文章目录
- 什么是Spark
- Spark的特点
- Spark vs Hadoop
- Spark+Hadoop
- Spark集群安装部署
- Spark集群安装部署
- Standalone
- ON YARN
- Spark的工作原理
- 什么是RDD
- RDD的特点
- Spark架构相关进程
- Spark架构原理
- Spark实战:单词统计
- Scala代码开发
- java代码开发
- 任务提交
- Transformation与Action开发
- 创建RDD
- 使用集合创建RDD
- 使用本地文件和HDFS文件创建RDD
- Transformation和Action
- 常用Transformation介绍
- Transformation操作开发实战
- 常用Action介绍
- Action操作开发实战
- RDD持久化
- RDD持久化原理
- RDD持久化策略
- 如何选择RDD持久化策略
- 案例:使用RDD的持久化
- 共享变量
- 共享变量的工作原理
- Broadcast Variable
- Accumulator
什么是Spark
Spark是一个用于大规模数据处理的统一计算引擎
注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎,Spark里面最重要的一个特性:内存计算
Spark中一个最重要的特性就是基于内存进行计算,从而让它的计算速度可以达到MapReduce的几十倍甚至上百倍,Spark是一个基于内存的计算引擎
Spark的特点
- Speed:速度快
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍。
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理。
注意:批处理其实就是离线计算,流处理就是实时计算,只是说法不一样罢了,意思是一样的
- Easy of Use:易用性

Spark的易用性主要体现在两个方面
- 可以使用多种编程语言快速编写应用程序,例如Java、Scala、Python、R和SQL
- Spark提供了80多个高阶函数,可以轻松构建Spark任务。
这个图中的代码,spark可以直接读取json文件,使用where进行过滤,然后使用select查询指定字段中的值
-
Generality:通用性
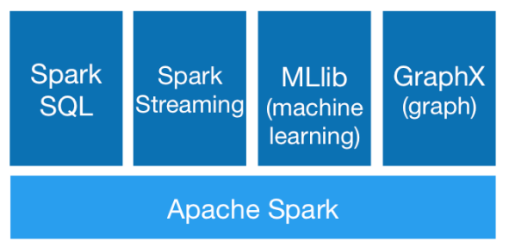
Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务。从这可以看出来Spark也是一个具备完整生态圈的技术框架,它不是一个人在战斗。 -
Runs Everywhere:到处运行

你可以在Hadoop YARN、Mesos或Kubernetes上使用Spark集群。并且可以访问HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive和数百个其它数据源中的数据
Spark vs Hadoop
我们通过三个层面进行对比分析
- 综合能力
Spark是一个综合性质的计算引擎
Hadoop既包含MapReduce(计算引擎),还包含HDFS(分布式存储)和Yarn(资源管理)。 所以说他们两个的定位是不一样的。从综合能力上来说,hadoop是完胜spark的
2. 计算模型
Spark 任务可以包含多个计算操作,轻松实现复杂迭代计算。而Hadoop中的MapReduce任务只包含Map和Reduce阶段,不够灵活。从计算模型上来说,spark是完胜hadoop的
- 处理速度
Spark 任务的数据是基于内存的,计算速度很快。而Hadoop中MapReduce 任务是基于磁盘的,速度较慢。从处理速度上来说,spark也是完胜hadoop的。之前有一种说法,说Spark将会替代Hadoop,这个说法是错误的,其实它们两个的定位是不一样的,Spark是一个通用的计算引擎,而Hadoop是一个包含HDFS、MapRedcue和YARN的框架,所以说Spark就算替代也只是替代Hadoop中的MapReduce,也不会整个替代Hadoop,因为Spark还需要依赖于Hadoop中的HDFS和YARN。所以在实际工作中Hadoop会作为一个提供分布式存储和分布式资源管理的角色存在Spark会在它之上去执行。所以在工作中就会把spark和hadoop结合到一块来使用。
Spark+Hadoop
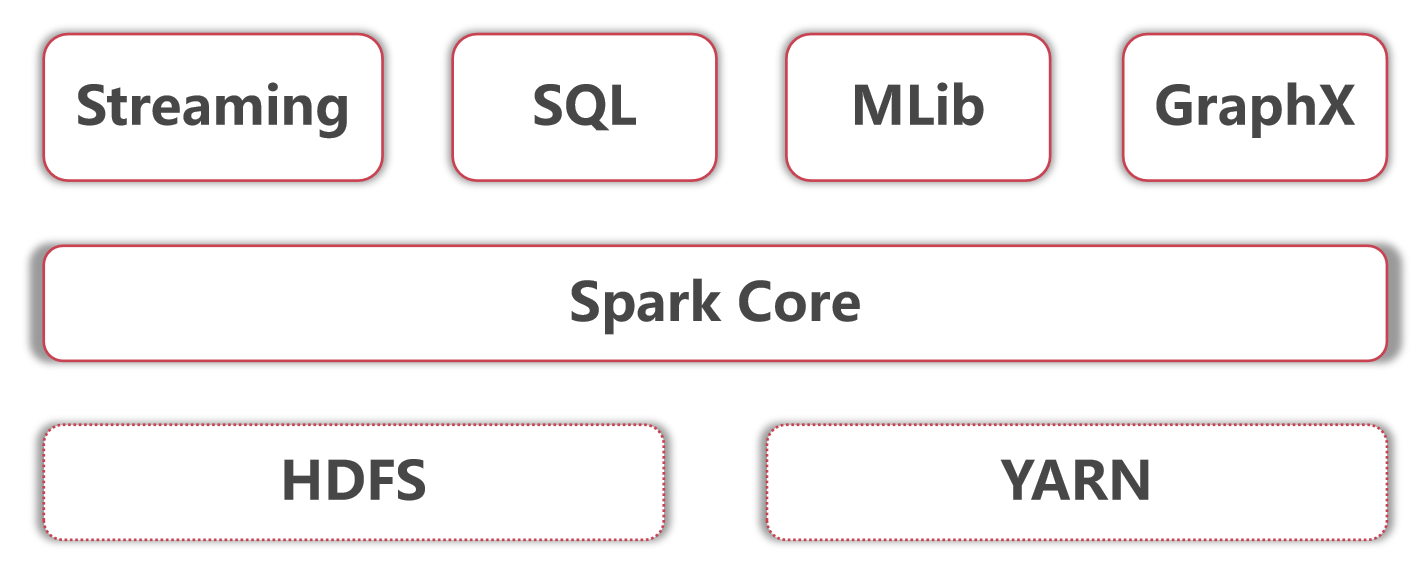
- 底层是Hadoop的HDFS和YARN
- Spark core指的是Spark的离线批处理
- Spark Streaming指的是Spark的实时流计算
- SparkSQL指的是Spark中的SQL计算
- Spark Mlib指的是Spark中的机器学习库,这里面集成了很多机器学习算法
- 最后这个Spark GraphX是指图计算
这里面这么多模块,针对大数据开发岗位主要需要掌握的是Spark core、streaming、sql这几个模块,其中Mlib主要是搞算法的岗位使用的,GraphX这个要看是否有图计算相关的需求,所以这两个不是必须要掌握的。所以在本套体系课程中我们会学习Spark core、Spark SQL、还有Spark streaming这三块内容。不过由于现在我们主要是学习离线批处理相关的内容,所以会先学习Spark core和Spark SQL,而Spark streaming等到后面我们讲到实时计算的时候再去学习。
Spark的应用场景:
- 低延时的海量数据计算需求,这个说的就是针对Spark core的应用
- 低延时SQL交互查询需求,这个说的就是针对Spark SQL的应用
- 准实时(秒级)海量数据计算需求,这个说的就是Spark Streaming的应用
Spark集群安装部署
Spark集群安装部署
