倒排索引
将文档中的内容分词,然后形成词条。记录每条词条与数据的唯一表示如id的对应关系,形成的产物就是倒排索引,如下图:
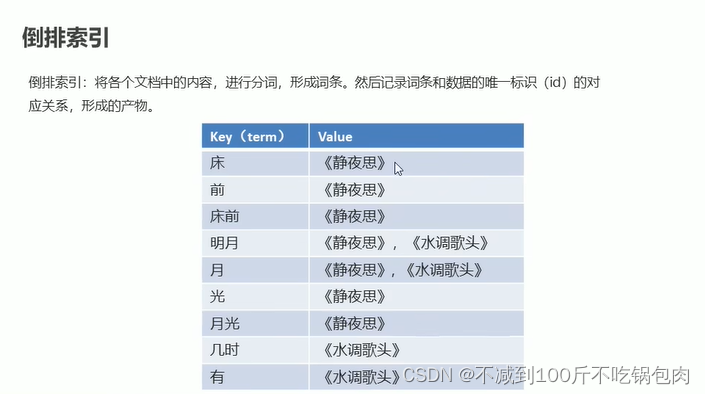
ElasticSearch数据的存储和搜索原理

这里的索引库相当于mysql中的database。一个文档(document)是一个可被索引的基础信息单元。
查询逻辑:根据词条去匹配查询,可以对搜索关键字先分词在查询。es中自动会对词条排序,形成一个树形的结构
ElasticSearch概念
- ElasticSearch是一个基于Lucene的搜索服务器
- 是一个分布式、高扩展、高实时的搜索与数据分析引擎
- 基于RESTfur web接口
- 流行的企业级搜索引警 Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种
- ElasticSearch和MySql分工不同,MySQL负责存储数据,ElasticSearch负责搜索数据
应用场景
- 搜索:海量数据的查询
- 日志数据分析
- 实时数据分析
映射(maping)
相当于数据库的表结构,也就是定义不同字段的类型
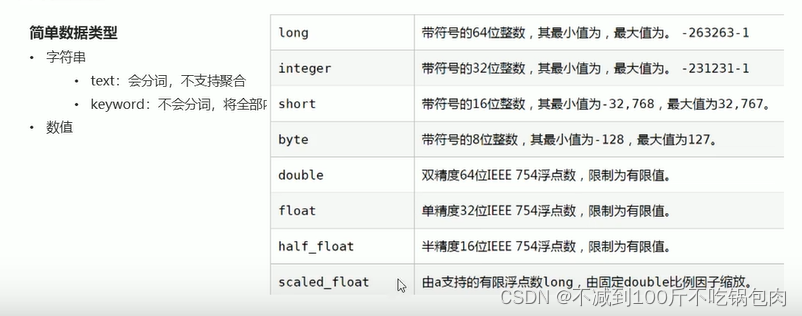
简单数据类型
1、字符串
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合
2、数值
3、布尔 boolean
4、二进制 .binary
范国类型
integer range, float range, long range, double range, date range
复杂数据类型
- 数组:[]
- 对象:()
文档操作
添加文档,指定id
put 索引/_doc/id{添加内容}
添加文档,不指定id
post 索引/_doc{添加内容}
查询指定id的文档
get 索引/_doc/id
查询所有文档
get 索引/_doc/_search
IK分词器
java开发的轻量级的中文分词器
springboot整合es
1、引入es的RestHighLevelClient依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2、初始化RestHighLevelClient:
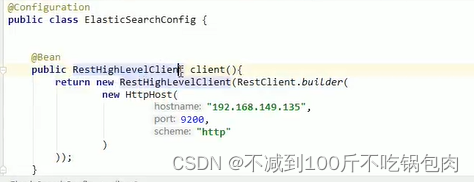
导入client
@Autowiredprivate
RestHighLevelClient client;
索引操作
操作索引对象的对象是indicesClient,使用create函数
参数:
Createindexrequest、请求类型
获取为getIndexrequest
删除为Deleteindexrequest
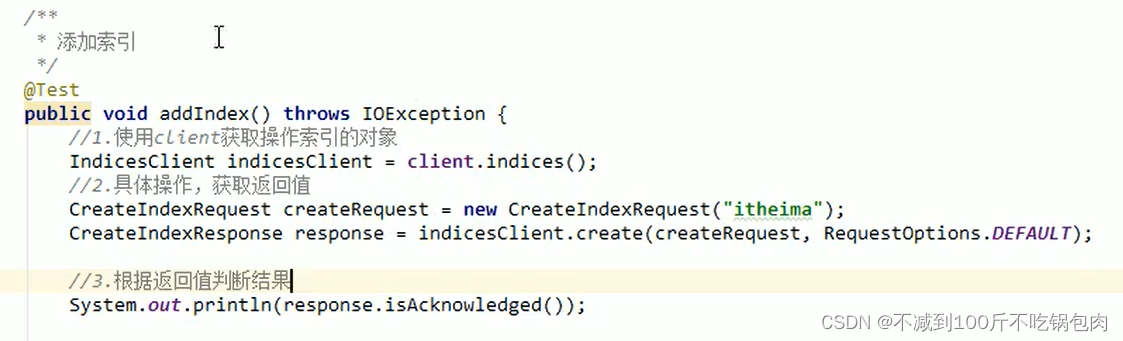 也可以添加mapping
也可以添加mapping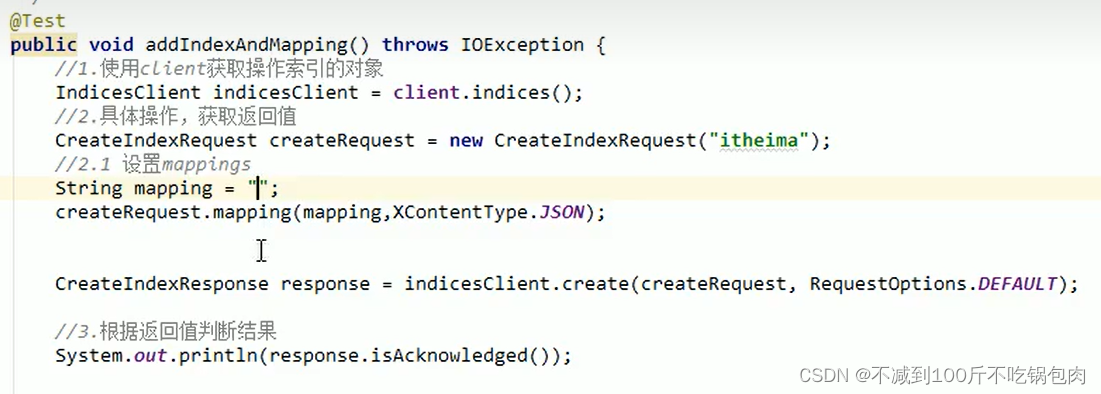
文档操作
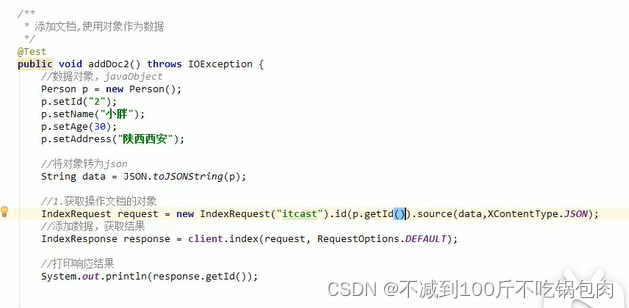
获取操作文档的对象:indexrequest
添加需要在indexrequest中设定索引、id、以及添加的数据(JSON)
修改:indexrequest
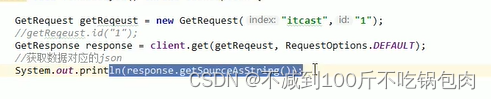
查询:getrequest
Bulk批量操作
