目录
1. M3 Dynamic Caching
2. Unified Memory
3. Unified Memory是如何处理page fault的
4. Unified Memory Page Fault的相关论文
M3 Dynamic Caching
最新的Apple M3 芯片最亮眼的可能是支持dynamic caching,如下图所示。
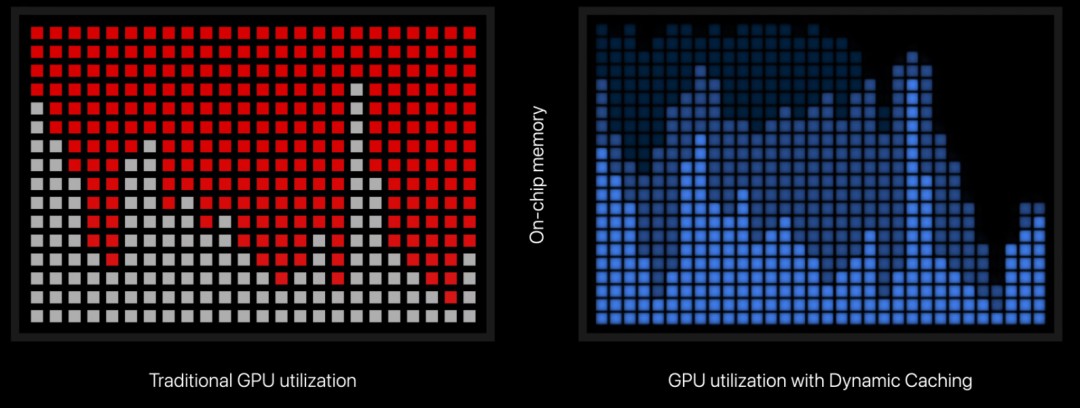
具体说来就是传统的GPU分配内存时,不是实时的分配内存,而是在一开始就分配好固定大小的内存,这时分配的内存是按照任务需要内存上限分配的,M3新支持的dynamic caching,可以支持GPU实时的分配内存,提高了内存的利用率,因为内存的使用就像上面的图片,有波峰和波谷。
但是这个应该是叫做dynamic allocation of memory,为什么叫做caching,个人理解可能是因为内存的分配也可以看作是caching,不过是按照page的颗粒度,将需要的页缓存在memory中,内存满时,也要将选作eviction的脏页写回disk,类似于脏的数据块64B写到下一级,不同的是此时颗粒度是4KB。
Apple M3介绍自己是业界首创,但是看着这更像是一个早就该有的基本功能,于是去看看Nvidia有没有类似的技术。
Unified Memory
传统的cuda教学课教的是在CPU malloc内存分配数据块,在GPU cudaMalloc数据块,然后将数据块从CPU内存拷贝到GPU内存,启动kernel的计算,这样的程序写起来比较复杂,更像是操作外设。
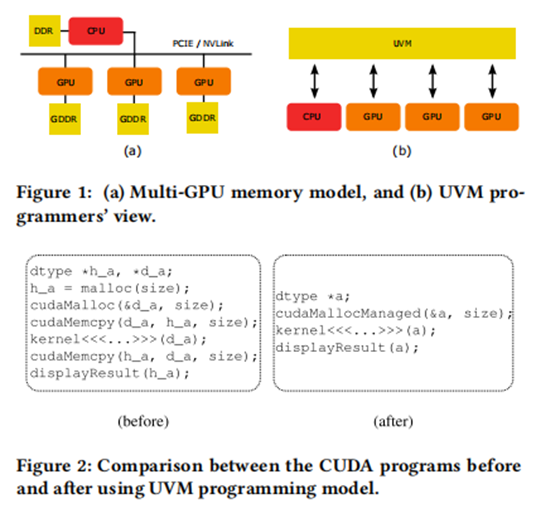
Nvidia在CUDA中引入了Unified Memory,将CPU内存和GPU内存视为一个大内存:
-
CUDA4引入了Unified Virtual Addressing可以访问一个pinned在CPU内存中的memory
-
CUDA6 引入了Unified Memory, CPU和GPU可以同时访问整个内存,但是不能同时访问一页内存,并且Unified Memory仅限于GPU memory的大小
-
CUDA8 增加了虚拟寻址的范围到49bit,并且支持了page fault。通过page fault,GPU可以实现像CPU一样的按需分配。
这样理想的情况下,CUDA的编写不再需要手动的在CPU和GPU侧分配内存,拷贝内存,kernel执行完毕后再拷贝回来,而是可以直接共享memory的指针。此外这个也可以减少CUDA对指针,链表,树,图这种需要深拷贝的内存的编程复杂度。
我们介绍最新的基于按需分配demand paging的unified memory,这个概念很像M3说的dynamic caching。
Unified Memory是如何处理page fault的
这里的demand paging的概念和CPU的相同,就是访问页时,发生page fault,然后获取page,也被称为memory oversubscription,但是与CPU不同,因为GPU没有处理precise exception的能力,也没有处理page fault的能力。当一个warp的遇到page fault时,GPU可以:
-
暂停所有warp的执行
-
或者暂停当前warp的执行,调度其他可以执行的warp