Spark集群有多种部署方式,比较常见的有Standalone模式和ON YARN模式
- Standalone模式就是说部署一套独立的Spark集群,后期开发的Spark任务就在这个独立的Spark集群中执行
- ON YARN模式是说使用现有的Hadoop集群,后期开发的Spark任务会在这个Hadoop集群中执行,此时这个Hadoop集群就是一个公共的了,不仅可以运行MapReduce任务,还可以运行Spark任务,这样集群的资源就可以共享了,并且也不需要再维护一套集群了,减少了运维成本和运维压力,一举两得。
所以在实际工作中都会使用Spark ON YARN模式
那在具体安装部署之前,需要先下载Spark的安装包。
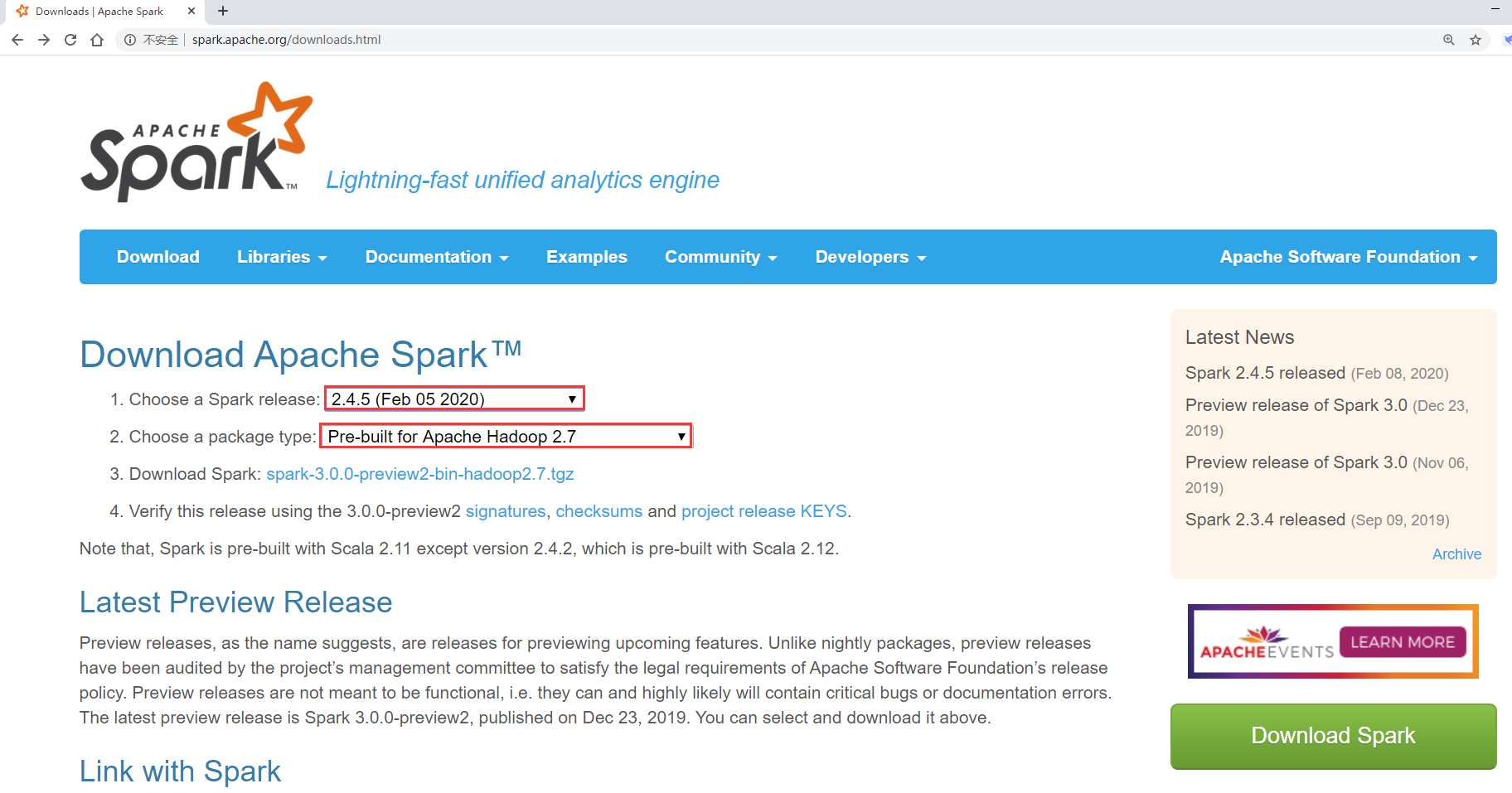
我们使用Spark的时候一般都是需要和Hadoop交互的,所以需要下载带有Hadoop依赖的安装包。这个时候就需要选择Hadoop版本对应的Spark安装包,我们的Hadoop是3.2的,里面Hadoop的版本只有2.6和2.7的,那就退而求其次选择hadoop2.7对应的这个Spark安装包,其实也是没什么问题的,如果有强迫症的话,就需要下载Spark的源码包,自己编译配套版本的安装包了。
其实在Spark3.0的那个预览版本里面是有和Hadoop3.2配套的版本的,不过那个不是稳定版本,不建议在生产环境下使用,所以就不考虑了。
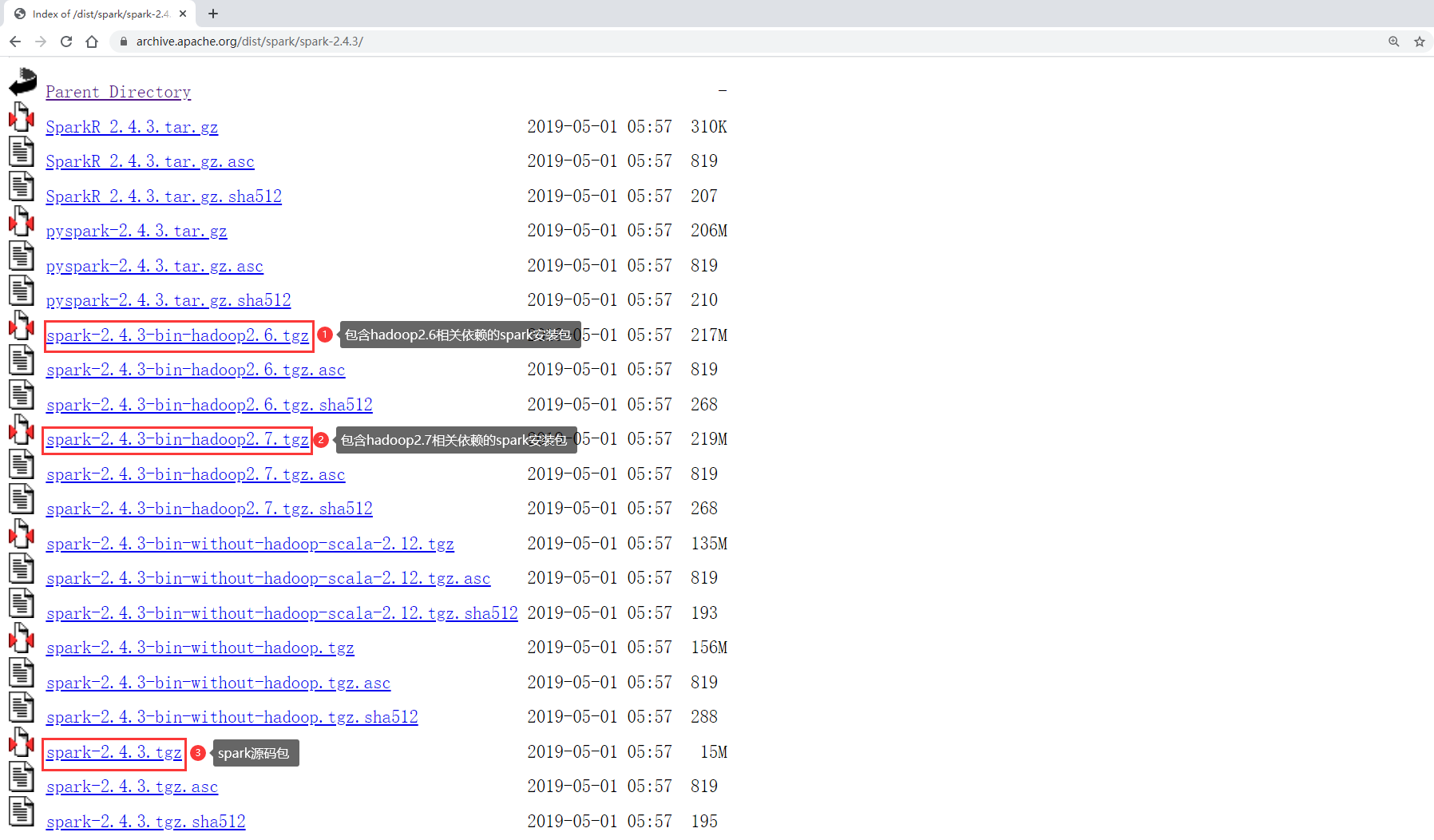
所以最终我们就下载这个版本:
spark-2.4.3-bin-hadoop2.7.tgz
Standalone
由于Spark集群也是支持主从的,在这我们使用三台机器,部署一套一主两从的集群
主节点: bigdata01
从节点: bigdata02,bigdata03
注意:需要确保这几台机器上的基础环境是OK的,防火墙、免密码登录、还有JDK。
因为这几台机器我们之前已经使用过了,基础环境都是配置过的,所以说在这就直接使用了。
先在bigdata01上进行配置
- 将spark-2.4.3-bin-hadoop2.7.tgz上传到bigdata01的/data/soft目录中
- 解压
- 重命名spark-env.sh.template
[root@bigdata01 soft]# cd spark-2.4.3-bin-hadoop2.7/conf/
[root@bigdata01 conf]# mv spark-env.sh.template spark-env.sh
- 修改 spark-env.sh
在文件末尾增加这两行内容,指定JAVA_HOME和主节点的主机名
export JAVA_HOME=/data/soft/jdk1.8
export SPARK_MASTER_HOST=bigdata01
- 重命名slaves.template
[root@bigdata01 conf]# mv slaves.template slaves
- 修改slaves
将文件末尾的localhost去掉,增加bigdata02和bigdata03这两个从节点的主机名
bigdata02
bigdata03
- 将修改好配置的spark安装包,拷贝到bigdata02和bigdata03上
[root@bigdata01 soft]# scp -rq spark-2.4.3-bin-hadoop2.7 bigdata02:/data/soft
[root@bigdata01 soft]# scp -rq spark-2.4.3-bin-hadoop2.7 bigdata03:/data/soft
- 启动Spark集群
[root@bigdata01 soft]# cd spark-2.4.3-bin-hadoop2.7
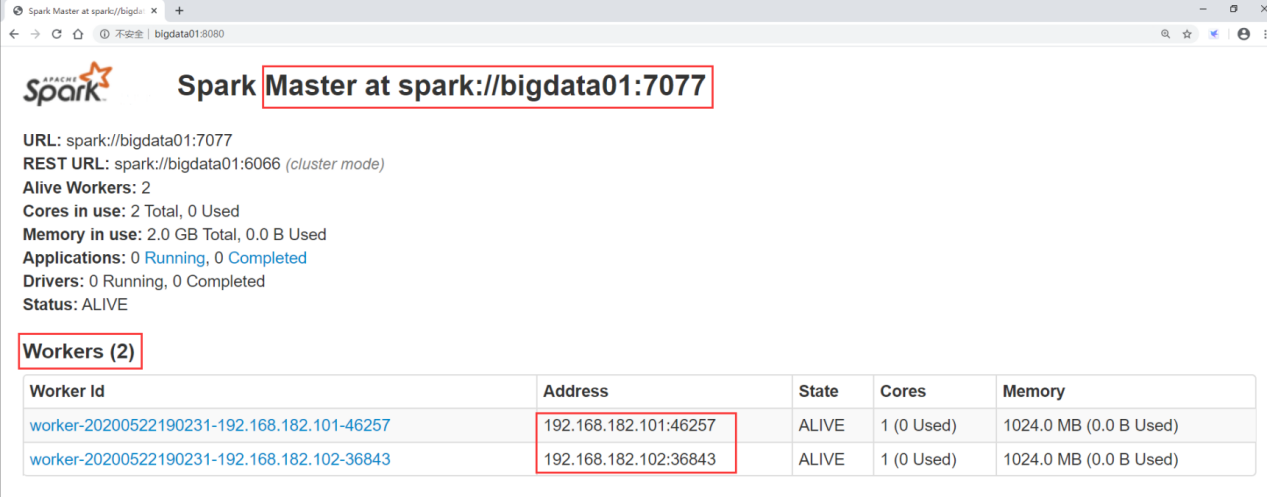
[root@bigdata01 spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh
还可以访问主节点的8080端口来查看集群信息
http://bigdata01:8080/
10. 提交任务
那我们尝试向这个Spark独立集群提交一个spark任务
提交任务的命令该如何写呢?
来看一下Spark的官方文档
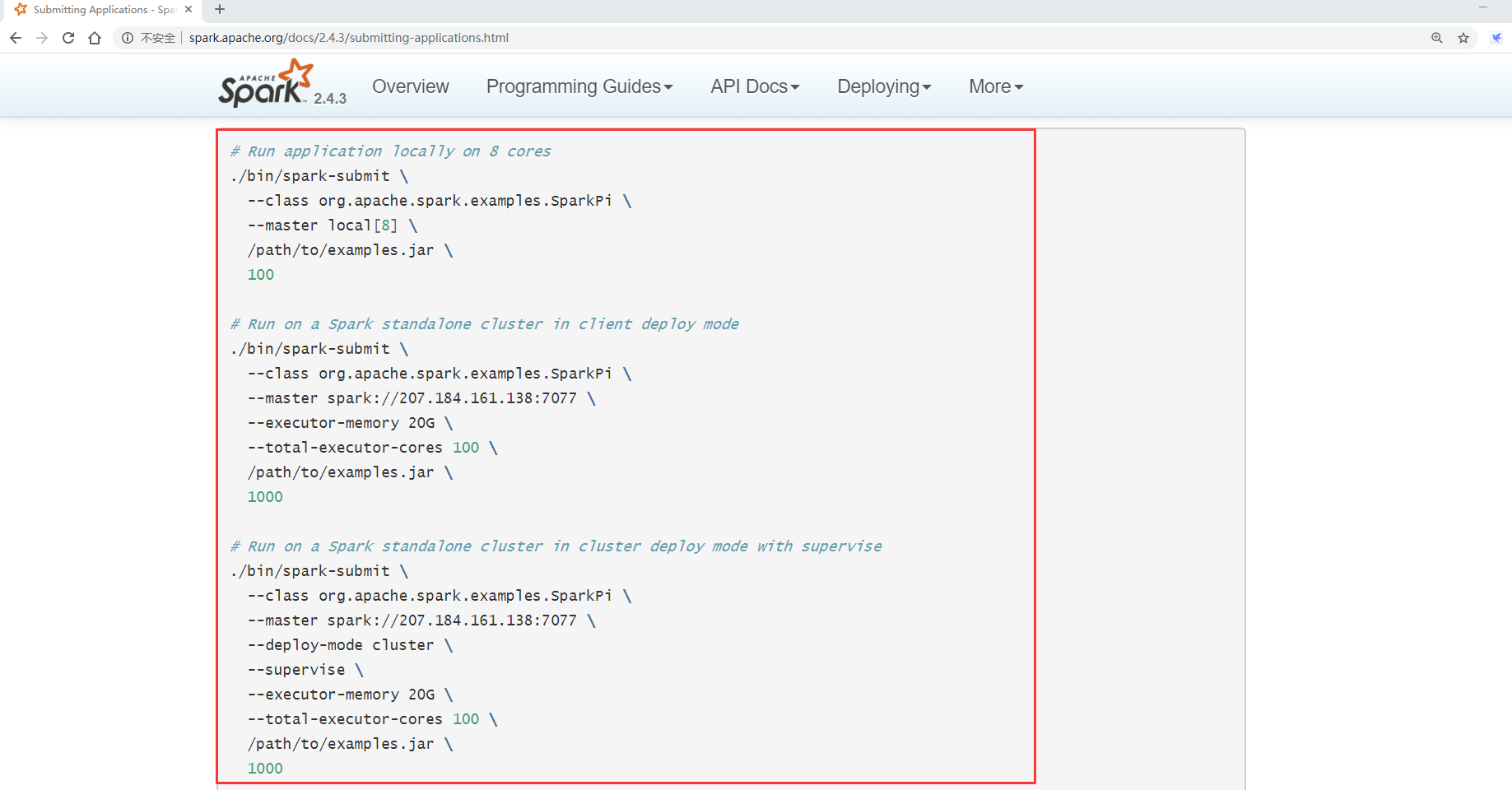
11. 停止Spark集群
在主节点 bigdata01上执行
[root@bigdata01 spark-2.4.3-bin-hadoop2.7]# sbin/stop-all.sh
bigdata03: stopping org.apache.spark.deploy.worker.Worker
bigdata02: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
ON YARN
ON YARN模式很简单,
先保证有一个Hadoop集群,然后只需要部署一个Spark的客户端节点即可,不需要启动任何进程。
注意:Spark的客户端节点同时也需要是Hadoop的客户端节点,因为Spark需要依赖于Hadoop
我们的Hadoop集群是 bigdata01、bigdata02、bigdata03
那我们可以选择把Spark部署在一个单独的节点上就可以了,其实就类似于我们之前部署Hadoop客户端节点。
在这我们使用bigdata04来部署spark on yarn,因为这个节点同时也是Hadoop的客户端节点。
- 将spark-2.4.3-bin-hadoop2.7.tgz上传到bigdata04的/data/soft目录中
- 解压
- 重命名spark-env.sh.template
[root@bigdata01 soft]# cd spark-2.4.3-bin-hadoop2.7/conf/
[root@bigdata01 conf]# mv spark-env.sh.template spark-env.sh
