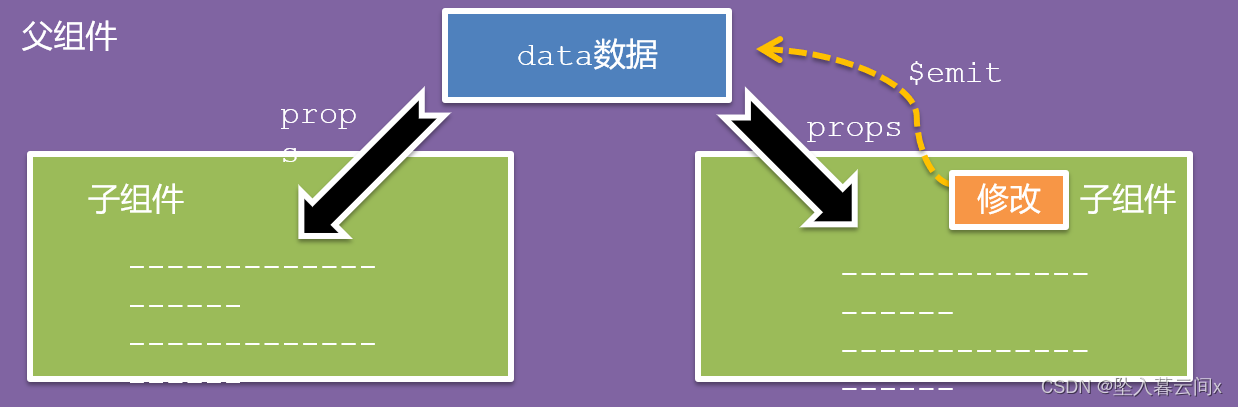
在实际的工作中,我们不免需要对SQL预计进行分析和优化,今天我们就来一起看下相关内容:
-
SQL性能分析
-
SQL优化原则
1 SQL性能分析
对SQL进行性能分析,主要有:
-
查看慢SQL
-
通过profile详情查看
-
explain执行计划
1.1 查看慢SQL
SQL执行频率
-- 查看系统的状态,7个_
show global status like 'Com_______';慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认是10秒)的所有的SQL语句的日志。MySQL的慢查询日志默认没有开启,需要在配置文件中加入。
-- 查看慢查询日志是否开启
show variables like 'show_query_log';开启慢查询的配置,在配置文件中增加:
# 开启慢SQL的开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会被记录
long_query_time=2慢查询日志记录的信息在/var/lib/mysql/localhost-slow.log。我用docker启动的MySQL的地址和上边不一样:
运行SQL,制造慢SQL
select sleep(5);查看慢SQL的日志:
[root@VM-24-10-centos data]# cat a5cbd50ec8f4-slow.log
/usr/sbin/mysqld, Version: 8.0.27 (MySQL Community Server - GPL). started with:
Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 2023-07-27T09:03:10.516956Z
# User@Host: root[root] @ [114.242.22.4] Id: 9
# Query_time: 5.000289 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
use test;
SET timestamp=1690448585;
/* ApplicationName=DataGrip 2018.1.3 */ select sleep(5);1.2 通过profile详情查看
通过profile查看最近执行的SQL情况
-- 查看profile是否支持
select @@have_profiling;
-- 查看profile是否开启
select @@profiling;
-- 设置开启
set profiling = 1;
-- 查询
select *
from test.user;
-- 查询
select *
from test.user where name ='张三';
select count(*) from user;
-- profiling_history_size的最大取值范围为[0,100]
set profiling_history_size = 100;
-- 查看当前所有执行的SQL
show profiles;
-- 通过Query_ID查询SQL执行详情
show profile for query 455;1.3 explain执行计划查看
explain或者desc命令获取MySQL如何执行select语句的信息,包括select语句执行过程中表如何连接和连接的顺序。
explain select * from test.user where name ='张三';
各个字段含义
-
id,查看该查询各个子句的执行顺序
-
select查询的序列号,表示查询中执行select子句或者操作表的顺序(id相同,执行顺序从上到下;id不同,id越大,越先执行)。
-
-
select_type,查看查询类型,一般不用关注
-
表示select的类型,simple(简单表,即不使用表连接或者子查询)、primary(主查询,即外层的查询)、union(union中的第二个或者后边的查询语句)、subquery(select/where之后包含了子查询)
-
-
type,连接类型,需要重点关注
-
表示连接类型,性能由好到差的连接类型为null、system、const、eq_ref、ref、range、index、all。
-
-
possible_key
-
显示可能应用在这张表上的索引,一个或者多个
-
-
Key,实际用到的索引,需要重点关注
-
实际使用的所有,如果为null,则没有使用索引
-
-
key_len,实际使用所有的字节数,需要重点关注
-
表示索引中使用的字节数,该值为索引字段最大可能的长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
