现在接到一个LLM模型任务,第一反应就是能不能通过精调prompt来实现,因为使用prompt不需要训练模型,只需输入指令就可以实现和LLM的交互。按照以往经验,不同的prompt对模型输出影响非常大,如果能构造一个好的prompt,往往可以达到事半功倍的效果。下面总结了目前我经常使用的一些构建prompt的技巧。
1. prompt要素
一个prompt主要有如下一些要素:
指令:想要模型执行特定任务的描述。
上下文:包含外部信息(如知识库)或额外的上下文信息。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。可以不指定,因为很多模型其实性能有限,不一定按照你指定的格式输出。
这里给出一篇prompt构造的参考文献:https://github.com/mattnigh/ChatGPT3-Free-Prompt-List
其遵循CRISPE提示框架:
Capacity and Role: What role (or roles) should ChatGPT act as?
Insight: Provides the behind the scenes insight, background, and context to your request.
Statement: What you are asking ChatGPT to do.
Personality: The style, personality, or manner you want ChatGPT to respond in.
Experiment: Asking ChatGPT to provide multiple examples to you.
给个例子:

2. 设计prompt通用技巧
2.1 关于prompt的调试经验
- 从简单的提示词开始,不断迭代和实验,比如添加上下文,或者将任务拆解
- 明确指令,一般需要将指令放在开头,并用清晰的分隔符区分(在调试过程发现,LLM对分隔符会有理解能力)
- 避免不精确,使用3到5句话就应该把任务说清楚
- 由易到难尝试使用prompt技术,如从zero-shot到few-shot甚至到最后的SFT
2.2 模型设置
目前一般的LLM都提供了和模型参数相关的一些接口,可以控制模型生成的多样性或者最大上下文长度。主要是调整以下的两个参数:
Temperature:范围是0-1,简单来说,temperature越小,模型输出越确定(准确)。temperature越大,返回结果更随机,也就是说这可能会带来更多样化或更具创造性的产出。在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,你可以适当调高 temperature 参数值。
Top_p:使top_p(与 temperature一起称为核采样的技术),可以控制模型返回结果的真实性。如果你需要准确和事实的答案,就把参数值调低。如果你想要更多样化的答案,就把参数值调高一些。