显然第一种代价更大,因此GPU按照第二种执行,内部也就需要存放一个page fault queue。而后具体的处理page fault,搬运page的操作,超出了GPU的能力范围,需要CPU执行或者CPU发送命令到GPU执行。
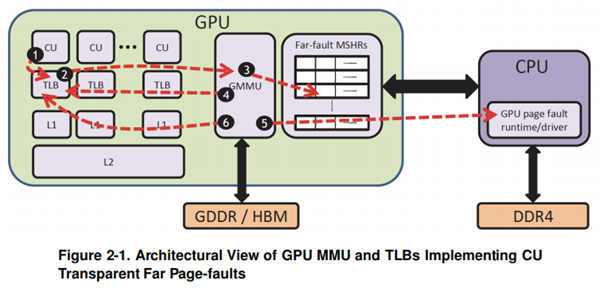
具体的流程:
-
GPU内部单元向TLB发起虚实地址转换请求,TLB miss,而后在GPU MMU page walk,查询页表,依然miss后,触发page fault。
-
GPU MMU向内部单元发送该地址翻译失败响应,挂起该warp。
-
GPU将page fault存到page fault queue中,向CPU发起page fault异常请求。
-
CPU执行GPU runtime程序从page fault queue中读取page fault的请求,不同于CPU处理CPU page fault的直接处理方式,GPU可能会同时发生多个page fault,于是:
-
对page fault queue中的地址进行排序sort
-
Sort之后,方便在CPU的页表中进行查找
-
-
不同于CPU处理CPU page fault的另一点是,不仅会处理GPU的page fault对应的页,也会进行prefetch其他的页,预取一些页进入GPU内存,提高page fault的利用效率
-
而后根据该page的属性,CPU需要unmap这个page,将该页放到GPU的内存中,同时在GPU的页表中增加这个page,并flush 这个GPU uTLB
-
完成上述操作后,GPU才可以重新将page fault的warp重新调度
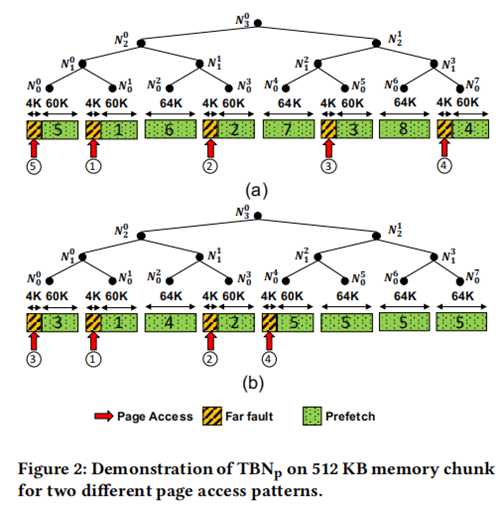
上述操作如下图左侧所示:

图源自[4]
这个过程十分繁琐,如果此时GPU的内存已满,还需要将GPU中的一页evict到CPU中,如上图右侧所示。
为了保证页表的顺序更新,evict旧页操作和fetch新页的操作还需要顺序执行,如下图所示,需要PageX被eviction之后,pageA才能allocation。

Unified Memory 处理Page Fault相关论文
最开始提出这个unified memory的论文[1],做出的贡献是
-
每次page fault不是只处理一个页,而是将page fault放入queue中
-
每次处理多个page fault时,因为时间比较长,因此可以同时增加prefetch,提高性能,他提供了sequential prefetch和random prefetch
后来的论文[2]发现GPU处理evict和fetch的操作是顺序的,以保证正确性,因此他们提出可以在中断处理时,先evict一个页,因为GPU内存向CPU内存写,比读要快,因此evict和fetch操作可以并行执行。

同时该论文还提出了我们还可以增加thread oversubscription,这样当所有的thread都page fault时,可以调度其他的thread block进入,类似于CPU的context switch。
Nvidia的GPU的prefetcher提供一种Tree Based Prefetcher,但是evict时使用的是LRU策略,有的论文[3]为了改进,也增加了tree based eviction的策略。