Elient.bulk(bulkRequest , RequestOptions.DEFAULT);
解释:
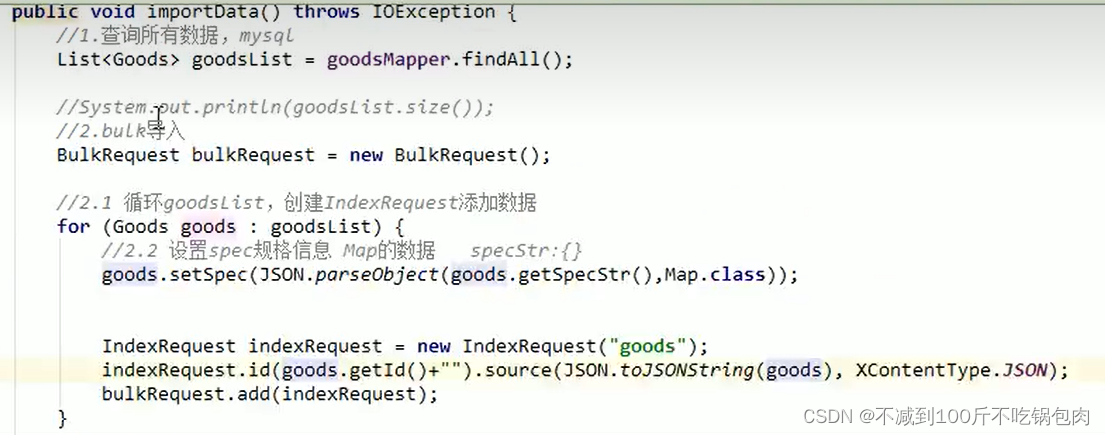
1、创建mybatis的map映射,并创建实例对象接收
2、查询mysql数据、存入到对象中
3、创建bulkrequest对象,操作批量操作
4、遍历查询结果,对不符合es映射规定的字段格式的进行转换、并添加到indexrequest中,在添加到bulkrequest中
6、调用client的bulk操作,批量插入
模糊查询
1、wildcard查询:会对查询条件进行分词。还可以使用通配符?(任意单个字符)和 * (0个或多个字符)
2、prefix查询:前缀查询
# wildcard 查询。查询条件分词,模糊查询
GET goods/_search
"query":(
"wildcard":{
"title":
"value":"华?

java代码:
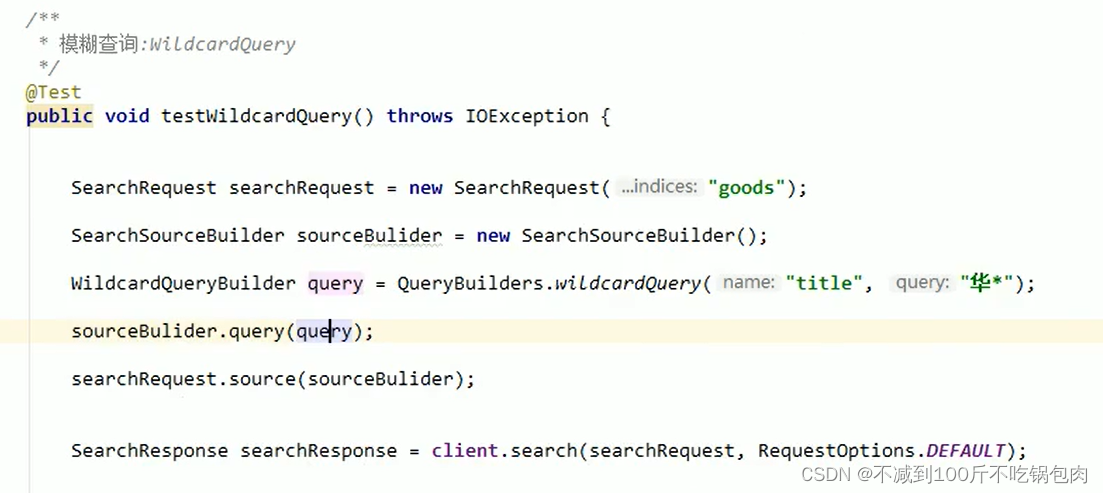
前缀查询;

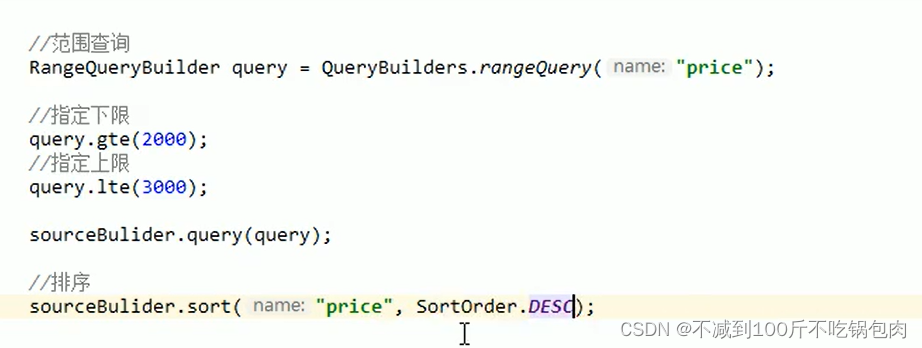
范围查询
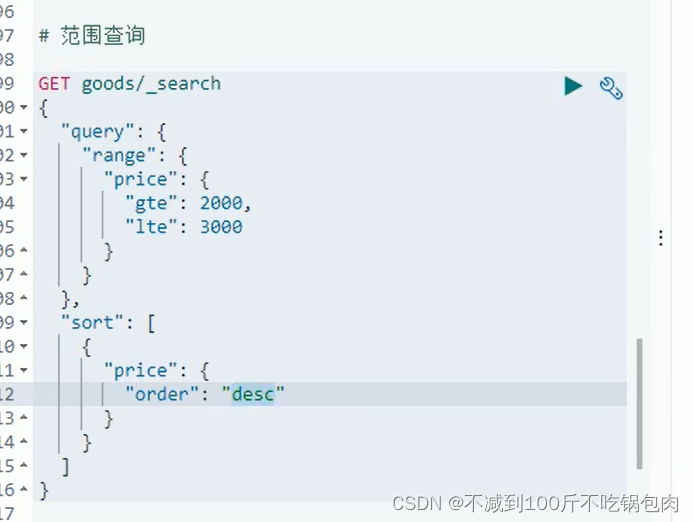 java代码:
java代码:
同样只需要修改query这个参数信息就行
布尔查询
脚本:
boolQuery:对多个查询条件连接。连接方式:
must (and):条件必须成立
must not (not):条件必须不成立
should (or):条件可以成立
filter: 条件必须成立,性能比must高。不会计算得分

高亮查询
高亮的三要素:
高亮字段、前缀、后缀
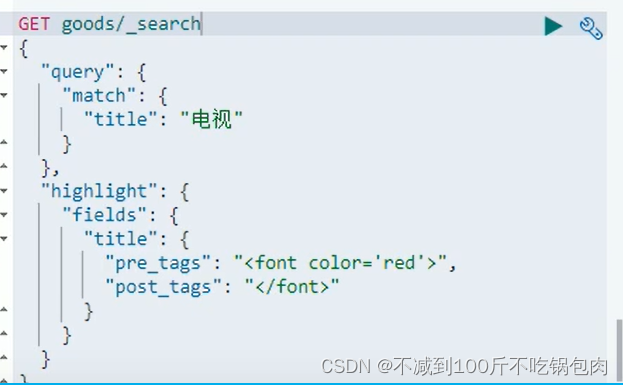
java代码:
1、设置高亮
//设置高亮
HighlightBuilder highlighter = new HighlightBuilder()://
设置三要素
highlighter.field("title");
highlighter.preTags("<font color='red'>");
highlighter.postTags("</font>");
2、用高亮的结果代替原有的结果
// 获取高亮结果,替换goods中的title
Map<String,HighlightField> highlightFields = hit,getHighlightFields().
HighlightField HighlightField = highlightFields.get("title");
Text[] fragments = HighlightField.fragments();//这里的fragments是表示我们的拿到是一个一个的高亮片段,包含了不同区域的高亮
//替换goods.setTitle(fragments[e].tostring()):
第二步为从查询到hit中的hightlight代替原有的字段
2、黑马头条es实践
2.1)搭建搜索微服务
(1)导入 heima-leadnews-search
(2)在heima-leadnews-service的pom中添加依赖
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.0</version>
</dependency>
(3)nacos配置中心leadnews-search
spring:
autoconfigure:
