Redis持久化的作用和意义
Redis 持久化是一种机制,用于将内存中的数据写入磁盘,以保证数据在服务器重启时不会丢失。持久化是为了解决内存数据库(如 Redis)在服务器关闭后,数据丢失的问题。 Redis 持久化的主要作用和意义为以下:
-
数据保护: 持久化确保在发生故障或服务器重启时,已存储在内存中的数据可以被恢复。这对于需要长期存储和保护数据的应用场景非常重要。
-
持久存储: 将数据持久化到磁盘上,可以在服务器重新启动时重新加载数据,从而确保数据的持久存储。
-
数据恢复: 持久化提供了一种在系统崩溃或断电的情况下能够快速恢复数据的方法。通过定期保存快照或者记录每次写操作,可以最大限度地减少数据丢失的可能性。
-
备份和迁移: 持久化的数据可以被用于创建备份,以便在需要时还原数据。同时,可以通过将持久化文件迁移到其他服务器,实现数据的迁移和共享。
-
避免内存溢出: 如果 Redis 中的数据集非常大,超过了系统的可用内存,那么持久化可以防止因内存溢出而导致的数据丢失。
Redis 提供了两种主要的持久化方式:
-
RDB 持久化: 将 Redis 数据在指定时间间隔内写入磁盘,生成一个快照文件。这种方式适用于数据集较大时的快速备份和还原。
-
AOF 持久化: 将每次写操作追加到一个文件中,以记录数据库状态的变化。这种方式适用于需要更精确的数据恢复,但相对来说,文件体积可能较大。
而我们这篇文章就会来详细解读RDB持久化的过程
详解RDB持久化
RDB(Redis DataBase)持久化是 Redis 数据库一种持久化机制,用于将内存中的数据保存到磁盘上,以防止数据在重启时丢失。RDB 持久化的主要作用是将当前时刻的数据库状态保存到一个二进制文件中,这个文件通常以 .rdb 为扩展名。

下面是 RDB 持久化的详细解释:
RDB 持久化的触发方式
RDB 持久化可以通过以下两种方式触发:

-
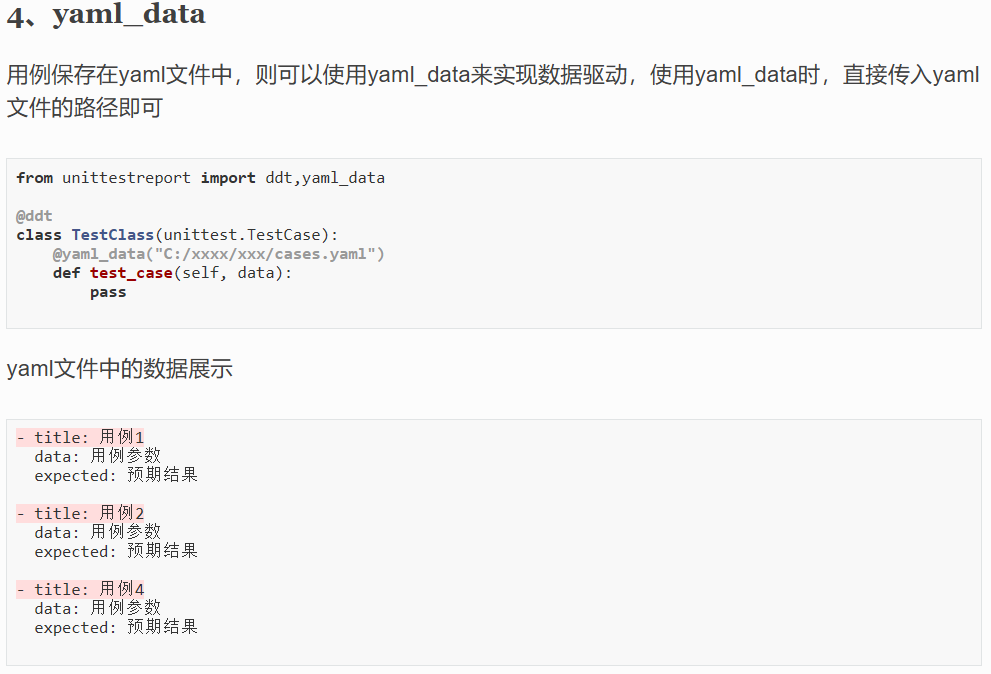
手动触发: 可以使用
SAVE或BGSAVE命令来手动触发 RDB 持久化。(如上图所示)SAVE命令会阻塞 Redis 服务器,直到 RDB 持久化完成为止。BGSAVE命令会在后台执行,不会阻塞 Redis 服务器,允许继续处理其他请求。
-
自动触发: Redis 还可以通过配置redis.conf文件后达到一定条件时自动触发 RDB 持久化,比如在一定时间内发生了一定数量的写操作。(如下图所示)

