一、实验目的
1.会用Python创建朴素贝叶斯模型
2.使用朴素贝叶斯模型对垃圾邮件分类
3.会把文本内容变成向量
4.会用评价朴素贝叶斯模型的分类效果
二、设备与环境
Jupyter notebook
Python=3.9
三、实验原理

四、实验内容
1.把给定的数据集message.csv拆分成训练集和测试集,使用sklearn.naive_bayes.MultionmialNB类常见一个朴素贝叶斯模型,使用训练数据训练出一个预测模型,然后用预测模型对测试集中数据进行分类,评价模型的分类效果
2.message.csv数据集中包含大量的短信,每行数据包括2个字段:短信内容,短信类别(1或者0),短信类别为1的是垃圾短信
3.MultinomialNB对象的
α
\alpha
α属性,可以用于设置或获取相应的平滑参数值
实现结果

改良版:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 1.读取csv文件,将数据集按3:1的比例拆分成训练集和测试集
data = pd.read_csv(r'D:\D\Download\360安全浏览器下载\messages.csv')
split_ratio = 0.75
training_data, testing_data = train_test_split(data, test_size=1 - split_ratio, random_state=0)
# 2.将文本拆分成单词函数
def tokenize(message):
message = message.lower()
all_words = re.findall("[a-z0-9]+", message)
return all_words
# 3.构建词汇表,形成特征矩阵和分类矩阵
def generateMat(data, word_dict):
num_samples = len(data)
num_features = len(word_dict)
feature = np.zeros((num_samples, num_features))
classify = np.zeros(num_samples)
for i, (message, cls) in enumerate(data.values):
classify[i] = cls
words = tokenize(message)
for word in words:
if word in word_dict:
feature[i][word_dict.index(word)] = 1
return feature, classify
# 4.根据训练数据生成特征矩阵和分类矩阵,显示训练矩阵特征维度
word_dict = []
for message in training_data["Subject"]:
words = tokenize(message)
for word in words:
if word not in word_dict:
word_dict.append(word)
training_features, training_classify = generateMat(training_data, word_dict)
print("Training matrix feature dimension:", training_features.shape)
# 5.用训练集训练朴素贝叶斯模型
model = GaussianNB()
model.fit(training_features, training_classify)
# 6.根据测试数据生成特征矩阵和分类矩阵,显示测试矩阵特征维度
testing_features, testing_classify = generateMat(testing_data, word_dict)
print("Testing matrix feature dimension:", testing_features.shape)
# 7.用测试集进行预测
predict_classify = model.predict(testing_features)
# 计算并显示模型的准确率、精度、召回率和F1值
accuracy = accuracy_score(testing_classify, predict_classify)
precision = precision_score(testing_classify, predict_classify)
recall = recall_score(testing_classify, predict_classify)
f1 = f1_score(testing_classify, predict_classify)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
改良版
import pandas as pd
import re
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 读取CSV文件,将数据集按3:1的比例拆分成训练集合测试集
print("1、读取csv文件数据,并拆分成训练数据和测试数据....")
df = r'D:\D\Download\360安全浏览器下载\messages.csv'
data = pd.read_csv(df)
fp = open(df, encoding="utf-8")
dataset = data.iloc[:, 0] # 短信内容
labels = data.iloc[:, 1] # 短信分类结果
split_ratio = 0.75 # 75%的训练数据
training_data = []
testing_data = []
np.random.seed(0)
x_train, x_test, y_train, y_test = train_test_split(
