文章目录
- I.CONTRIBUTION
- II. ASSUMPTIONS AND THREAT MODEL
- A. Assumptions
- B. Threat Model
- III. SYSTEM DESIGN
- A. Design Overview
- B. Block Design
- C. Initialization
- D. Role Selection
- E. Storage Protocol
- F. Aggregation Protocol
- G. Proof of Reliability
- H. Blockchain Consensus
- IV. SECURITY ANALYSIS
论文地址:https://ieeexplore.ieee.org/abstract/document/10159020
I.CONTRIBUTION
- 提出了轻量级的区块链TORR用于去中心化的联邦学习
- 提出了新的共识协议Proof of Reliablity来过滤掉不可靠的设备,从而减少系统延迟。提出了一种快速聚合算法来执行快速且正确的聚合,进一步降低系统延迟。
- 采用纠删码,高效可靠地存储模型,而区块链账本仅记录模型的哈希值。提出了定期存储刷新策略以进一步减少存储开销。
- 将系统部署在五台服务器上,模拟 100 个节点,并在三种不同的模型上进行测试。实验表明,TORR 可以将系统延迟、整体存储开销和峰值存储开销分别降低高达 62%、75.44% 和 51.77%。
II. ASSUMPTIONS AND THREAT MODEL
A. Assumptions
Federated Learning. 遵循典型联邦学习中的一般假设,TORR假设许多分布式设备愿意联合进行机器学习来训练全局模型。在每一轮训练中,都会选择一部分设备来训练本地模型。然而,没有中央参数服务器。轻量级设备作为存储容量有限、异构连接的节点加入区块链网络。部分节点存在由于网络条件差而响应缓慢或者恶意减缓训练进程的问题,这些节点被视为不可靠节点。
Proof of Reliability. 在TORR中,节点使用PoR就区块链账本的状态达成共识,PoR是基于PoS设计的。PoS 根据节点的stake选举一部分节点作为委员会,委员会成员决定下一个区块的内容。TORR将节点的stake定义为其可靠性的衡量标准,而不是贡献的资金,将一定的stake分配给保持在线并正确快速响应的节点。任意不可靠的行为如网络缓慢或断开连接,都会减少节点的stake。与PoS相同,PoR假设诚实的参与方拥有至少70%的stake。stake的分配情况记录在每个区块中,节点可以通过区块链账本获取stake的分配情况。
B. Threat Model
恶意节点可以通过生成fake节点来增加其比例进行女巫攻击。使用PoS-like协议,恶意节点无法通过简单地增加节点数量来增加其stake。只要不超过30%的stake被恶意节点控制,TORR就可以正常工作。
在存储过程中,恶意节点可以声称存储了一个chunk,但当其他节点请求时总是返回错误的chunk。TORR记录block中每个chunk的哈希值来解决这个问题。当向其他节点请求chunk时,每个节点都可以通过检查存储在区块链中的哈希值来验证该chunk。
恶意节点可以通过缓慢响应或故意不响应任何请求来尝试减慢整个训练过程。在PoR协议中,任何此类行为都将被记录为减少节点stake的证据。随着训练的进行,stake较低的节点将很难被选为委员会成员。