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:
host: 192.168.200.130
port: 9200
2.2) 搜索接口定义
package com.heima.search.controller.v1;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {
@PostMapping("/search")
public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {
return null;
}
}
UserSearchDto
package com.heima.model.search.dtos;
import lombok.Data;
import java.util.Date;
@Data
public class UserSearchDto {
/**
* 搜索关键字
*/
String searchWords;
/**
* 当前页
*/
int pageNum;
/**
* 分页条数
*/
int pageSize;
/**
* 最小时间
*/
Date minBehotTime;
public int getFromIndex(){
if(this.pageNum<1)return 0;
if(this.pageSize<1) this.pageSize = 10;
return this.pageSize * (pageNum-1);
}
}
2.3) 业务层实现
创建业务层接口:ApArticleSearchService
package com.heima.search.service;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.model.common.dtos.ResponseResult;
import java.io.IOException;
public interface ArticleSearchService {
/**
ES文章分页搜索
@return
*/
ResponseResult search(UserSearchDto userSearchDto) throws IOException;
}
实现类:
package com.heima.search.service.impl;
import com.alibaba.fastjson.JSON;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.model.user.pojos.ApUser;
import com.heima.search.service.ArticleSearchService;
import com.heima.utils.thread.AppThreadLocalUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* es文章分页检索
*
* @param dto
* @return
*/
@Override
public ResponseResult search(UserSearchDto dto) throws IOException {
//1.检查参数
if(dto == null || StringUtils.isBlank(dto.getSearchWords())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.设置查询条件
