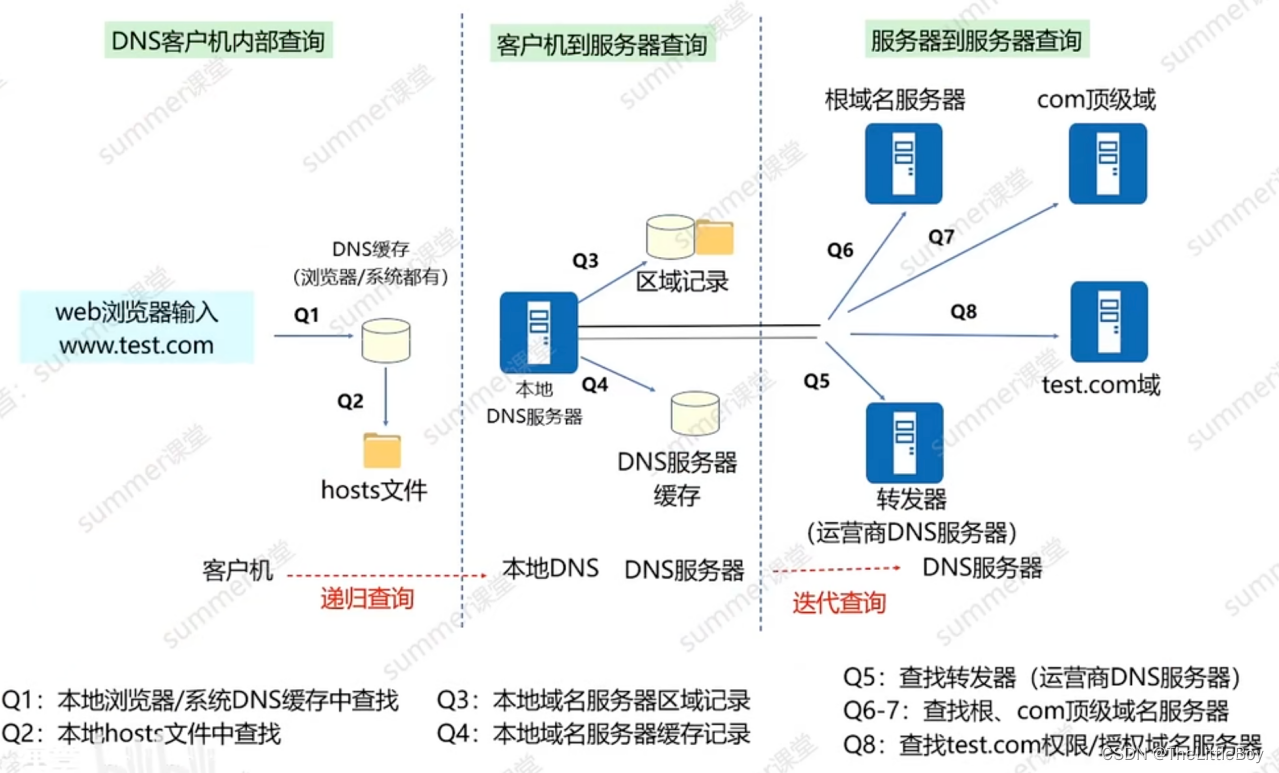
基于ssm+vue协同过滤算法的电影推荐系统
摘要
电影推荐系统在信息技术发展的背景下日益成为研究的焦点,本研究基于SSM(Spring + SpringMVC + MyBatis)框架与Vue.js技术,以协同过滤算法为核心,旨在构建一种高效、准确的电影推荐系统。该系统通过整合前后端技术,实现了用户与电影信息的全面管理,并通过协同过滤算法为用户提供个性化的电影推荐服务。在后端方面,采用SSM框架搭建系统的服务端,借助Spring进行依赖注入和事务管理,SpringMVC实现Web层的请求处理,MyBatis作为持久层框架进行数据库操作。这样的架构保证了系统后端的高效性、可维护性和可扩展性,为电影数据的存储和处理提供了强有力的支持。前端方面,系统采用Vue.js构建用户界面,通过其响应式设计和组件化开发,实现了用户友好的交互体验。Vue.js的轻量级特性使得前端页面更加灵活,同时通过与后端的数据交互,用户可以轻松浏览、搜索和评价电影,从而为协同过滤算法提供更为精准的用户行为数据。协同过滤算法作为推荐系统的核心算法之一,通过分析用户历史行为与其他用户的相似性,为用户推荐未曾接触的电影。本研究在算法层面深入研究协同过滤的优化方法,包括基于用户的协同过滤和基于物品的协同过滤,以提高推荐的准确性和用户满意度。整体而言,本研究结合了SSM框架、Vue.js技术以及协同过滤算法,构建了一套电影推荐系统,旨在为用户提供更个性化、精准的电影推荐服务。通过前后端的协同工作和协同过滤算法的优化,该系统在电影推荐领域具有良好的实用性和研究价值。
研究意义
该基于SSM+Vue协同过滤算法的电影推荐系统在多个方面具有重要的研究意义:
-
个性化服务提升用户体验: 通过协同过滤算法,系统能够根据用户的个性化兴趣和行为历史,精准推荐电影,提升用户体验。这对于满足用户多样化需求、提高用户黏性和满意度具有显著意义。
-
技术整合与创新: 该研究将SSM框架与Vue.js前端技术相结合,实现了前后端的无缝整合,为电影推荐系统的开发提供了一种全新的技术实践。这有助于推动前后端技术整合的发展,为其他领域的系统设计提供新思路。
-
协同过滤算法的优化与应用: 协同过滤作为推荐系统的经典算法,通过在研究中对其进行深入优化,可以提高推荐准确性和系统性能。这对于推动协同过滤算法在推荐系统中的应用和发展具有积极推动作用。
-
用户行为分析与数据挖掘: 通过对用户的电影观看历史、评价和喜好进行分析,系统能够更好地理解用户的行为模式。这有助于推动用户行为分析和数据挖掘在推荐系统中的研究和应用。
-
电影产业的发展推动: 电影推荐系统的研究对于电影产业的发展也有积极推动作用。通过提高电影的曝光度和推广效果,电影产业可以更好地满足观众需求,促进产业的繁荣。
