JiebaTokenizer类继承自Tokenizer类,而Tokenizer类又继承自GraphComponent类,GraphComponent类继承自ABC类(抽象基类)。本文使用《使用ResponseSelector实现校园招聘FAQ机器人》中的例子,主要详解介绍JiebaTokenizer类中方法的具体实现。
0.JiebaTokenizer类中方法列表
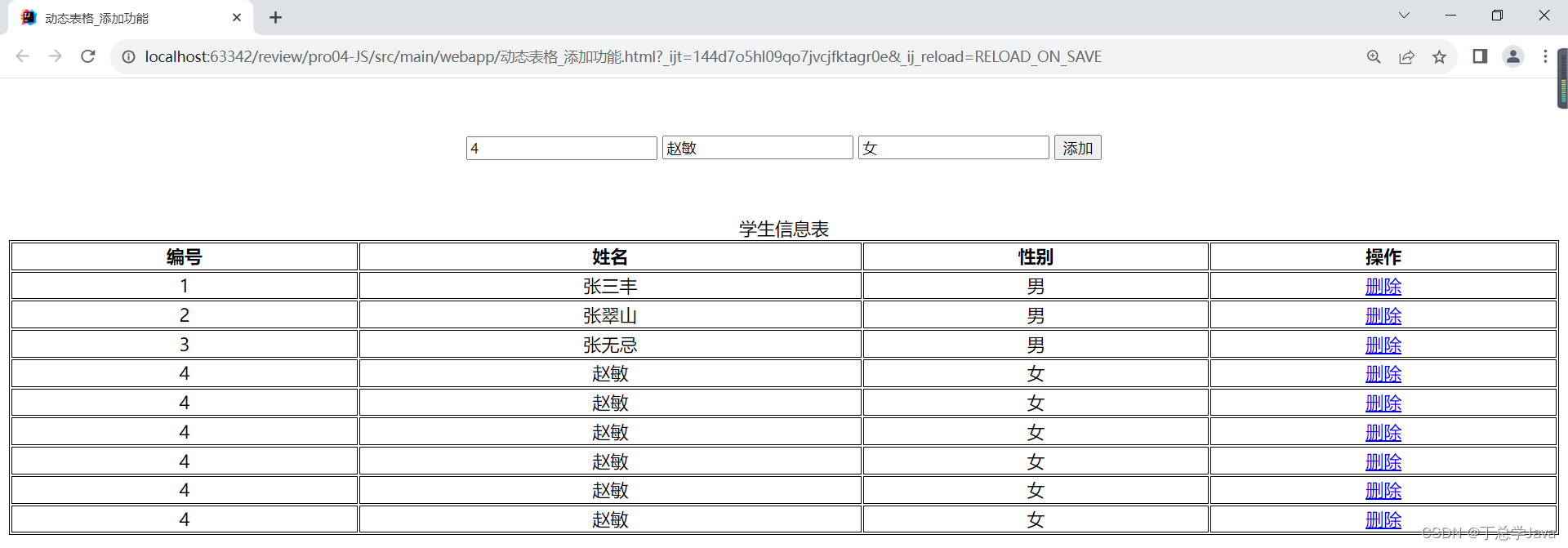
下面是JiebaTokenizer类中所有方法和属性列表,也包括从其它类中继承来的方法和属性,如下所示:

JiebaTokenizer类(默认参数)中本身方法执行顺序,如下所示:
JiebaTokenizer.supported_languages()
JiebaTokenizer.required_packages()
JiebaTokenizer.get_default_config()
JiebaTokenizer.create()
JiebaTokenizer.__init__()
JiebaTokenizer.train()
JiebaTokenizer.persist()
JiebaTokenizer.load()
JiebaTokenizer.tokenize()
默认参数没有执行2个方法,如下所示:
_load_custom_dictionarypipeline(*)方法
_copy_files_dir_to_dir(*)方法
接下来自然而然的问题是,如何在config.yml中给JiebaTokenizer自定义参数呢?可参考get_default_config()方法,如下所示:
def get_default_config() -> Dict[Text, Any]:
return {
# default don't load custom dictionary # 默认不加载自定义字典
"dictionary_path": None, # 自定义字典的路径
# Flag to check whether to split intents # 检查是否拆分intent的标志
"intent_tokenization_flag": False,
# Symbol on which intent should be split # intent应该拆分的符号
"intent_split_symbol": "_",
# Regular expression to detect tokens # 用于检测tokens的正则表达式
"token_pattern": None,
# Symbol on which prefix should be split # 前缀应该拆分的符号
"prefix_separator_symbol": None,
}
1.supported_languages(*)方法
解析:支持的语言,即[“zh”]。如下所示:
@staticmethod
def supported_languages() -> Optional[List[Text]]:
"""Supported languages (see parent class for full docstring).""" # 支持的语言(请参阅父类的完整文档字符串)。
print("JiebaTokenizer.supported_languages()")
return ["zh"]
2.get_default_config(*)方法
解析:返回默认配置,如下所示:
@staticmethod
def get_default_config() -> Dict[Text, Any]:
"""Returns default config (see parent class for full docstring).""" # 返回默认配置(请参阅父类的完整文档字符串)。
print("JiebaTokenizer.get_default_config()")
return {
# default don't load custom dictionary # 默认不加载自定义字典
"dictionary_path": None,
# Flag to check whether to split intents # 检查是否拆分意图的标志
"intent_tokenization_flag": False,
# Symbol on which intent should be split # 意图应该拆分的符号
"intent_split_symbol": "_",
# Regular expression to detect tokens # 用于检测tokens的正则表达式
"token_pattern": None,
# Symbol on which prefix should be split # 前缀应该拆分的符号
"prefix_separator_symbol": None,
}
3.__init__(*)方法
解析:执行到create()方法的cls(config, model_storage, resource)时,实际调用的是def __init__()。如下所示:
def __init__(
self, config: Dict[Text, Any], model_storage: ModelStorage, resource: Resource
) -> None:
"""Initialize the tokenizer.""" # 初始化标记器。
print("JiebaTokenizer.__init__()")
super().__init__(config)
self._model_storage = model_storage
self._resource = resource
4.create(*)方法
解析:创建一个新组件,如下所示:
@classmethod
def create(
cls,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
) -> JiebaTokenizer:
"""Creates a new component (see parent class for full docstring).""" # 创建一个新组件(请参阅父类的完整文档字符串)。
print("JiebaTokenizer.create()")
# Path to the dictionaries on the local filesystem.
dictionary_path = config["dictionary_path"]
if dictionary_path is not None:
cls._load_custom_dictionary(dictionary_path)
return cls(config, model_storage, resource)
(1)config: Dict[Text, Any]
{
'dictionary_path': None,
'intent_split_symbol': '_',
'intent_tokenization_flag': False,
'prefix_separator_symbol': None,
'token_pattern': None
}
(2)model_storage: ModelStorage

(3)resource: Resource
{
name = 'train_JiebaTokenizer0',
output_fingerprint = '318d7f231c4544dc9828e1a9d7dd1851'
}
(4)execution_context: ExecutionContext

其中,cls(config, model_storage, resource)实际调用的是def __init__()。
5.required_packages(*)方法
解析:此组件运行所需的任何额外python依赖项,即[“jieba”]。如下所示:
@staticmethod
def required_packages() -> List[Text]:
"""Any extra python dependencies required for this component to run.""" # 此组件运行所需的任何额外python依赖项。
print("JiebaTokenizer.required_packages()")
return ["jieba"]
6._load_custom_dictionary(*)方法
解析:从模型存储加载自定义字典,如下所示:
@staticmethod
def _load_custom_dictionary(path: Text) -> None:
"""Load all the custom dictionaries stored in the path. # 加载存储在路径中的所有自定义字典。
More information about the dictionaries file format can be found in the documentation of jieba. https://github.com/fxsjy/jieba#load-dictionary
"""
print("JiebaTokenizer._load_custom_dictionary()")
import jieba
jieba_userdicts = glob.glob(f"{path}/*") # 获取路径下的所有文件。
for jieba_userdict in jieba_userdicts: # 遍历所有文件。
logger.info(f"Loading Jieba User Dictionary at {jieba_userdict}") # 加载结巴用户字典。
jieba.load_userdict(jieba_userdict) # 加载用户字典。
7.train(*)方法
解析:将字典复制到模型存储,如下所示:
def train(self, training_data: TrainingData) -> Resource:
"""Copies the dictionary to the model storage."""