- 修改 spark-env.sh
在文件末尾增加这两行内容,指定JAVA_HOME和Hadoop的配置文件目录
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
- 提交任务
那我们通过这个spark客户点节点,向Hadoop集群上提交spark任务
[root@bigdata04 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit --class org.apache
- 可以到YARN的8088界面查看提交上去的任务信息
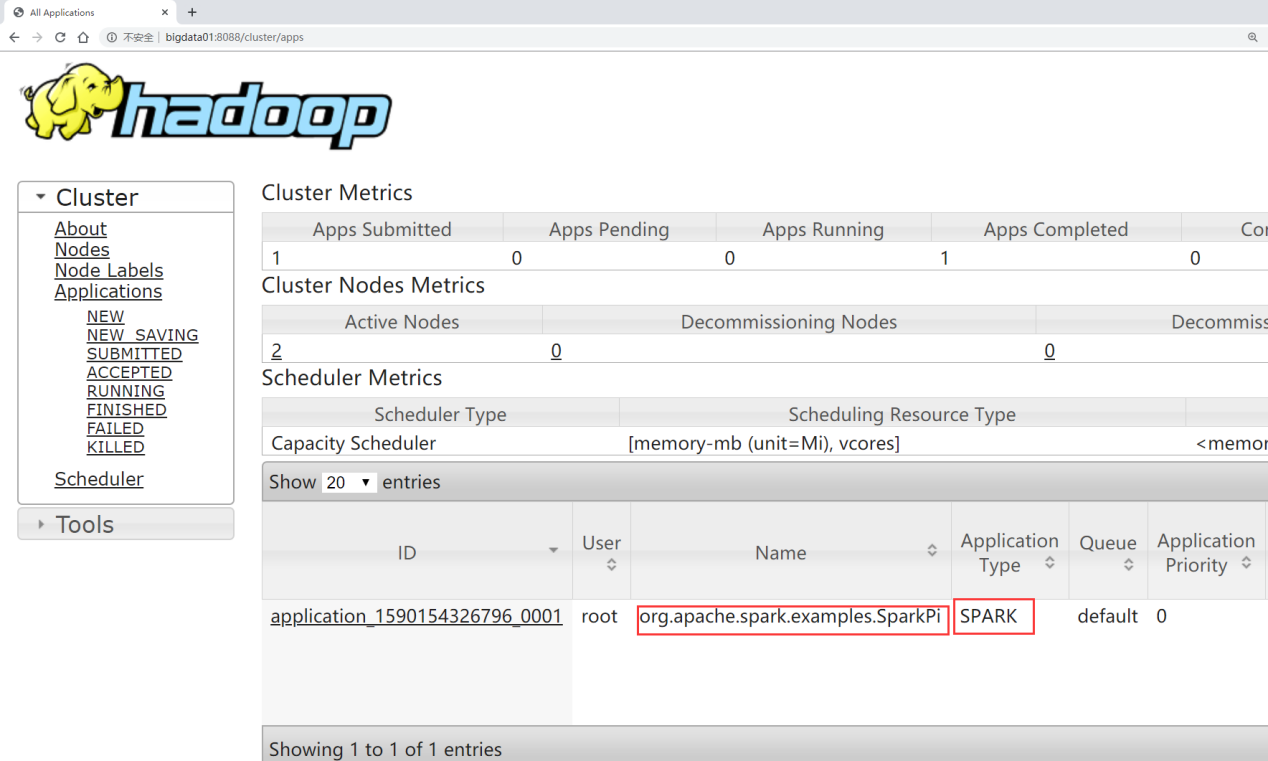
此时就可以使用ON YARN模式来执行Spark任务了
Spark的工作原理
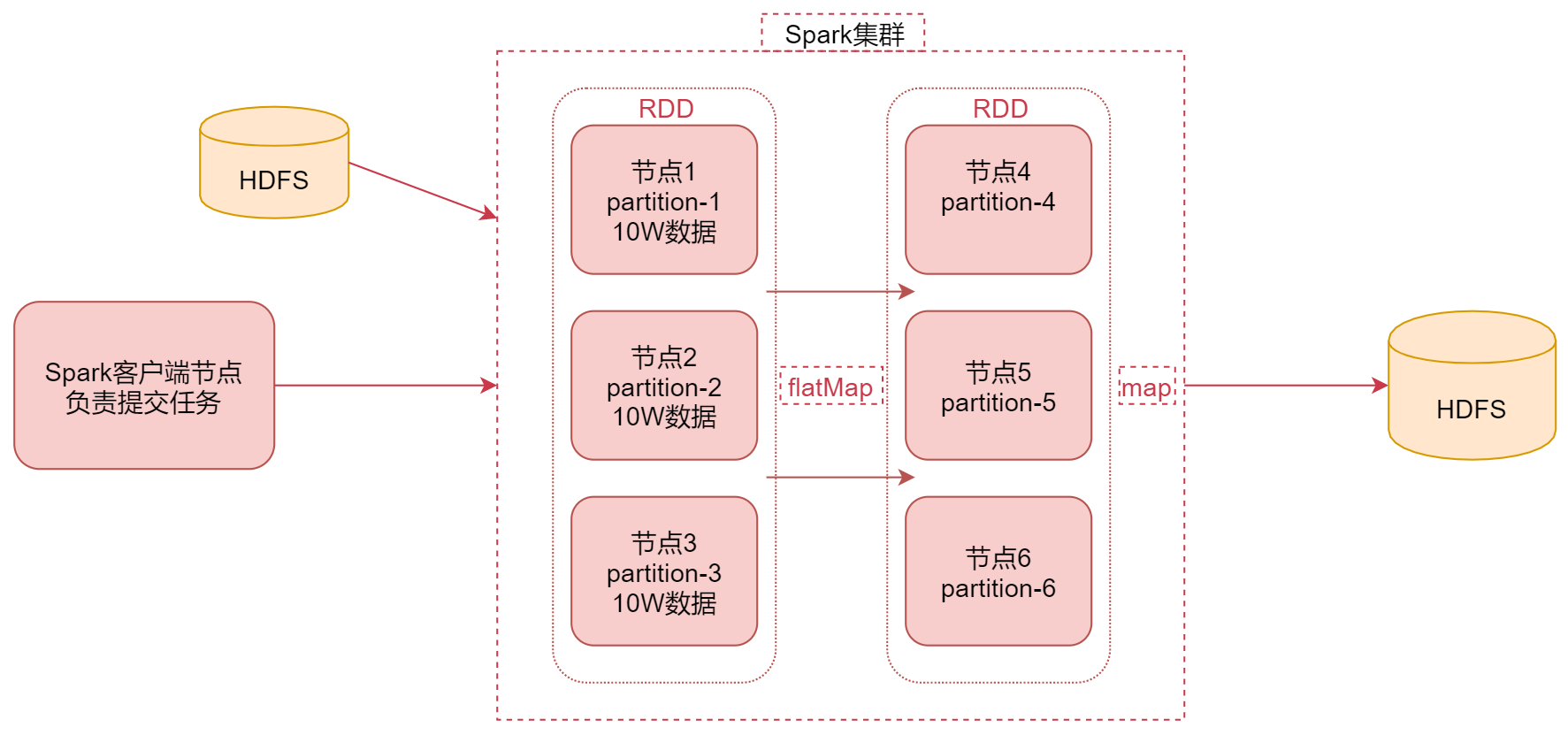
首先看中间是一个Spark集群,可以理解为是Spark的 standalone集群,集群中有6个节点。
左边是Spark的客户端节点,这个节点主要负责向Spark集群提交任务,假设在这里我们向Spark集群提交了一个任务。那这个Spark任务肯定会有一个数据源,数据源在这我们使用HDFS,就是让Spark计算HDFS中的数据。当Spark任务把HDFS中的数据读取出来之后,它会把HDFS中的数据转化为RDD,RDD其实是一个弹性分布式数据集,它其实是一个逻辑概念,在这你先把它理解为是一个数据集合就可以了。
在这里这个RDD你就可以认为是包含了我们读取的HDFS上的数据,其中这个RDD是有分区这个特性的,也就是一整份数据会被分成多份,假设我们现在从HDFS中读取的这份数据被转化为RDD之后,在RDD中分成了3份,那这3份数据可能会分布在3个不同的节点上面,对应这里面的节点1、节点2、节点3。这个RDD的3个分区的数据对应的是partiton-1、partition-2、partition-3。这样的好处是可以并行处理了,后期每个节点就可以计算当前节点上的这一个分区的数据。
这个计算思想是不是类似于MapReduce里面的计算思想啊,本地计算,但是有一点区别就是这个RDD的数据是在内存中的。假设现在这个RDD中每个分区中的数据有10w条,那接下来我们就想对这个RDD中的数据进行计算了,可以使用一些高阶函数进行计算,例如:flatMap、map之类的。
那在这我们先使用flatMap对数据进行处理,把每一行数据转成多行数据,此时flatMap这个函数就会在节点1、节点2和节点3上并行执行了。
计算之后的结果还是一个带有分区的RDD,那这个RDD我们假设存在节点4、节点5和节点6上面。
此时每个节点上面会有一个分区的数据,我们给这些分区数据起名叫partition-4、partition-5、partition-6。正常情况下,前面节点1上的数据处理之后会发送到节点4上面,另外两个节点也是一样的。此时经过flatmap计算之后,前面RDD的数据传输到后面节点上面这个过程是不需要经过shuffle的,可以后面可能还会通过map、或者其它的一些高阶函数对数据进行处理,当处理到最后一步的时候是需要把数据存储起来的,在这我们选择把数据存储到hdfs上面,其实在实际工作中,针对这种离线计算,大部分的结果数据都是存储在hdfs上面的,当然了也可以存储到其它的存储介质中。
那这个就是Spark的基本工作原理。
再梳理一下,首先通过Spark客户端提交任务到Spark集群,然后Spark任务在执行的时候会读取数据源HDFS中的数据,将数据加载到内存中,转化为RDD,然后针对RDD调用一些高阶函数对数据进行处理,中间可以调用多个高阶函数,最终把计算出来的结果数据写到HDFS中。这里面的这个RDD是Spark的核心内容,那下面我们来详细分析一下这个RDD
什么是RDD
-
RDD通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建
-
RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
那我们接下来来看一下这个弹性分布式数据集的特点
RDD的特点
- 弹性:RDD数据默认情况下存放在内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘
- 分布式:RDD在抽象上来说是一种元素数据的集合,它是被分区的,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作
- 容错性:RDD最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来
如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition的数据。
Spark架构相关进程
下面我们来看一下Spark架构相关的进程信息
注意:在这里是以Spark的standalone集群为例进行分析
- Driver:
我们编写的Spark程序就在Driver(进程)上,由Driver进程负责执行
Driver进程所在的节点可以是Spark集群的某一个节点或者就是我们提交Spark程序的客户端节点。具体Driver进程在哪个节点上启动是由我们提交任务时指定的参数决定的,这个后面我们会详细分析 - Master:
集群的主节点中启动的进程
主要负责集群资源的管理和分配,还有集群的监控等 - Worker:
集群的从节点中启动的进程
主要负责启动其它进程来执行具体数据的处理和计算任务 - Executor:
此进程由Worker负责启动,主要为了执行数据处理和计算
Task 是一个线程
由Executor负责启动,它是真正干活的
Spark架构原理
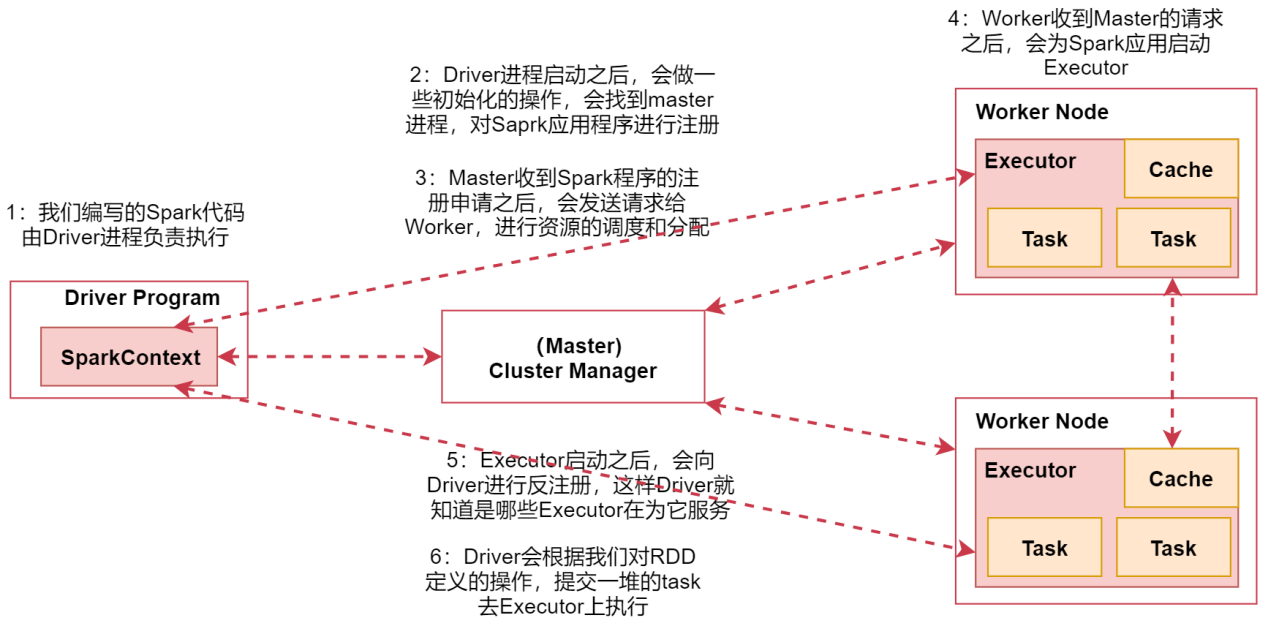
- 首先我们在spark的客户端机器上通过driver进程执行我们的Spark代码。当我们通过spark-submit脚本提交Spark任务的时候Driver进程就启动了。
