文章目录
- 一、Linux内核怎么设计各种结构
- 二、进程优先级
- 1.基本概念
- 2.是什么
- 3.为什么要有优先级
- 4.批量化注释操作
- 5.查看优先级
- 6.PRI and NI
- 三、位图与优先级
一、Linux内核怎么设计各种结构
我们前面所写的数据结构都是比较单纯的。
而linux中就比较复杂了,同一个结点可能既处于链表,也处于队列,也处于树中。是极其复杂的
我们可以这样简单的理解为,在一个PCB中,有链表的指针,也有队列的指针,也有树的指针等待。
即如下的情况
struct node
{
struct node* prev;
struct node* next;
};
struct task_struct
{
//各种属性
//....
struct node link;
};
也就是和我们之前的是刚好相反的,我们是将指针给存储起来的
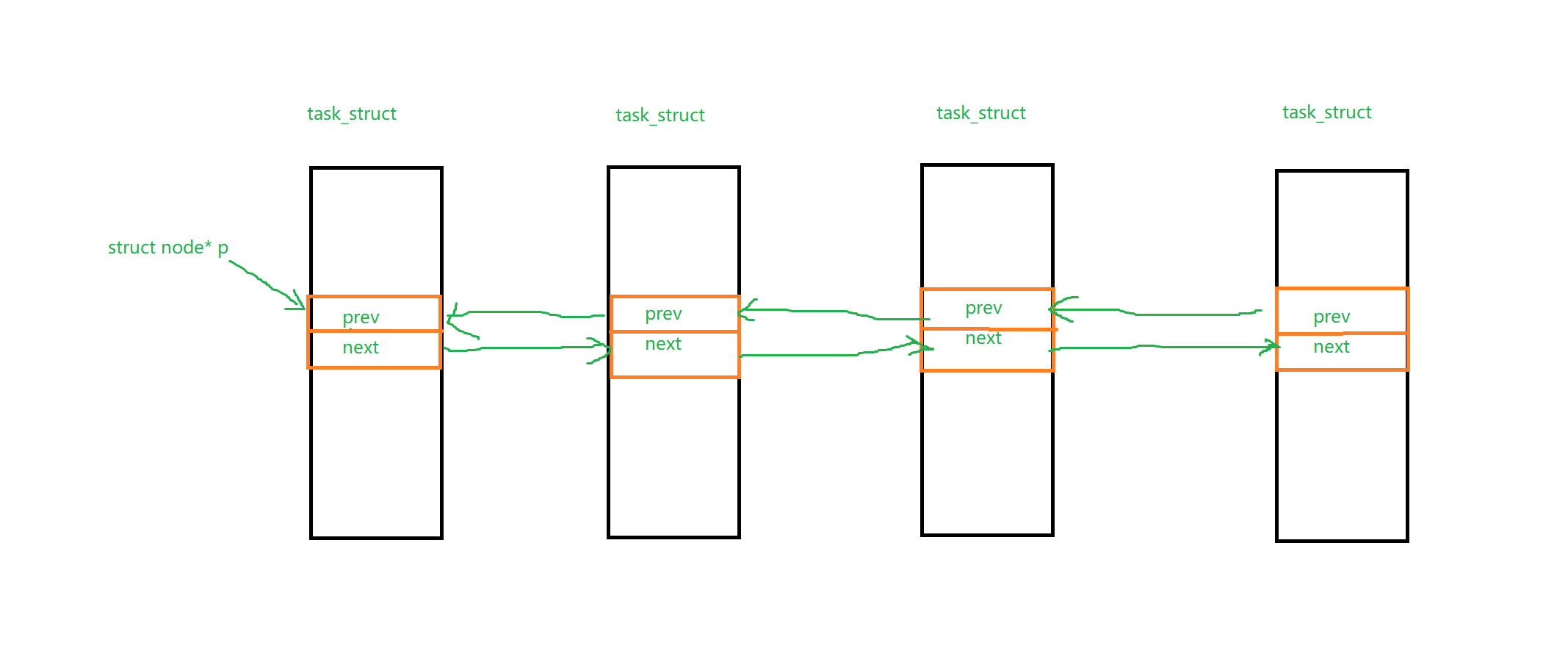
这里的指针指向只是在内部的指针进行寻找进程的,如果我们想要找到这个进程的起点,我们可以这样做
(task_struct*)((int)p - (int)&((task_struct*)0->link))
这样就可以找到起始地址了
然后我们就可以直接去找到其他属性了
同样的,如果想将这个放到其他的结构体内,只需要将结点指针直接往里定义即可。
二、进程优先级
1.基本概念
- cpu资源分配的先后顺序,就是指进程的优先权(priority)。
- 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。(可能改善)
- 还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能
2.是什么
优先级和权限的区别是什么?
