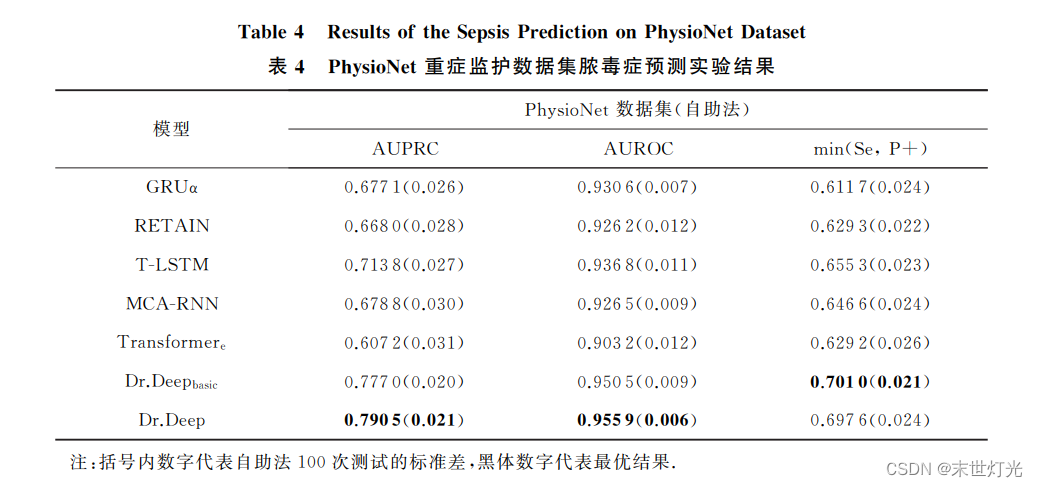
2022年11月13日,第二届SpeechHome语音技术研讨会和第七届Kaldi技术交流会圆满落幕。本届SpeechHome语音技术研讨会由中国计算机学会、深圳市人工智能学会、小米集团、腾讯天籁实验室、语音之家主办,CCF语音对话与听觉专委会作为指导单位,由内蒙古大学语音信号处理组、清华大学语音和语言技术中心、香港中文大学(深圳)语音与语言实验室、上海交通大学跨媒体语言智能实验室、昆山杜克大学语音与多模态智能信息处理实验室、西北工业大学音频语音与语言处理研究组、厦门大学智能语音实验室、上海白玉兰开源开放研究院、希尔贝壳协办。
下面是整体会议的内容回顾:

13日上午9:00,AISHELL & SpeechHome CEO卜辉宣布研讨会开始,并简要介绍本次研讨会的筹备情况以及报告内容。随后,天津大学教授、CCF 语音对话与听觉专委会主任党建武老师对本次大会进行开幕致辞,他提到语音界能够如此迅速的发展,能够吸引许多年轻初学者,很重要的一个要素就是语音领域有很多丰富而且活跃的开源平台(包括算法和数据)。它的出现给我们提供了很好的交流平台,使得我们避免了许多重复性的劳动,并且降低了初学者进入本领域的门槛。在国际上,开源的语音工具包大约出现在上个世纪90年代,虽然,我国的开源平台和社区起步较晚、缺乏类似国外成熟的开源社区和平台,近年来也涌现出一批与智能语音相关的成熟的开源软件平台和社区,对语音技术的发展起到了重要作用。随后介绍了CCF语音对话与听觉专委会的发展以及呼吁更多的同仁能够加入到CCF语音对话与听觉专委会,为语音界的发展添砖加瓦。同时希望这次研讨会能够起到互相交流,互相促进的作用,激发更多的年轻学者和技术人员参与开源平台的开发和建设,把中国的开源力量推向世界!最后党老师预祝研讨会圆满成功!
接下来是上午的主旨报告和技术分享两个主题的内容回顾。
主旨报告

陈景东分享的主题是《多通道声信号感知与处理:原理、现状与挑战》。下一代智能声学与临境通信系统必然涉及到多通道声信号的感知与处理。在这个报告中,我将简要介绍单通道拾音系统的局限以及多通道拾音系统带来的好处,然后和大家分享一下多通道声信号感知的基本原理、多通道声信号处理所要解决的主要问题以及面临的主要挑战。
技术分享

余涛分享的主题是《腾讯会议的实时音频技术介绍和展望》。报告覆盖腾讯会议天籁实验室在多声学场景,复杂网络条件下的,实时音频通信领域的全链路音频技术研发,从声音信号的采集,处理,编码到回放技术,音频和视频AI多模态技术在视频会议场景下的应用,以及相关的实时字幕,会议纪要技术在远程视频会议场景下的技术挑战和应用。