-
-
rows
-
MySQL认为必须要执行的查询的行数,在InnoDB中是一个估计值,该值越小越好
-
-
filtered,需要重点关注
-
表示返回结果的行数占需读取行数的百分比,该值越大越好
-
-
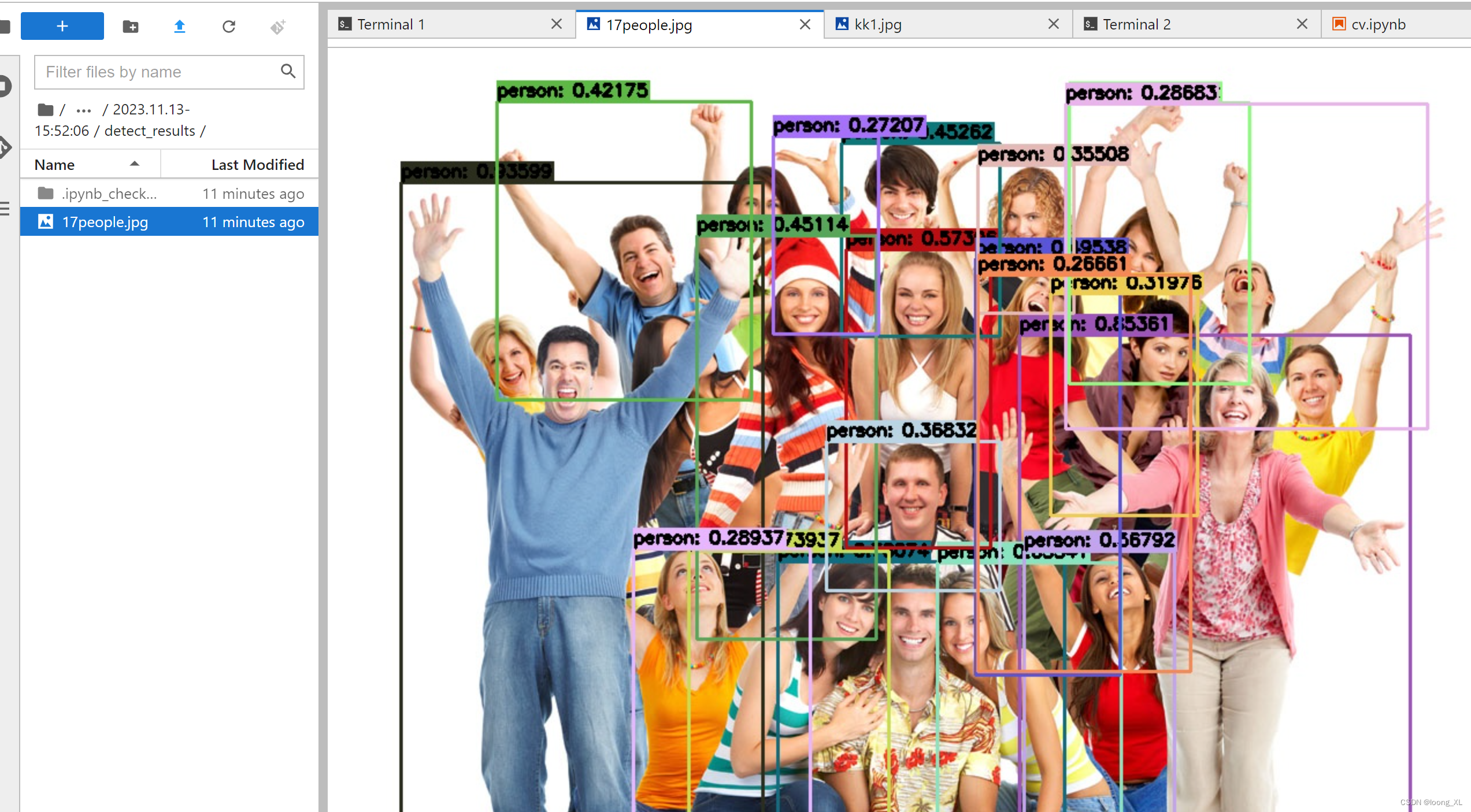
Extra,执行计划的额外说明,包含重要信息
| id | type value | Meaning |
| 1 | const row not found | 所要查询的表为空 |
| 2 | Distinct | mysql正在查询distinct值,因此当它每查到一个distinct值之后就会停止当前组的搜索,去查询下一个值 |
| 3 | Impossible WHERE | where条件总为false,表里没有满足条件的记录 |
| 4 | Impossible WHERE noticed after reading const tables | 在优化器评估了const表之后,发现where条件均不满足 |
| 5 | no matching row in const table | 当前join的表为const表,不能匹配 |
| 6 | Not exists | 优化器发现内表记录不可能满足where条件 |
| 7 | Select tables optimized away | 在没有group by子句时,对于MyISAM的select count(*)操作,或者当对于min(),max()的操作可以利用索引优化,优化器发现只会返回一行。 |
| 8 | Using filesort | 使用filesort来进行order by操作 |
| 9 | Using index | 覆盖索引 |
| 10 | Using index for group-by | 对于group by列或者distinct列,可以利用索引检索出数据,而不需要去表里查数据、分组、排序、去重等等 |
| 11 | Using join buffer | 之前的表连接在nested loop之后放进join buffer,再来和本表进行join。适用于本表的访问type为range,index或all |
| 12 | Using sort_union,using union,using intersect | index_merge的三种情况 |
| 13 | Using temporary | 使用了临时表来存储中间结果集,适用于group by,distinct,或order by列为不同表的列。 |
| 14 | Using where | 在存储引擎层检索出记录后,在server利用where条件进行过滤,并返回给客户端 |
2 SQL优化原则
2.1 插入数据
2.1.1 insert 优化
-
批量插入,减少建立连接。不建议批量插入超过1000条
-
手动提交事务,在执行insert之前,开启事务,insert数据之后,手动commit
-
主键顺序插入
insert into user values(1,'小米'),(2,'小孩'),(3,'小红');
-- 开启事务
-- 也可以使用begin
start transaction;
-- 插入操作
insert into user values(1,'小米'),(2,'小孩'),(3,'小红');
insert into user values(4,'小米1'),(5,'小孩1'),(6,'小红1');
-- 提交
commit;2.1.2 大批量插入数据
如果一次性需要插入大批量数据,使用load指令进行插入

新建数据库表,准备给该表出入数据
drop table if exists user;
create table user (
id int primary key auto_increment,
name varchar(20) not null,
age int not null,
city varchar(20) default null
);使用Java代码生成需要导入的批量数据文件
package com.wmding;
import java.io.*;
import java.util.ArrayList;
import java.util.Random;
/**
* @author 明月
* @version 1.0
* @date 7/29/23 9:50 AM
* @description:
*/
public class WriteFile {
public static void main(String[] args) throws IOException {
ArrayList cityList = new ArrayList();
cityList.add("北京");
cityList.add("上海");
cityList.add("广州");
cityList.add("郑州");
