使用grad-cam对ViT的输出进行可视化
文章目录
- 使用grad-cam对ViT的输出进行可视化
- 前言
- 原理
- 使用代码
- Pytorch-grad-cam库的更多方法
- 在MMpretrain中使用
- 示例
- 总结
前言
Vision Transformer (ViT) 作为现在CV中的主流backbone,它可以在图像分类任务上达到与卷积神经网络 (CNN) 相媲美甚至超越的性能。ViT 的核心思想是将输入图像划分为多个小块,然后将每个小块作为一个 token 输入到 Transformer 的编码器中,最终得到一个全局的类别 token 作为分类结果。
ViT 的优势在于它可以更好地捕捉图像中的长距离依赖关系,而不需要使用复杂的卷积操作。然而,这也带来了一个挑战,那就是如何解释 ViT 的决策过程,以及它是如何关注图像中的不同区域的。为了解决这个问题,我们可以使用一种叫做 grad-cam 的技术,它可以根据 ViT 的输出和梯度,生成一张热力图,显示 ViT 在做出分类时最关注的图像区域。
原理
grad-cam对ViT的输出进行可视化的原理是利用 ViT 的最后一个注意力块的输出和梯度,计算出每个 token 对分类结果的贡献度,然后将这些贡献度映射回原始图像的空间位置,形成一张热力图。具体来说,grad-cam+ViT 的步骤如下:
-
给定一个输入图像和一个目标类别,将图像划分为 14x14 个小块,并将每个小块转换为一个 768 维的向量。在这些向量之前,还要加上一个特殊的类别 token ,用于表示全局的分类信息。这样就得到了一个 197x768 的矩阵,作为 ViT 的输入。
-
将 ViT 的输入通过 Transformer 的编码器,得到一个 197x768 的输出矩阵。其中第一个向量就是类别 token ,它包含了 ViT 对整个图像的理解。我们将这个向量通过一个线性层和一个 softmax 层,得到最终的分类概率。
-
计算类别 token 对目标类别的梯度,即 ∂ y c ∂ A \frac{\partial y_c}{\partial A} ∂A∂yc ,其中 y c y_c yc 是目标类别的概率, A A A 是 ViT 的输出矩阵。这个梯度表示了每个 token 对分类结果的重要性。
-
对每个 token 的梯度求平均值,得到一个 197 维的向量 w w w ,其中 w i = 1 Z ∑ k ∂ y c ∂ A i k w_i = \frac{1}{Z}\sum_k \frac{\partial y_c}{\partial A_{ik}} wi=Z1∑k∂Aik∂yc , Z Z Z 是梯度的维度,即 768 。这个向量 w w w 可以看作是每个 token 的权重。
-
将 ViT 的输出矩阵和权重向量相乘,得到一个 197 维的向量 s s s ,其中 s i = ∑ k w k A i k s_i = \sum_k w_k A_{ik} si=∑kwkAik 。这个向量 s s s 可以看作是每个 token 对分类结果的贡献度。
-
将贡献度向量 s s s 除去第一个元素(类别 token ),并重塑为一个 14x14 的矩阵 M M M ,其中 M i j = s ( i − 1 ) × 14 + j + 1 M_{ij} = s_{(i-1) \times 14 + j + 1} Mij=s(i−1)×14+j+1 。这个矩阵 M M M 可以看作是每个小块对分类结果的贡献度。
-
将贡献度矩阵 M M M 进行归一化和上采样,得到一个与原始图像大小相同的矩阵 H H H ,其中 H i j = M i j − min ( M ) max ( M ) − min ( M ) H_{ij} = \frac{M_{ij} - \min(M)}{\max(M) - \min(M)} Hij=max(M)−min(M)Mij−min(M) 。这个矩阵 H H H 就是我们要求的热力图,它显示了 ViT 在做出分类时最关注的图像区域。
-
将热力图 H H H 和原始图像进行叠加,得到一张可视化的图像,可以直观地看到 ViT 的注意力分布。
使用代码
import argparse
import cv2
import numpy as np
import torch
from pytorch_grad_cam import GradCAM, \
ScoreCAM, \
GradCAMPlusPlus, \
AblationCAM, \
XGradCAM, \
EigenCAM, \
EigenGradCAM, \
LayerCAM, \
FullGrad
from pytorch_grad_cam import GuidedBackpropReLUModel
from pytorch_grad_cam.utils.image import show_cam_on_image, \
preprocess_image
from pytorch_grad_cam.ablation_layer import AblationLayerVit
# 加载预训练的 ViT 模型
model = torch.hub.load('facebookresearch/deit:main',
'deit_tiny_patch16_224', pretrained=True)
model.eval()
# 判断是否使用 GPU 加速
use_cuda = torch.cuda.is_available()
if use_cuda:
model = model.cuda()
接下来,我们需要定义一个函数来将 ViT 的输出层从三维张量转换为二维张量,以便 grad-cam 能够处理:
def reshape_transform(tensor, height=14, width=14):
# 去掉类别标记
result = tensor[:, 1:, :].reshape(tensor.size(0),
height, width, tensor.size(2))
# 将通道维度放到第一个位置
result = result.transpose(2, 3).transpose(1, 2)
return result
然后,我们需要选择一个目标层来计算 grad-cam。由于 ViT 的最后一层只有类别标记对预测类别有影响,所以我们不能选择最后一层。我们可以选择倒数第二层中的任意一个 Transformer 编码器作为目标层。在这里,我们选择第 11 层作为示例:
# 创建 GradCAM 对象
cam = GradCAM(model=model,
target_layer=model.blocks[5],
use_cuda=use_cuda,
reshape_transform=reshape_transform)
接下来,我们需要准备一张输入图像,并将其转换为适合 ViT 的格式:
# 读取输入图像
image_path = "cat.jpg"
rgb_img = cv2.imread(image_path, 1)[:, :, ::-1]
rgb_img = cv2.resize(rgb_img, (224, 224))
# 预处理图像
input_tensor = preprocess_image(rgb_img,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 将图像转换为批量形式
input_tensor = input_tensor.unsqueeze(0)
if use_cuda:
input_tensor = input_tensor.cuda()
最后,我们可以调用 cam 对象的 forward 方法,传入输入张量和预测类别(如果不指定,则默认为最高概率的类别),得到 grad-cam 的输出:
# 计算 grad-cam
target_category = None # 可以指定一个类别,或者使用 None 表示最高概率的类别
grayscale_cam = cam(input_tensor=input_tensor,
target_category=target_category)
# 将 grad-cam 的输出叠加到原始图像上
visualization = show_cam_on_image(rgb_img, grayscale_cam)
# 保存可视化结果
cv2.imwrite('cam.jpg', visualization)
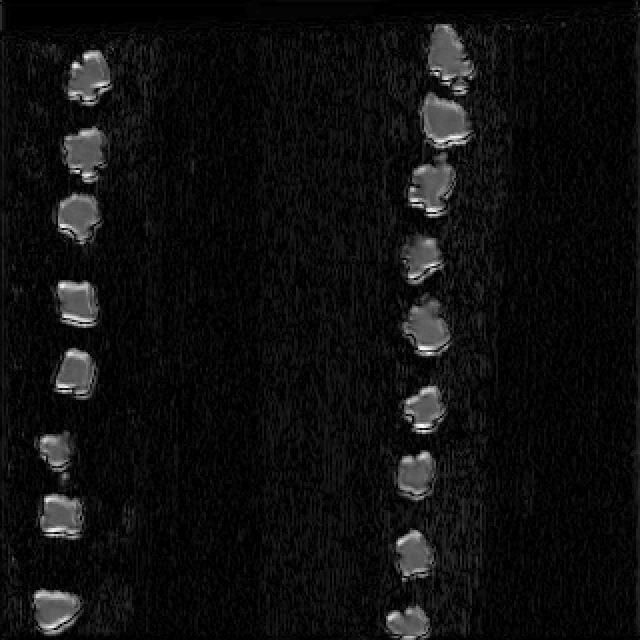
这样,我们就完成了使用 grad-cam 对 ViT 的输出进行可视化的过程。我们可以看到,ViT 主要关注了图像中的猫的头部和身体区域,这与我们的直觉相符。通过使用 grad-cam,我们可以更好地理解 ViT 的工作原理,以及它对不同图像区域的重要性。
Pytorch-grad-cam库的更多方法
除了经典的grad-cam,库里目前支持的方法还有:
| Method | What it does |
|---|---|
| GradCAM | 使用平均梯度对 2D 激活进行加权 |
| GradCAM++ | 类似 GradCAM,但使用了二阶梯度 |
| XGradCAM | 类似 GradCAM,但通过归一化的激活对梯度进行了加权 |
| EigenCAM | 使用 2D 激活的第一主成分(无法区分类别,但效果似乎不错) |
| EigenGradCAM | 类似 EigenCAM,但支持类别区分,使用了激活 * 梯度的第一主成分,看起来和 GradCAM 差不多,但是更干净 |
| LayerCAM | 使用正梯度对激活进行空间加权,对于浅层有更好的效果 |
这里给出MMpretrain提供的对比示例:

