什么是Online DDL?
在线DDL(Online Data Definition Language)是指在数据库运行状态下执行数据定义语言(DDL)操作,例如创建、修改或删除表结构、索引等操作,而不会造成数据库的长时间锁定或无法使用。传统的DDL操作通常需要对受影响的表进行排他锁定,这可能导致其他会话无法对该表进行读写操作,从而影响了数据库的正常使用。
Online DDL解决了什么问题?
- 减少系统停机时间:传统的DDL操作通常需要锁定受影响的表,这可能导致数据库在执行DDL操作期间无法对外提供服务,造成系统停机时间。在线DDL能够在不中断正常服务的情况下执行表结构的变更,从而减少系统停机时间,提高系统可用性。
- 提高并发性能:通过在线DDL,数据库系统可以允许DDL操作与其他事务并发执行,减少对表的锁定时间,提高了数据库的并发性能,使得用户可以在不受影响的情况下继续进行数据操作。
- 降低业务风险:在线DDL可以避免由于长时间锁定表而导致的业务中断和故障。这对于对数据库连续性和可用性要求较高的业务尤为重要,能够降低业务风险。
- 提高管理效率: 在线DDL使得数据库管理员可以在不停机的情况下进行表结构调整,从而提高了管理效率,并且减少了对业务的影响。
- 解决锁等待:在传统的DDL操作中,数据库通常需要对受影响的表进行排他锁定,这可能导致其他会话无法对该表进行读写操作,从而产生锁等待现象。而在线DDL可以有效解决传统DDL操作可能引发的锁等待问题。
总之,通过解决上述问题,在线DDL提高了数据库系统的可用性、并发性和管理效率,使得数据库在不中断服务的情况下能够进行结构调整,适应了现代业务对数据库连续性和稳定性的要求。
分类
目前支持的主流算法有三种:
- COPY —— MySQL 5.6之前非Online,都是执行这种算法
- INPLACE —— MySQL 5.6出现的
- INSTANT —— MySQL 8.0.12出现的
这时就有疑问了,这么多算法头都大了

我们知道要想把一件东西放进冰箱需要三个阶段,而在DDL操作,执行时,不管何种算法,也都会经历三个阶段,准备阶段【prepare】、执行阶段【DDL】、提交阶段【commit】。不同之处是,在三个阶段中分别做了不同的处理,接下来我们仔细分析一下不同算法的这三个阶段。
