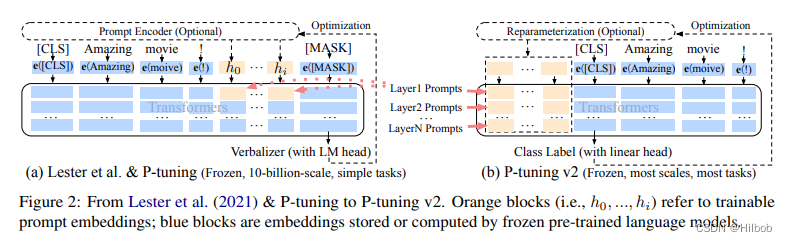
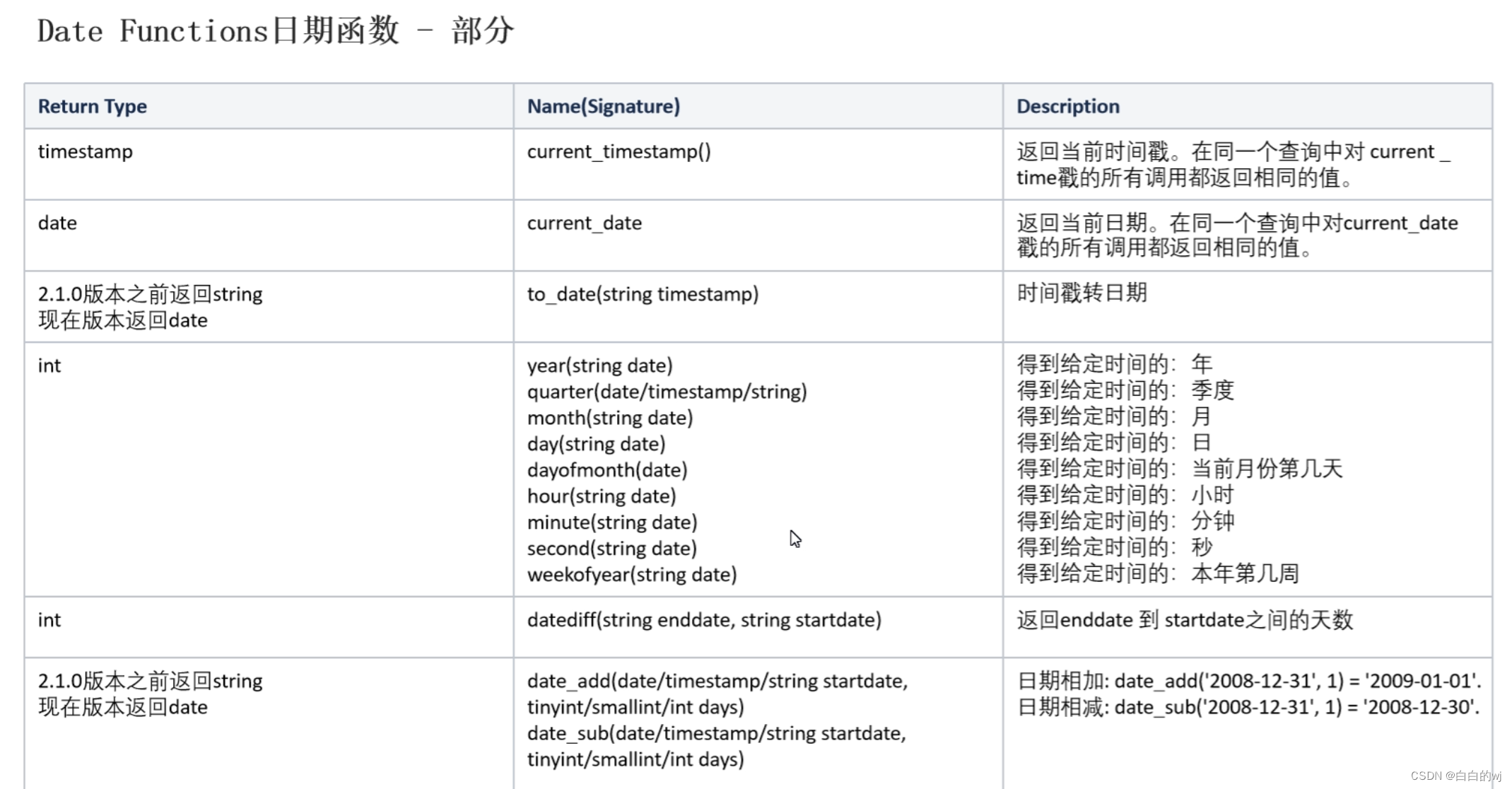
通过toDF方法创建DataFrame
通过toDF的方法创建
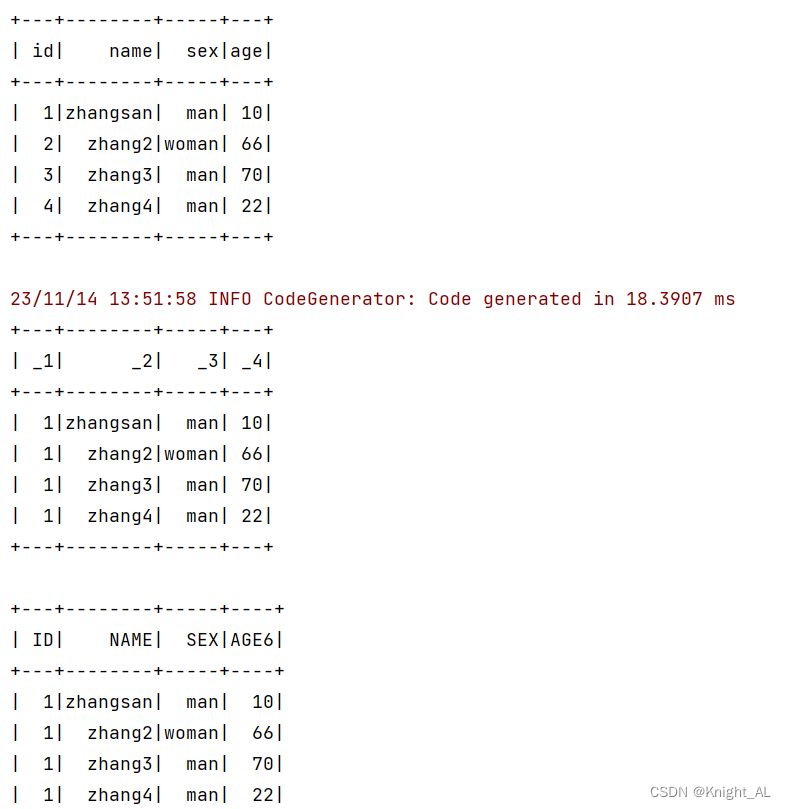
- 集合rdd中元素类型是样例类的时候,转成DataFrame之后列名默认是属性名
- 集合rdd中元素类型是元组的时候,转成DataFrame之后列名默认就是_N
- 集合rdd中元素类型是元组/样例类的时候,转成DataFrame(toDF(“ID”,“NAME”,“SEX”,“AGE6”))可以自定义列名
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.junit.Test
case class Person(id:Int,name:String,sex:String,age:Int)
class TestScala {
val spark = SparkSession
.builder()
.appName("test")
.master("local[4]")
.getOrCreate()
import spark.implicits._
/**
* 通过toDF的方法创建
* 集合rdd中元素类型是样例类的时候,转成DataFrame之后列名默认是属性名
* 集合rdd中元素类型是元组的时候,转成DataFrame之后列名默认就是_N
*/
@Test
def createDataFrameByToDF():Unit={
//TODO 样例类是属性名
val list = List(Person(1,"zhangsan","man",10),Person(2,"zhang2","woman",66),Person(3,"zhang3","man",70),Person(4,"zhang4","man",22))
//需要隐士转换
val df:DataFrame = list.toDF()
df.show()
//TODO 元祖是_N
val list2 = List((1,"zhangsan","man",10),(1,"zhang2","woman",66),(1,"zhang3","man",70),(1,"zhang4","man",22))