- Driver进程启动之后,会做一些初始化的操作,会找到集群master进程,对Spark应用程序进行注册
- 当Master收到Spark程序的注册申请之后,会发送请求给Worker,进行资源的调度和分配
- Worker收到Master的请求之后,会为Spark应用启动Executor进程会启动一个或者多个Executor,具体启动多少个,会根据你的配置来启动
- Executor启动之后,会向Driver进行反注册,这样Driver就知道哪些Executor在为它服务了
- Driver会根据我们对RDD定义的操作,提交一堆的task去Executor上执行task里面执行的其实就是具体的map、flatMap这些操作。
这就是Spark架构的原理。
Spark实战:单词统计
需求这样的:读取文件中的所有内容,计算每个单词出现的次数
注意:由于Spark支持Java、Scala这些语言,目前在企业中大部分公司都是使用Scala语言进行开发,个别公司会使用java进行开发
先配置好Scala开发环境,最后需要添加Spark的maven依赖
注意:由于目前我们下载的spark的安装包中使用的scala是2.11的,所以在这里要选择对应的scala 2.11版本的依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
Scala代码开发
在scala目录下创建包com.imooc.scala
再创建一个Scala object:WordCountScala
代码如下:
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:单词计数
*/
object WordCountScala {
def main(args: Array[String]): Unit = {
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala")//设置任务名称
.setMaster("local")//local表示在本地执行
val sc = new SparkContext(conf)
//第二步:加载数据
val linesRDD = sc.textFile("D:\\hello.txt")
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转化为(word,1)这种形式
val pairRDD = wordsRDD.map((_,1))
//第五步:根据key(其实就是word)进行分组聚合统计
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
wordCountRDD.foreach(wordCount=>println(wordCount._1+"--"+wordCount._2))
//第七步:停止SparkContext
sc.stop()
}
}
注意:由于此时我们在代码中设置的Master为local,表示会在本地创建一个临时的spark集群运行这个代码,这样有利于代码调试
执行代码,结果如下:
you--1
hello--2
me--1
总结一下代码中这几个RDD中的数据结构
val linesRDD = sc.textFile("D:\\hello.txt")
linesRDD中的数据是这样的:
hello you
hello me
val wordsRDD = linesRDD.flatMap(_.split(" "))
wordsRDD中的数据是这样的:
hello
you
hello
me
val pairRDD = wordsRDD.map((_,1))
pairRDD 中的数据是这样的
(hello,1)
(you,1)
(hello,1)
(me,1)
val wordCountRDD = pairRDD.reduceByKey(_ + _)
wordCountRDD 中的数据是这样的
(hello,2)
(you,1)
(me,1)
这是Scala代码的实现
java代码开发
package com.imooc.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:单词计数
*/
public class WordCountJava {
public static void main(String[] args) {
//第一步:创建SparkContext:
//注意,针对java代码需要获取JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("WordCountJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//第二步:加载数据
JavaRDD<String> linesRDD = sc.textFile("D:\\hello.txt");
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//注意:FlatMapFunction的泛型,第一个参数表示输入数据类型,第二个表示是输出
JavaRDD<String> wordRDD = linesRDD.flatMap(new FlatMapFunction<String
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//第四步:迭代words,将每个word转化为(word,1)这种形式
//注意:PairFunction的泛型,第一个参数是输入数据类型
//第二个是输出tuple中的第一个参数类型,第三个是输出tuple中的第二个参数类型
//注意:如果后面需要使用到....ByKey,前面都需要使用mapToPair去处理
//注意:如果后面需要使用到....ByKey,前面都需要使用mapToPair去处理