-
信息科技与文化交流: 电影推荐系统的建设促进了信息科技与文化的深度交流。通过推荐系统,不同文化、不同地区的电影作品可以更广泛地被推荐和接受,从而推动了文化的交流和共享。
研究现状
目前,基于SSM(Spring + SpringMVC + MyBatis)+Vue协同过滤算法的电影推荐系统研究领域正逐渐受到广泛关注。以下是该领域的一些研究现状:
-
协同过滤算法的发展: 协同过滤是电影推荐系统中应用广泛的算法之一。近年来,研究者们在基于用户的协同过滤和基于物品的协同过滤上进行了深入研究。同时,混合推荐算法、深度学习在协同过滤中的应用等也成为研究热点,以提高推荐的精准性和个性化程度。
-
前后端技术整合: SSM框架作为一种Java后端技术集成框架,与Vue.js这类现代前端框架的结合,使得系统在开发效率和性能方面都得到了提升。研究者们关注如何更好地整合前后端技术,提高系统的响应速度和用户体验。
-
用户行为分析与数据挖掘: 研究者通过对用户的行为数据进行分析和挖掘,探索用户的观影偏好、评价习惯等,以提高推荐系统的个性化水平。这涉及到对大规模用户数据的处理和分析,以及如何确保用户数据的隐私安全。
-
推荐系统的可解释性和公平性: 随着推荐系统的广泛应用,其可解释性和公平性变得日益重要。研究者们关注推荐算法的可解释性,使用户能够理解推荐背后的原理。同时,也在研究如何保障推荐系统的公平性,避免因为算法偏向某一群体而导致信息过滤。
-
电影产业与推荐系统的融合: 一些研究关注电影产业如何利用推荐系统提升用户体验和市场份额。这包括了推广、精准营销等方面的研究,使推荐系统不仅仅是学术研究,同时也是实际应用的有效工具。
-
多媒体内容的推荐: 随着多媒体技术的不断发展,电影不再仅仅是文字和图片,还包括音频和视频等多媒体内容。因此,研究者开始关注如何将协同过滤算法应用于多媒体内容的推荐领域,以满足用户对多样化媒体的需求。
功能展示
主页

电影详情
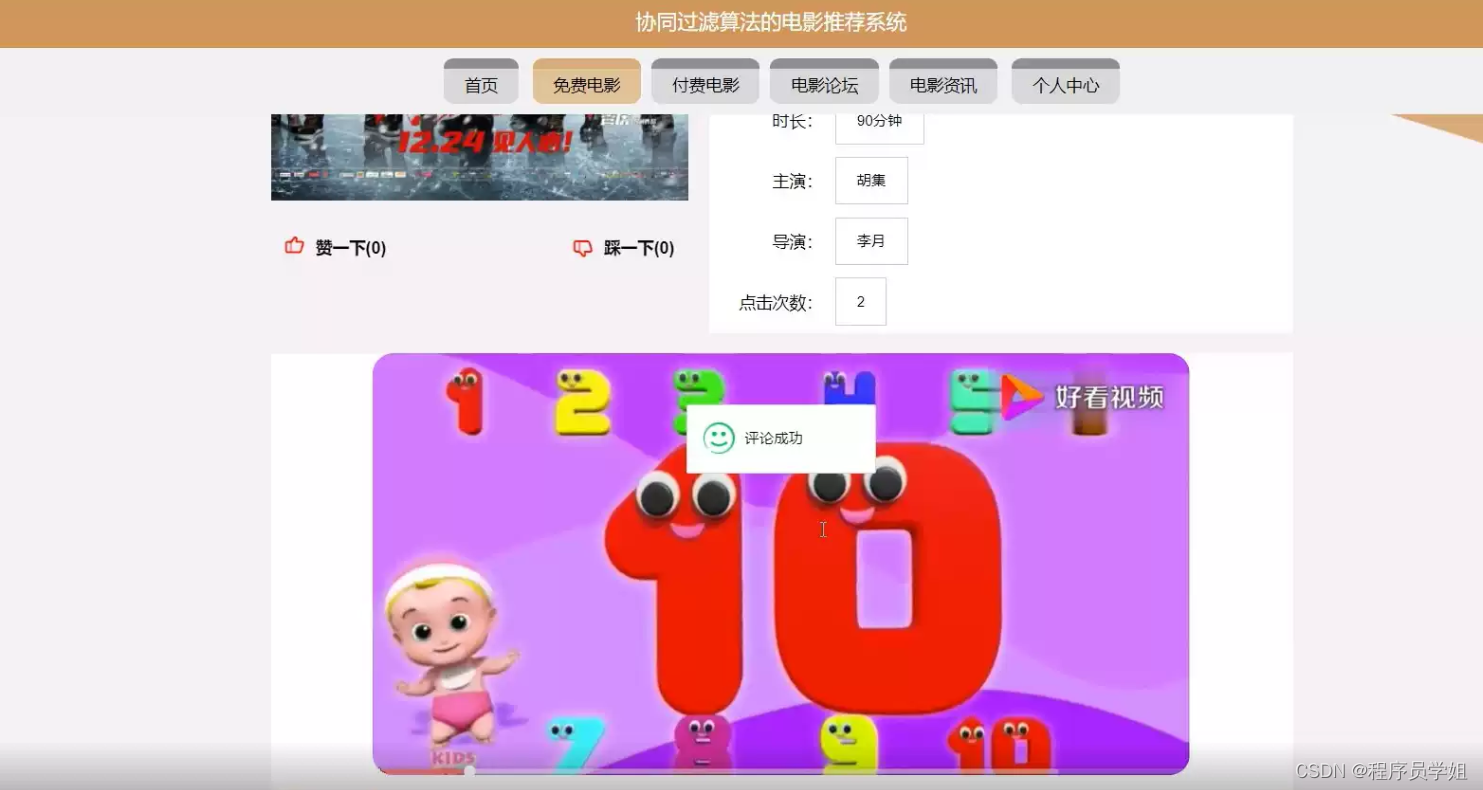
管理员界面

论坛管理

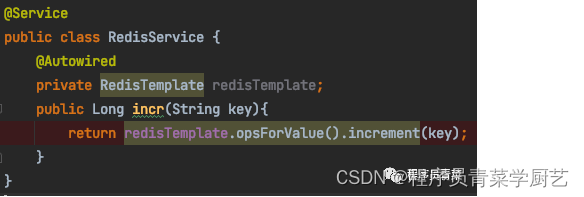
代码展示
import numpy as np
# 用户-物品矩阵,表示用户对物品的评分
user_item_matrix = np.array([
[5, 4, 0, 0, 1],
[4, 0, 0, 0, 2],
[0, 5, 4, 0, 0],
[0, 0, 0, 4, 5],
])
# 计算用户相似度
def calculate_user_similarity(user_item_matrix):
