Alibi explain: 解释机器学习模型的算法
- 可解释人工智能简介
- Alibi特点
- 算法
- Library设计
- 展望
- 参考资料
今天介绍Alibi Explain,一个开源Python库,用于解释机器学习模型的预测(https://github.com/SeldonIO/alibi)。该库具有最先进的分类和回归模型可解释性算法。算法涵盖了模型不可知(黑框)和模型特定(白框)设置,满足多种数据类型(表格、文本、图像)和解释范围(局部和全局解释)。该库公开了一个统一的API,使用户能够以一致的方式使用解释。Alibi坚持最佳开发实践,在持续集成环境中广泛测试代码正确性和算法收敛性。该库提供了关于方法的用法和理论背景的大量文档,以及一套端到端的工作用例。Alibi旨在成为一个可生产的工具包,集成到Seldon Core和KFServing等机器学习部署平台,并使用Ray实现分布式解释功能。

可解释人工智能简介
可解释的人工智能,也称为模型可解释性,是指以人类观察者可以理解的格式阐明复杂、不透明的机器学习模型做出的预测背后的原因的技术(Molnar,2019)。 解释预测的能力有助于建立对模型决策过程的信任,因此是强大的机器学习系统不可或缺的一部分(Bhatt 等人,2020;Klaise 等人,2020)。
解释所提供的所需见解在很大程度上取决于解释的使用者,从调试模型的数据科学家到审核模型的监管机构。 因此,需要多种方法来满足目标受众的需求(ICO,2019;Bhatt et al.,2020)。 此外,独立的解释方法可能会产生非信息性甚至误导性的解释(Heo et al., 2019)。 这意味着需要采用整体方法来解释模型。