在聚合过程中,多个节点将会被选择为aggregator来进行聚合任务。如果恶意节点拥有aggregator一半以上的stake,则它们可能会主导聚合以获得不正确的全局模型。文章使用评分机制来评估每个节点的可靠性并确定stake的增加或减少。在每一轮中,选定的客户端和aggregator可以对存储chunks的节点进行评分。恶意客户端或aggregator可能会尝试通过提供极高或极低的分数来操纵此过程。为了解决这个问题,方案需要使委员会规模足够大以包含足够的诚实节点。此外还设计了聚合算法和适当的评分规则来防止恶意行为。
III. SYSTEM DESIGN
TORR设计目标如下:(1)系统延迟应与集中式联邦学习相当,并且低于其他基于区块链的联邦学习框架。(2)单个节点的存储需求应比其他基于区块链的联邦学习框架少得多。(3)恶意节点在没有获得足够stake的情况下无法控制系统。
A. Design Overview
TORR中存在三种角色:client、aggregator、keeper。每轮会选择
K
K
K 个clients和
M
M
M 个aggergator来分别进行训练和聚合。参数
K
K
K由发起联邦学习的模型拥有者指定,参数
M
M
M是TORR预先定义的。keepers用于存储模型。通过使用纠删码(erasure coding),无论是本地模型还是全局模型,都应该被编码成
n
n
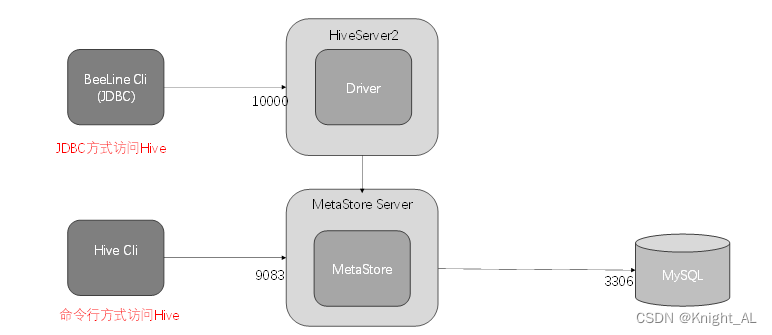
n 个chunks,这些块存储在 $n $ 个选定的keeper中。block由aggregator或模型所有者生成,包含全局模型的哈希值并指示某一轮的开始,第一个block由模型所有者生成以启动联邦学习。TORR框架Fig.1所示。
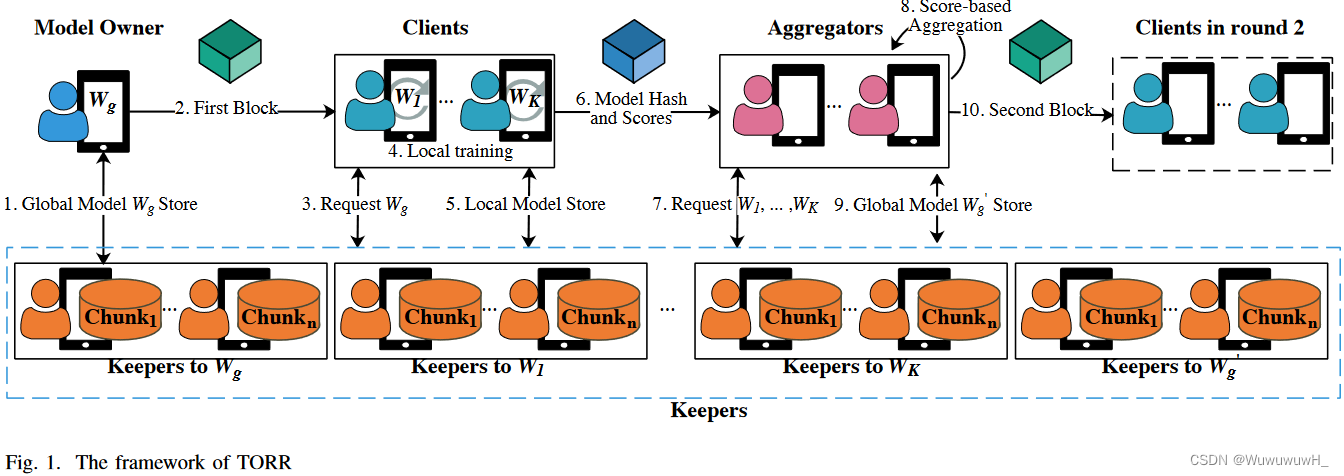
(step 1) 模型拥有者将全局模型编码为 n n n 个chunks,并将他们存储到 n n n 个keepers中。keepers通过VRF和一致性哈希进行选择,将全局模型的哈希值作为VRF的输入。同时,clients和aggregators同样使用前一个块的哈希值进行选择,即将创世块的哈希值作为VRF的输入。
(step 2) 在全局模型存储完毕后,模型拥有者将创建包含模型哈希值的block,并将block进行广播。
(step 3) 当收到block后,每个节点都会检查自身的角色。如果节点该轮为client,它首先会从keepers处请求chunks来恢复全局模型。client将会记录每个keeper的响应延迟,将其作为评分标准。
(step 4) client使用自己的本地数据进行模型训练。
(step 5) 训练完毕后,client会使用本地模型的哈希值作为VRF的输入来选择 n n n 个keepers。本地模型被编码为 n n n 个chunks,并存储在相应的keepers。
(step 6) 任何完成存储操作的client都会将其本地模型的哈希值和记录的延迟传输到aggregators。当一个aggregator收到 K K K 个本地模型的哈希值时,将开始进行聚合操作。
(step 7) aggergator首先向keepers请求chunks来恢复K个本地模型。同时,aggregator会记录每个keeper的响应延迟。然后aggregator将本地模型聚合为新的全局模型。
(step 8) 需要注意的是,恶意的aggregator可能会聚合不正确的全局模型。为保证正确的聚合,文章设计了一种most-stake聚合算法,该算法由Bully选举算法修改而来。Bully算法是一种著名的选举算法,可以帮助高效地在多个节点中选择领导者,但不能容忍恶意节点。如果恶意节点赢得选举,它可以执行错误的聚合或停止运行以暂停该过程。文章添加了验证步骤来保证聚合的正确性,并添加了计时机制来保证算法的效率。Bully 选举算法选择 ID最大的节点作为leader。文章选择stake最多的节点作为leader,以保证区块更有可能由诚实且快速的节点创建。