//需要隐士转换
val df1:DataFrame = list2.toDF()
df1.show()
//TODO 自定义属性名
val list3 = List((1,"zhangsan","man",10),(1,"zhang2","woman",66),(1,"zhang3","man",70),(1,"zhang4","man",22))
//需要隐士转换
val df2:DataFrame = list3.toDF("ID","NAME","SEX","AGE6")
df2.show()
}
}
结果
通过读取文件创建DataFrame
json数据
{"age":20,"name":"qiaofeng"}
{"age":19,"name":"xuzhu"}
{"age":18,"name":"duanyu"}
/**
* 通过读取文件创建
*/
@Test
def createDataFrame():Unit={
val df = spark.read.json("src/main/resources/user.json")
df.show()
}
通过createDataFrame方法创建DF
@Test
def createDataFrameByMethod():Unit={
val fields = Array(StructField("id",IntegerType),StructField("name",StringType),StructField("sex",StringType),StructField("age",IntegerType))
val schema = StructType(fields)
val rdd = spark.sparkContext.parallelize(List(Row(1, "zhangsan", "man", 10), Row(2, "zhang2", "woman", 66), Row(3, "zhang3", "man", 70), Row(4, "zhang4", "man", 22)))
val df = spark.createDataFrame(rdd, schema)
df.show()
}