Copy
- Copy算法指的是创建一个新的表,将原表的数据复制到新表中,然后对新表进行结构修改,最后删除原表。这个算法的优点是修改过程中不会影响原表的读写操作,但需要较多的空间和时间。
- 适用场景:适用于需要做大量结构修改、或者表的大小不是特别大的情况。
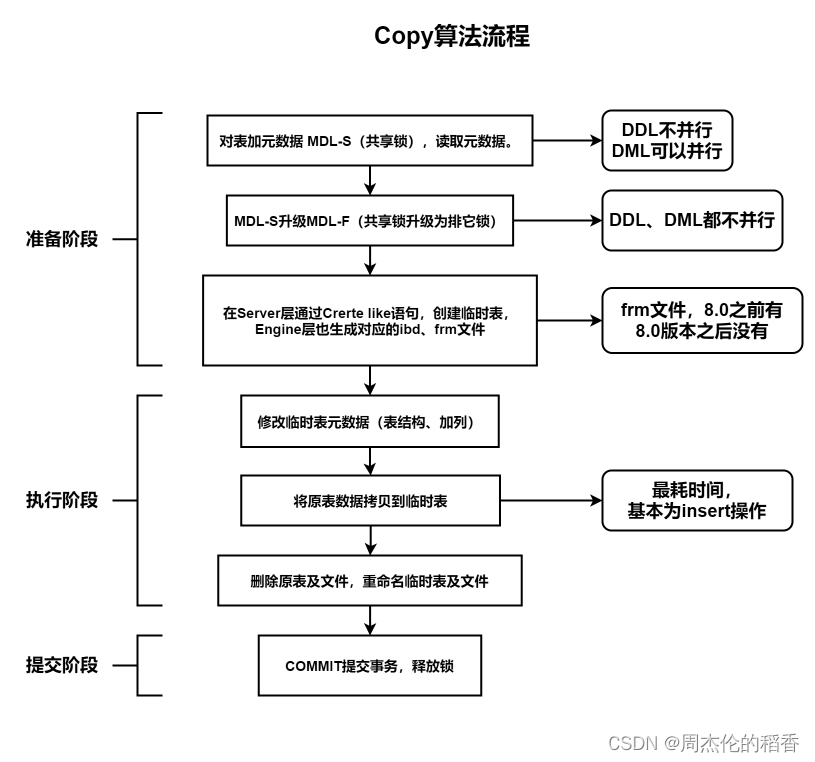
下面是copy算法的三个阶段
准备(Prepare)
- 对表加元数据共享锁,读取frm元数据(此时DDL不能并发执行,DML可以并发)
- 共享锁升级为排他锁(此时DDL,DML都不能并发执行)
- 在server层通过create like语句,创建临时表,engine层也生成对应的ibd,frm文件(8.0之后没有.frm文件)
执行(Execute)
- 修改临时表元数据(加列)
- 拷贝元数据到临时表【最耗时,表中的数据需要一行一行的拷贝】
- 删除原表及文件
- 重命名临时表及文件
提交(Commit)
- 提交事务,释放锁
copy算法流程
Inplace
- Inplace算法指的是直接在原表上进行结构修改,不创建新表。这个算法的优点是不需要额外的存储空间,但可能会产生较大的锁、阻塞和性能开销。
- 适用场景:适用于对表进行小范围的结构修改、或者表的大小较大但有足够的空闲空间的情况。
对于"Inplace"算法,它的核心思想是在原表上直接进行结构修改,不创建新的表。然而,在实际的数据库系统中,即使使用"Inplace"算法,也可能会需要创建临时的数据结构来完成修改操作,这些临时数据结构通常并不是完全独立的新表,而是一种用于辅助修改操作的数据结构。因此,严格意义上讲,即使使用"Inplace"算法,也可能会涉及到创建临时的数据结构。
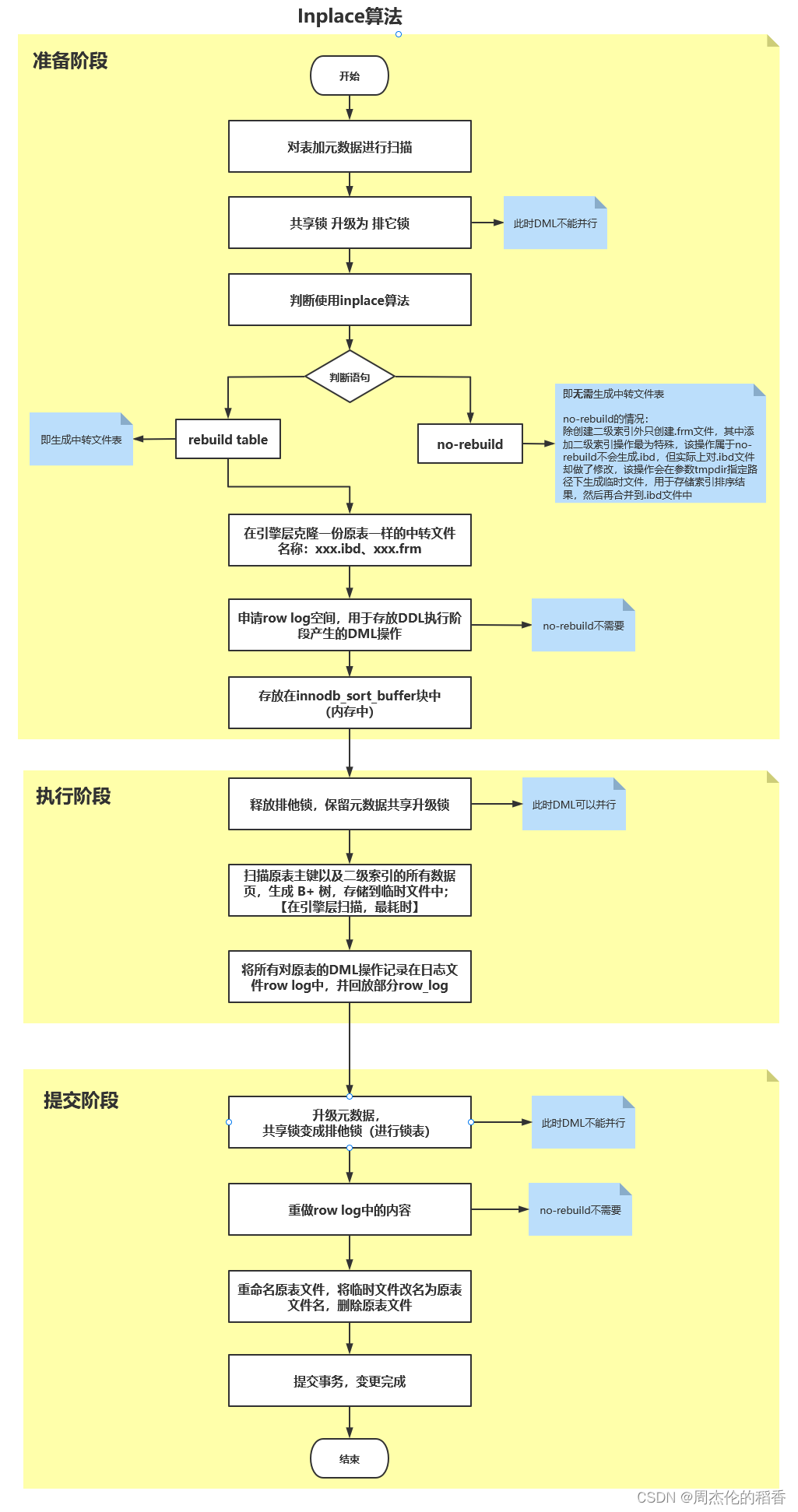
准备(Prepare)
- 对表加元数据共享升级锁,并升级为排他锁(此时DML不能并行)
- 判断使用inplace算法
- 判断语句是”rebulid table“还是”no-rebuild“
- 申请row log空间,用于存放DDL执行阶段产生的DML操作。(no-rebuild不需要)【在 innodb_sort_buffer块中】