(step 9) 一旦aggergator(通常是拥有最多stake的节点)赢得选举并成为leader,它将选择新的全局模型的keepers并将新的全局模型存储在这些keepers中。
(step 10) 然后创建包含新全局模型哈希的下一个块并将其传播到其他节点以开始下一轮联邦学习。
B. Block Design
TORR 中的节点通过gossip协议传播区块,以保证网络中的每个节点都会收到新区块。接收者会将收到的块附加到其本地账本中。区块的结构如Fig.2所示。

每个block包含前一个block的哈希值,从而形成一条链。每个块中记录了参数round,当round达到模型所有者在创世块中所指定的数值时,联邦学习进程将会停止。block中还包含一个model object,它包含全局模型的哈希值、chunk的哈希值和所对应keeper的签名。任何节点都能够通过model object中记录的信息知道从哪里获取全局模型。keepers的签名能够保证模型已正确存储,模型的哈希保证了全局模型的正确性。stake distribution 表明每个节点持有多少stake。
VRF proof π通过block共享。有了proof、区块矿工的公钥以及用于生成证明的公共种子(前一个区块哈希或模型哈希),任何人都可以确定性地获得相同的 VRF 哈希输出并验证输出是否有效。VRF 哈希输出与一致性哈希一起用于client和aggregator的选择。此外,一个block最多应包含clients和aggregators提供的 K + M K+M K+M 个分数以及来自aggregator的 j j j 个签名,其中$ j ≥ ⌊M/2⌋ + 1$。这些分数用于更新每个节点的stake。签名是在聚合算法的验证步骤期间提供的,如果包含至少 ⌊ M / 2 ⌋ + 1 ⌊M/2⌋ + 1 ⌊M/2⌋+1 个签名,则块被视为有效。
C. Initialization
联邦学习模型拥有者创建创世块来初始化整个联邦学习过程。文章假设模型所有者是可信的,并且仅在这一步中可信,因此第一个块不包含聚合器的任何签名。此外,第一个块还包含预期的轮数,以便每个节点了解何时停止训练进程。
D. Role Selection
为了防止可能的攻击,TORR中的角色每轮都会发生改变。当aggregator创建新块时,它使用其私钥、前一个块的哈希和模型哈希来选择新的client、aggregator和keeper。角色选择过程如Fig.3所示。

根据一致性哈希,所有可能的哈希形成一个哈希环,从0到 2 32 2^{32} 232。每一块节点的stake都被哈希为位于环上的虚拟节点。节点所拥有的stake的数量不同,虚拟节点的数量也就不同。节点拥有的stake越多,它就会拥有更多的虚拟节点,那么被选中的可能性就更大。在联邦学习的背景下,通常存在大量的设备,从而产生大量的虚拟节点,这些节点将近似均匀地分布在环上。TORR 遵循了 PoS 的特点,即节点被选中的概率等于其拥有的stake比例。
首先,将前一个区块的哈希或者模型哈希输入到VRF中,生成VRF哈希。由于哈希位于环上的一个点,因此将选择顺时针方向的第一个节点。然后计算这个哈希值的哈希值来选择第二个节点。该过程将持续进行,直至选择到所需数量的节点。VRF函数如公式 (1)所示。
![]()
VRF以随机种子
α
\alpha
α和私钥
s
k
sk
sk作为输入,输出确定性哈希
β
\beta
β 和 proof
π
\pi
π。如果输入相同的私钥和种子,则输出相同。对于不知道私钥的人来说,哈希输出
β
\beta
β 看起来与随机变量并无区别。因此,可以将该哈希作为一致性哈希的起点,以公平地选择节点。
其他节点能够通过公式(2)验证哈希输出是否是由具有公钥
p
k
p_k
pk的节点生成的,因此攻击者无法伪造输出。TORR使用前一个块哈希或模型哈希作为输入的随机种子