JavaPairRDD<String, Integer> pairRDD = wordRDD.mapToPair(new PairFunct
public Tuple2<String, Integer> call(String word) throws Exception
return new Tuple2<String, Integer>(word, 1);
}
});
//第五步:根据key(其实就是word)进行分组聚合统计
JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new F
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//第六步:将结果打印到控制台
wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup._1+"--"+tup._2);
}
});
//第七步:停止sparkContext
sc.stop();
}
}
执行结果
you–1
hello–2
me–1
任务提交
针对任务的提交有这么几种形式
1)直接在idea中执行,方便在本地环境调试代码,咱们刚才使用的就是这种方式
2)使用spark-submit
使用spark-submit提交到集群执行,实际工作中会使用这种方式。那接下来我们需要把我们的代码提交到集群中去执行。这个时候就需要对代码打包了
首先在项目的pom文件中添加 build 配置,和 dependencies 标签平级
Transformation与Action开发
创建RDD
RDD是Spark编程的核心,在进行Spark编程时,首要任务是创建一个初始的RDD。
这样就相当于设置了Spark应用程序的输入源数据然后在创建了初始的RDD之后,才可以通过Spark 提供的一些高阶函数,对这个RDD进行操作,来获取其它的RDD
Spark提供三种创建RDD方式:集合、本地文件、HDFS文件
- 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造一些测试数据,来测试后面的spark应用程序的流程。
- 使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件
- 使用HDFS文件创建RDD,是最常用的生产环境的处理方式,主要可以针对HDFS上存储的数据,进行离线批处理操作。
使用集合创建RDD
首先来看一下如何使用集合创建RDD
如果要通过集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上,形成一个分布式的数据集合,也就是一个RDD。相当于,集合中的部分数据会到一个节点上,而另一部分数据会到其它节点上。然后就可以用并行的方式来操作这个分布式数据集合了。调用parallelize()时,有一个重要的参数可以指定,就是将集合切分成多少个partition。Spark会为每一个partition运行一个task来进行处理。Spark默认会根据集群的配置来设置partition的数量。我们也可以在调用parallelize()方法时,传入第二个参数,来设置RDD的partition数量,例如:parallelize(arr, 5)
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用集合创建RDD
*/
object CreateRddByArrayScala {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf()
conf.setAppName("CreateRddByArrayScala ")//设置任务名称
.setMaster("local")//local表示在本地执行
val sc = new SparkContext(conf)
//创建集合
val arr = Array(1,2,3,4,5)
//基于集合创建RDD
val rdd = sc.parallelize(arr)
val sum = rdd.reduce(_ + _)
println(sum)
//停止SparkContext
sc.stop()
}
}
注意:
val arr = Array(1,2,3,4,5)还有println(sum)代码是在driver进程中执行的,这些代码不会并行执行。
parallelize还有reduce之类的操作是在worker节点中执行的
使用本地文件和HDFS文件创建RDD
下面我们来看一下使用本地文件和HDFS文件创建RDD
通过SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD,RDD中的每个元素就是文件中的一行文本内容
textFile()方法支持针对目录、压缩文件以及通配符创建RDD
Spark默认会为HDFS文件的每一个Block创建一个partition,也可以通过textFile()的第二个参数手动设置分区数量,只能比Block数量多,不能比Block数量少,比Block数量少的话你的设置是不生效的
scala代码如下:
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:通过文件创建RDD
* 1:本地文件
* 2:HDFS文件
*/
object CreateRddByFileScala {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf()
conf.setAppName("CreateRddByFileScala")//设置任务名称
.setMaster("local")//local表示在本地执行
val sc = new SparkContext(conf)
var path = "D:\\hello.txt"
path = "hdfs://bigdata01:9000/test/hello.txt"