那么inplace算法是如何判断是否需要rebuild table的呐?
inplace算法判断是否需要重建新表通常会考虑以下几个因素:
- 表的大小:如果表的大小较小,那么执行"Inplace"修改可能比较快速,并且不会对数据库的整体性能产生太大影响。因此,对于小型表的结构修改,通常不需要进行重建。
- 可用空间:"Inplace"算法还会考虑表的碎片化程度和可用空间大小。如果表的碎片化比较严重,或者表中有足够的连续空闲空间,那么执行"Inplace"修改可能会比较顺利,不需要重建表。
- 修改类型:某些特定类型的结构修改可能无法通过"Inplace"算法进行处理,比如涉及到对表的物理结构有较大改动的情况。在这种情况下,"Inplace"算法可能会判断需要使用重建表的方式来完成修改。
执行(Execute)
- 释放排他锁,保留元数据共享升级锁(此时DML可以并行)
- 扫描原表主键以及二级索引的所有数据页,生成B+Tree,存储到临时文件中;【在engine扫描,最耗时】
- 将所有对原表的DML操作记录在日志文件row log中,并回放部分row_log
提交(Commit)
- 升级元数据共享升级锁,产生排他锁锁表;(此时DDL不能并行)
- 重做row log中的内容;(no-rebuild不需要)
- 重命名原表文件,将临时文件名改名为原表文件名,删除原表文件
- 提交事务,变更完成
inplace算法流程
注意事项:
- 在DDL期间产生的数据,会按照正常操作一样,写入原表,记redolog、undolog、binlog,并同步到从库去执行,只是额外会记录在row log中,并且写入row log的操作本身也会记录redolog
- 而在提交阶段才进行row log重做,此阶段会锁表,此时主库(新表空间+row log)和从库(表空间)数据是一致的,在主库DDL操作执行完成并提交,这个DDL才会写入binlog传到从库执行,在从库执行该DDL时,这个DDL对于从库本地来讲仍然是online的,也就是在从库本地直接写入数据是不会阻塞的,也会像主库一样产生row log。