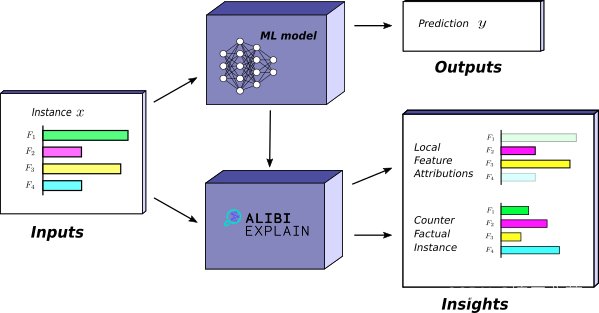
我们推出 Alibi,旨在弥合快速增长的可解释性研究领域与行业之间的差距。 Alibi 的目标是托管各种可用于生产的模型解释算法的参考实现。 Alibi 包含本地、全局、黑盒和白盒事后解释方法,涵盖各种用例。 虽然有一些同时存在的可解释性库(参见表 1),但 Alibi 唯一专注于提供具有部署平台集成和分布式后端的生产级解释方法。
Alibi特点
- 应用范围。 模型的可解释性通常需要一种整体方法,因为没有一刀切的解决方案。 这反映在当前支持的算法的广度(第 2.1 节)及其适用性指南(表 2)中。
- 建立稳健性。 在各种Python版本下使用pytest对代码正确性和算法收敛性进行广泛的测试。 使用 Github Actions 通过持续集成设置对每个拉取请求执行测试。
- 文档和示例。 该库具有全面的文档和广泛深入的用例示例1。 该文档包括每种方法的用法和理论背景。 此外,所有方法的范围和适用性都有清晰的记录,以帮助从业者快速识别相关算法(表2)。
- 行业相关性。 Alibi 已集成到部署平台 Seldon Core(Cox 等人,2018 年)和 KFServing(KFServing,2019 年)中,以便将解释部署到生产中。 Alibi 还具有使用 Ray 的分布式后端(Moritz et al., 2018)来启用批量解释的大规模并行计算。