RDB 持久化的过程
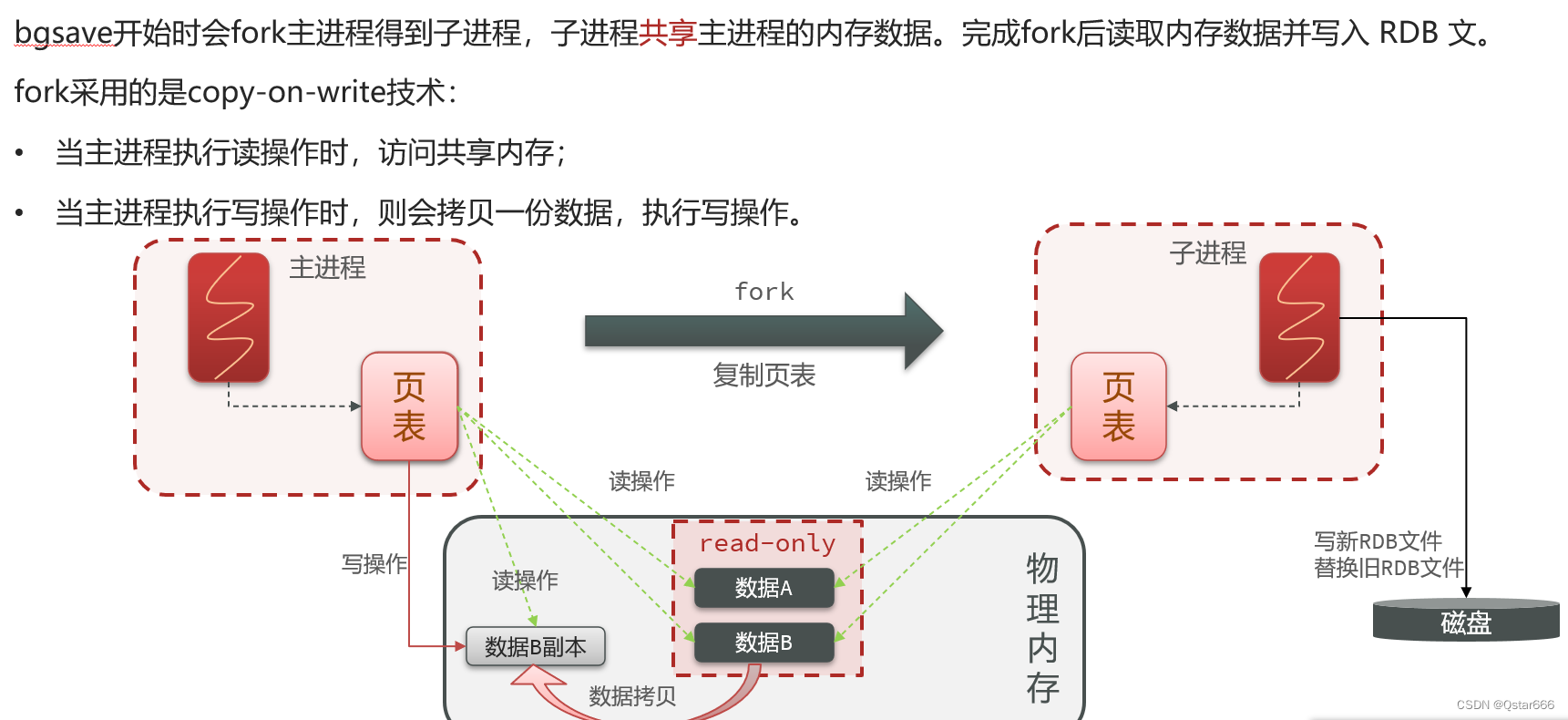
RDB 持久化的过程可以概括为以下几个步骤:(如上图所示)
-
触发持久化: 当触发条件满足时,Redis 将会执行 RDB 持久化。
-
创建数据快照: Redis 会生成一个数据快照,即当前数据库在内存中的数据的副本。
-
数据写入临时文件: 将数据快照写入一个临时文件。
-
替换旧的 RDB 文件: 当临时文件写入完成后,Redis 会将旧的 RDB 文件替换为新的文件。
-
完成持久化: 持久化完成后,Redis 将继续处理其他请求。
RDB 文件的结构
RDB 文件是一个二进制文件,包含了保存了整个数据库状态的数据。文件的结构可以分为以下几个部分:
-
文件头部: 包含了一个魔数(Magic Number)和版本号等信息,用于标识文件类型和版本。
-
全局信息: 包含了数据库的基本信息,比如 Redis 服务器的版本、生成 RDB 文件的时间等。
-
键值对数据: 包含了数据库中的所有键值对的数据。每个键值对都包含键的数据、值的数据以及过期时间等信息。
-
数据校验和: 用于校验文件完整性的校验和数据。
RDB 持久化的优缺点
优点:
- 高性能: RDB 持久化是通过快照的方式保存数据,因此在恢复数据时非常快速。
- 紧凑: RDB 文件是二进制格式,相对于文本格式更加紧凑,占用的磁盘空间相对较小。
缺点:
- 可能丢失数据: 如果在两次持久化之间发生故障,可能会导致一定时间内的数据丢失。
- 不适用于大规模数据: 对于大规模数据的数据库,生成快照和持久化会占用较多的系统资源。