- 但是对于主库同步过来DML,此时会被阻塞,是offline的,DDL是排他锁的在复制线程中也是一样,所以不只会阻塞该表,而是后续所有从主库同步过来的操作(主要是在复制线程并行时会排他,同一时间只有他自己在执行)。所以大表的DDL操作,会造成同步延迟。
值得思考的是,虽然三个阶段(准备、执行、提交)中,有两个阶段(准备、提交)都无法进行CRUD,但实际上,整个DDL中执行阶段时间占比最长,例如30分钟的DDL,准备+提交阶段只占用1分钟的时间,剩下的29分钟都在执行,那么对于业务层来说,绝大部分时间都是能正常访问的,所以就做到了Oline DDL了。
那么当我们需要在这一分钟之内的时候插入大量的数据哪?

那我们来看一下下面的这个算法。
Instant
- Instant算法是一种特殊的算法,只需修改数据字典中的元数据,无需拷贝数据也无需重建整表,同样,也无需加排他MDL锁,原表数据也不受影响。整个DDL过程几乎是瞬间完成的,也不会阻塞DML。
- 适用场景:适用于对表进行极小范围的结构修改、或者要求对数据库性能影响极小的情况。
这个新特性是8.0.12引入的(腾讯DBA团队贡献)。执行DDL操作时,ALGORITHM选项可以不指定,这时候MySQL按照INSTANT、INPLACE、COPY的顺序自动选择合适的模式。也可以指定ALGORITHM=DEFAULT,也是同样的效果。如果指定了ALGORITHM选项,但不支持的话,会直接报错。
MySQL 8.0.12 才提出的新算法,目前只支持添加列等少量操作(还不是太成熟,企业中一般都是5.6、5.7版本),利用 8.0 新的表结构设计,可以直接修改表的 metadata 数据,省掉了 rebuild 的过程,极大的缩短了 DDL 语句的执行时间。
利用第三方工具实现Online DDL
有一些第三方工具也可以实现 DDL 操作,最常见的是 percona 的 pt-online-schema-change 工具(简称为 pt-osc),和 github 的 gh-ost 工具,均支持 MySQL 5.5 以上的版本。
gh-ost
参考文章:MySQL 最佳实践:gh-ost 工具使用详解
pt-osc
参考文章:PT-OSC在线DDL变更工具使用攻略
一些补充
那么支持Inplace算法的DDL一定是online的吗?