α
α
α,使用节点
s
k
i
sk_i
ski的私钥作为输入的私钥
s
k
sk
sk。由于输出由
s
k
i
sk_i
ski决定,因此哈希输出
β
β
β 对于每个节点来说是唯一的。在创建块或模型之前,无法知道块哈希和模型哈希,恶意节点无法预测 VRF 的输出并对客户端或聚合器进行目标攻击。
![]()
E. Storage Protocol
Storage Requirement Reduction. 许多设备在联邦学习中闲置,因为每轮只选择其中的一小部分来训练本地模型,因此TORR利用许多闲置设备的有限存储空间来存储模型。考虑到恶意节点的影响和单个设备存储空间有限的问题,采用纠删码将模型划分为多个chunks。一方面,纠删码保证了模型的可用性。方案使用RS code来对模型进行编码。 ( n , k ) (n, k) (n,k) RS code可以将模型总共编码为 n n n 个chunks,并且 n n n 个chunks中的任何 k k k 个都可以用来恢复整个模型。正确设置 k k k 和 n n n 可以保证即使某些节点是恶意的或发生故障,任何节点都可以恢复模型。另一方面,与大尺寸模型的存储相比,小尺寸chunks的存储平均了所有节点上沉重的存储压力。
此外还设计了周期性的存储刷新策略,以避免整体存储的持续扩展。在联邦学习中,全局模型每轮都会更新。因此,在某些场景下,可以将模型存储一段时间后将其删除。具体来说,当节点请求在TORR中存储chunk时,该chunk连同block-tolive (BTL) 参数一起被发送给keeper。BTL是一个整数,表示一个chunk可以存活的轮数或block数。当新块到达时,节点会将所有所存储的chunks的 BTL 减一。任何 BTL 变为零的chunk都允许被删除,通过BTL的定义实现了灵活的存储刷新。
Mitigation of the Impact of Unreliable Devices. 在联邦学习中,轻量级设备通过不同的通信介质(例如 Wifi 或蜂窝网络)访问公共网络。网络中很大概率存在一些网络状况较差的不可靠设备。更严重的情况下,攻击者可以故意缓慢响应甚至不响应,这将威胁模型的可用性。纠删码避免了client和aggregator之间可能出现的不良连接。特别是当多个clients需要将本地模型传输到aggregator时,其中一个客户端与聚合器的连接可能较差。现在aggregator不再从单个client接收整个模型,而是同时从不同的keeper请求多个块。纠删码允许aggregator不等待来自某些stragglers的块,而是仅使用部分chunks来恢复整个模型。
Selection of k k k and n n n of RS Code. TORR 假设了一个更不友好的环境,最多 30% 的stake可能被恶意节点持有。因此通过选择 n n n 和 k k k 来允许 30% 的节点发生故障。
由于TORR使用基于节点stake的一致性哈希,因此节点被选择的概率等于其stake的比例。假设恶意节点持有的stake比例为
p
p
p,至少需要选择
n
n
n 个keepers来存储模型chunks。最多允许
n
−
k
n-k
n−k 个节点失败,因为任何
k
k
k 个块都可以用于恢复模型。由此,可以计算出keepers被恶意节点支配的概率:

考虑到恶意节点最多拥有 30% 的stake,可以通过将
p
p
p 设置为 30% 来获得概率
P
u
p
p
e
r
P_{upper}
Pupper 的上限。实验要求每轮选择10个客户端,整个联邦学习持续100轮。在100轮中,keepers将被选择1100次,以存储100个全局模型和1000个本地模型。因此,上界概率
P
u
p
p
e
r
P_{upper}