//读取文件数据,可以在textFile中指定生成的RDD的分区数量
val rdd = sc.textFile(path,2)
//获取每一行数据的长度,计算文件内数据的总长度
val length = rdd.map(_.length).reduce(_ + _)
println(length)
sc.stop()
}
}
Transformation和Action
接下来我们详细分析一下Spark中对RDD的操作
Spark对RDD的操作可以整体分为两类:Transformation和Action
- 这里的Transformation可以翻译为转换,表示是针对RDD中数据的转换操作,主要会针对已有的RDD创建一个新的RDD:常见的有map、flatMap、filter等等
- Action可以翻译为执行,表示是触发任务执行的操作,主要对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并且还可以把结果返回给Driver程序
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子,例如:map算子、reduce算子。其中Transformation算子有一个特性:lazy
lazy特性在这里指的是,如果一个spark任务中只定义了transformation算子,那么即使你执行这个任务,任务中的算子也不会执行。也就是说,transformation是不会触发spark任务的执行,它们只是记录了对RDD所做的操作,不会执行。
只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。
Spark通过lazy这种特性,来进行底层的spark任务执行的优化,避免产生过多中间结果。Action的特性:执行Action操作才会触发一个Spark 任务的运行,从而触发这个Action之前所有Transformation的执行。
以我们的WordCount代码为例:
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala")//设置任务名称
//.setMaster("local")//local表示在本地执行
//第二步:加载数据
var path = "D:\\hello.txt"
if(args.length==1){
path = args(0)
}
//这里通过textFile()方法,针对外部文件创建了一个RDD,linesRDD,实际上,程序执行到这
val linesRDD = sc.textFile(path)
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//这里通过flatMap算子对linesRDD进行了转换操作,把每一行数据中的单词切开,获取了一个
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转化为(word,1)这种形式
//这个操作和前面分析的flatMap的操作是一样的,最终获取了一个逻辑上的pairRDD,此时里面
val pairRDD = wordsRDD.map((_,1))
//第五步:根据key(其实就是word)进行分组聚合统计
//这个操作也是和前面分析的flatMap操作是一样的,最终获取了一个逻辑上的wordCountRDD,
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
//这行代码执行了一个action操作,foreach,此时会触发之前所有transformation算子的执行
//注意:只有当任务执行到这一行代码的时候任务才会真正开始执行计算,如果任务中没有这一行
wordCountRDD.foreach(wordCount=>println(wordCount._1+"--"+wordCount._2))
//第七步:停止SparkContext
sc.stop()
常用Transformation介绍
先来看一下Spark中的Transformation算子
先来看一下官方文档,进入2.4.3的文档界面
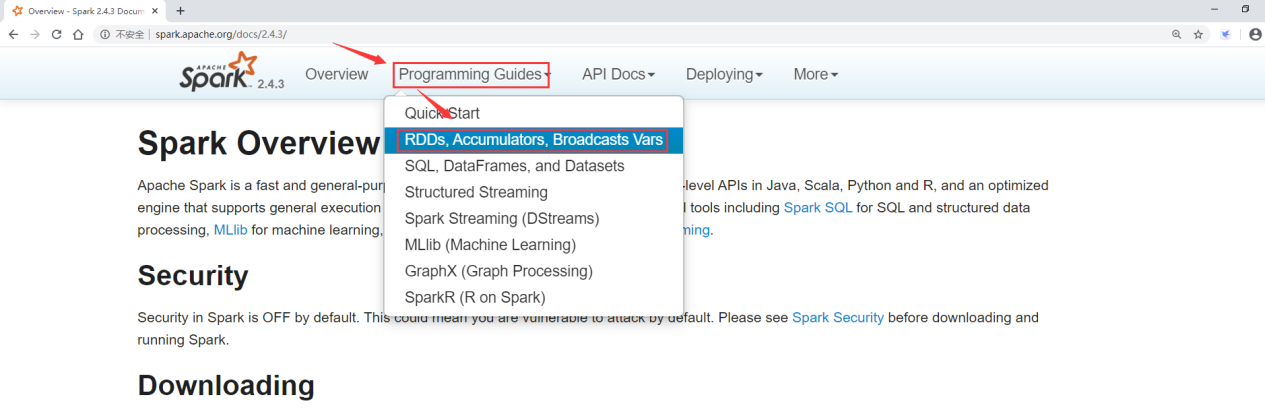
这里面列出了Spark支持的所有的transformation算子
算子 介绍
map 将RDD中的每个元素进行处理,一进一出
filter 对RDD中每个元素进行判断,返回true则保留
flatMap 与map类似,但是每个元素都可以返回一个或多个新元素
groupByKey 根据key进行分组,每个key对应一个Iterable<value>
reduceByKey 对每个相同key对应的value进行reduce操作
sortByKey 对每个相同key对应的value进行排序操作(全局排序)
join 对两个包含<key,value>对的RDD进行join操作
distinct 对RDD中的元素进行全局去重
Transformation操作开发实战
下面我们来针对常见的Transformation来具体写一些案例
- map:对集合中每个元素乘以2
- filter:过滤出集合中的偶数
- flatMap:将行拆分为单词
- groupByKey:对每个大区的主播进行分组
- reduceByKey:统计每个大区的主播数量
- sortByKey:对主播的音浪收入排序
- join:打印每个主播的大区信息和音浪收入
- distinct:统计当天开播的大区信息
Scala代码如下:
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:Transformation实战
* map:对集合中每个元素乘以2
* filter:过滤出集合中的偶数
* flatMap:将行拆分为单词
* groupByKey:对每个大区的主播进行分组
* * reduceByKey:统计每个大区的主播数量