优先级解决的是对于资源的访问,谁先访问,谁后访问?
权限解决的是能不能访问
3.为什么要有优先级
因为资源是有限的,进程是多个的,注定了,进程之间是竞争关系! ----竞争性
操作系统必须保证大家良性竞争,必须要确认优先级。
但是如果我们进程长时间得不到CPU资源,该进程的代码长时间无法得到推进----就出现了该进程的饥饿问题。
4.批量化注释操作
当我们注释代码的时候,可能会非常麻烦,所以,我们就需要批量化注释操作
操作如下
- 按住CTRL + V
- 通过HJKL左下上右四个方向键来选中区域。
- 按住Shift + i,即大写I,进入插入模式
- 按//
- 按ESC
如果我们想要取消批量化注释,那么操作如下
- 按住CTRL + V
- 通过HJKL选中区域
- 直接按d
5.查看优先级
我们可以用这个简单的代码来测试

我们可以使用ps命令带上-l选项来查看到
ps -l
不过上述命令存在一个问题,就是我们是两个终端的,上面默认只能查看一个终端进程,如下所示
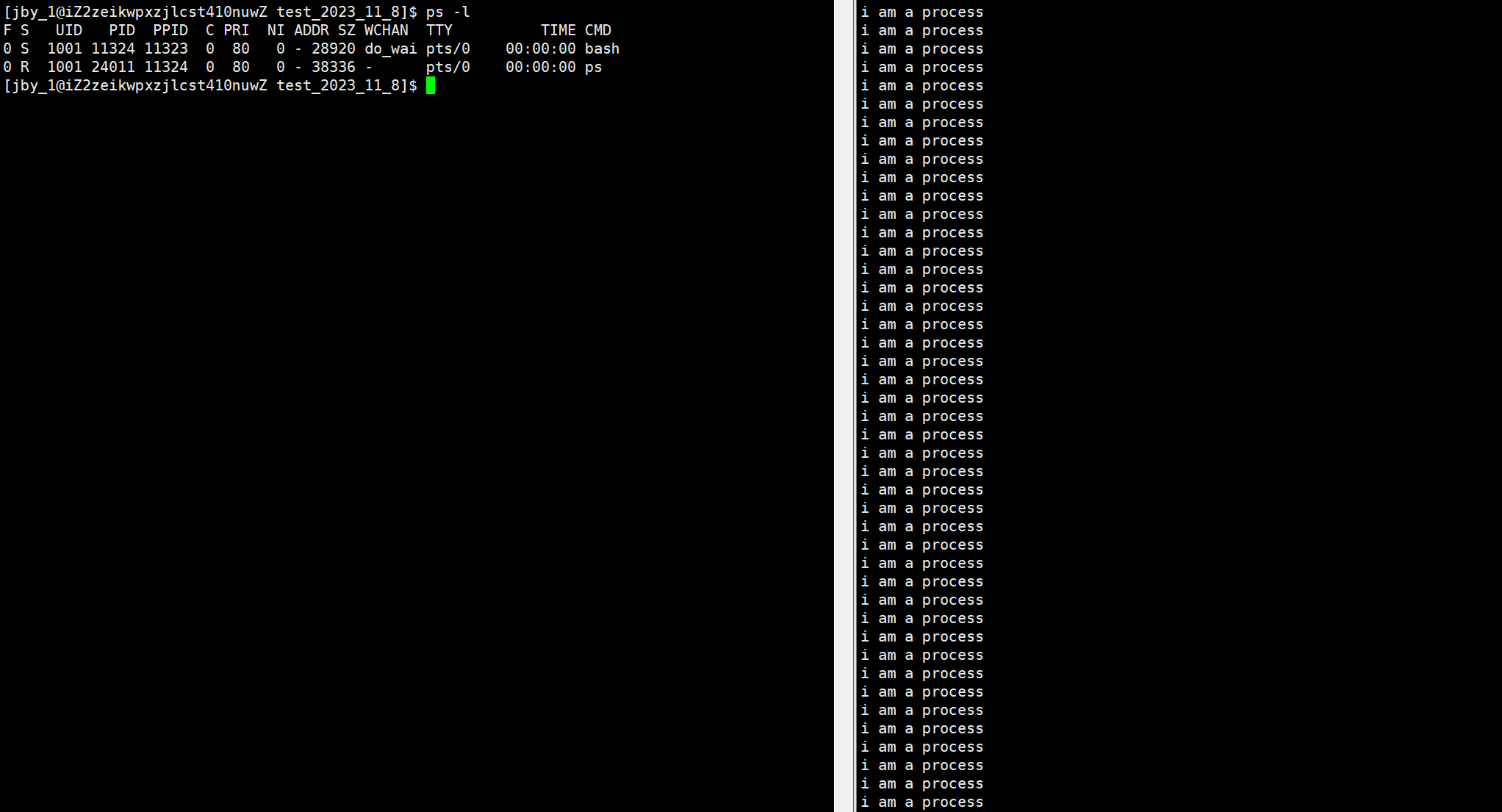
为了可以查看到其他终端的进程,我们可以加上a选项
ps -al

为了方便,我们可以将我们想要的那部分给拿出来
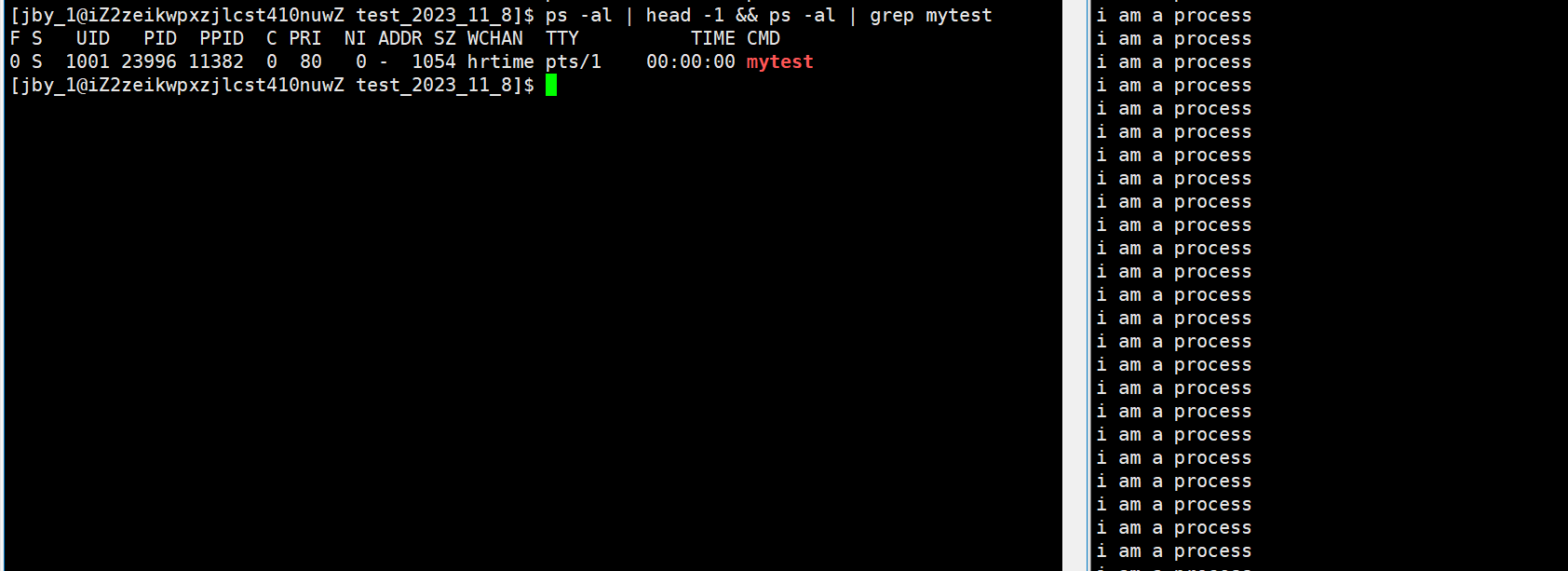
在这里,我们重点查看的就是这两个

这个PRI既是传说中的优先级。(priority单词的简写)
NI这个是进程优先级的修正数据(nice值)
下面是这些数据的含义
- UID : 代表执行者的身份
- PID : 代表这个进程的代号