Pupper应小于0.0009,以保证系统安全运行。选择
n
n
n 和
k
k
k 时应考虑平衡。如果固定
k
k
k,选择较大的
n
n
n 有助于降低
P
u
p
p
e
r
P_{upper}
Pupper 的概率,但会导致更高的冗余(以
n
/
k
n/k
n/k 衡量)。
F. Aggregation Protocol
为了保证聚合过程中的安全性和防止单点故障,TORR需要多个aggregator共同进行聚合。当aggragator接收到来自所有client的本地模型object和score时,它首先检查签名。有效的本地模型object包含本地模型的哈希值和 n n n 个块的哈希值,通过 n n n 个keepers的签名证明模型已正确存储。然后aggregators将向相应的keeper请求chunks,以准备恢复所有本地模型。
方案只用FedAvg方案进行聚合。假设client i i i 上传的本地模型用 w i w_i wi 表示,client的数据点数量为 n i n_i ni。总共包含K个clients,聚合的全局模型通过公式(4)表示。

由于公式 (4) 由多个加法操作组成,aggregator不需要等待恢复所有本地模型来进行聚合。一旦恢复了新的本地模型,aggregator就会立即计算中间模型。为了在多个aggregator之间达成共识,方案设计了一个根据 Bully 选举算法修改的a most-stake aggregation协议,如Algorithm 1所示。

Timed Election. 当aggregator生成全局模型时,将会向拥有更多stake的aggregator发送选举消息。选举消息是用于检测网络中是否存在另一个aggregator的消息。如果收到对选举消息的任何响应,则aggregator不能成为leader,因为有人拥有更多stake并保持在线。然而,如果拥有最多stake的攻击者成为leader,它可以立即停止运行,然后其他aggregator将永远等待新块。因此,每个aggregator在收到其他aggregators对选举消息的响应后,都会设置一个定时器 T T T。如果 T T T 过期但没有收到进一步的块,则意味着leader可能是攻击者或落后者。aggregators将开始新一次的选举,并将选举消息发送给拥有更多stake的aggregator,但上一次选出的leader除外。
Verification. 定时选举可以保证恶意节点无法故意暂停系统,但不能保证全局模型的正确性。拥有最多stake的恶意节点仍然可以赢得选举,然后在区块中包含不正确的全局模型。因此方案引入了验证步骤以保证正确性。aggregator成为领导者后,应将包含其全局模型哈希的块发送给所有其他aggregators进行验证。如果其他aggregators发现哈希值与其全局模型的哈希值相同,则会对该块进行签名。如果一个区块包含超过一半aggregators的签名,则该区块被视为有效。只要不超过一半的aggregators是恶意的,全局模型就是正确的。
Minimum Size of Aggregator Committee. 应适当选择委员会的大小
M
M
M,以避免委员会被恶意节点控制。如上所述,恶意节点被选择的概率
p
p
p 不超过30%。aggregator被恶意节点控制的概率
P
a
g
r
P_{agr}
Pagr 如下公式(5)所示:

考虑运行联邦学习100轮,聚合器委员会将被选择100次。因此,安全阈值为0.01。委员会的最小规模为26人。
G. Proof of Reliability
文章设计了一种Proof of Reliability共识协议来适应异构网络条件和不可靠的设备。核心是找到一个可信度量来评估每个节点的可靠性。方案使用client或aggregator报告获取的chunks的延迟作为评估的基础。