秦勇分享的主题是《针对病理性发音的语音技术研究进展》。随着深度学习技术的发展,语音识别性能在训练数据量规模能够满足的情况下,在多种复杂的声学环境中都取得了巨大的进展。但是,对于病理性发音,例如构音障碍患者的语音,由于其语速慢、韵律不规则、鼻音较重、声音嘶哑、语调单一等,与正常语音信号的特性差别显著,再加上难于获取真实的海量大数据,因而构音障碍患者在使用普通的语音识别服务时,其识别精度显著下降,导致病理性发音人无法有效利用数字设备带来的便利,进行有效的人际交互和人机交互,因此急需语音技术的突破。本报告重点介绍国内、国际上在相关研究领域的思路和进展。

张学良分享的主题是《基于原地卷积网络的前端信号处理算法》。深度学习最早被应用于单麦语音增强中,并展现出了优异的性能。随着研究的不断深入,近几年,深度学习开始用于其他传统信号处理任务中,包括:语音增强、回声消除、混响消除等。采用的模型包含DNN、RNN、CNN等。以广泛使用的CNN为例,卷积过程中通常伴有下采样和上采样。考虑到众多传统信号处理算法都采用频带单独处理的方式。上采样和下采样会导致信息丢失,从而增加了学习难度。因此,我们提出了原地卷积网络,避开了卷积过程中的上采样和下采样。在对麦克风阵列增强、AEC和dereverberation任务的验证结果表明,相比其他深度学习模型,原地卷积网络可以明显的提升算法的性能,并有效的降低模型的参数量。

李圣辰分享的主题是《用于声学信号内容理解的机器学习算法前瞻》。近年来,对于声学信号内容进行理解的研究得到了长足的进步。音频信号内容理解任务主要通过分析一般声音信号,对声音信号中的内容进行分析。典型的声音信号理解任务包括但不限于:声学场景分类,声音事件检测,声音异常检测,音频内容描述等。作为声学信号内容理解的标志性事件,DCASE(声学场景分类与事件检测)数据挑战赛的举办,引领着相关领域的科研前沿与热点。讲座通过讲述DCASE数据挑战赛的项目设置沿袭与发展,讨论用于声学信号的机器学习算法的发展方向。

武执正分享的主题是《跨语种的语音转换》。随着深度学习技术的发展,目前同语种的语音转换已经能够达到很好的效果。但是,在跨语种场景中,由于不同语种发音系统的差异,使用同语种语音转换技术会导致生成的语句中带有我们不希望听到的口音。就像外国人学习讲普通话的时候,不能发出正确的音调。这种带口音的普通话,也往往会造成理解上的歧义。该报告将介绍一种消除上述口音的技术。该技术通过引入语言学知识来达到消除口音的目的。该算法能够在保持录音内容不变、韵律不变等情况下,通过消除口音以达到提高转换语音易懂度的目的。

陈卓分享的主题是《实时多人会话的语音识别》。在会议中,多人的对话包含语音混叠和快速说话人切换,破环了传统语音处理系统对于单说话人的假设,从而对实时语音转录造成了大量的性能损失。为了解决多人会话中的实时语音转录,我们在不同层面提出了解决方案,包含模块化的设计以及端到端的识别系统。在本次报告中,我将会介绍我们利用大规模自监督学习以及端到端系统来解决实时多人会话识别问题的进展。


13日下午14:00,小米集团副总裁、集团学习发展部总经理崔宝秋对会议进行致辞。在万物智能互联时代,语音交互及以音视频为主的多模态交互技术有了更多的应用场景。随着AI技术的发展,智能语音技术和产品也迎来了一个快速发展的机会,这些产品和技术的发展和开源息息相关。而开源届出现了不同的声音,崔总认为开源的本质包含开放、共享、平等、协作和创新,回归开源的本质,可以帮助我们做到更加纯粹、更加极致的开源,帮助智能语音技术得到快速的发展。
崔总提到Kaldi是一个比较好的坚持开源本质的案例,这和Daniel Povey博士本人的理念和坚持密不可分,他希望通过Kaldi为中小微企业打造一个免费且性能强大的语音识别工具集,他选择小米的理由也是因为小米多年来极致追求开源。Daniel在小米的三年期间一心致力于下一代Kaldi的开发,在去年Interspeech会议上他正式向外宣布新一代Kaldi正式成型,里面分为三个子模块——LHOTSE、K2、ICEFALL。今天下午的研讨会上也将发布第四个模块。崔总希望有更多的语音届同仁能够参与到Kaldi项目中,一起打造一个更加繁荣的Kaldi开源生态。小米会一如既往的深度拥抱开源,对Kaldi技术交流提供支持,将Kaldi做成国际化的开源标杆。
接下来是下午的主旨报告和开源技术分享两个主题,由内蒙古大学研究员刘瑞担任主持。