一般建议是改变其中一个参数就行,不用两个都调整。
2.3 prompt技术
2.3.1 Zero shot
零样本prompt,说白了就是想让LLM完成某个任务但是却不给LLM参考的样例,直接让模型生成答案。这种方法往往比较简单,仅仅使用一两句话描述任务和问题即可。
2.3.2 Few shot
这个与Zero shot对应,Few shot 在构建提示词的时候会给模型一些参考的样例。个人认为Few shot是一种非常有效的提示方式,模型可以从你给出的样例中学习到特定的范式或者知识,让模型可以更好地输出你想要的回复。
当然,few shot也有一些局限性:
- 多数标签的偏见(majority label bias):few-shot例子中所提供的标签如果分布不平衡,则会严重影响到测试任务。这个非常好理解:是传统的不平衡学习(imbalanced learning)在prompt上的具体体现。
- 近期偏见(recency bias):模型倾向于为测试样本输出最近看到的few-shot样本。这个听上去有点像灾难遗忘,即模型更喜欢记住最近输入的样本信息。
- 公共token偏见(common token bias):模型倾向于考虑那些出现次数较多的token。这个也比较好理解。因为大模型本质上就是统计模型,当然倾向于出现次数多的那些词。
2.3.3 思维链COT
思维链技术意思是使用特定的步骤设定,引导模型输出和思考。研究表明,使用COT技术能明现提升模型对运算或复杂问题处理的能力。往往会加上一句 let’s think step by step。