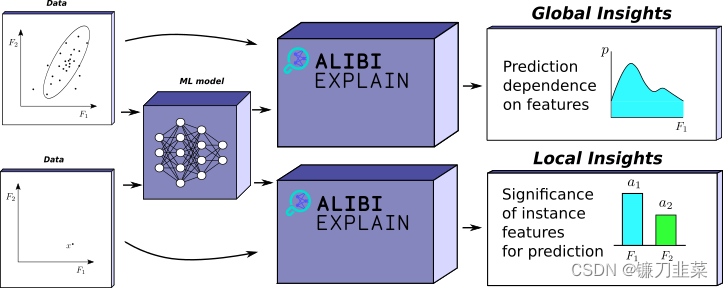
我们还提供了与其他积极开发的解释库的更详细的功能比较,请参见表 1。
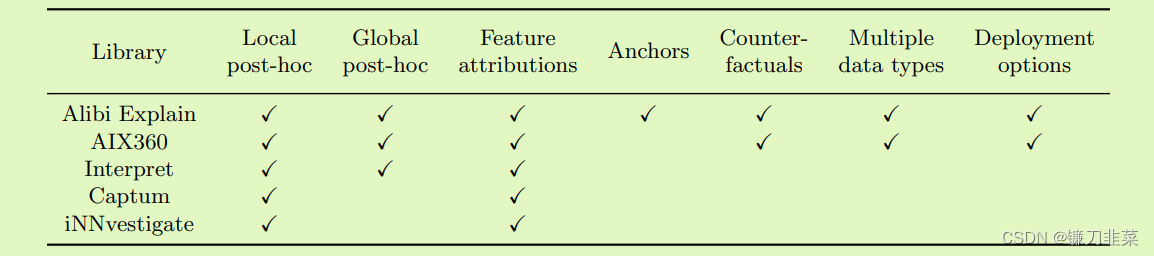
表1:与相关解释库AIX360(Arya等人,2020)、Interpret(Nori等人,2019)、Captum(Kokhlikyan等人,2020)、iNNvestigate(Alber等人,2019)的比较。 库的选择和比较是基于提供事后、黑盒或白盒、本地或全局解释技术,这些技术是用 Python 实现的,这些技术在过去 12 个月内进行了一些开发活动。
算法
该库的当前版本包括以下解释算法(详细功能参见表 2):
-
Accumulated Local Effects(ALE),Apley 和 Zhu (2016):计算模型预测的全局特征影响。
-
- Anchor explanations(锚点解释),Ribeiro 等人。 (2018):找到最小的特征子集,以保证(以高概率)相同的预测,而不管其他特征如何。
-
- Contrastive Explanation Methods(对比解释法 , CEM),Dhurandhar 等人。 (2018):找到应该最少且充分存在的特征以及应该必然不存在的特征,以证明对特定的预测是合理的实例。
-
- Counterfactual explanations(反事实解释),Wachter 等人。 (2018):找到接近原始但导致不同预测的合成实例。
-