SearchRequest searchRequest = new SearchRequest("app_info_article");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//关键字的分词之后查询
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);
boolQueryBuilder.must(queryStringQueryBuilder);
//查询小于mindate的数据
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());
boolQueryBuilder.filter(rangeQueryBuilder);
//分页查询
searchSourceBuilder.from(0);
searchSourceBuilder.size(dto.getPageSize());
//按照发布时间倒序查询
searchSourceBuilder.sort("publishTime", SortOrder.DESC);
//设置高亮 title
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//3.结果封装返回
List<Map> list = new ArrayList<>();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
Map map = JSON.parseObject(json, Map.class);
//处理高亮
if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){
Text[] titles = hit.getHighlightFields().get("title").getFragments();
String title = StringUtils.join(titles);
//高亮标题
map.put("h_title",title);
}else {
//原始标题
map.put("h_title",map.get("title"));
}
list.add(map);
}
return ResponseResult.okResult(list);
}
}
2.4) 控制层实现
新建控制器ArticleSearchController
package com.heima.search.controller.v1;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {
@Autowired
private ArticleSearchService articleSearchService;
@PostMapping("/search")
public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {
return articleSearchService.search(dto);
}
}
3.5.5) 测试
需要在app的网关中添加搜索微服务的路由配置
#搜索微服务
- id: leadnews-search
uri: lb://leadnews-search
predicates:
- Path=/search/**
filters:
- StripPrefix= 1
