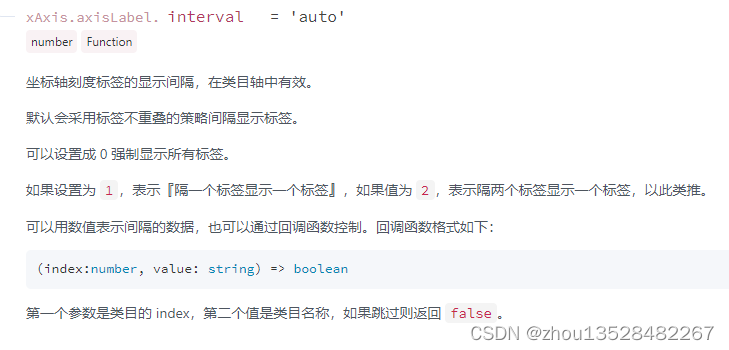
一、概述
还记得我们在上一讲末尾提到的关于默认标签解析和自定义标签解析吧。本讲就来针对默认标签解析进行讲解。为了便于衔接上一讲的内容,我们将源码部分粘贴出来:
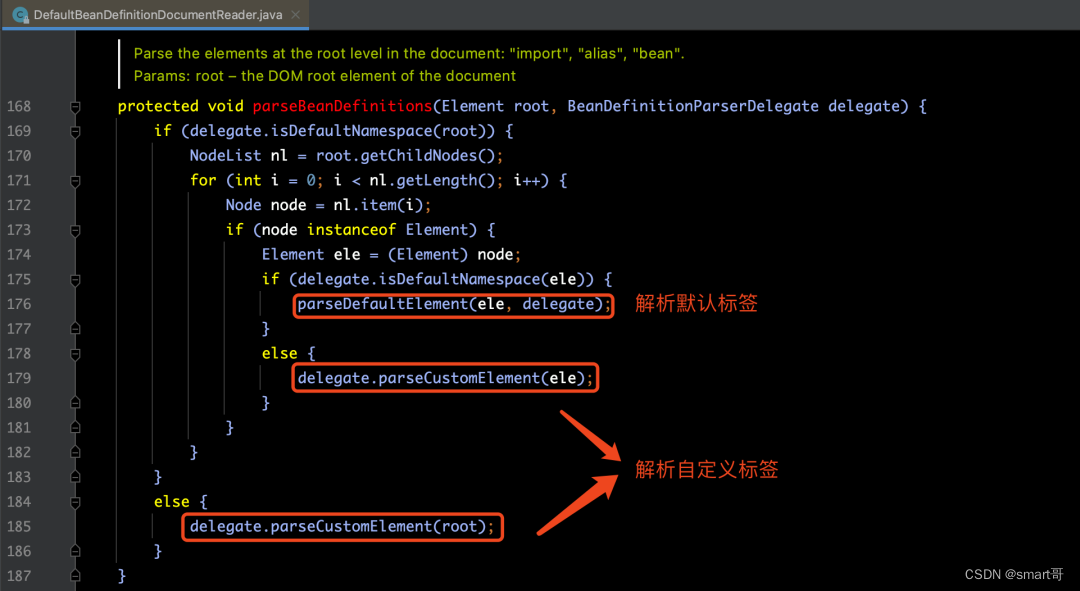
从上图中的源码中,我们可以看出默认标签的解析是在parseDefaultElement(ele, delegate)方法中实现的。我们来看一下这个方法如何实现的:

在parseDefaultElement(ele, delegate)方法中我们可以看到,它分别针对4种不同的标签(即:import标签、alias标签、bean标签和beans标签)做了解析操作。那么下面我们就通过下面的4部分内容来对这些标签的解析进行深度剖析。
二、bean标签的解析
在上面的4种标签中,对bean标签的解析最为复杂和重要,所以我们先从这个标签开始深入分析,如果能够理解它的解析过程,那么其他标签就不难理解了。我们废话不多说,言归正传。先来看看processBeanDefinition(ele, delegate)方法内部的具体实现逻辑:
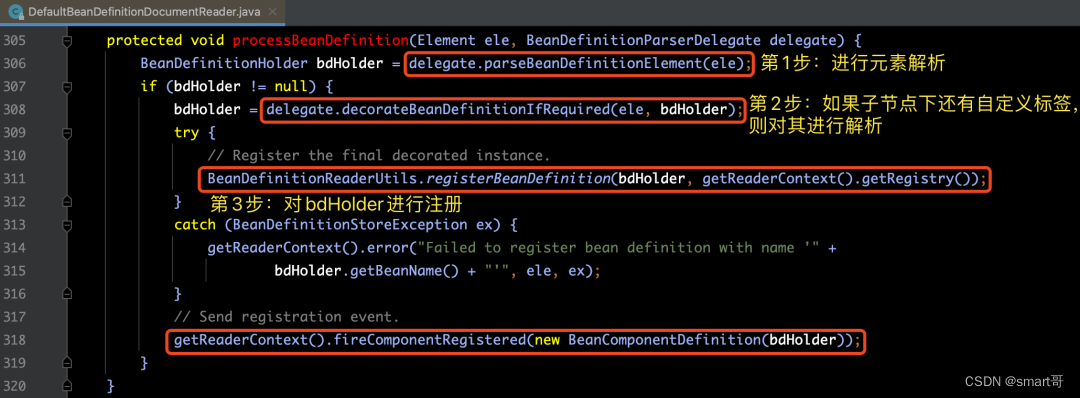
bean标签的解析和注册的时序图如下所示:
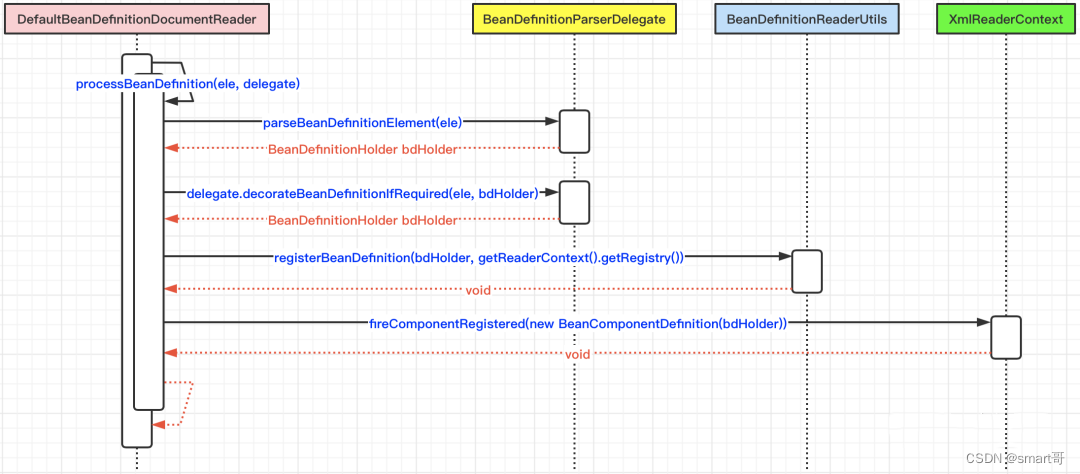
2.1> parseBeanDefinitionElement(ele)
首先我们来看一下元素解析部分内容,在parseBeanDefinitionElement(ele)方法中,但是这个方法其实只起到了“周转”的作用,它的内部其实又调用了parseBeanDefinitionElement(ele, null)方法,所以,我们看下一个方法的内部实现:

在 parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) 方法中,其实一共执行了如下4个步骤(【注】但是下图中只列出了其中的第1步骤和第2步骤,后面文章内容,再给大家展示剩下的后两个步骤)。
【步骤1】提取Element元素中的“
id”和“name”属性,并将name解析为aliases,然后为beanName赋值。
【步骤2】解析其他属性并封装到GenericBeanDefinition类型的实例中。
【步骤3】如果发现bean没有指定beanName,那么使用默认规则生成beanName。
【步骤4】将获取到的信息封装到GenericBeanDefinition类型的实例中。
2.1.1> 步骤1:解析beanName和aliases
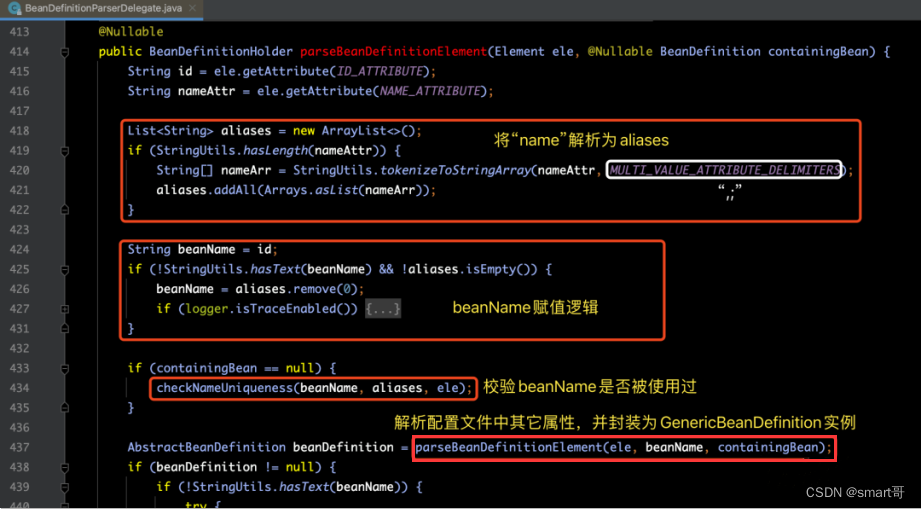
其中,checkNameUniqueness(beanName, aliases, ele)是用于校验beanName和aliases是否是唯一的,即:不允许出现重复的名字(name)。如果发现有重复的,则直接抛出异常。具体逻辑实现,请见下图源码注释:

2.1.2> 步骤2:解析其他属性
对于其他属性的解析,是在parseBeanDefinitionElement(ele, beanName, containingBean)方法中实现的,具体源码如下所示:
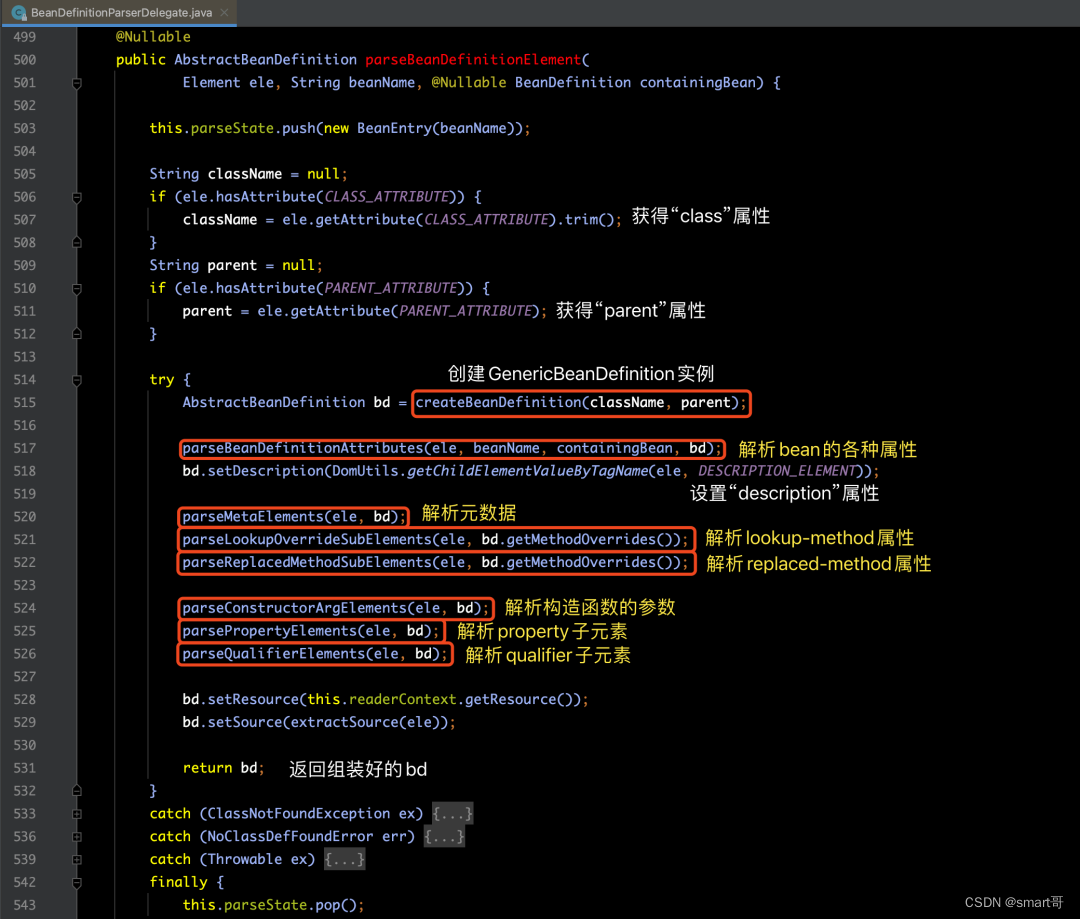
a> 创建GenericBeanDefinition实例
创建BeanDefinition的这部分内容,是通过调用createBeanDefinition(className, parent)方法实现的。但是,在介绍整个方法内部逻辑之前,我们先来了解一下BeanDefinition,它到底是做什么用的?
BeanDefinition是配置文件中 <bean>元素标签在Spring容器中的表现形式 ,也就是说,它是用来承载bean信息的。在配置文件中可以定义父级<bean> 和 子集<bean> ,它们分别由RootBeanDefinition和ChildBeanDefinition表示。而如果没有父级的话,则用RootBeanDefinition表示。而GenericBeanDefinition是从2.5版本之后加入进来的,用于为bean文件配置属性属性定义提供一站式服务。这三个类之间的关系如下图所示:

了解了BeanDefinition的3个实现类之后,我们再来看一下createBeanDefinition(className, parent)方法的具体实现:

上图中的createBeanDefinition(...)方法内部基本没做什么,关键的内容在红框的BeanDefinitionReaderUtils.createBeanDefinition(...)方法调用上,下图是createBeanDefinition(...)方法的源码部分:
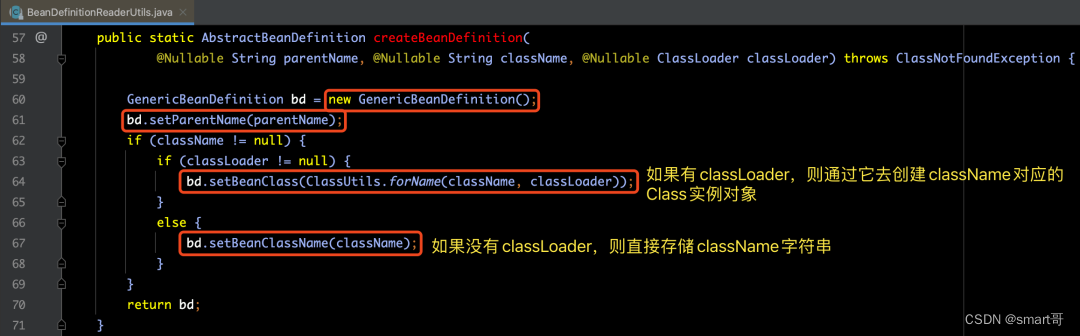
通过上图源码,我们可以看出来createBeanDefinition(...) 方法执行了很简单的 4步 操作:
【步骤1】创建
GenericBeanDefinition实例对象bd。
【步骤2】为bd设置parentName属性。
【步骤3】为bd设置beanClass属性。(如果classLoader不为空,则利用它去创建className对应的Class实例对象)
【步骤4】为bd设置beanClassName属性。(如果classLoader为空,则只需赋值className即可)
b> 解析bean的各种属性
有了可以承载bean信息的GenericBeanDefinition实例对象之后,我们就来继续往下分析,看看负责 解析bean中各个属性 的逻辑代码——parseBeanDefinitionAttributes(ele, beanName, containingBean, bd):需要补充的一点是,此时入参containingBean等于null。
在分析该方法源码之前,我们先来看如下两个遍历中的内容:一个是入参的ele,另一个是全局变量defaults。在下面的源码解析中,我们会经常回过来参照这两个参数所存储的值。
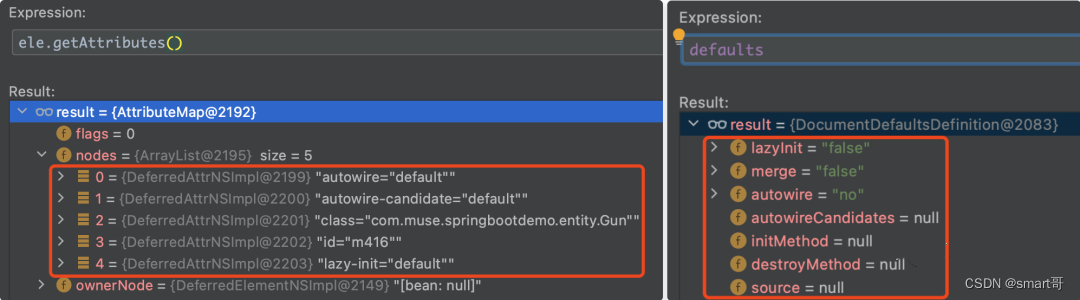
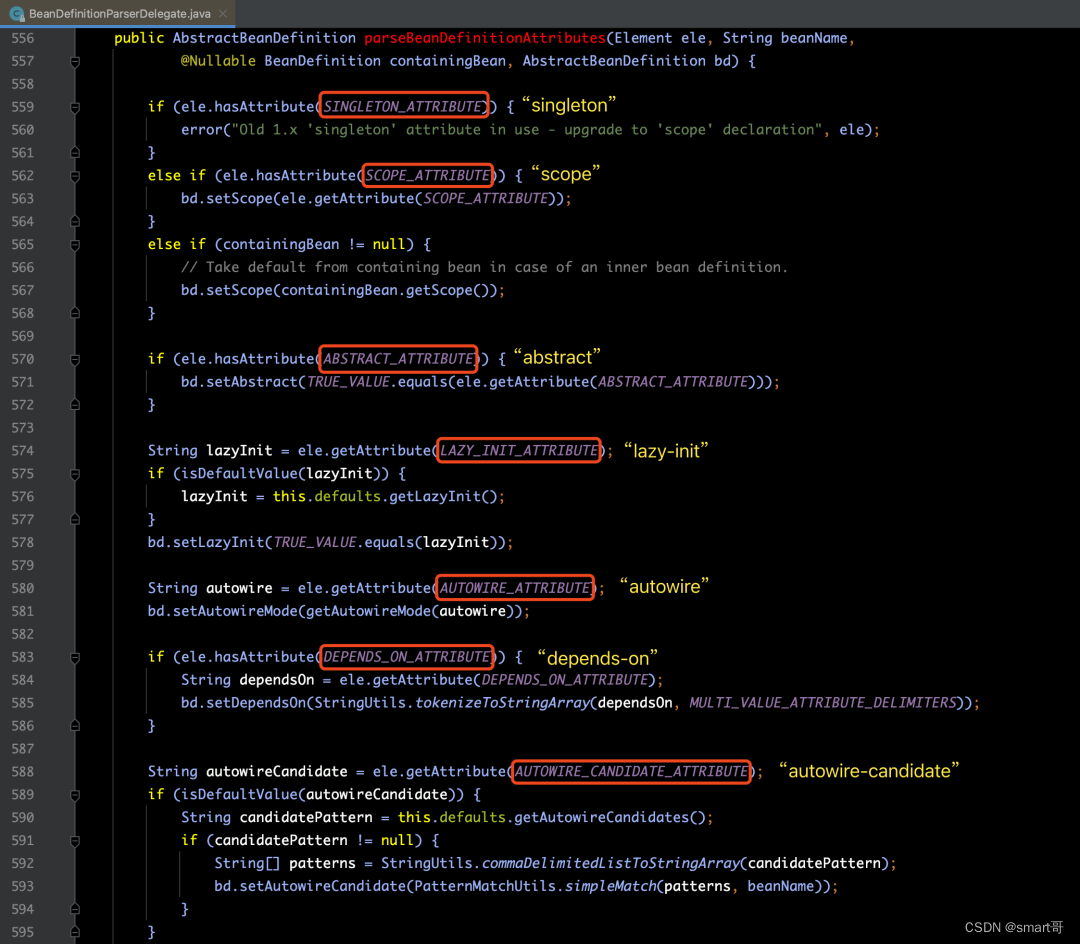
针对parseBeanDefinitionAttributes(ele, beanName, containingBean, bd)方法的源码,如下图所示:
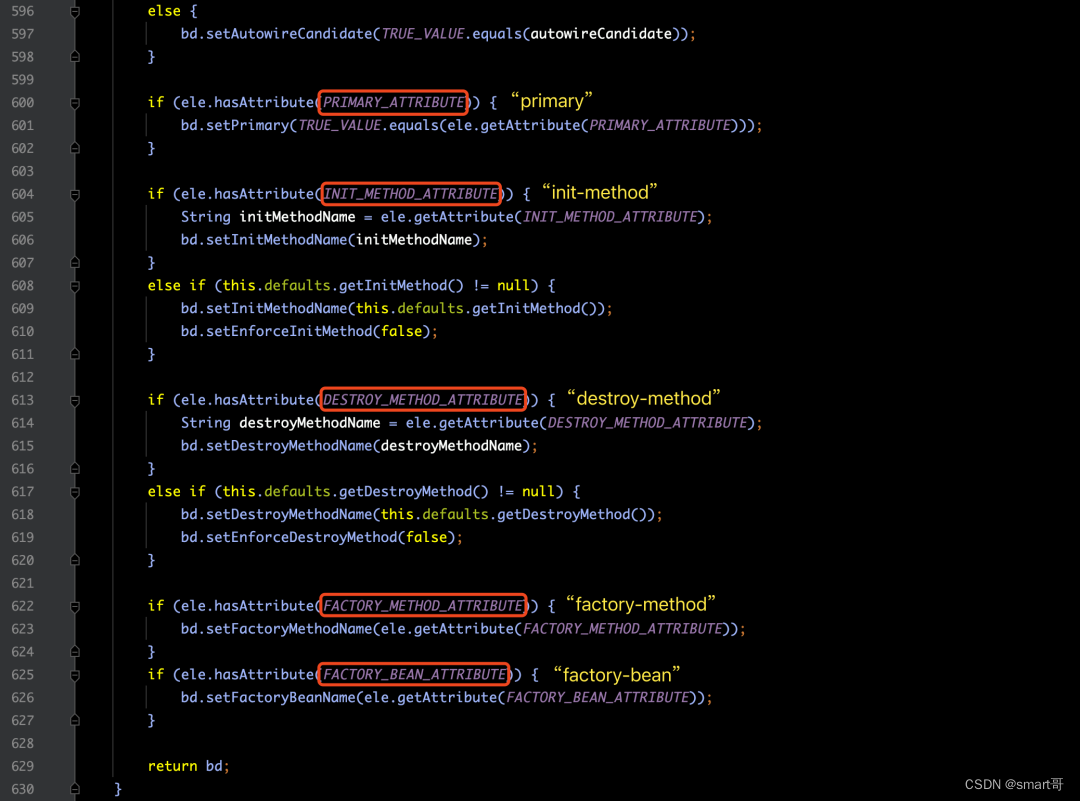
c> 解析元数据
下面我们在来看一下元数据解析方法——parseMetaElements(ele, bd);再介绍源码之前,我们先来看一下Spring中的meta标签使用方式如下:
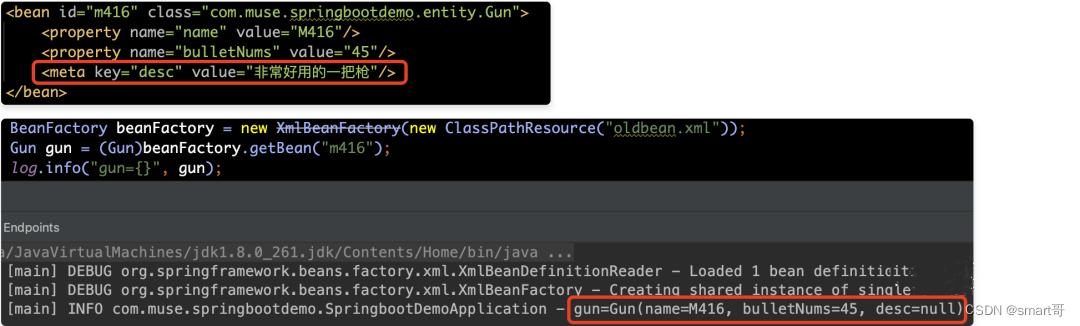
从上面的例子我们可以看出来,使用了
meta标签后,配置的desc并不会体现在Gun的属性当中,而只是一个额外的声明。当需要使用里面的信息的时候,可以通过BeanDefinition的getAttribute(key)方法进行获取。
下面我们再来看一下parseMetaElements(ele, bd)的源码部分:
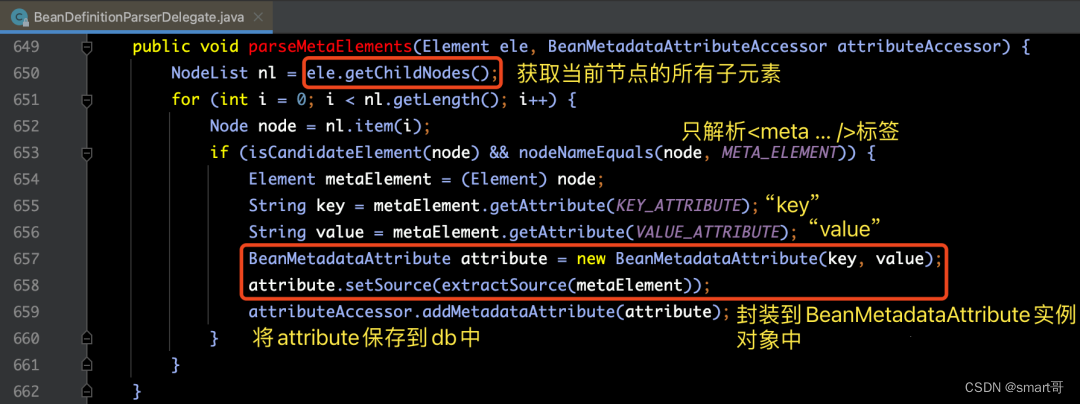
d> 解析lookup-method属性
我们平时对于lookup-method的使用其实是不多的,所以,我们在介绍关于lookup-method属性解析之前,先了解一下它是怎么使用的。如下代码所示,我们有一个抽象类Writer,它有一个写作的方法write(),但是具体使用哪种类型的笔去写作,则需要抽象方法getPen()来决定。那么关于笔的类型,我们提供了铅笔(Pencil)和毛笔(Brush)这两种。具体如下所示:
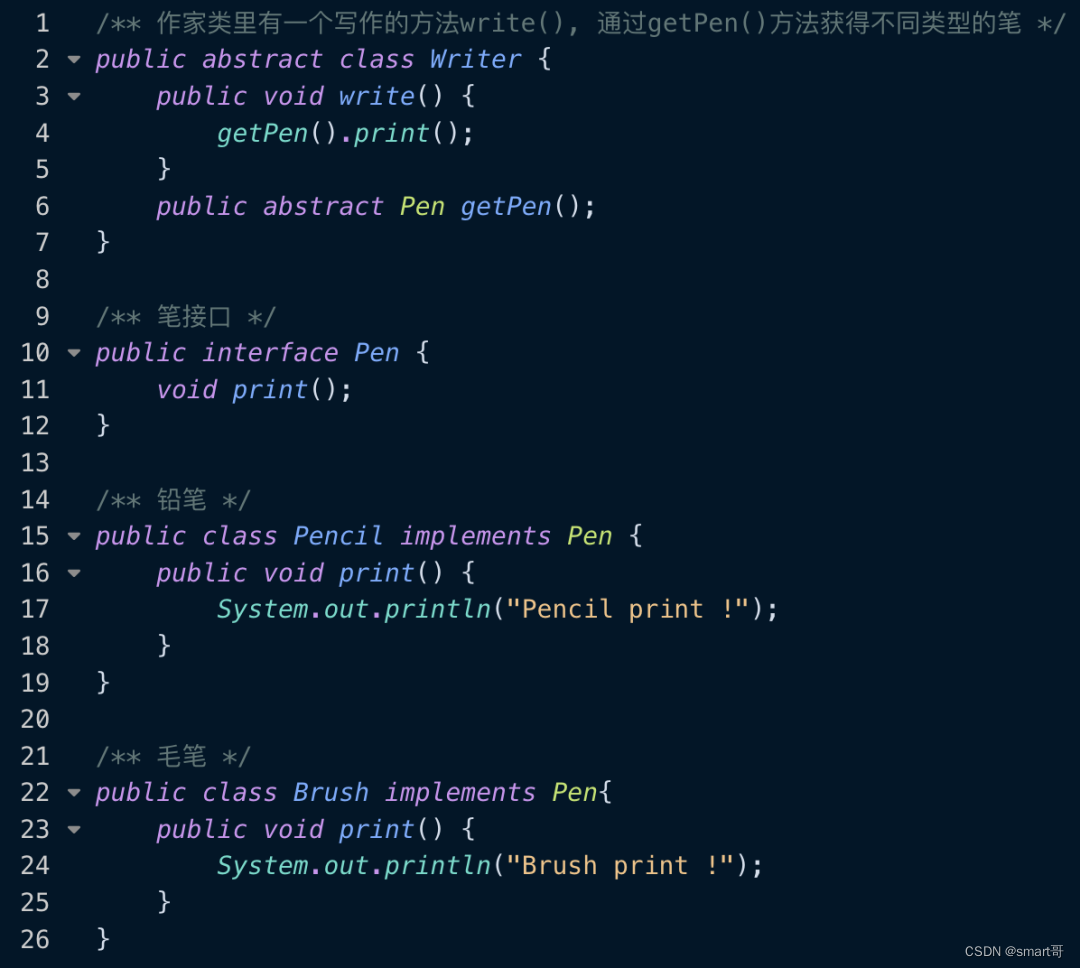
然后,我们通过在xml的配置文件中,使用lookup-method标签,将pencil的bean赋值给getPen()方法,那么运行结果显示“Pencil print !”
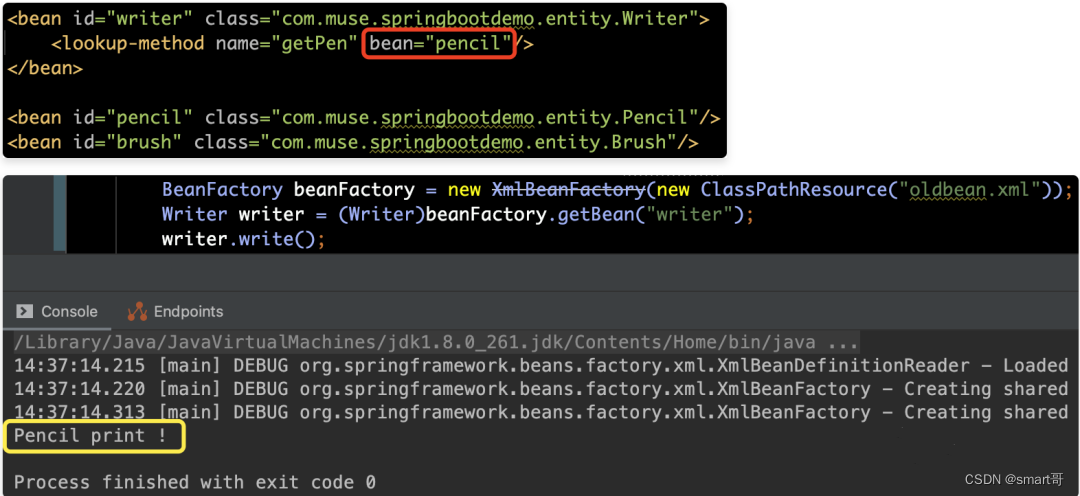
然后,我们可以通过修改xml配置中的lookup-method标签,将原来的“pencil”替换为“brush”,再运行一下,那么运行结果显示“Brush print !”