- Counterfactual explanations with prototypes(原型反事实解释),Van Looveren 和 Klaise (2019):改进反事实解释方法,以产生更多可解释的分布实例。
-
- Integrated Gradients(积分梯度),Sundararajan 等人。 (2017):通过沿着从基线实例到感兴趣实例的路径累积梯度来计算预测的特征属性。
-
- Kernel Shapley Additive Values,Lundberg 和 Lee (2017):通过博弈论方法通过考虑特征组“无信息”来计算预测的特征归因。
-
- Tree Shapley Additive Values,Lundberg 等人。 (2020):树集成模型的 Shapley 加性值的算法改进。
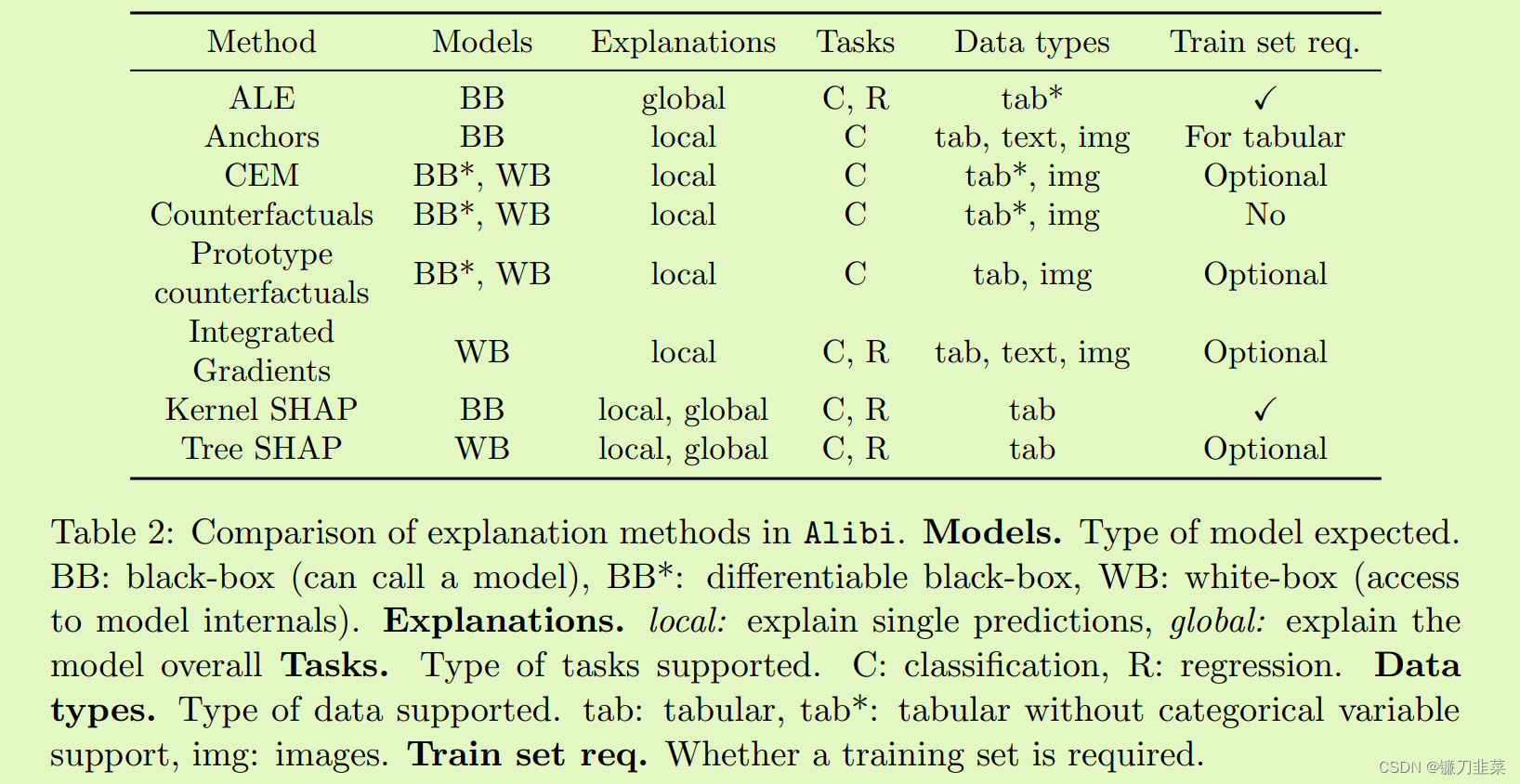
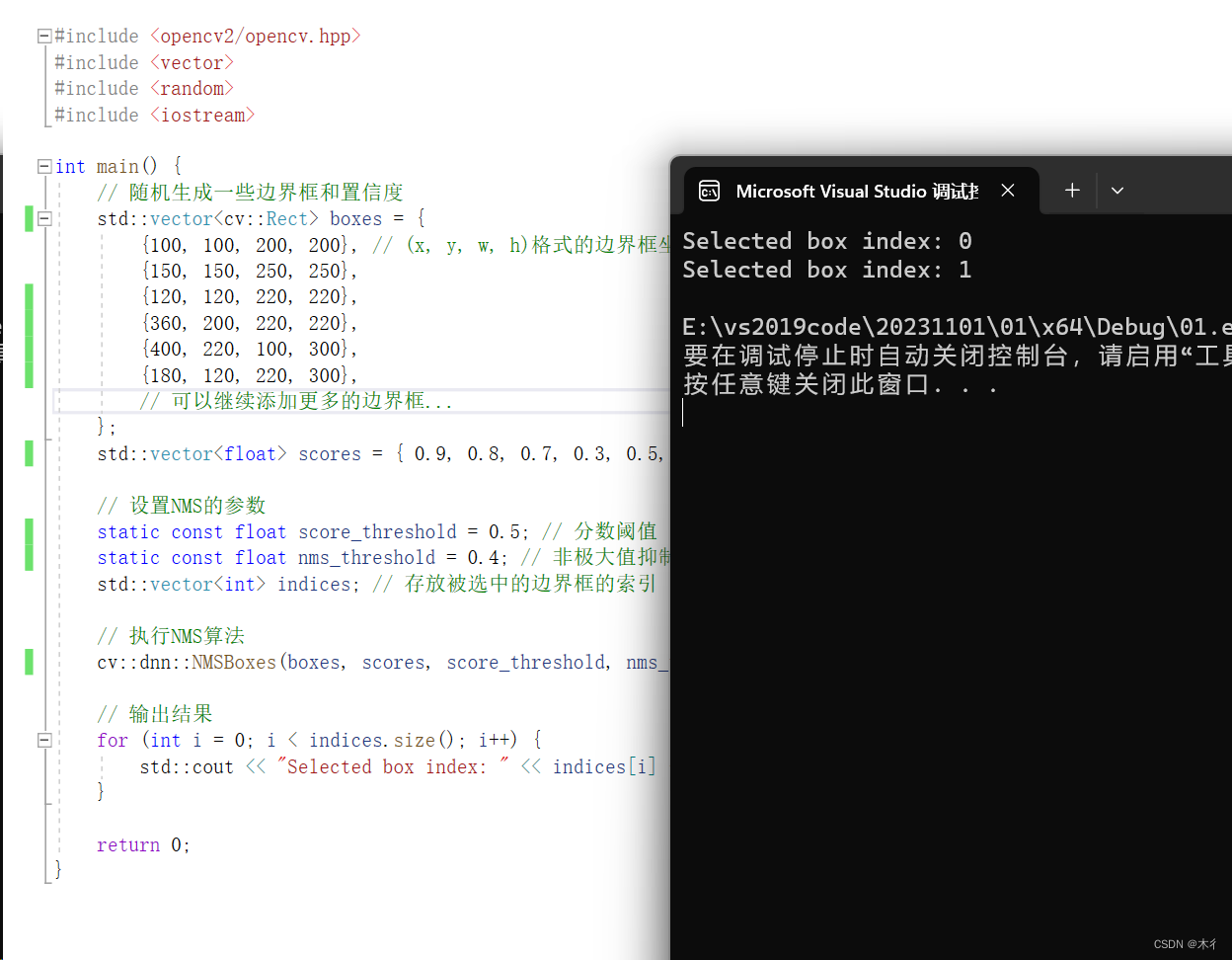
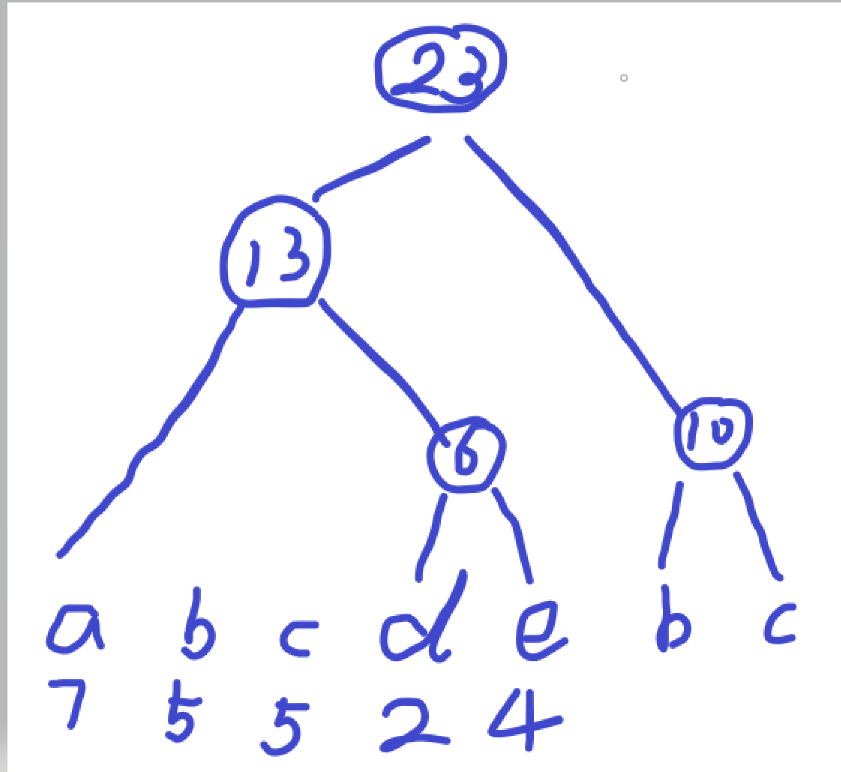
图 1 显示了一系列支持的解释算法的输出:
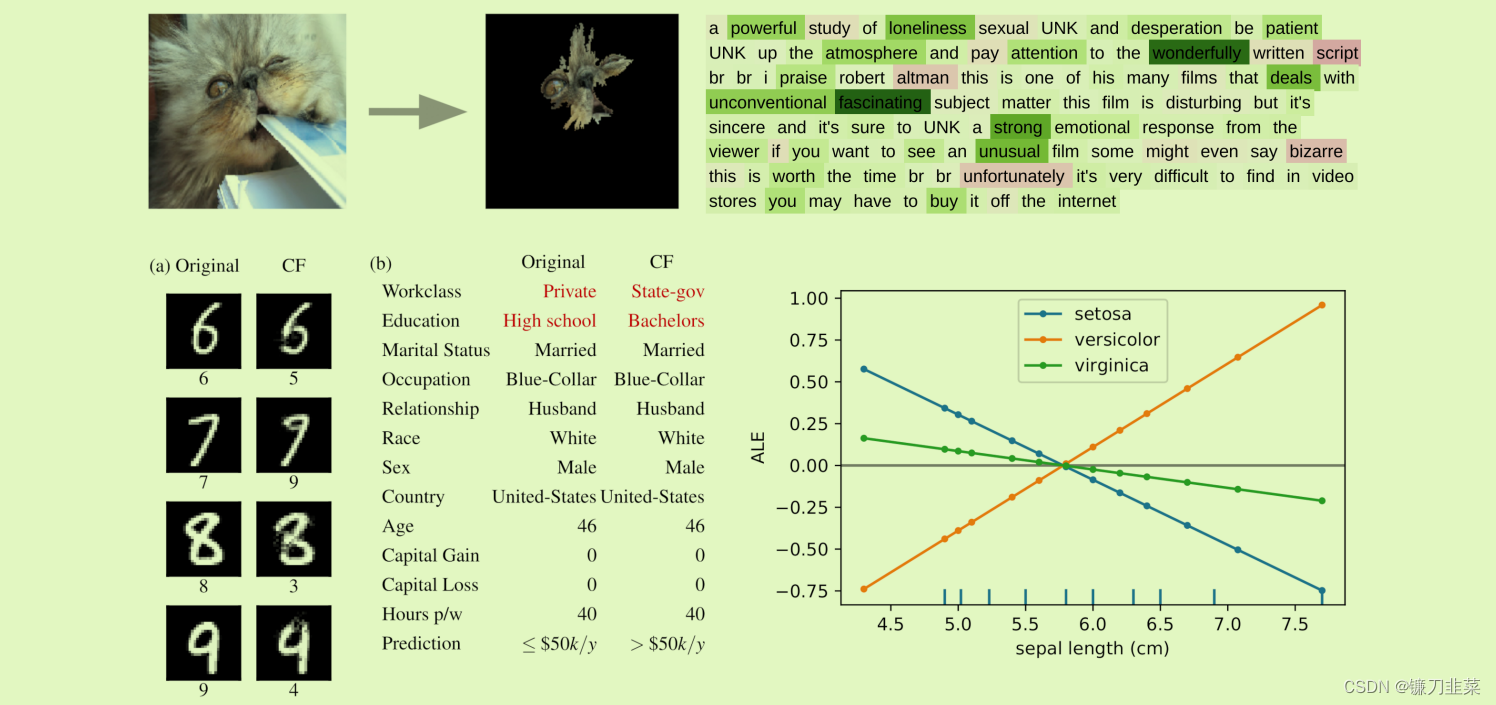
图 1:支持的解释算法的选择。 左上:图像分类的锚点解释解释了预测“波斯猫”。 右上:情绪预测任务的综合梯度归因解释了预测“积极”。 左下:(a) MNIST 数字分类和 (b) 收入分类的反事实解释。 右下:ALE 特征对 Iris 数据集上逻辑回归模型的影响。
Library设计