一般会结合few shot使用,就是few shot的时候告诉模型,我在解决这一类问题的时候会先这么做,然后这么做,最后这么做,最后模型就会模仿你的思考方式来解决新的问题。[1]
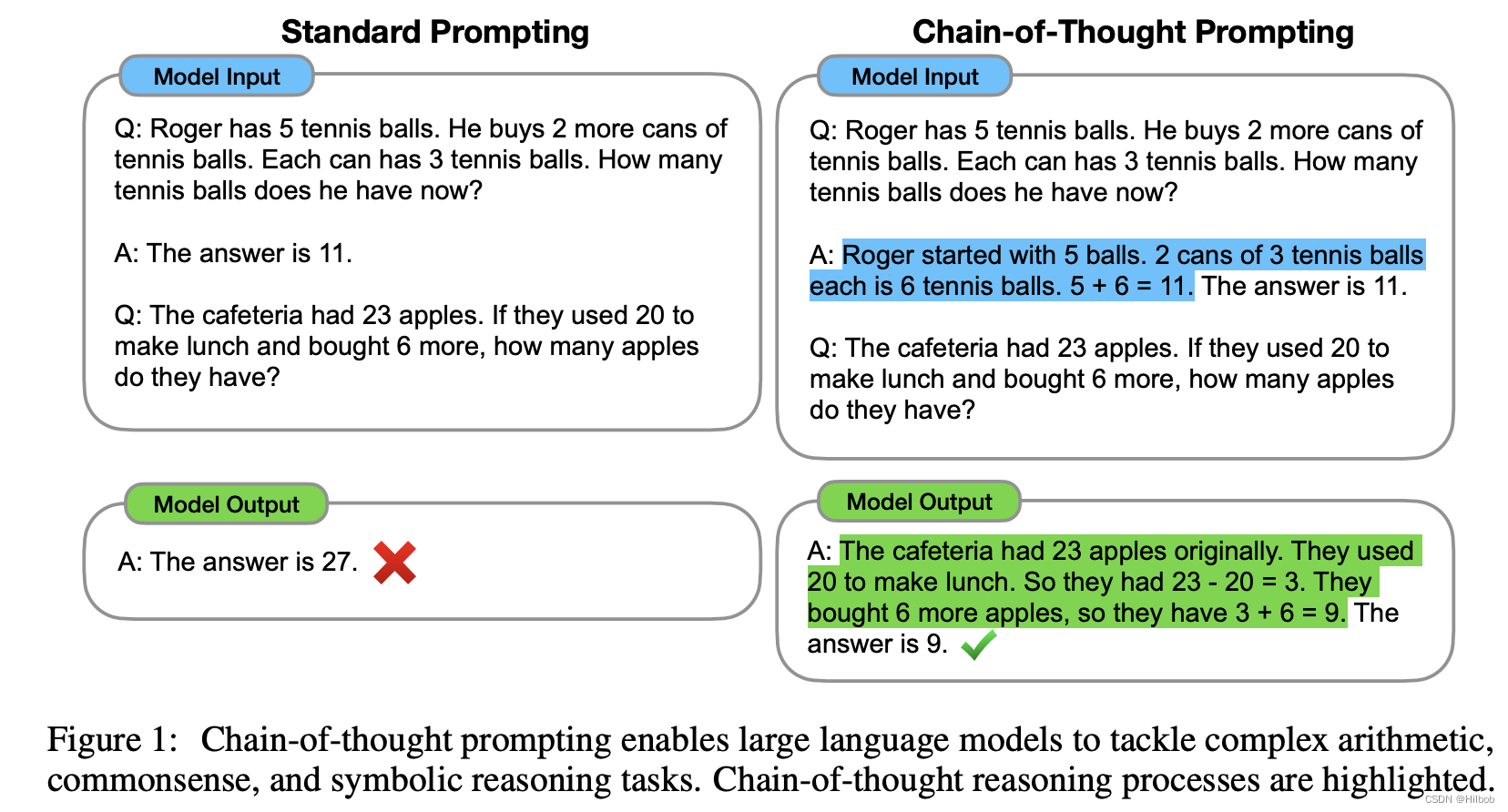
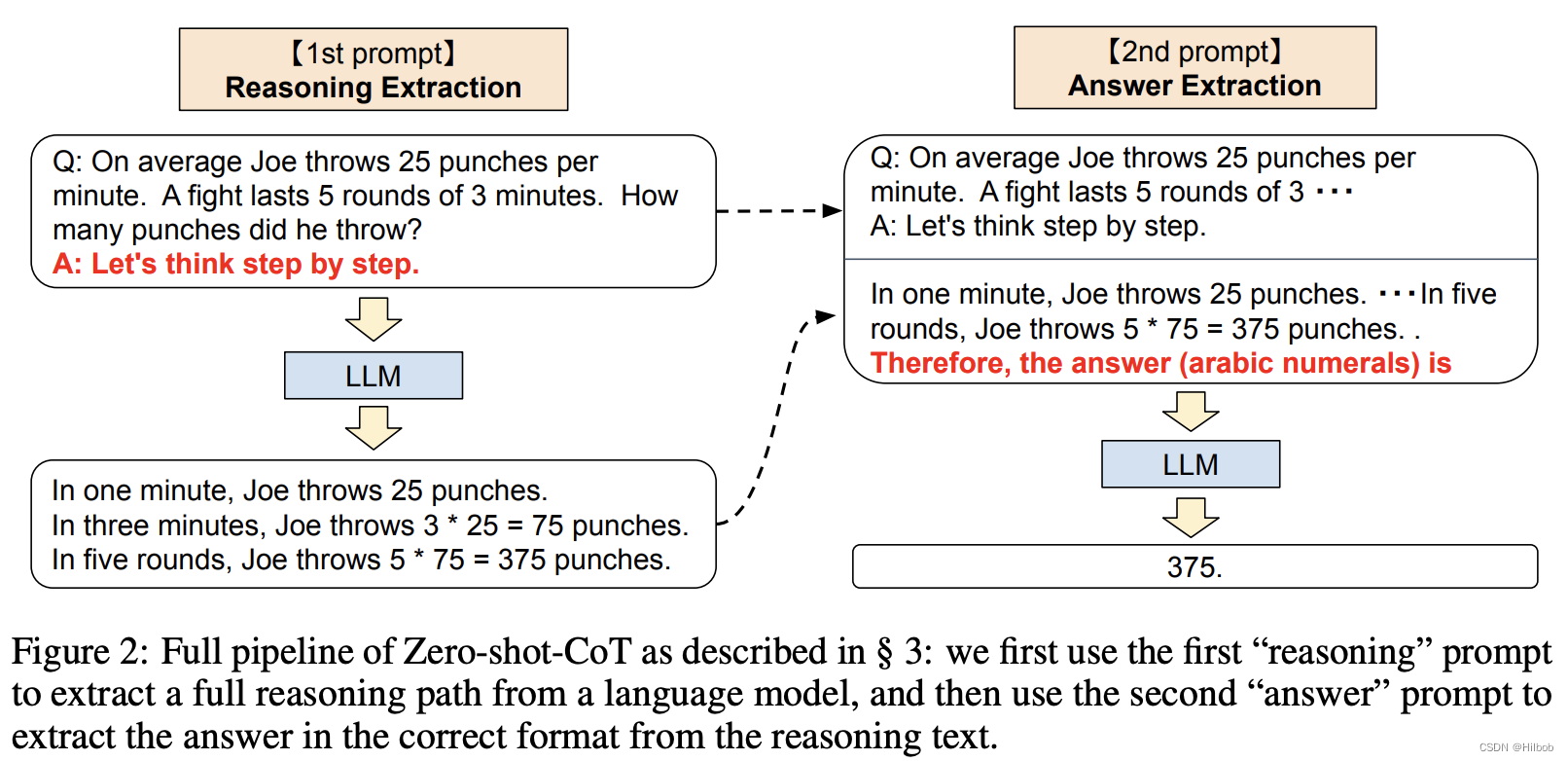
当然你也可以zero shot,加一句魔法词let’s think step by step或其他你能想到的能引导模型分步骤思考和输出的prompt。[2]
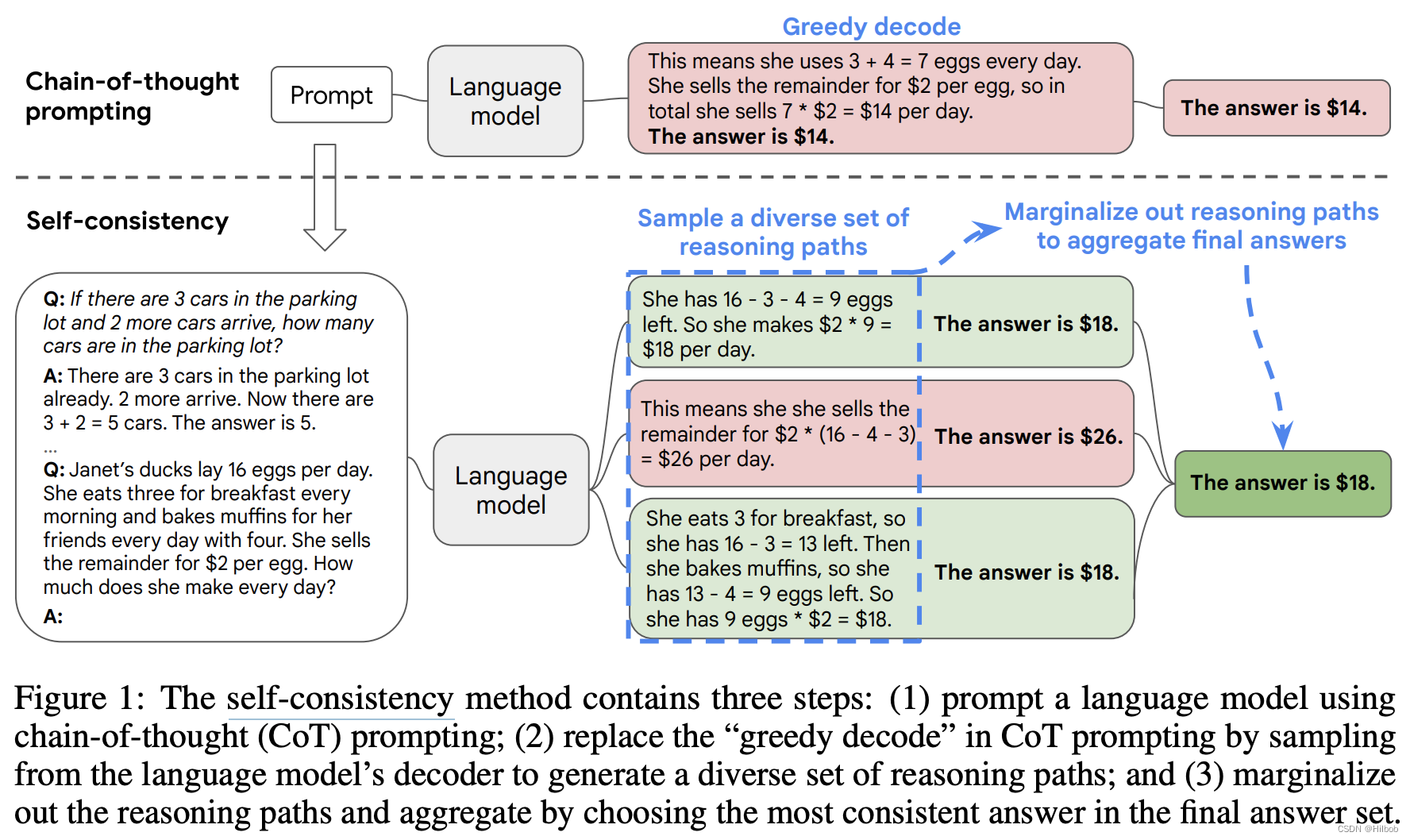
2.3.4 自我一致性 self-consistency[3]
说白了就是单一一条思维链COT的结果可能还是有问题的,这里让模型按照思维链的方式多,生成几个结果,然后取多数出现的结果作为最终结果
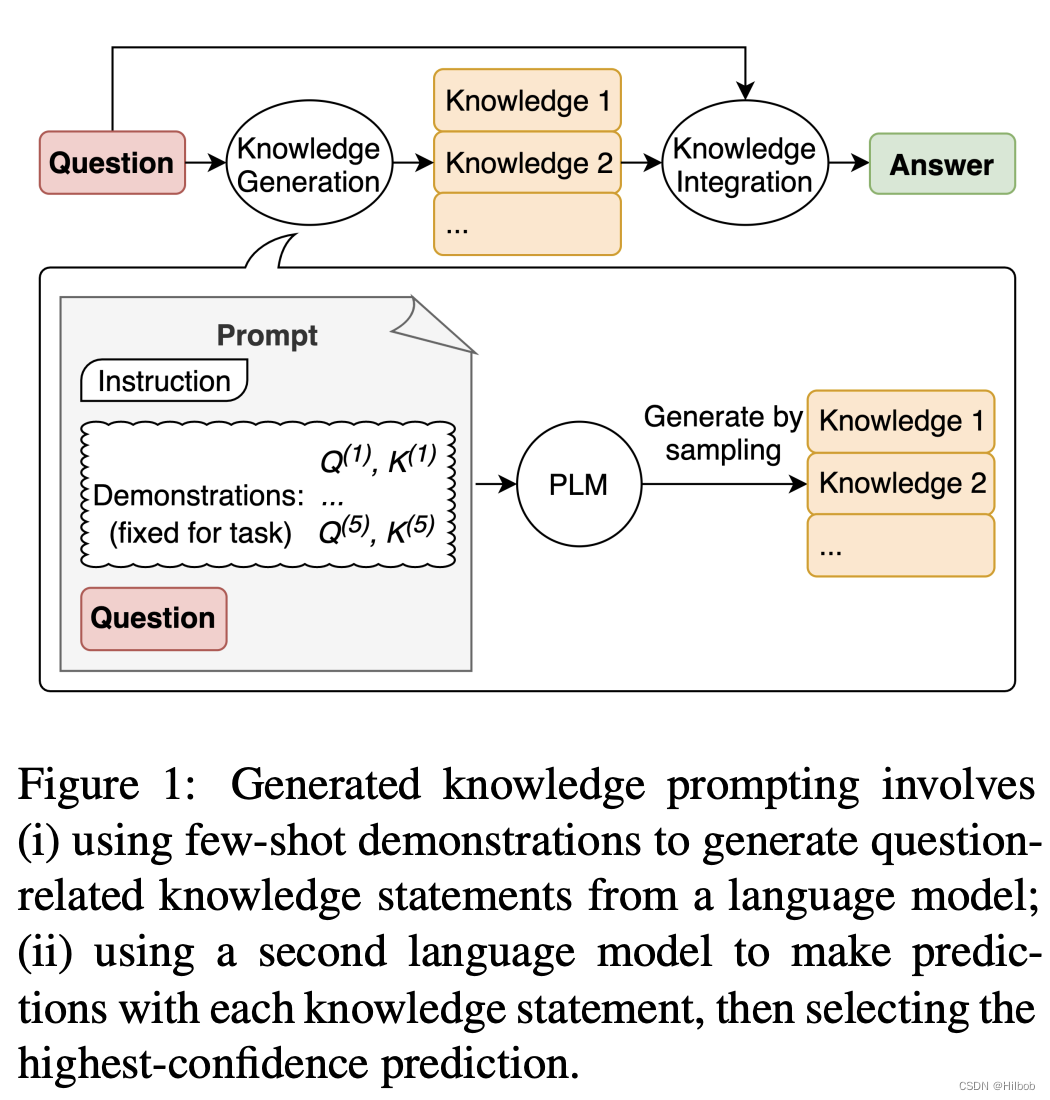
2.3.5 生成知识提示[4]
简单来说,就是让模型先对问题生成一些相关的知识点,然后将这些知识作为另一个LLM的输入,最终生成答案。
2.3.6 提示学习
这部分内容就更高级了,因为涉及到模型的训练。
参考一篇综述[5],以LLM是否微调、prompt是否微调为标准,可以将prompt tuning分为以下5个方面:
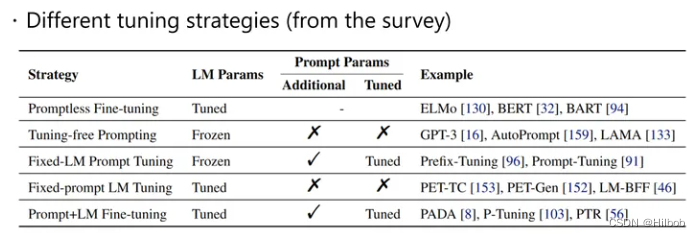