【总结】根据上面的演示,我们可以知道
lookup-method它的作用是获取器注入。即:获取器注入是一种特殊的方法注入,它是把一个方法声明为返回某种类型的bean,但实际要返回的bean是在配置文件里面配置的,此方法可用在设计有些可插拔的功能上,解除程序依赖。
好了,讲完了lookup-method的使用方法和作用之后,我们再来看一下parseLookupOverrideSubElements(ele, bd.getMethodOverrides())方法的源码实现:
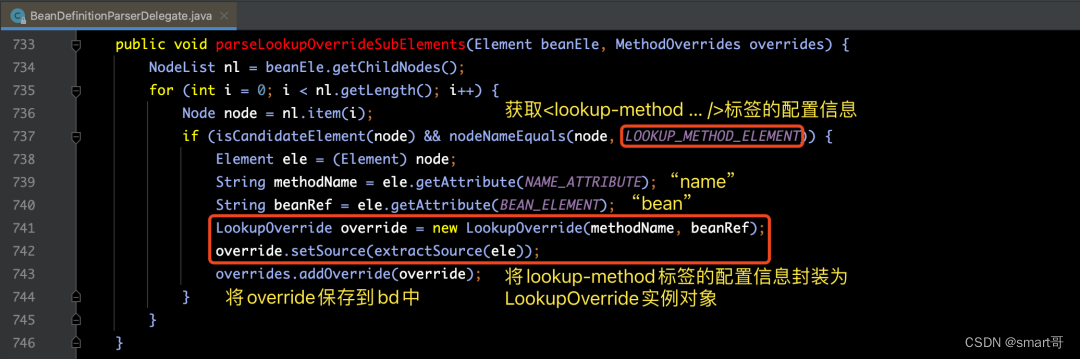
【总结】
parseLookupOverrideSubElements(ele, bd.getMethodOverrides())方法的内部逻辑跟我们解析元数据的方法parseMetaElements(ele, bd)非常类似。此次就不再赘述了。
e> 解析replaced-method属性
在介绍对replaced-method属性解析之前,我们还是来看一下它的使用场景吧。假设有个程序员Coder觉得工资又少,工作又多,非常烦躁。他打算去跟他们老板吼叫(shout)一番,表达自己内心的不满——“老板!我要离职!我不想写代码了!烦死了!”。具体实现如下所示:
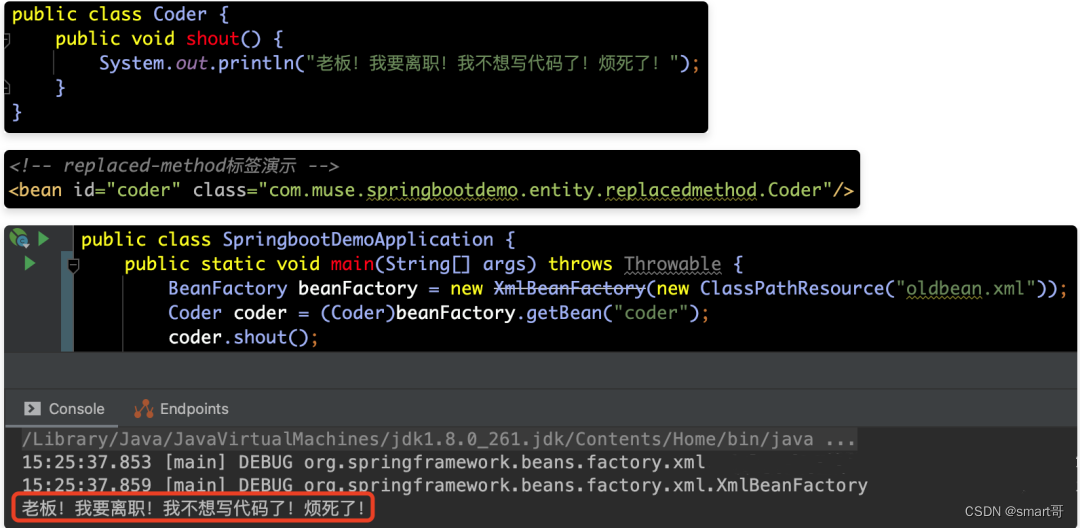
但是在他马上要到达老板办公室门口的时候,接到了他女朋友的电话,电话那头说:“我爸妈同意咱俩结婚了,但是有个前提,就是要买个楼房。”程序员一想,自己买房的钱还没凑够呢!这不能离职啊!但是他此时已经推开了领导办公室的门。为了不喊出离职的那句话,我们可以采用MethodReplacer的方式改变shout方法的实现逻辑,从而让程序员Coder说出:“老板!我最爱写代码了!我会一直忠于公司为您工作的!”这句话,具体实现如下所示:
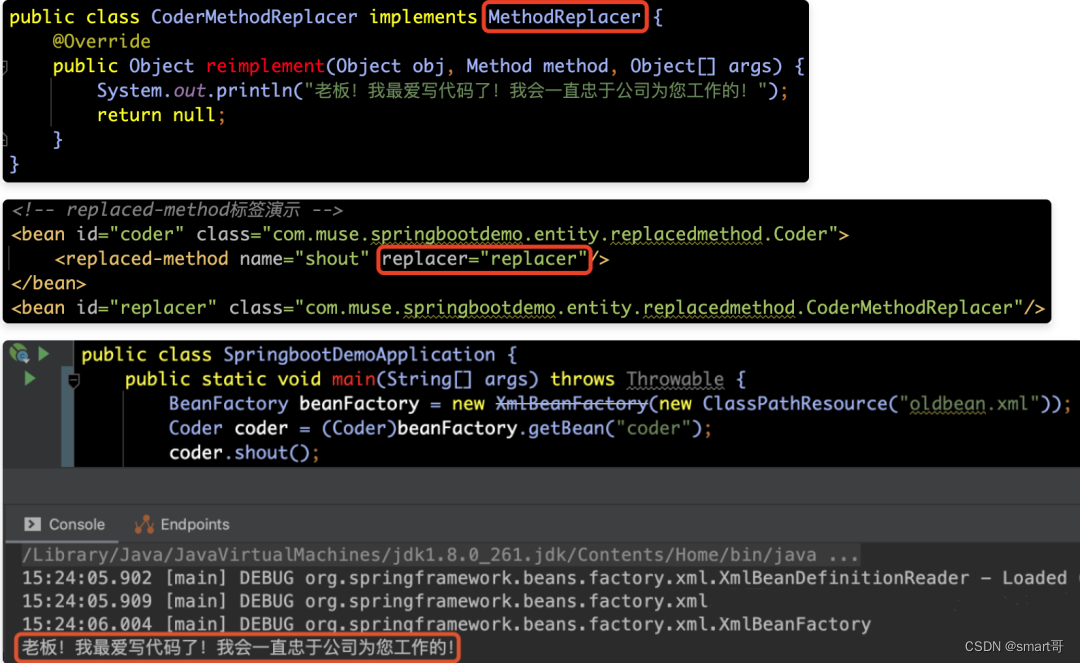
【总结】
replaced-mothod可以实现方法替换,即:可以在运行时用新的方法替换现有的方法。
好了,理解了replaced-mothod标签的使用方式之后,我们来看一下parseReplacedMethodSubElements(ele, bd.getMethodOverrides())方法是如何对replaced-method属性进行解析的。详细解题源码如下所示:

f> 解析构造函数的参数
对于构造函数的配置方式,请见如下所示:
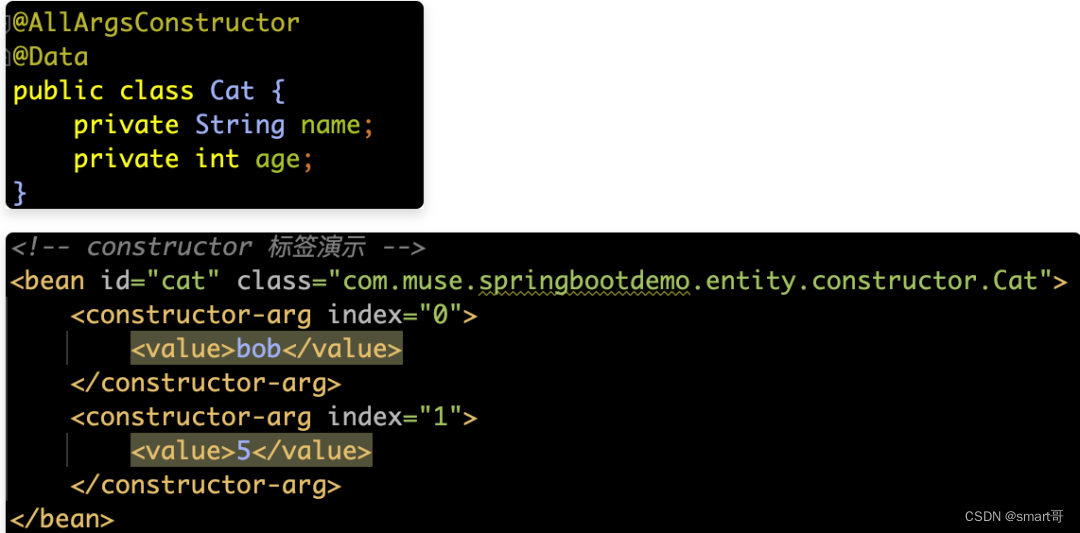
【解释】默认情况下是按照参数的顺序注入的,当指定index索引后,就可以改变注入参数的顺序。
下面是parseConstructorArgElements(ele, bd)方法的源码实现:

我们可以在上面看到,方法内部又调用了parseConstructorArgElement((Element) node, bd)方法,这里面才是真正解析逻辑的地方:



上面的代码还是比较好理解的,但是关于parsePropertyValue(ele, bd, null)方法,我们还需要再看一下。源码如下所示:

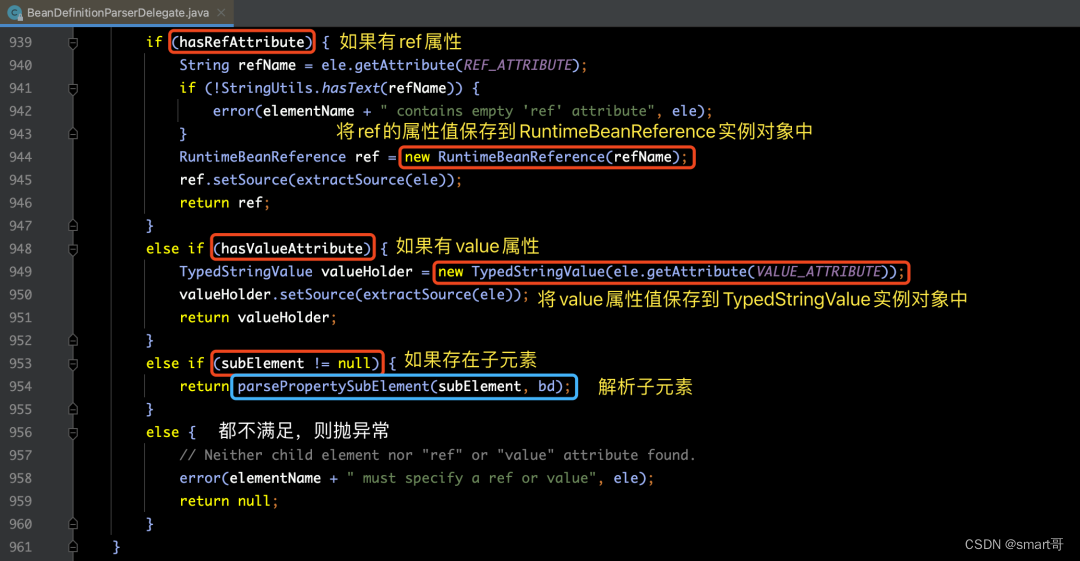

那么关于上图蓝色框所标注的parsePropertySubElement(subElement, bd)方法,我们来看一下它的具体实现:


通过上图中源码的注释,可以看出逐一的对constructor-arg的子元素进行解析,针对每个子元素的解析此处不再进行讲解。这些子元素都可以通过如下配置方式进行配置:

g> 解析property子元素
在方法parsePropertyElements(ele, bd)中,对property标签进行了解析。关于property标签的使用,如下所示:

那么解析property子元素的源码如下所示:

【解释】可以看到上面函数与构造函数注入方式不同的是,返回值使用PropertyValue进行封装,并记录在了
BeanDefinition的propertyValues属性里。
h> 解析qualifier子元素
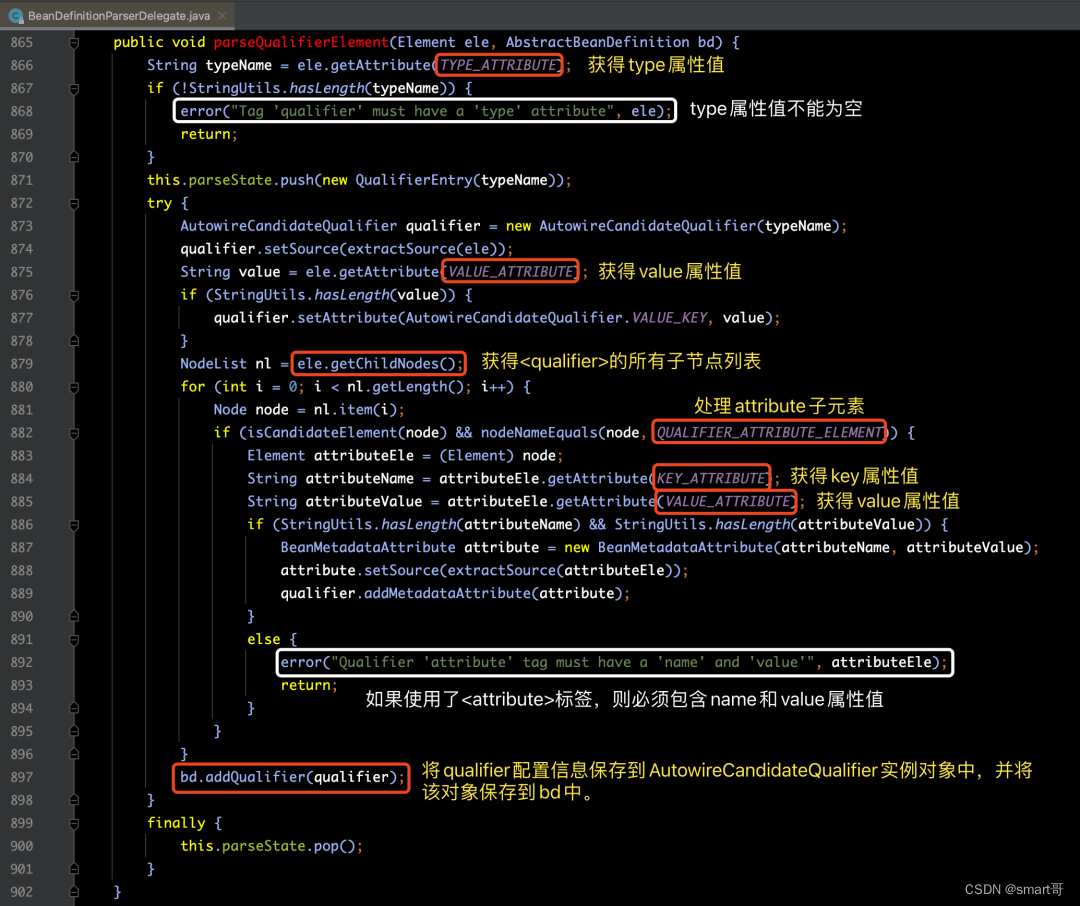
当同一类型的bean注入到IOC之后,Spring容器中匹配的候选Bean数目必须有且仅有一个,那么此时,我们可以通过Qualifier指出注入Bean的名称,这样其一就消除掉了,配置方式如下所示:

具体源码实现,如下图所示:

2.2> decorateBeanDefinitionIfRequired(ele, bdHolder)
上面是针对parseBeanDefinitionElement(ele)方法进行的解析,下面我们要解析的是下图中红框标注的方法:

当Spring中的<bean>标签的子元素使用了自定义标签配置,则会被decorateBeanDefinitionIfRequired(ele, bdHolder)方法解析,如下所示:
<bean id="test" class="com.muse.Test">
<mybean:user username="muse">
</bean>那么,下面我们来看一下decorateBeanDefinitionIfRequired(ele, bdHolder)方法的源码实现:
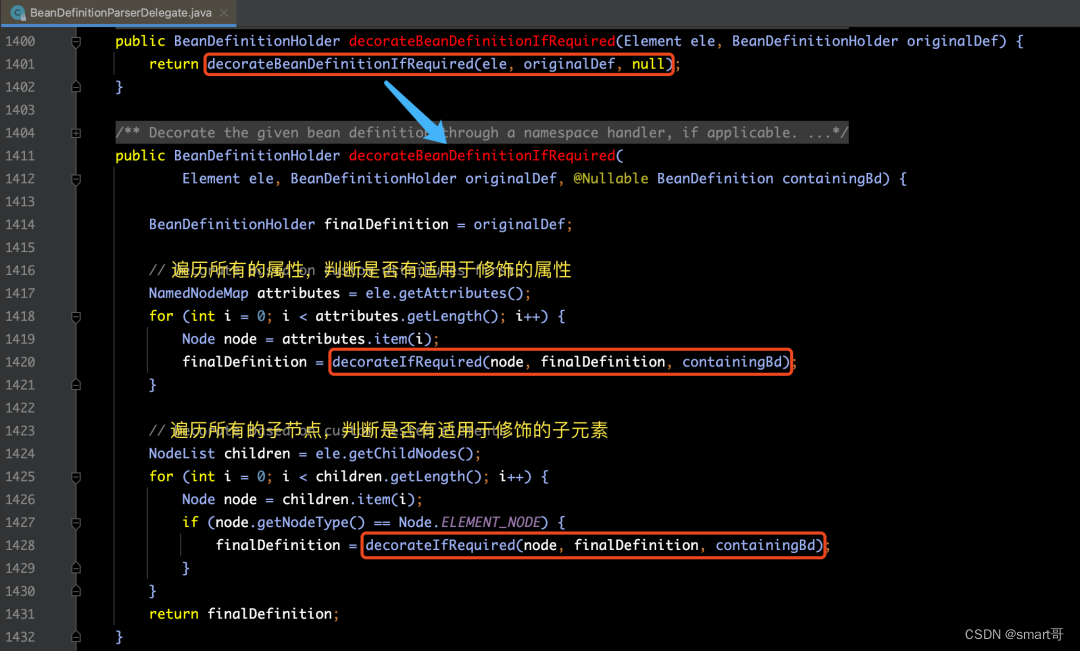
【解释】上面调用
decorateBeanDefinitionIfRequired(ele, originalDef, null)方法的时候,第三个参数传递的是null,因为第三个参数是父类bean,当堆某个嵌套配置进行分析时,这里需要传递父类的BeanDefinition。分析源码得知这里传递的参数其实是为了使用父类的scope属性,以备子类若是没有设置scope时,默认使用父类的属性,这里分析的是顶层配置,所以传递null。
在上面代码中,我们看到无论是对所有属性还是所有子节点,都会执行decorateIfRequired(node, finalDefinition, containingBd)方法,那么我们再来看一下这个方法的内部实现:

其中,isDefaultNamespace(namespaceUri)是通过判断 namespaceUri不为空,并且等于"http://www.springframework.org/schema/beans",如果都满足,则是默认的命名空间。否则是自定义的命名空间。
通过调用readerContext.getNamespaceHandlerResolver(),我们可以获得如下红框中的 命名空间对应的处理器(NamespaceHandler)。
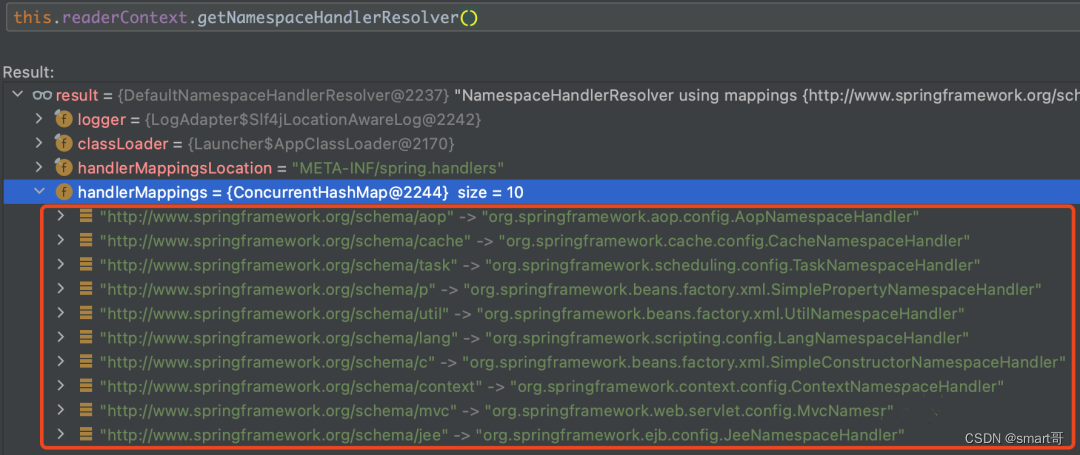
其中关于自定义标签的解析过程,我们会在第3讲部分介绍,此处就直接略过了。
2.3> registerBeanDefinition(...)
上面我们执行完了对配置的解析和装饰操作,那么下面就该到注册阶段了。涉及源码部分如下图所示:
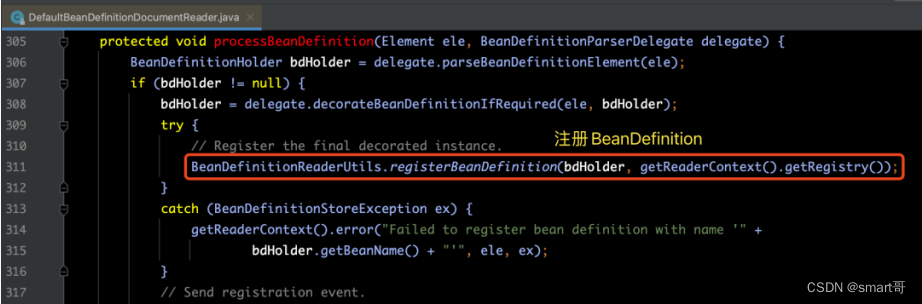
在下面的代码中,我们可以看到总共有两个步骤的操作,分别是:注册BeanDefinition 和 注册别名Alias。
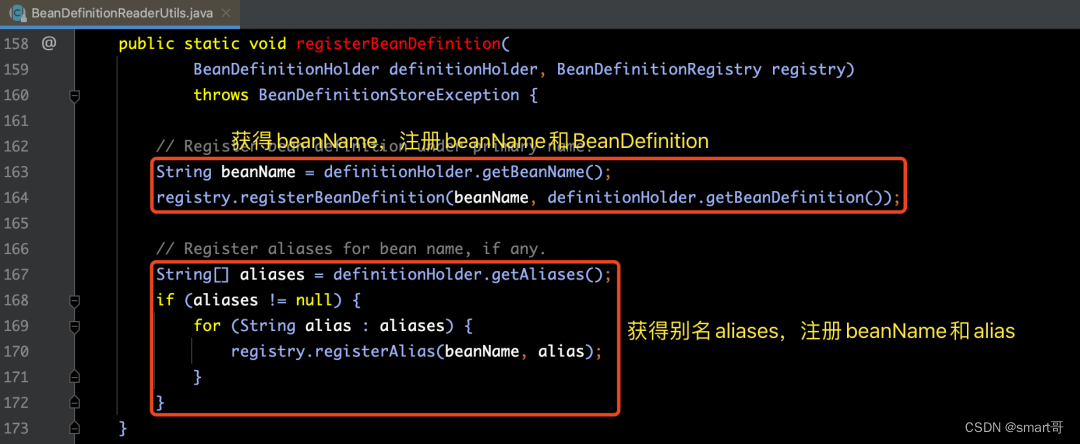
那么下面我们先来看一下注册BeanDefinition的方法registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition())的处理逻辑:
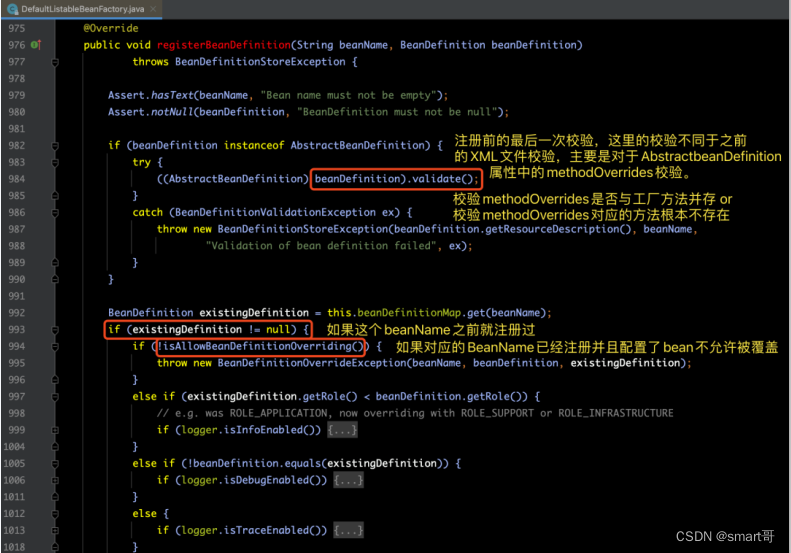

