import requests
from bs4 import BeautifulSoup
import json
# 定义代理信息
proxy_host = 'www.duoip.cn'
proxy_port = 8000
# 定义要爬取的url
url = 'http://localhost:9200/_search'
# 创建一个requests.Session对象,并设置代理
session = requests.Session()
session.proxies = {'http': f'http://jshk.com.cn}:{proxy_port}'}
# 发送GET请求,获取网页内容
response = session.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有的elasticsearch返回结果的json数据
json_data = soup.find_all('script', type_='application/json')
# 将json数据转换为Python字典
data = [json.loads(json_data[i].string) for i in range(len(json_data))]
# 打印数据
for item in data:
print(item)
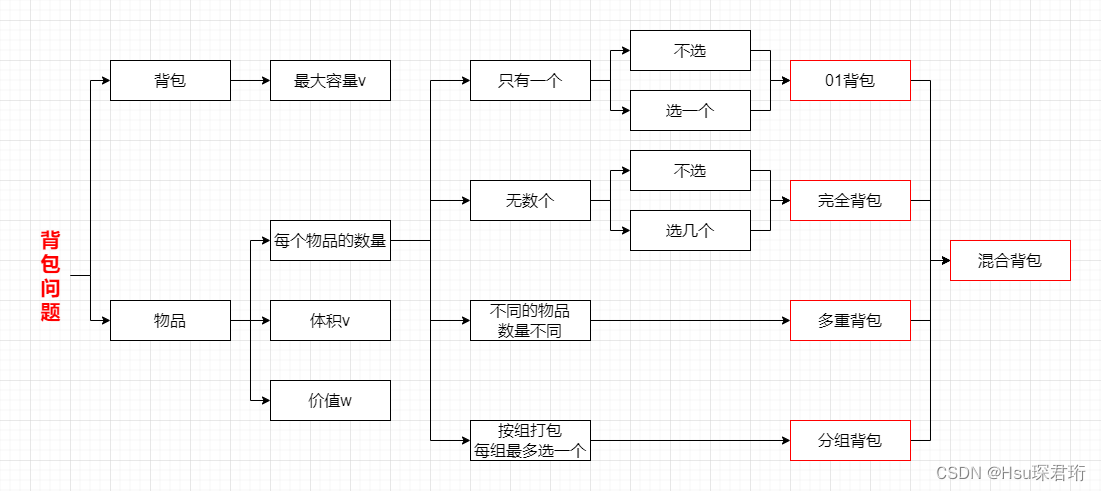
步骤:
- 导入需要的库:requests,BeautifulSoup,json。
- 定义代理信息,这里使用的是一个免费的代理服务网站。
- 定义要爬取的url,这里爬取的是Elasticsearch的搜索结果。
- 创建一个requests.Session对象,并设置代理。
- 使用requests的get方法发送GET请求,获取网页内容。
- 使用BeautifulSoup解析网页内容,找到所有的json数据。
- 使用json.loads将json数据转换为Python字典。
- 打印数据。