新增文章同步添加索引
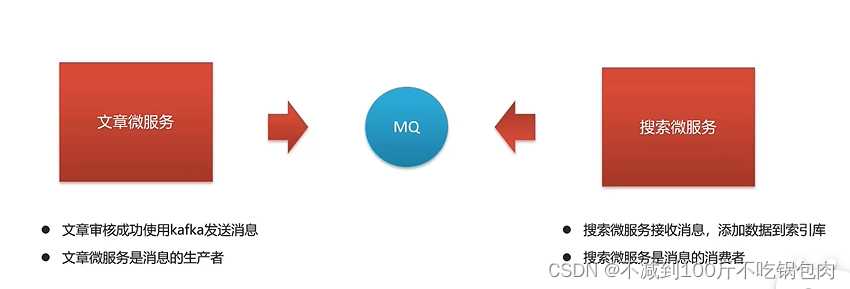
1、把SearchArticleVo放到model工程下
2、文章微服务的ArticleFreemarkerService中的buildArticleToMinIO方法中收集数据并发送消息
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 送消息,创建索引
* @param apArticle
* @param content
* @param path
*/
private void createArticleESIndex(ApArticle apArticle, String content, String path) {
SearchArticleVo vo = new SearchArticleVo();
BeanUtils.copyProperties(apArticle,vo);
vo.setContent(content);
vo.setStaticUrl(path);
kafkaTemplate.send(ArticleConstants.ARTICLE_ES_SYNC_TOPIC, JSON.toJSONString(vo));
}
3、文章微服务集成kafka发送消息
kafka:
bootstrap-servers: 192.168.200.130:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
4、搜索微服务中添加kafka的配置,nacos配置如下
spring:
kafka:
bootstrap-servers: 192.168.200.130:9092
consumer:
group-id: ${spring.application.name}
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
5.定义监听接收消息,保存索引数据
@Component
@Slf4j
public class SyncArticleListener {
@Autowired
private RestHighLevelClient restHighLevelClient;
@KafkaListener(topics = ArticleConstants.ARTICLE_ES_SYNC_TOPIC)
public void onMessage(String message){
if(StringUtils.isNotBlank(message)){
log.info("SyncArticleListener,message={}",message);
SearchArticleVo searchArticleVo = JSON.parseObject(message, SearchArticleVo.class);
IndexRequest indexRequest = new IndexRequest("app_info_article");
indexRequest.id(searchArticleVo.getId().toString());
indexRequest.source(message, XContentType.JSON);
try {
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
log.error("sync es error={}",e);
}
}
}