print("JiebaTokenizer.train()")
self.persist() # 持久化。
return self._resource
其中,返回的self._resource内容如下所示:

8.tokenize(*)方法(重点)
解析:对传入消息的提供属性的文本进行tokenize,如下所示:
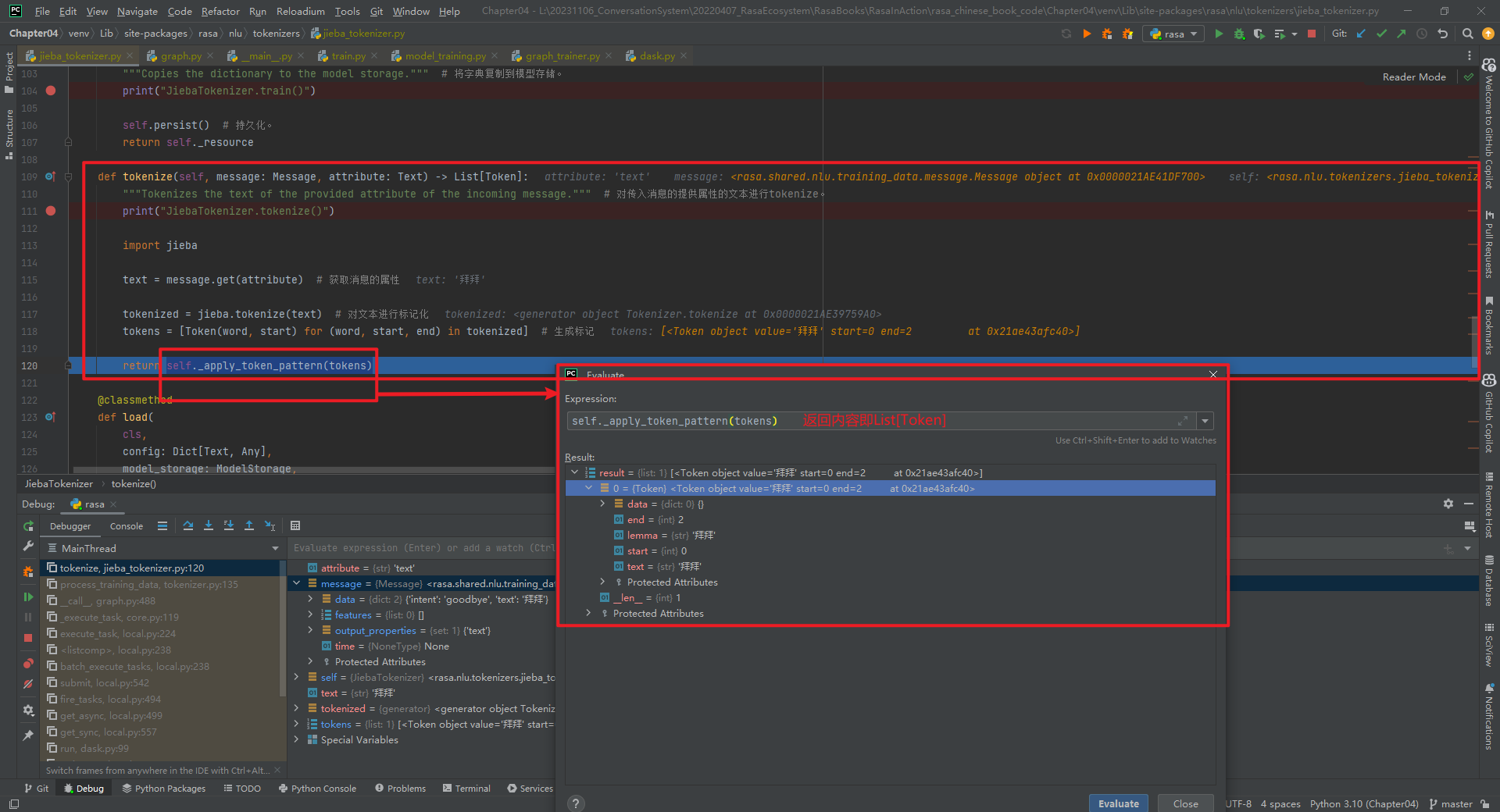
def tokenize(self, message: Message, attribute: Text) -> List[Token]:
"""Tokenizes the text of the provided attribute of the incoming message."""
print("JiebaTokenizer.tokenize()")
import jieba
text = message.get(attribute) # 获取消息的属性
tokenized = jieba.tokenize(text) # 对文本进行标记化
tokens = [Token(word, start) for (word, start, end) in tokenized] # 生成标记
return self._apply_token_pattern(tokens)
其中,message.data内容为{'intent': 'goodbye', 'text': '拜拜'}。其它字段具体数值,如下所示:
9.load(*)方法
解析:从模型存储加载自定义字典,如下所示:
@classmethod
def load(
cls,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
**kwargs: Any,
) -> JiebaTokenizer:
"""Loads a custom dictionary from model storage.""" # 从模型存储加载自定义字典。
print("JiebaTokenizer.load()")
dictionary_path = config["dictionary_path"]
# If a custom dictionary path is in the config we know that it should have been saved to the model storage. # 如果配置中有自定义字典路径,我们知道它应该已保存到模型存储中。
if dictionary_path is not None:
try:
with model_storage.read_from(resource) as resource_directory:
cls._load_custom_dictionary(str(resource_directory))