dataset, labels, train_size=0.75, random_state=0)
xTrain = x_train.reset_index(drop=True)
yTrain = y_train.reset_index(drop=True)
xTest = x_test.reset_index(drop=True)
yTest = y_test.reset_index(drop=True)
# 将文本拆分成单词
def tokenize(message):
message = message.lower()
all_words = re.findall("[a-z0-9']+", message)
return set(all_words)
print("2、构建词汇表,并形成Feature矩阵和Classify矩阵....")
# 构建词汇表
word_dict = []
for i in range(len(xTrain)):
te = tokenize(xTrain[i])
for word in te:
word_dict.append(word)
# print(word_dict)
# print(len(word_dict))
word_dict_set = set(word_dict)
word_dict_done = list(word_dict_set)
num_features = len(word_dict_done)
# 生成训练矩阵(特征+标签)
# 构建词汇表,形成特征矩阵和分类矩阵
def generateMat(data):
num_samples = len(data)
feature = np.zeros((num_samples, num_features))
classify = np.zeros(num_samples)
for i in range(num_samples):
te = tokenize(data[i])
# classify[i] = data[1] # 有错误,显示是空的字符串,没有解决
for word in te:
if word in word_dict_done:
feature[i][word_dict_done.index(word)] = 1
return feature
# def generateMat(data):
# num_samples = len(data)
# feature = np.zeros((num_samples, num_features))
# classify = np.zeros(num_samples)
# for i in range(num_samples):
# data_row = data[i]
# classify[i] = data_row[1]
# for word in data_row[0]:
# if word in word_dict:
# feature[i][word_dict.index(word)] = 1
# return feature, classify
xTrain_future = generateMat(xTrain)
xTest_future = generateMat(xTest)
print("3、根据训练数据,形成Feature矩阵和Classify矩阵....")
# 训练集的维度
print("训练矩阵特征维度:", xTrain_future.shape)
# 测试集的维度
print("4、根据测试数据,形成Feature矩阵和Classify矩阵....")
print("测试矩阵特征维度:", xTest_future.shape)
# 用训练集训练朴素贝叶斯模型
print("5、训练朴素贝叶斯模型....")
model = MultinomialNB()
model.fit(xTrain_future, yTrain)
# 用测试集进行预测
print("6、用测试集进行预测....")
predict_classify = model.predict(xTest_future)
# 计算并显示模型的准确率、精度、召回率和F1值
TN = FP = TP = FN = 0
for i in range(len(predict_classify)):
if yTest[i] == 0 and predict_classify[i] == 0:
TN += 1
if yTest[i] == 0 and predict_classify[i] == 1:
FP += 1
if yTest[i] == 1 and predict_classify[i] == 1:
TP += 1
if yTest[i] == 1 and predict_classify[i] == 0:
FN += 1
p = TP / (TP + FP)
r = TP / (TP + FN)
# F1值(是一个平均数,对精度与召回率进行平均的结果)
F1 = 1 / ((1 / 2) * (1 / p + 1 / r))
# 用测试集进行预测
# predict_classify与yPredict一样的
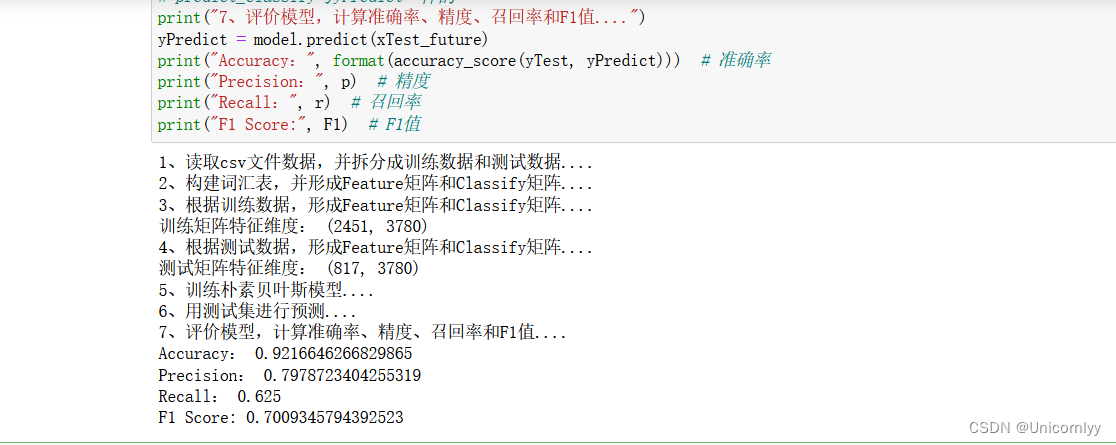
print("7、评价模型,计算准确率、精度、召回率和F1值....")
yPredict = model.predict(xTest_future)
print("Accuracy:", format(accuracy_score(yTest, yPredict))) # 准确率
print("Precision:", p) # 精度
print("Recall:", r) # 召回率
print("F1 Score:", F1) # F1值


![P1529 [USACO2.4] 回家 Bessie Come Home 题解](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)