【解释】从上面的代码中,我们可以看到针对bean的注册处理方式上,主要进行了以下几个步骤:
【步骤1】对AbstractBeanDefinition的校验。在解析XML文件的时候我们提过校验,但是此校验非彼校验,之前的校验是针对XML格式的校验,而此时的校验是针对于AbstractBeanDefinition的methodOverrides属性的。
【步骤2】对beanName已经注册的情况的处理。如果设置了不允许bean的覆盖,则需要抛出异常,否则直接覆盖。
【步骤3】加入map缓存。
【步骤4】清除解析之前留下的对应beanName的缓存。
那么下面我们先来看一下注册别名Alias的方法registry.registerAlias(beanName, alias)的处理逻辑:
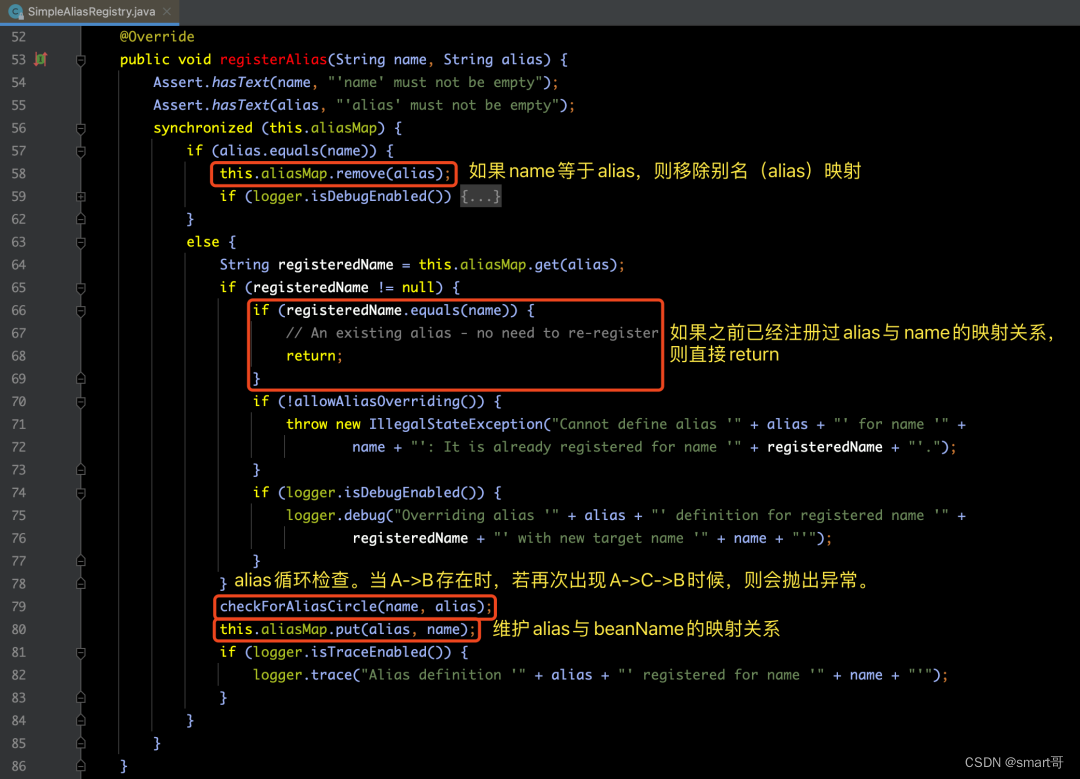
【解释】由以上代码中可以得知,注册alias的步骤如下:
【步骤1】alias与beanName相同情况处理。若alias与beanName名称相同,则不需要处理并删除掉原有alias。
【步骤2】alias覆盖处理。若aliasName之前已经被配置了,则进行3个判断处理。
【步骤3】alias循环检查。
【步骤4】注册alias和beanName到aliasMap中。
2.4> fireComponentRegistered(...)
该方法的目的是为了通知监听器解析及注册完成,这里的实现只为扩展,目前Spring并没有对其进行任何实现。

三、alias标签的解析
在对bean进行定义时,除了使用id属性来指定名称之外,为了提供多个bean的名称,我们可以使用alias标签来指定。例如,通过在<bean>标签中设置name属性来为bean设置别名(alias)。如下所示:
<bean id="gun" name="m416, ak47" class="com.muse.Gun" />另外,Spring还有另外一种声明别名的方式:
<bean id="gun" class="com.muse.Gun" />
<alias name="gun" alias="m416, ak47" />关于alias标签的解析的代码,是在processAliasRegistration(ele)方法内实现的,具体源码请见下图所示:
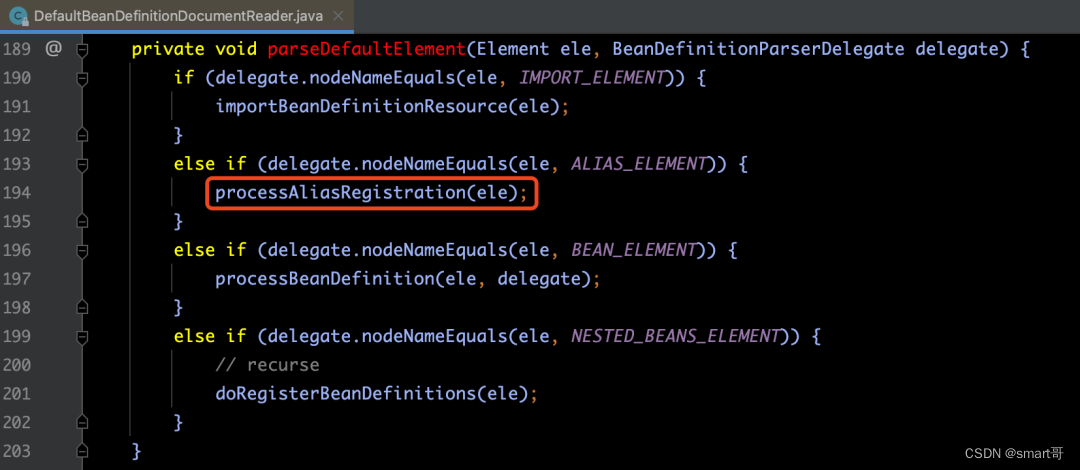
processAliasRegistration(ele)方法的内部源码如下图所示:

【解释】
processAliasRegistration(ele)这个方法的代码逻辑比较简单,与在上文的2.3中讲的内容一样,都是将别名alias与beanName组成一对注册到registry中。此处不再赘述。
四、import标签的解析
对于项目中的大量Spring配置文件而言,如果我们采取分模块维护,那么更易于我们的管理。我们可以通过采用<import>标签,来引入不同模块的配置文件,具体如下所示:
<beans>
<import resource="order.xml" />
<import resource="stock.xml" />
</beans>关于import标签的解析逻辑,我们来看如下源码:
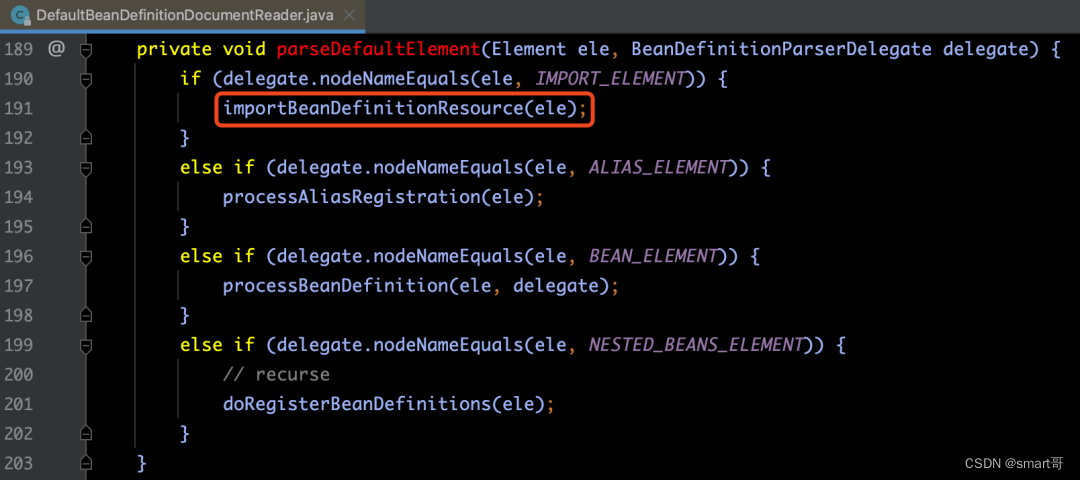
其中,importBeanDefinitionResource(ele)方法的详细源码内容和注释,如下图所示:

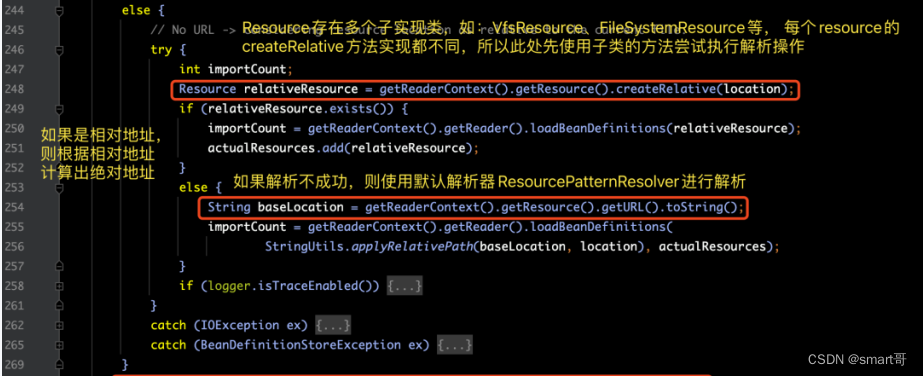
【解释】
1> 获取resource属性所表示的路径。
2> 解析路径中的系统属性,格式如“${user.dir}”。
3> 判定location是绝对路径还是相对路径。
4> 如果是绝对路径,则递归调用bean的解析过程,进行另一次的解析。
5> 如果是相对路径,则计算出绝对路径并进行解析。
6> 通知监听器,解析完成(Spring没有实现内部逻辑)。
五、beans标签的解析
对于嵌入式的beans标签,非常类似于import标签所提供的功能。具体源码位置为下图所示:
对于嵌入式beans标签来讲,并没有太多可讲,与单独的配置文件并没有太大的差别,无非是递归调用beans的解析过程。并且,在第1讲的2.3.2章节,就对doRegisterBeanDefinitions(ele)方法进行了解析,此处就不在赘述了。