* sortByKey:对主播的音浪收入排序
* join:打印每个主播的大区信息和音浪收入
* distinct:统计当天开播的主播数量
*/
object TransformationOpScala {
def main(args: Array[String]): Unit = {
val sc = getSparkContext
sc.stop()
}
def distinctOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"C
//由于是统计开播的大区信息,需要根据大区信息去重,所以只保留大区信息
dataRDD.map(_._2).distinct().foreach(println(_))
}
def joinOp(sc: SparkContext): Unit = {
val dataRDD1 = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"
val dataRDD2 = sc.parallelize(Array((150001,400),(150002,200),(150003,300
val joinRDD = dataRDD1.join(dataRDD2)
//joinRDD.foreach(println(_))
joinRDD.foreach(tup=>{
//用户id
val uid = tup._1
val area_gold = tup._2
//大区
val area = area_gold._1
//音浪收入
val gold = area_gold._2
println(uid+"\t"+area+"\t"+gold)
})
}
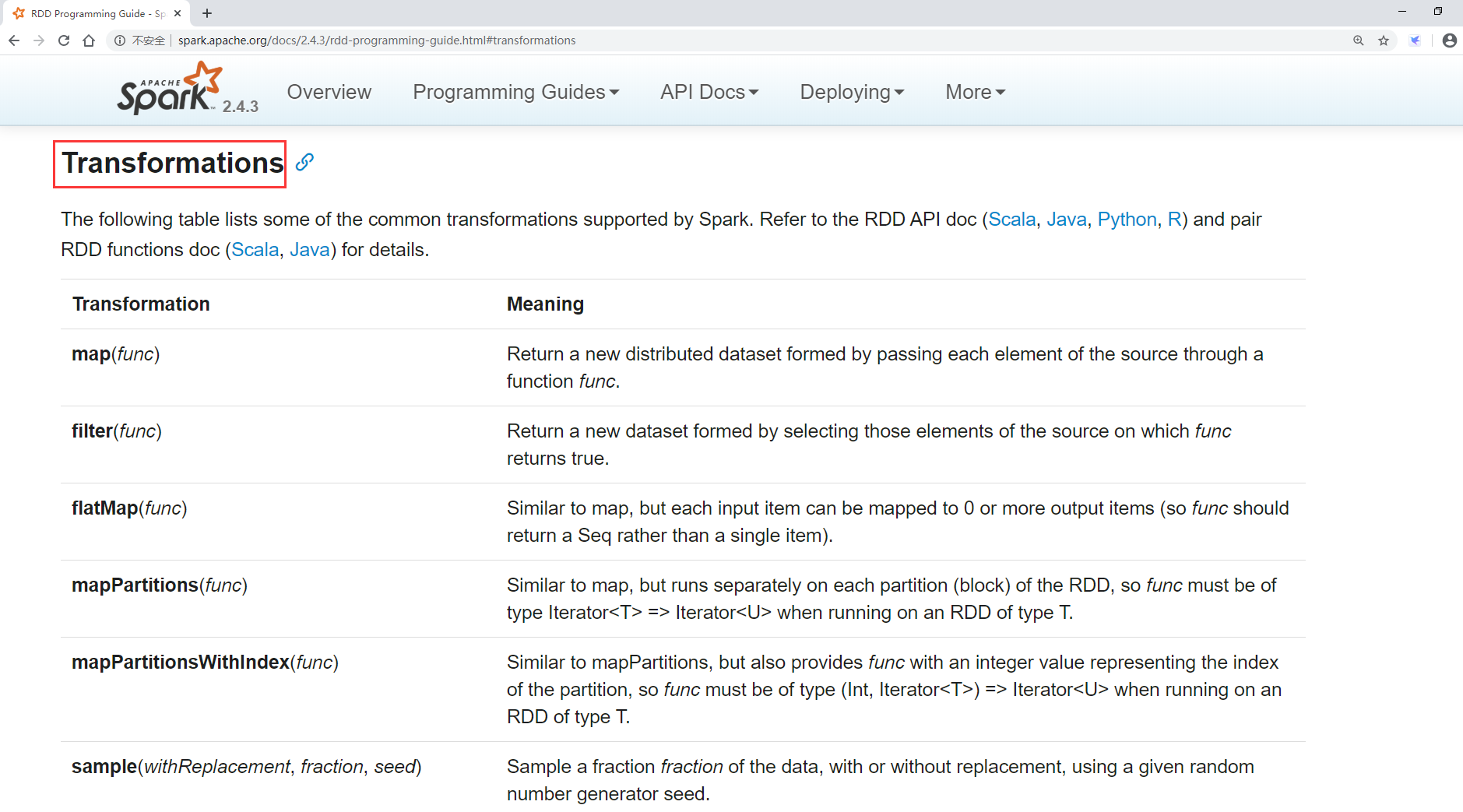
常用Action介绍
接下来看一下常见的Action算子
算子 介绍
reduce 将RDD中的所有元素进行聚合操作
collect 将RDD中所有元素获取到本地客户端(Driver)
count 获取RDD中元素总数
take(n) 获取RDD中前n个元素
saveAsTextFile 将RDD中元素保存到文件中,对每个元素调用toString
countByKey 对每个key对应的值进行count计数
foreach 遍历RDD中的每个元素
Action操作开发实战
下面针对常见的Action算子来写一些具体案例
- reduce:聚合计算
- collect:获取元素集合
- take(n):获取前n个元素
- count:获取元素总数
- saveAsTextFile:保存文件
- countByKey:统计相同的key出现多少次
- foreach:迭代遍历元素
scala代码如下:
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:Action实战
* reduce:聚合计算
* collect:获取元素集合
* take(n):获取前n个元素
* count:获取元素总数
* saveAsTextFile:保存文件
* countByKey:统计相同的key出现多少次
* foreach:迭代遍历元素
*/
object ActionOpScala {
def main(args: Array[String]): Unit = {
val sc = getSparkContext
//reduce:聚合计算
//reduceOp(sc)
//collect:获取元素集合
//collectOp(sc)
//take(n):获取前n个元素
//takeOp(sc)
//count:获取元素总数
//countOp(sc)
//saveAsTextFile:保存文件
//saveAsTextFileOp(sc)
//countByKey:统计相同的key出现多少次
//foreach:迭代遍历元素
//foreachOp(sc)
sc.stop()
}
def countByKeyOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(("A",1001),("B",1002),("A",1003),("C",
//返回的是一个map类型的数据
val res = dataRDD.countByKey()
for((k,v) <- res){
println(k+","+v)
}
}
def saveAsTextFileOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//指定HDFS的路径信息即可,需要指定一个不存在的目录
dataRDD.saveAsTextFile("hdfs://bigdata01:9000/out0524")
}
def countOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val res = dataRDD.count()
println(res)
}
RDD持久化
RDD持久化原理
Spark中有一个非常重要的功能就是可以对RDD进行持久化。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition数据持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存中缓存的partition数据。这样的话,针对一个RDD反复执行多个操作的场景,就只需要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。因为正常情况下这个RDD的数据使用过后内存中是不会一直保存的。
例如这样的操作:针对mapRDD需要多次使用的
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val mapRDD = dataRDD.map(...)
