化参数
L
(
θ
)
→
=
−
1
N
∑
t
=
1
N
l
o
g
p
(
y
t
→
∣
y
<
t
→
)
\overrightarrow{L(\theta )} =-\frac{1}{N}\sum_{t=1}^{N}logp(\overrightarrow{y_{t}}|\overrightarrow{y_{<t}} ) \
L(θ)=−N1t=1∑Nlogp(yt∣y<t)
L
(
θ
)
←
=
−
1
N
∑
t
=
1
N
l
o
g
p
(
y
N
−
t
←
∣
y
<
N
−
t
←
)
\overleftarrow{L(\theta )} =-\frac{1}{N}\sum_{t=1}^{N}logp(\overleftarrow{y_{N-t}}|\overleftarrow{y_{<N-t}} )
L(θ)=−N1t=1∑Nlogp(yN−t∣y<N−t)
L
(
θ
)
↔
=
−
1
N
′
∑
i
=
1
n
∑
t
=
1
N
′
/
2
l
o
g
p
(
(
y
↔
t
∣
y
↔
<
t
,
>
k
i
−
t
)
+
(
y
↔
k
i
−
t
∣
y
↔
<
t
,
>
k
i
−
t
)
)
\overleftrightarrow{L(\theta )} =-\frac{1}{N^{'}}\sum_{i=1}^{n}\sum_{t=1}^{N^{'}/2} logp((\overleftrightarrow{y}_{t}|\overleftrightarrow{y}_{<t,>k_{i}-t})+(\overleftrightarrow{y}_{k_{i}-t}|\overleftrightarrow{y}_{<t,>k_{i}-t}) ) \
L(θ)
=−N′1i=1∑nt=1∑N′/2logp((y
t∣y
<t,>ki−t)+(y
ki−t∣y
<t,>ki−t))
L
j
o
i
n
t
=
L
(
θ
)
→
+
L
(
θ
)
←
+
λ
L
(
θ
)
↔
L_{joint} = \overrightarrow{L(\theta )} + \overleftarrow{L(\theta )} + \lambda \overleftrightarrow{L(\theta )}
Ljoint=L(θ)+L(θ)+λL(θ)
4 THE M2E DATASET

5 EXPERIMENT
5.1 Implementation Details
- RTX 3090 x1
- Intel Core i7-12700KF CPU
- batchsize=12
- Transformer hidden dim = 256
- number heads = 8
- number of layers = 3
- dropout = 0.3
- Adadelta: weight decay 1e−4 , 𝜌= 0.9,𝜖 = 1 e−6
- maximum line number = 16
- λ \lambda λ = 1
5.2 Evaluation Metrics
评估指标:
- 整行正确率
- 推理速度(fps)
5.3 Comparisons with State-of-the-arts
- M2E

- CROHME

“*”表示该模型在多行CROHME数据(多个图片进行合成)上进行训练,并在单行CROHME数据上进行测试。

5.4 Ablation Study
消融实验:
-
行感知位置编码
的影响虽然行双端解码策略和行分割双端掩码调节了半自回归解码的回归关系,但由于缺乏位置感知,模型无法收敛。结合所提出的线感知位置编码显著提高了识别性能,表明我们所提出的行感知位置编码对于多线表达式的半自回归关系建模是至关重要和不可或缺的。
-
共享任务优化策略
我们的模型能够同时进行半自回归和普通的自回归解码,所提出的半自回归任务与自回归任务具有协同作用。
-
解码效率
我们提出的LAST通过减少回归迭代的次数来加速解码速度。与自回归模型相比,所提出的逐行式双端解码策略使平均迭代次数减少了78.8%,从而显著提高了解码效率

“LWDE”、“LAPE”和“STO”分别表示所提出的行双端解码策略、行感知位置编码策略和共享任务优化策略。"Avg“它表示在整个测试集上的解码器迭代的平均次数。
6 VISUALIZATION






![23111706[含文档+PPT+源码等]计算机毕业设计SSM框架网上书城全套微信支付电商购物](https://img-blog.csdnimg.cn/img_convert/8e4fb2245d5c5847f514e415a873d82b.png)