在MMpretrain中使用

如果你刚好在用MMpretrain,那么有着方便的脚本文件来帮助你更加方便的进行上面的工作,具体可见:类别激活图(CAM)可视化 — MMPretrain 1.0.0rc7 文档

示例
这里也放一些我自己试过的例子:
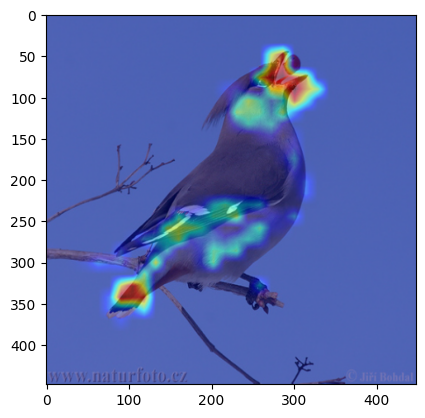
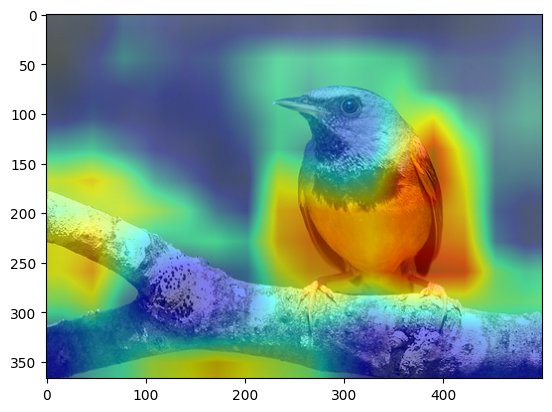
总结
通过使用 grad-cam,我们可以更好地理解 ViT 的工作原理,以及它是如何从图像中提取有用的特征的。grad-cam 也可以用于其他基于 Transformer 的模型,例如DeiT、Swin Transformer 等,只需要根据不同的模型结构和输出,调整相应的计算步骤即可。