File file = new File("/Users/wmding/WorkSpaces/My/ThreadDemo/src/main/java/com/wmding/data.log");
if (!file.exists()) {
file.createNewFile();
} else {
file.delete();
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file);
int num = 1000000;
// int num = 10;
// 1,sexe,10,sexeee
for (int i = 1; i <= num; i++) {
StringBuffer sb = new StringBuffer();
sb.append(i);
sb.append(',');
String randomStr1 = createRandomStr1(6);
sb.append(randomStr1);
sb.append(',');
int age = creatRandom();
sb.append(age);
sb.append(',');
int index = i % 2;
sb.append(cityList.get(index));
System.out.println(sb.toString());
fileWriter.write(sb.toString());
// Add a new line after writing the content
fileWriter.write("\n");
}
fileWriter.close();
}
/**
* 生成的字符串每个位置都有可能是str中的一个字母或数字
*/
private static String createRandomStr1(int length) {
String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random = new Random();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < length; i++) {
int number = random.nextInt(62);
stringBuffer.append(str.charAt(number));
}
return stringBuffer.toString();
}
private static int creatRandom() {
Random random = new Random();
// 生成大于1小于100的随机数
int randomNumber = random.nextInt(98) + 2;
return randomNumber;
}
}将数据文件上传到服务器
复制数据文件到MySQL容器内部的/test目录下
docker cp data.log a5cbd50ec8f4:/test/data.log
进入MySQL容器内部
docker exec -it 5d5ab079a223 bash导入数据,导入100万条数据,耗时5.64秒
-- 使用--local-infile模式进入数据库
mysql -uroot -p --local-infile
-- 设置local_infile为1
mysql> set global local_infile = 1;
-- 导入数据
mysql> load data local infile '/test/data.log' into table user fields terminated by ',' lines terminated by '\n';
Query OK, 1000000 rows affected (5.64 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 0
2.2 主键优化
2.2.1 数据的组织方式
在InnoDB存储引擎中,表数据是根据主键顺序组织存放的,这种存储方式的表称为是索引组织表(index organization table,缩写IOT)。
-
非叶子节点存放的是索引
-
叶子节点存放的是索引和数据
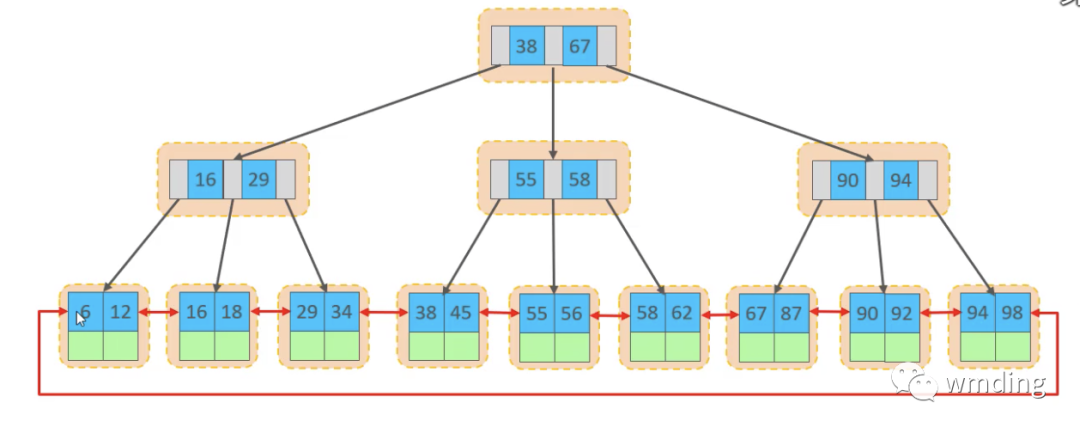
2.2.2 页分裂
不同的插入方式导致效率不同
-
主键顺序插入时,主键按照顺序放入页(page)中
-
主键乱序插入时,由于顺序不确定,所以会使在插入过程中,先找到合适的位置,然后插入。原来插入的数据进行页分裂
2.2.3 页合并
当删除一行数据时,实际上记录并没有被物理删除,只是被标记为删除并且它的空间变成允许被使用。
当页中的删除记录达到merge_threshold(默认为页的50%),InnoDB会进行页合并以优化空间使用。