Alibi 面向用户的 API 设计为跨算法一致且易于使用(代码片段 1)。 解释算法是通过在黑盒情况下传递预测函数(采用并返回 numpy 数组的 Python Callable)或在白盒情况下传递预训练模型(例如 TreeSHAP 或 TensorFlow 的 xgboost)来初始化的。 如表2所示,对于需要训练数据的方法,必须调用fit方法。 最后,调用解释方法来计算一个实例或一组实例的解释。 这将返回一个 Explanation 对象,其中包含字典元数据和数据,分别具有解释元数据(例如超参数设置、名称)和解释数据。 Explanation 对象的结构可以在生产系统中轻松序列化以进行进一步处理(例如日志记录、可视化)。 元数据捕获用于获取每个解释的设置并充当审计跟踪。

代码片段 1:使用 AnchorTabular 解释算法的 Alibi API 演示。
展望
Alibi 开发的第一阶段重点是创建一组精选的参考解释算法,并对典型用例提供全面指导。 虽然基于白盒梯度的方法的工作重点是支持 TensorFlow 模型,但在不久的将来实现与 PyTorch 模型的功能对等是一个关键目标。 此外,我们计划扩展 Ray 项目的使用,以实现所有解释算法的并行化。 Ray 的选择还可以将解释扩展到单个多核计算节点之外。
补充:
Ray是一个用于扩展AI和Python应用程序的统一框架。Ray由一个核心分布式运行时和一组用于加速ML工作负载的AI库组成。
参考资料
- Alibi explain: algorithms for explaining machine learning models
- Alibi explain
- Ray