mapRDD.foreach(...)
mapRDD.saveAsTextFile(...)
mapRDD.collect()
巧妙使用RDD持久化,在某些场景下,对spark应用程序的性能有很大提升。特别是对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只需要调用它的cache()或者persist()方法就可以了。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition数据丢失了,那么Spark会自动通过其源RDD,使用transformation算子重新计算该partition的数据。cache()和persist()的区别在于:cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,也就是调persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清除缓存,那么可以使用unpersist()方法。
RDD持久化策略
下面看一下目前Spark支持的一些持久化策略

补充说明:
- MEMORY_ONLY:以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算。
- MEMORY_AND_DISK:当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取,不需要重新计算
- MEMORY_ONLY_SER:同MEMORY_ONLY,但是会使用Java的序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是在使用的时候需要进行反序列化,因此会增加CPU开销。
- MEMORY_AND_DISK_SER:同MEMORY_AND_DSK。但是会使用序列化方式持久化Java对象。
- DISK_ONLY:使用非序列化Java对象的方式持久化,完全存储到磁盘上。
- MEMORY_ONLY_2、MEMORY_AND_DISK_2等:如果是尾部加了2的持久化级别,表示会将持久化数据复制一份,保存到其它节点,从而在数据丢失时,不需要重新计算,只需要使用备份数据即可。
如何选择RDD持久化策略
Spark提供了多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍。
下面是一些通用的持久化级别的选择建议:
- 优先使用MEMORY_ONLY,纯内存速度最快,而且没有序列化不需要消耗CPU进行反序列化操作,缺点就是比较耗内存
- MEMORY_ONLY_SER,将数据进行序列化存储,纯内存操作还是非常快,只是在使用的时候需要消耗CPU进行反序列化
注意:
如果需要进行数据的快速失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了能不使用DISK相关的策略,就不要使用,因为有的时候,从磁盘读取数据,还不如重新计算一次。
案例:使用RDD的持久化
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:RDD持久化
*/
object PersistRddScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("PersistRddScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.textFile("D:\\hello_10000000.dat").cache()
var start_time = System.currentTimeMillis()
var count = dataRDD.count()
println(count)
var end_time = System.currentTimeMillis()
println("第一次耗时:"+(end_time-start_time))
start_time = System.currentTimeMillis()
count = dataRDD.count()
println(count)
end_time = System.currentTimeMillis()
println("第二次耗时:"+(end_time-start_time))
sc.stop()
}
}
在没有添加cache之前,每一次都耗时很长,加上cache之后,第二次计算耗时就很少了
共享变量
共享变量的工作原理
Spark还有一个非常重要的特性就是共享变量
默认情况下,如果在一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量数据。如果多个task想要共享某个变量,那么这种方式是做不到的。
Spark为此提供了两种共享变量
- 一种是Broadcast Variable(广播变量)
- 另一种是Accumulator(累加变量)
Broadcast Variable
Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,而不会为每个task都拷贝一份副本,因此其最大的作用,就是减少变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。
通过调用SparkContext的broadcast()方法,针对某个变量创建广播变量
注意:广播变量,是只读的。
然后在算子函数内,使用到广播变量时,每个节点只会拷贝一份副本。可以使用广播变量的value()方法获取值。接下来看一个图深入理解一下
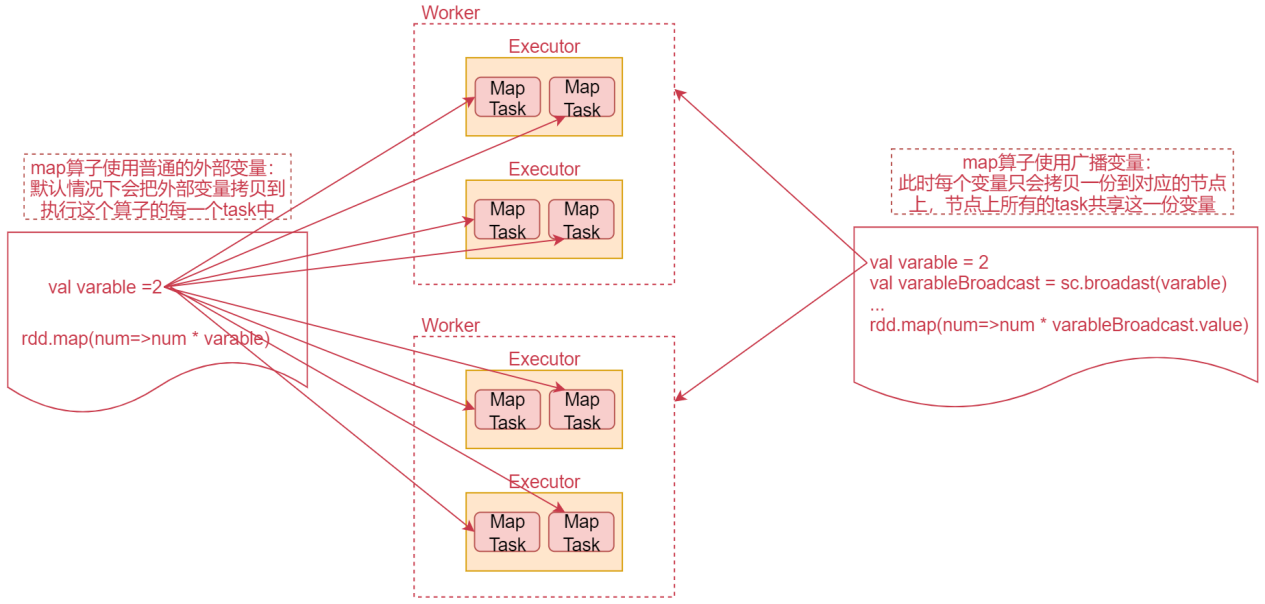
先看左边的代码
这个是一个咱们经常使用的map算子的代码,map算子中执行对每一个元素乘以一个固定变量的操作,此时这个固定的变量属于外部变量。
默认情况下,算子函数内,使用到的外部变量,会被拷贝到执行这个算子的每一个task中。看图中间的MapTask,这些都是map算子产生的task,也就是说这个外部变量会被拷贝到每一个task中。
如果这个外部变量是一个集合,集合中有上亿条数据,这个网络传输就会很耗时,而且在每个task上,占用的内存空间,也会很大>如果算子函数中使用的外部变量,是广播变量的话,那么每个变量只会拷贝一份到每个节点上。节点上所有的task都会共享这一份变量,就可以减少网络传输消耗的时间,以及减少内存占用了。
大家可以想象一个极端情况,如果map算子有10个task,恰好这10个task还都在一个worker节点上,那么这个时候,map算子使用的外部变量就会在这个worker节点上保存10份,这样就很占用内存了。
下面我们来具体使用一下这个广播变量
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用广播变量
*/
object BroadcastOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("BroadcastOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val varable = 2
//dataRDD.map(_ * varable)
//1:定义广播变量
val varableBroadcast = sc.broadcast(varable)
//2:使用广播变量,调用其value方法
dataRDD.map(_ * varableBroadcast.value).foreach(println(_))
sc.stop()
}
}
Accumulator
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。
正常情况下在Spark的任务中,由于一个算子可能会产生多个task并行执行,所以在这个算子内部执行的聚合计算都是局部的,想要实现多个task进行全局聚合计算,此时需要使用到Accumulator这个共享的累加变量。
注意:Accumulator只提供了累加的功能。在task只能对Accumulator进行累加操作,不能读取它的值。只有在Driver进程中才可以读取Accumulator的值。
下面我们来写一个案例
package com.imooc.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用累加变量
*/
object AccumulatorOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("AccumulatorOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//这种写法是错误的,因为foreach代码是在worker节点上执行的
// var total = 0和println("total:"+total)是在Driver进程中执行的
//所以无法实现累加操作
//并且foreach算子可能会在多个task中执行,这样foreach内部实现的累加也不是最终全局
/*var total = 0
dataRDD.foreach(num=>total += num)
println("total:"+total)*/
//所以此时想要实现累加操作就需要使用累加变量了
//1:定义累加变量
val sumAccumulator = sc.longAccumulator
//2:使用累加变量
dataRDD.foreach(num=>sumAccumulator.add(num))
//注意:只能在Driver进程中获取累加变量的结果
println(sumAccumulator.value)
}
}