2.4 主键的设计原则
-
满足业务需求的情况下,尽量降低主键的长度,减少查询时磁盘IO
-
插入数据时,尽量选择顺序插入,选择使用 auto_increment自增主键,避免页分裂
-
尽量不要使用UUID做主键或者使用其他自然主键,如身份号码
-
业务操作时,避免对主键的修改。修改主键后,索引结构就需要发生改变
2.3 order by优化
2.3.1 排序的方式
order by排序中有2种排序方式:Using index > Using filesort
-
Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序。
-
Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
#没有创建索引时,根据age,phone进行排序
explain select id,age,phone from tb_user order by age, phone;
#创建索引
create index idx_user_age_phone_aa on tb_user(age, phone);
#创建索引后,根据age,phone进行升序排序
explain select id,age,phone from tb_user order by age, phone;
#创建索引后,根据age,phone进行降序排序
explain select id,age,phone from tb_user order by age desc, phone desc;
-- 一个升序、一个降序时联合索引不起作用
#根据age,phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age asc,phone desc;
-- 解决办法是,重新创建索引,一个升序、一个降序
#创建索引
create index idx_ user_age_phone_ad on tb_user(age asc ,phone desc);
#根据age,phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age asc, phone desc;
3.2 排序优化
-
根据排序字段建立合适的索引,多字段排序时,也要遵循最左前缀法则
-
尽量使用覆盖索引
-
多字段排序,一个升序、一个降序,这时需要注意联合索引在创建的规则(asc\desc)
-
如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区,如果超过256K时,可能会涉及磁盘文件
-- 查看排序缓冲取大小,默认为256K
show variablees like 'sort_buffer_size';2.4 group by优化
create index index_age_city on user(age,city);
-- Extra:Using index
explain select age,count(*) from test.user group by age;
-- Extra:Using index; Using temporary
explain select city,count(*) from test.user group by city;优化原则:
-
分组操作时,可以通过索引来提高效率
-
分组操作时,索引的使用也是满足最左前缀法则的
2.5 limit优化
-- 当user表中数据量较大时。limit从0开始和limit从990900的速度差别很大。
select * from test.user limit 0, 10;
select * from test.user limit 990900, 10;
-- 可使用子查询来进行优化
select s.* from test.user as s, (select id from test.user order by id limit 909000,10) as a where s.id = a.id;一般分页查询时,优化思路:
-
通过创建 覆盖索引 提高执行效率
-
覆盖索引+子查询的方式进行优化
2.6 count优化
count是一个聚合函数,对于返回的结果集,一行一样的判断是否为null,如果不为null就累计加1,最后返回累计值。
用法有:
-
count(*)
-
count(主键)
-
count(字段)
-
count(1)

使用近似计数:如果你对精确的行数没有严格要求,可以使用近似计数方法。MySQL提供了一个叫做SHOW TABLE STATUS的命令,它可以返回表的元数据信息,包括数据行数的近似值
show table status like 'user';2.7 update优化
InnoDB使用的是行锁,是针对索引加的锁,该索引不能失效,失效后行锁会升级为表锁。
关注我,我们一起学习。