假设在一轮开始时,全局模型存储在 n n n 个keepers中。当接收到新的block后, K K K 个client将首先向这些keepers请求chunks。在这个过程中,每个client都能够对这 n n n 个keepers打分。该分数等于发起请求和接收回复之间的延迟,这样每个keeper都会拥有 K K K 个分数。使用 S i C j S^{C_j}_i SiCj 来表示client j j j 向keeper i i i 提供的分数。client将分数与本地模型的哈希值一起发送给aggregator。
为了执行聚合,每个aggregator需要向这些本地模型的keepers请求chunks。在这个过程中,每个aggregator会为最多 n K nK nK 个keepers进行评分,使用$ S^{A_j}_i $来表示aggregator j j j 为 keeper i i i 所评价的分数。每个aggregator都会将其分数发送给所有其他aggregators。那么所有aggregators都会获得本轮产生的所有分数,包括来自clients的 n K nK nK 个分数和来自aggregator的 n K M nKM nKM 个分数。
如果某个keeper在某一轮中被挑选存储所有模型,它会获得 K + K M {K+KM} K+KM个分数。如果keeper仅被挑选一次来存储全局模型,那么它会获得 K K K 个分数。最终使用某个keeper所有得分的中位数作为指标来评估其可靠性,如公式(6)所示。
![]()
如上所述,假设恶意节点所持stake不超过 30%,则保证诚实方占多数的委员会的最小规模为 26。因此,TORR 仅当收到超过 26 个节点的分数时才会调整节点的stake。stake更新公式如 (7) 所示。

因此,能够快速响应的可靠节点将拥有更多的stake。更新后的stake包含在新区块中,新区块将在most-stake aggregation验证步骤中进行验证。如果leader捏造分数,会立即被其他aggregator检测到,并且该区块无法被验证。
H. Blockchain Consensus
TORR中没有分叉。由于client和aggregator是通过 VRF 和使用前一个块哈希作为输入的一致性哈希来选择的,因此所有节点应该在一轮中观察到相同的client和aggregator。只有一个aggregator将被选为leader来创建下一个块,并且该块应由大多数aggregator验证。因此,该区块不存在争议。
IV. SECURITY ANALYSIS
恶意的client可能会发送伪造的本地模型来毒害全局模型,并故意给keeper高分或低分。第一个问题文章不做讨论。第二个问题,如果少于 26 个节点对相同的 keeper 进行评分,则来自client的评分将不会被信任和使用,因为在这种情况下恶意节点可能占大多数。如果节点较多,则使用分数的中位数来防止恶意节点的影响。
恶意的keeper可能声称存储了一个chunk,但是删除了该chunk或者修改了一个块。第一种行为破坏了模型的可用性。但通过RS code的正确选择,能够保证可以从诚实的keeper获得n个块中的k个来恢复模型。即使所有恶意模型都不存储chunks,也能够恢复该模型。第二种行为威胁模型的正确性。通过记录块中每个chunk的哈希值,以便任何节点都可以通过比较哈希值来验证chunk。如果恶意keeper返回了错误的哈希值,它将立即被检测到。
恶意的aggregator可能会伪造一个不正确的全局模型,并故意给keeper高分或低分。第一个问题通过most-stake aggregattion中的验证操作解决。第二个问题通过使用中位数而不是平均分数来评估keeper来解决。