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- PRI :代表这个进程可被执行的优先级,其值越小越早被执行
- NI :代表这个进程的nice值
对于UID,它才是linux系统中真正识别一个文件的东西。
因为linux系统根本不认文件名。只认UID
比如可以直接使用ls命令就可以看到UID,如果带上n就会显示UID
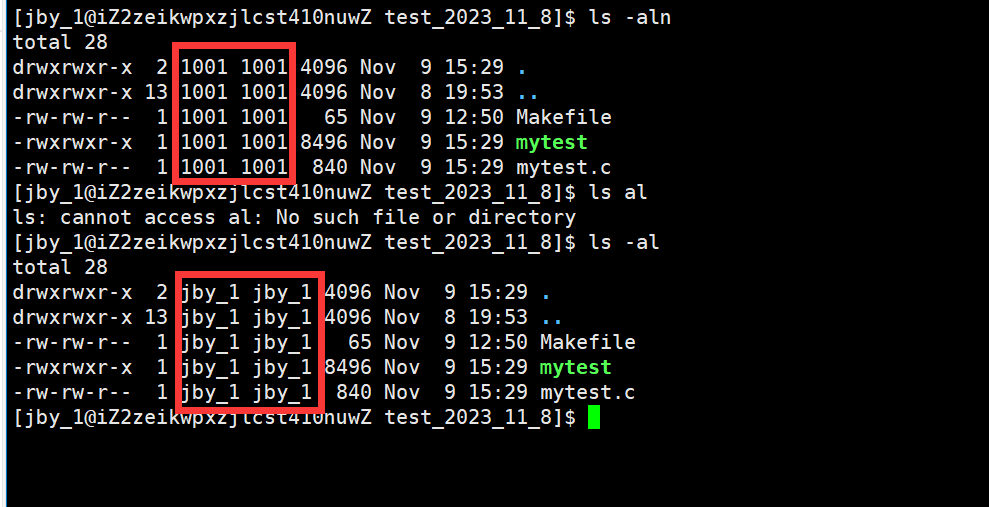
在下面的这个PRI中,在linux中,这个数字是一个整数,这个PRI越小,优先级越高,越早被执行

6.PRI and NI
- PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小,程的优先级别越高