except ValueError:
logger.debug(
f"Failed to load {cls.__name__} from model storage. "
f"Resource '{resource.name}' doesn't exist."
)
return cls(config, model_storage, resource)

10._copy_files_dir_to_dir(*)方法
解析:执行persist(*)方法时会调用该方法,如下所示:
@staticmethod
def _copy_files_dir_to_dir(input_dir: Text, output_dir: Text) -> None:
print("JiebaTokenizer._copy_files_dir_to_dir()")
# make sure target path exists # 确保目标路径存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
target_file_list = glob.glob(f"{input_dir}/*")
for target_file in target_file_list:
shutil.copy2(target_file, output_dir)
11.persist(*)方法
解析:持久化自定义字典,如下所示:
def persist(self) -> None:
"""Persist the custom dictionaries."""
print("JiebaTokenizer.persist()")
dictionary_path = self._config["dictionary_path"]
if dictionary_path is not None:
with self._model_storage.write_to(self._resource) as resource_directory:
self._copy_files_dir_to_dir(dictionary_path, str(resource_directory))
12._model_storage属性
解析:用来初始化JiebaTokenizer类的属性,详见构造函数。
13._resource属性
解析:用来初始化JiebaTokenizer类的属性,详见构造函数。
参考文献:
[1]https://github.com/RasaHQ/rasa/blob/main/rasa/nlu/tokenizers/jieba_tokenizer.py
[2]使用ResponseSelector实现校园招聘FAQ机器人:https://mp.weixin.qq.com/s/ZG3mBPvkAfaRcjmXq7zVLA