num_users, num_items = user_item_matrix.shape
similarity_matrix = np.zeros((num_users, num_users))
for i in range(num_users):
for j in range(num_users):
if i != j:
# 使用余弦相似度计算用户相似度
numerator = np.dot(user_item_matrix[i], user_item_matrix[j])
denominator = np.linalg.norm(user_item_matrix[i]) * np.linalg.norm(user_item_matrix[j])
similarity_matrix[i, j] = numerator / (denominator + 1e-9)
return similarity_matrix
# 预测用户对未评分物品的评分
def predict_user_item_rating(user_item_matrix, similarity_matrix, user_index, item_index):
num_users, num_items = user_item_matrix.shape
numerator = 0
denominator = 0
for i in range(num_users):
if i != user_index and user_item_matrix[i, item_index] != 0:
numerator += similarity_matrix[user_index, i] * user_item_matrix[i, item_index]
denominator += np.abs(similarity_matrix[user_index, i])
if denominator == 0:
return 0
else:
return numerator / denominator
# 使用示例
user_similarity_matrix = calculate_user_similarity(user_item_matrix)
user_index = 0
item_index = 2
predicted_rating = predict_user_item_rating(user_item_matrix, user_similarity_matrix, user_index, item_index)
print(f"预测用户 {user_index} 对物品 {item_index} 的评分为:{predicted_rating:.2f}")