Promptless fine-tuning: 不使用prompt、直接微调语言模型。
Tuning-free prompting: 无需微调的prompt。
Fixed-LM prompt tuning: 固定LM,微调prompt。这种最为常用。
Fixed-prompt LM tuning: 固定prompt,微调LM。
Prompt+LM fine-tuning: 两部分一起微调
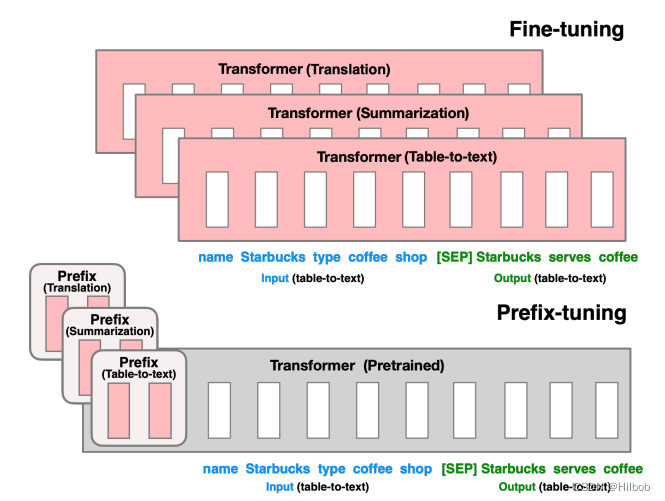
Prefix-tuning[6]
由斯坦福大学的Percy Liang团队提出,其在LLM的输入层中加入可学习的prompt embedding,即在文段开头引入连续的前缀向量,固定住LLM的权重,专门只微调prompt部分参数。
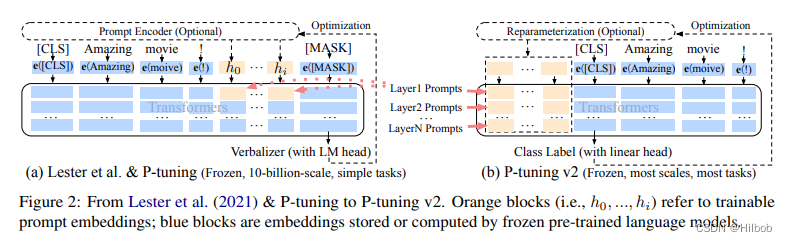
P-tuning[7]
数据集往往是{prompt,input,output}的形式,思想是专门对于输入的prompt部分,将其转换成相应的token embedding去训练优化,最后的embedding通过训练迭代确定的,这相当于在连续空间中去学习一个prompt。
参考文献
[1]Wei, Jason, et al. “Chain of thought prompting elicits reasoning in large language models.” arXiv preprint arXiv:2201.11903 (2022).NeurIPS 2022. 2.
[2]Kojima, Takeshi, et al. “Large language models are zero-shot reasoners.” arXiv preprint arXiv:2205.11916 (2022).NeurIPS 2022.
[3]Wang, Xuezhi, et al. “Self-consistency improves chain of thought reasoning in language models.” arXiv preprint arXiv:2203.11171 (2022). ICLR 2023
[4]Liu, Jiacheng, et al. “Generated knowledge prompting for commonsense reasoning.” arXiv preprint arXiv:2110.08387 (2021). ACL2022
[5]Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1-35.
[6]Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[7]Liu X, Ji K, Fu Y, et al. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022: 61-68.