- 那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值
- PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice
- 这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行
- 所以,调整进程优先级,在Linux下,就是调整进程nice值
- nice其取值范围是-20至19,一共40个级别
注意事项
- 需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
- 可以理解nice值是进程优先级的修正修正数据
如果要更改nice值,那么可以使用如下指令
nice
renice
具体使用方法可以使用man手册
我们也可以使用top命令来更改优先级
我们使用如下代码
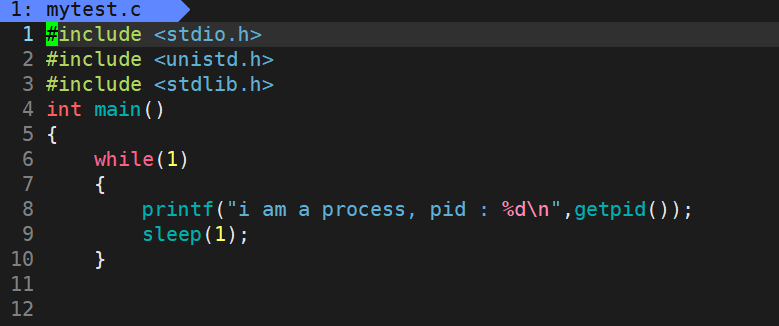
然后我们可以先查看一下默认优先级,为80

然后我们现在更改优先级,先使用top命令,然后按一下R
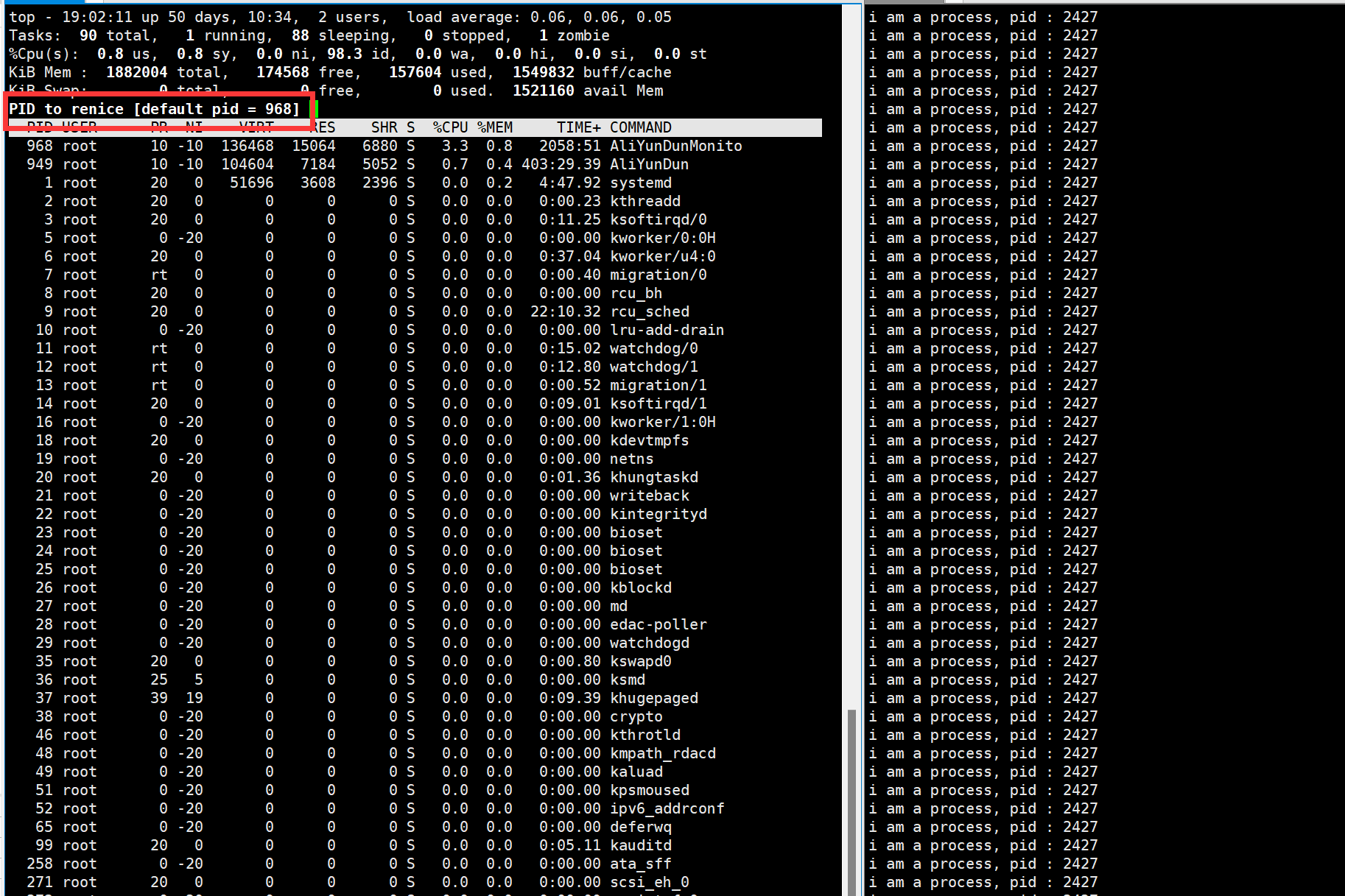
然后输入要更改优先级的PID,我们这里是2427
然后会让我们修改多少
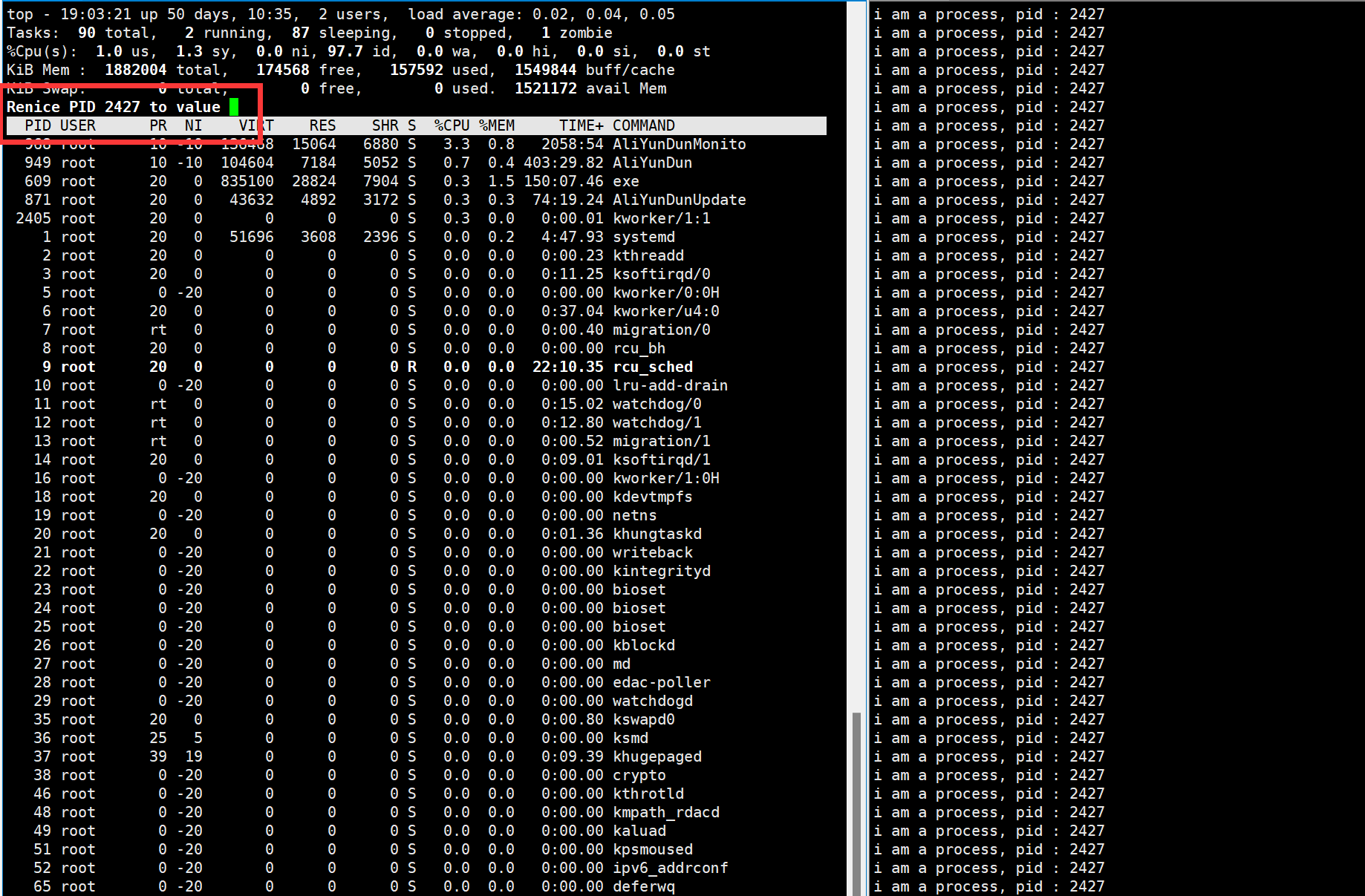
虽然我们知道修改范围是-20至19,但是我们可以先尝试一下-30
我们可以看到,这里我们没有权限,所以我们可以使用su指令先换为root在来尝试一下
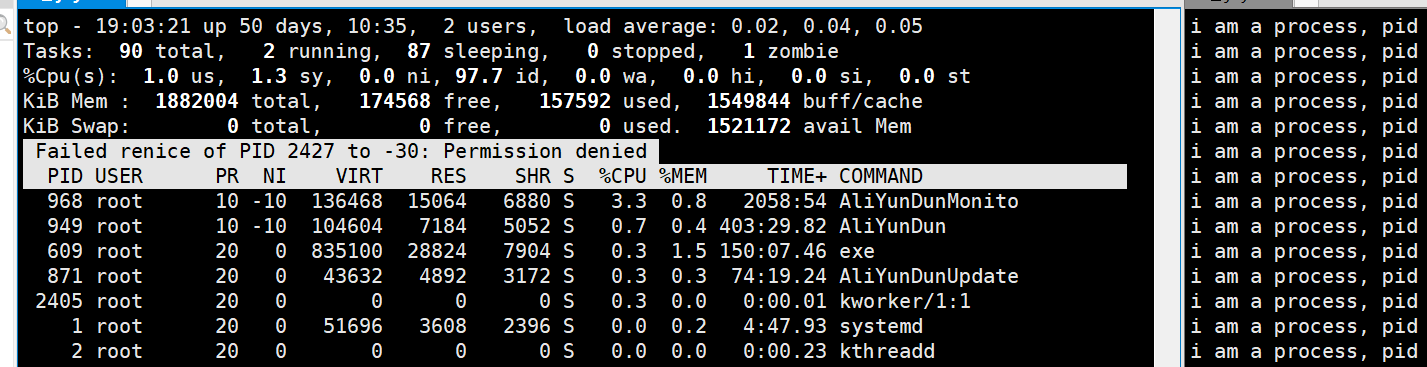