- 从概念上来说,inplace和online是两个不同维度的事
- copy和inplace指的是DDL内部的执行算法,可以理解称成:copy是在server层的操作,inplace是在innodb层的操作
- 其实,对用户来说,关心online与否,通常至于一个问题有关:是否允许并发DML
- 用一句哲学经典术语:copy算法执行的DDL不是online的,inplace算法执行的DDL不一定是online的
总结
常用的DDL的执行方式:
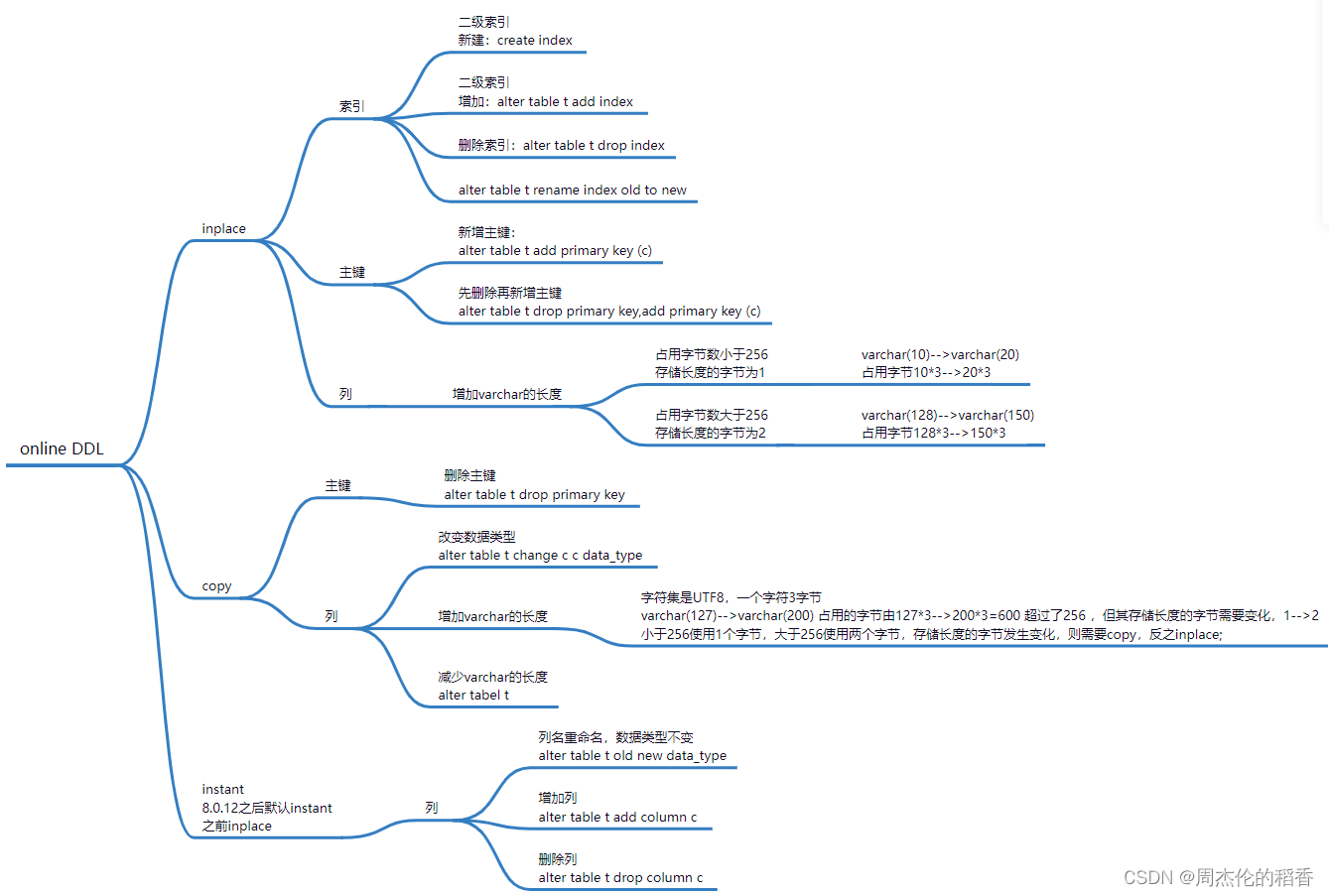
DDL语句使用的算法及是否允许并发DML,是否需要重建表等,可参考
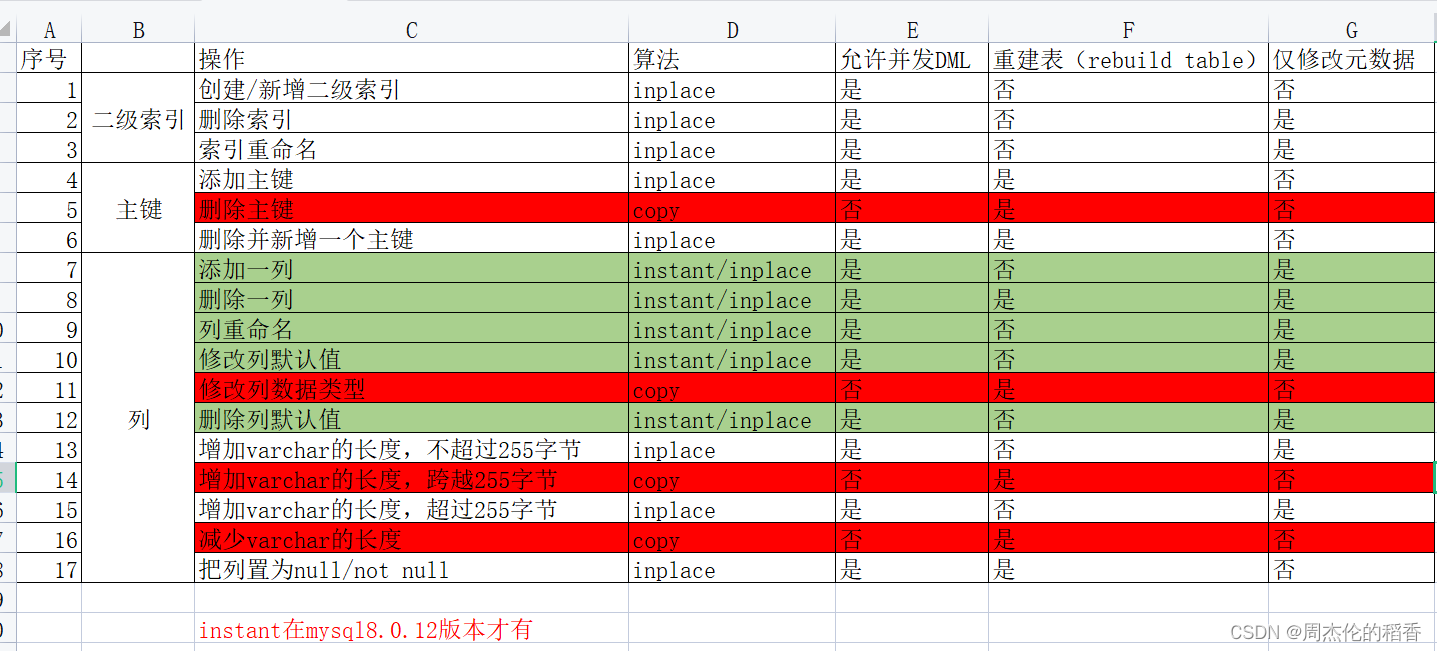
Online DDL语法
ALTER TABLE tbl_name ADD COLUMN col_name col_type, ALGORITHM=INPLACE, LOCK=NONE;其中的ALGORITHM有如下选择:
- INPLACE:替换:直接在原表上面执行DDL的操作。
- COPY:复制:使用一种临时表的方式,克隆出一个临时表,在临时表上执行DDL,然后再把数据导入到临时表中,在重命名等。这期间需要多出一倍的磁盘空间来支撑这样的 操作。执行期间,表不允许DML的操作。
- INSTSNT:
- DEFAULT:默认方式,有MySQL自己选择,优先使用INPLACE的方式。
其中的LOCK有如下选项:
- SHARE:共享锁,执行DDL的表可以读,但是不可以写。
- NONE:没有任何限制,执行DDL的表可读可写
- EXCLUSIVE:排它锁,执行DDL的表不可以读,也不可以写。
- DEFAULT:默认值,也就是在DDL语句中不指定LOCK子句的时候使用的默认值。如果指定LOCK的值为DEFAULT,那就是交给MySQL子句去觉得锁还是不锁表。不建议使用,如果你确定你的DDL语句不会锁表,你可以不指定lock或者指定它的值为default,否则建议指定它的锁类型。
执行DDL操作时,ALGORITHM选项可以不指定,这时候MySQL按照INSTANT、INPLACE、COPY的顺序自动选择合适的模式。也可以指定ALGORITHM=DEFAULT,也是同样的效果。如果指定了ALGORITHM选项,但不支持的话,会直接报错。


![P1529 [USACO2.4] 回家 Bessie Come Home 题解](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)