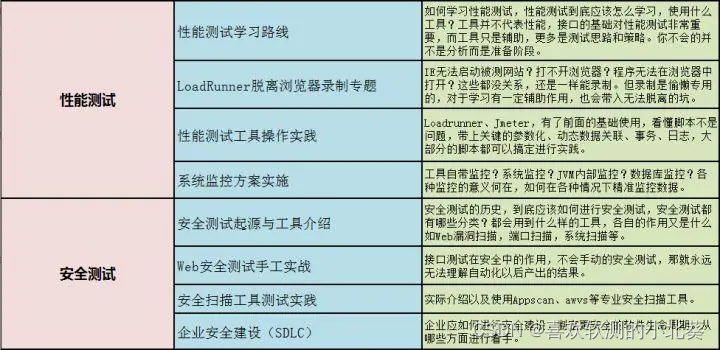
这里写目录标题
- 动手学深度学习pandas完整代码
- 数据处理
- TypeError: can only concatenate str (not "int") to str(fillna填补缺失值)
- 创建文件夹
- 学习这个数据分组
- get_dummies实现one hot encode
动手学深度学习pandas完整代码
import os
import numpy as np
import pandas as pd
import torch
from numpy import nan as NaN
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
with open(datafile, 'w') as f: # 往文件中写数据
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 第1行的值
f.write('2,NA,106000\n') # 第2行的值
f.write('4,NA,178100\n') # 第3行的值
f.write('NA,NA,140000\n') # 第4行的值
data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
print('1.原始数据:\n', data)
inputs, outputs = data.iloc[:, 0: 2], data.iloc[:, 2]
# inputs = inputs.fillna(inputs.mean()) # 用均值填充NaN
# inputs = inputs.fillna(66) # 用均值填充NaN
#在mean()括号里面加入numeric_only=Ture
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
print(outputs)
# 利用pandas中的get_dummies函数来处理离散值或者类别值。
# [对于 inputs 中的类别值或离散值,我们将 “NaN” 视为一个类别。] 由于 “Alley”列只接受两种类型的类别值 “Pave” 和 “NaN”
inputs = pd.get_dummies(inputs, dummy_na=True)
print('2.利用pandas中的get_dummies函数处理:\n', inputs)
# x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)报错!!!
x = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
print('3.转换为张量:')
print(x)
print(y)
# 扩展填充函数fillna的用法
df1 = pd.DataFrame([[1, 2, 3], [NaN, NaN, 2], [NaN, NaN, NaN], [8, 8, NaN]]) # 创建初始数据
print('4.函数fillna的用法:')
print(df1)
print(df1.fillna(100)) # 用常数填充 ,默认不会修改原对象
print(df1.fillna({0: 10, 1: 20, 2: 30})) # 通过字典填充不同的常数,默认不会修改原对象
print(df1.fillna(method='ffill')) # 用前面的值来填充
# print(df1.fillna(0, inplace=True)) # inplace= True直接修改原对象
df2 = pd.DataFrame(np.random.randint(0, 10, (5, 5))) # 随机创建一个5*5
df2.iloc[1:4, 3] = NaN
df2.iloc[2:4, 4] = NaN # 指定的索引处插入值
print(df2)
print(df2.fillna(method='bfill', limit=2)) # 限制填充个数
print(df2.fillna(method="ffill", limit=1, axis=1)) #
数据处理
TypeError: can only concatenate str (not “int”) to str(fillna填补缺失值)
不能让字符串 和int 值 连接
这里报错不是简单的连接,是因为mean函数的,求mean的对象中有整数也有字符串
解决方法
#在mean()括号里面加入numeric_only=Ture
inputs = inputs.fillna(inputs.mean(numeric_only=True))
import os
import numpy as np
import pandas as pd
import torch
from numpy import nan as NaN
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
with open(datafile, 'w') as f: # 往文件中写数据
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 第1行的值
f.write('2,NA,106000\n') # 第2行的值
f.write('4,NA,178100\n') # 第3行的值
f.write('NA,NA,140000\n') # 第4行的值
data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
print('1.原始数据:\n', data)
inputs, outputs = data.iloc[:, 0: 2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean()) # 用均值填充NaN
print(inputs)
print(outputs)

创建文件夹
在上级目录创建data文件夹,记得找到上级目录的data再删
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
1.1 os.makedirs(path, mode=0o777) 方法:用于递归创建目录。
path – 需要递归创建的目录,可以是相对或者绝对路径。。
mode – 权限模式。
无返回值
1.2 os.path.join()函数:连接两个或更多的路径名组件
- 如果各组件名首字母不包含’/’,则函数会自动加上
- 如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
- 如果最后一个组件为空,则生成的路径以一个’/’分隔符结尾
学习这个数据分组
get_dummies实现one hot encode
get_dummies方法可以把把 离散的类别信息转化为onehot编码形式,
dummy_na=True意为是否把nan单独看做一个类别。
get_dummies
是利用pandas实现one hot encode的方式
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
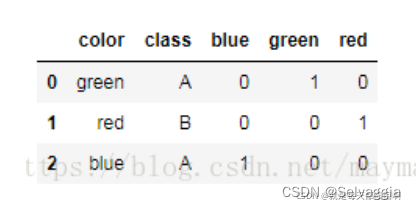
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
df.columns = ['color', 'class']
pd.get_dummies(df)

对每个类别的值都进行0-1编码
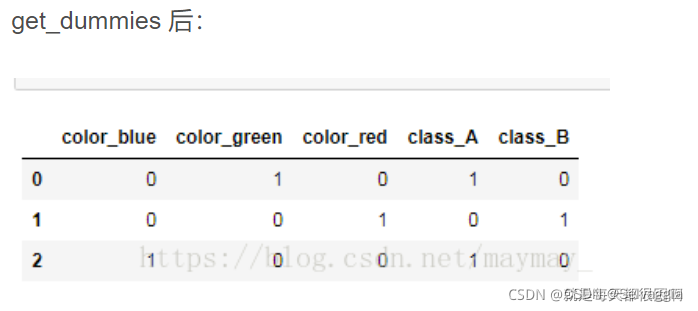
上述执行完以后再打印df 出来的还是get_dummies 前的图,因为你没有写,赋值
df = pd.get_dummies(df)
可以对指定列进行get_dummies
pd.get_dummies(df.color)

将指定列进行get_dummies 后合并到元数据中
df = df.join(pd.get_dummies(df.color))