这一下,我们发现,修改成功了。最终结果如下所示

不过我们会发现,虽然我们修改的是30,但是最终的结果是-20,也就是说不会超过这个范围
但是假如,我们继续再次调整之后,我们为他+100
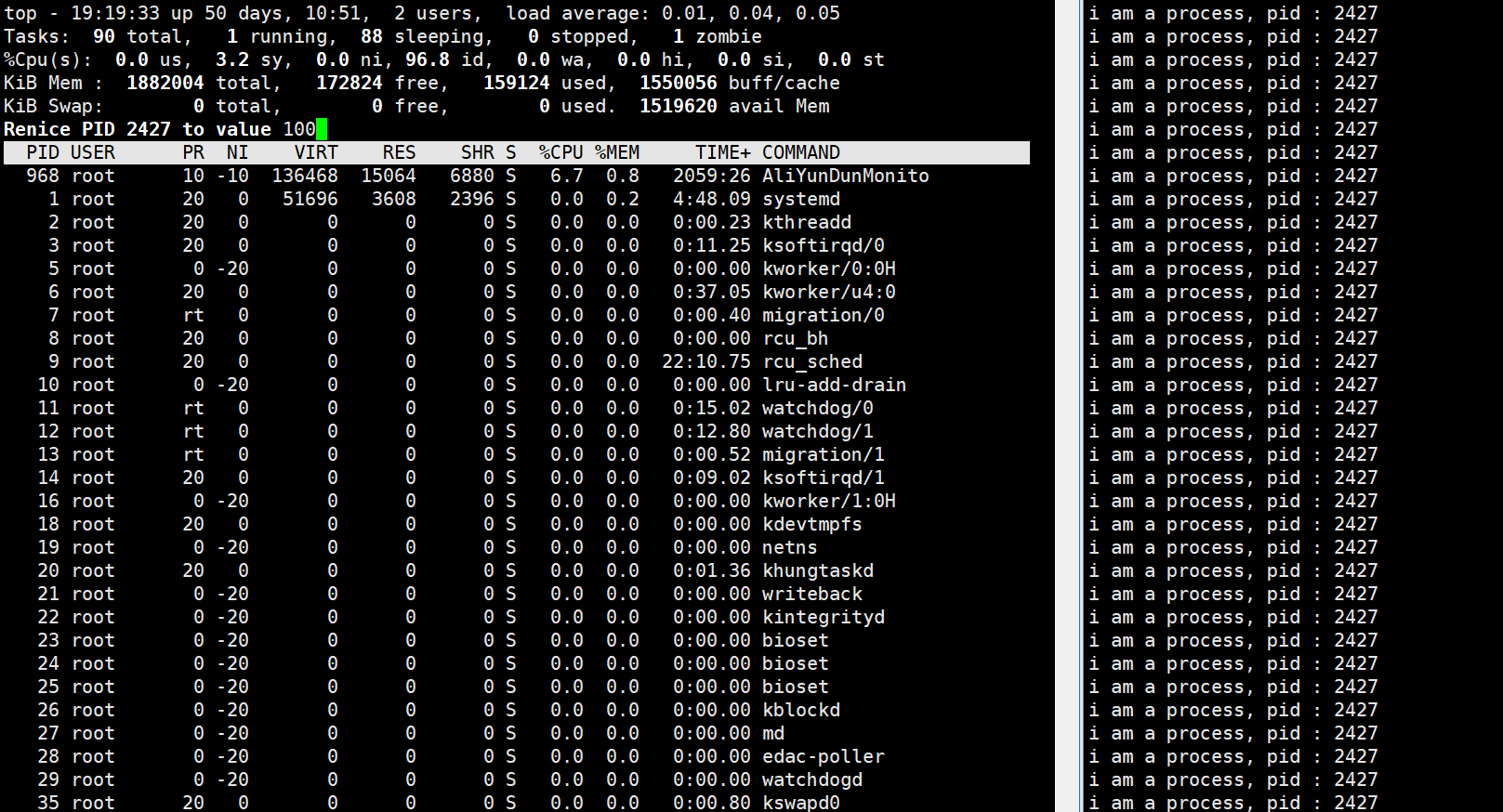
最终结果如下,是99
可见,实际的最终的优先级PRI = PRI(旧) + NI,其中,这个旧的PRI一般都是80
三、位图与优先级
操作系统是如何根据优先级,开展的调度呢??
其实这是因为里面使用了一种哈希的做法
里面会有这样一个结构体
struct runqueue
{
task_struct* running[140]
task_struct* waiting[140]
//........