主旨报告

金耀辉分享的主题是《白玉兰开源:面向人工智能应用的开放数据集构建及许可协议》。深度学习过去一直集中在改善模型提高性能,然而随着深度学习在一些关键任务中的落地应用,人们越来越发现过去这种以模型为中心人工智能方法的弊端。如何测度深度学习中的不变性和因果性,从而为人工智能带来更可靠的可复现性,是目前的研究热点和前沿。我们还将介绍木兰-白玉兰开放数据许可协议,界定数据利益相关方之间对特定数据对象流通条件和方式的各自权责,推动面向人工智能应用的数据要素流通。
开源技术分享

Daniel Povey分享的主题是《Recent progress and Upcoming Work in Next-Gen Kaldi》。I will talk about some of our recent improvements in next-gen Kaldi (Icefall, Lhotse and k2), including modeling improvements (mostly RNNT-based), updates to available decoding methods, new recipes, and so on. I will also discuss our plans for the future and ongoing work.

郭理勇分享的主题是《基于新一代kaldi项目的语音识别应用实例》。主要介绍一些新一代kaldi项目在学术研究和工程部署两个方面的应用案例。

张彬彬分享的主题是《WeNet 开源社区》。报告内容主要是WeNet开源社区和社区项目介绍。

钱彦旻、张王优、李晨达分享的主题是《ESPnet-SE 开源工具介绍》。本次报告将会介绍 ESPnet 开源工具在语音增强方面的进展。ESPnet-SE 是 2020 年 6 月开始筹备的 ESPnet 子项目,目的是为 ESPnet 提供丰富的前端语音处理功能,包括降噪、去混响和语音分离等。在两年多的时间里,ESPnet-SE 累计添加了对 24 种语音增强模型(12 种单通道模型 + 12 种多通道模型)的支持,并配有 22 个覆盖从数据准备到模型训练及评估等全流程的 recipes,其中部分 recipe 在 Hugging Face 上提供了相应的已训练模型。ESPnet-SE 也提供了对其他语音前端开源工具的兼容,如允许在 ESPnet 中直接加载并训练来自 Asteroid 工具的模型。除此之外,ESPnet-SE 提供了将前端模型和其他下游语音任务(语音识别、语音翻译、口语理解等)进行结合的接口和示例,使得我们能够很容易实现前端模型和不同后端任务的联合训练或评估。本次报告将重点介绍 ESPnet-SE 工具的特色功能以及使用方法,并对后续开发计划进行简单梳理。

江涛分享的主题是《声纹识别工具ASV-Subtools》。推动声纹识别开源有助于语音行业生态的建设,促进学术研究和更多产业应用。ASV-Subtools是厦门大学智能语音团队经过多年研发的一套高效、易于扩充的声纹识别开源工具,报告将介绍ASV-Subtools的系统组件、特性和最新的研究结果,同时介绍最新开源的声纹落地Runtime实现,并对下一步的发展做了规划。

卜辉分享的主题是《AISHELL Datasets and SpeechHome Benchmarks》。AISHELL的语音数据集和开源项目的现状介绍。语音识别的准确率通过数据集的评估可以体现具体的性能指标,例如句准、字准等。通过构建高质量语音评测数据集来实现ASR模型的评估,对智能语音产业及用户体验的提升都起到了促进作用。SpeechHome在模型评测方面的工作,介绍了SpeechHome针对ASR模型的SOTA内容,包括Benchmark和Leaderboard。

在Panel环节,郭理勇、张彬彬、张王优、江涛四位嘉宾围绕语音技术的开源进行了探讨,对未来开源的方向和方式上提出了自身的想法和建议。
最后主办方对大会做总结和鸣谢。至此,第二届SpeechHome语音技术研讨会圆满结束,期待与大家再次相见。各平台会议直播观看人数累计9000+。
嘉宾PPT下载
语音之家公众号后台回复 “2022SH语音技术研讨会”,获取嘉宾PPT。