}
在这个结构体中,两个数组
这个数组的大小一般是140个,但是[0,99]是其他种类的进程用的。只有[100,139]这40个刚好是我们优先级时候所用的
而我们的优先级一般会从[60,99],会先将这个转化为[100,139]之间
然后使用开散列去一一映射。这样就可以直接按照优先级排好队了
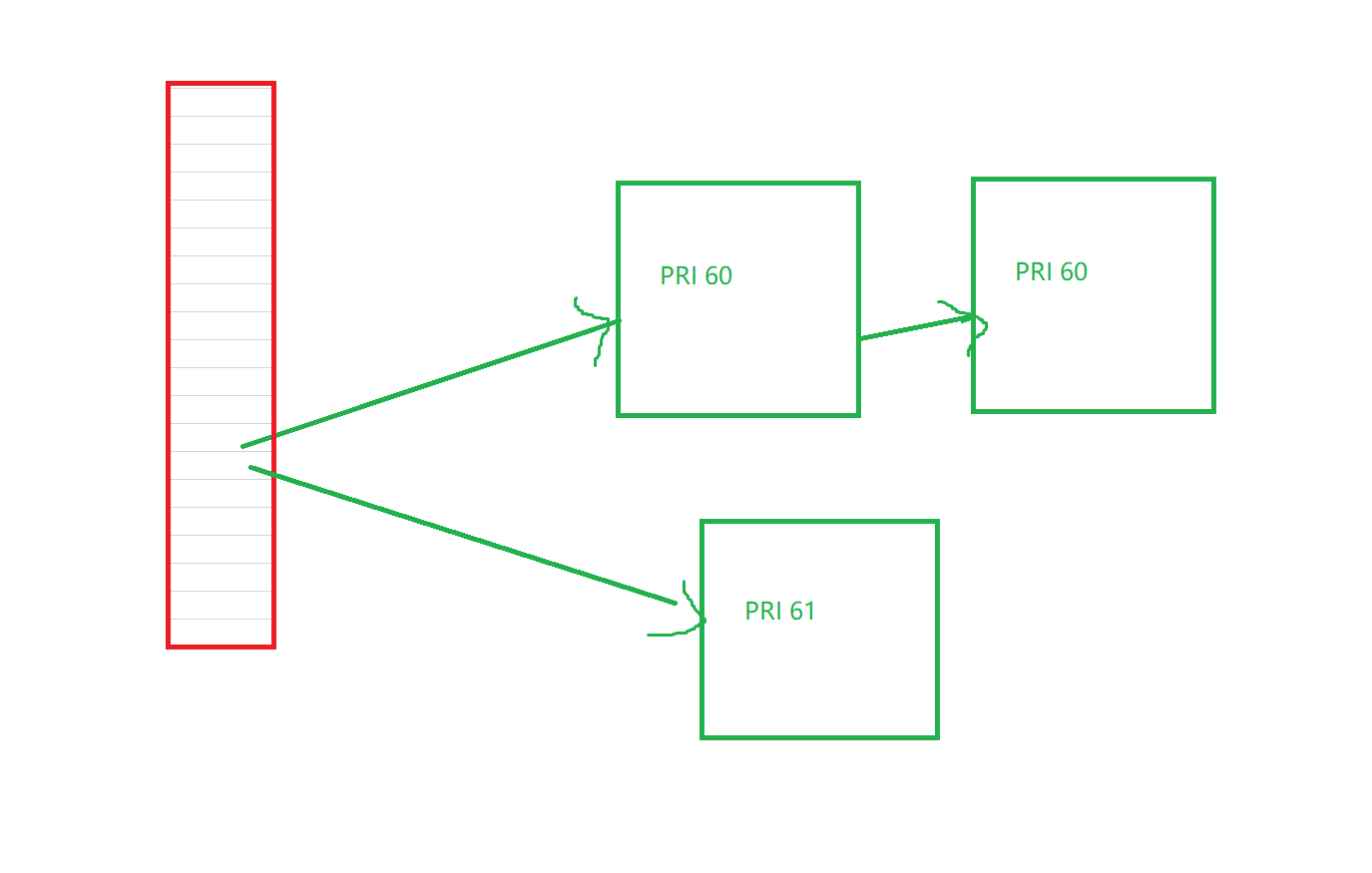
不过这里我们只是使用了一个数组,但是我们上面还写一个数组是用来干什么呢?
这是因为有时候,当我们正在调度一个队列的时候,可能还有新的进程过来。这时候,我们既要向这个队列插入进程,又要移走进程,这不是一个好现象。
所以我们还维护了一个一模一样的镜像队列。
struct runqueue
{
task_struct** run;
task_struct** wait;
task_struct* running[140]
task_struct* waiting[140]
//........
}
如上所示,run指向running,wait指向waiting。
这样的话,当我们正在调度run队列的时候,我们这个run队列就不可以插入数据了。只能根据优先级在wait队列中插入。
当run的队列一旦被处理完了,只需要将这两个指针的指向进行一次交换。此时我们就又有了一批需要处理的进程。
不过,在判断处理完的时候,我们现在只能一遍一遍的遍历,这里的话时间复杂度太高。我们可以在开一个位图,用来判断每一个位是否位空
struct runqueue
{
bitset<140> isempty;
task_struct** run;
task_struct** wait;
task_struct* running[140]
task_struct* waiting[140]
//........
}
这样我们就可以以O(1)的复杂度去调度进程
这样的算法也叫做,Linux内核的O(1)调度算法