- 给定长度为m的非重复数组p,以及从其中取n(n<m)个数字组成新的子数组q。现要对p进行排序,要求:q在数组的最前方,其余数字按从小到大的顺序依次排在后面
输入样例:
q = [3, 5, 4]
p = [5, 4, 3, 2, 1]
输出样例:
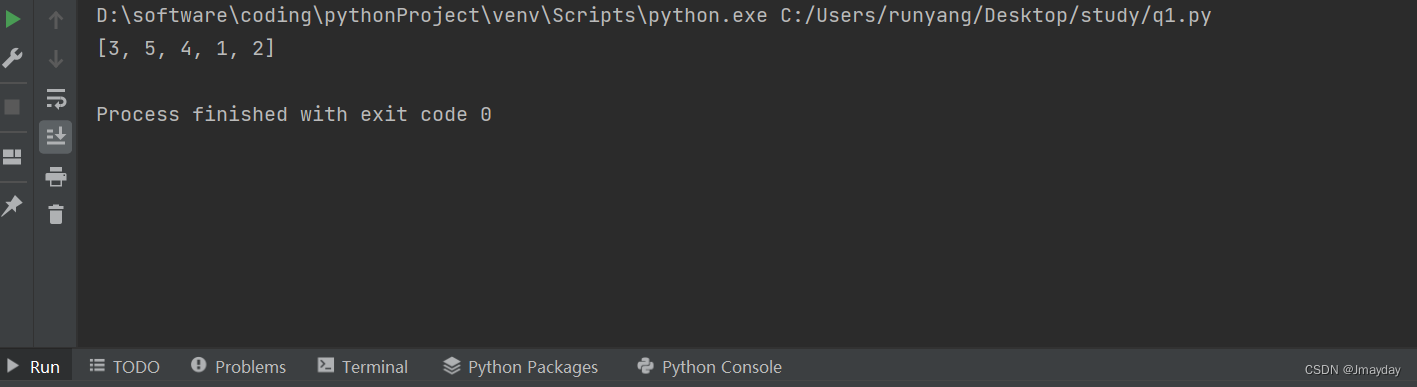
3 5 4 1 2
代码如下:
q = [3, 5, 4]
p = [5, 4, 3, 2, 1]
# 对 p 中的数字进行排序
sorted_p = sorted(p)
# 创建一个空的列表(数组)result
result = []
# 先把q中的数字依次放入result
for ele in q:
result.append(ele)
# 遍历一下排好序的p,也即sorted_p, 将sorted_p 中不在q中的元素依次放到result
for num in sorted_p:
if num not in q:
result.append(num)
# 最后,输出结果
print(result)运行结果:
 2、
2、
- 给定小写英文字符串a和一个非负数b(0<=b<26), 将a中的每个小写字符替换成字母表中比它大b的字母。这里将字母表的z和a相连,如果超过了z就回到了a。
输入样例:
a = "dfjkldfdfdl"
b = 5
输出示例:
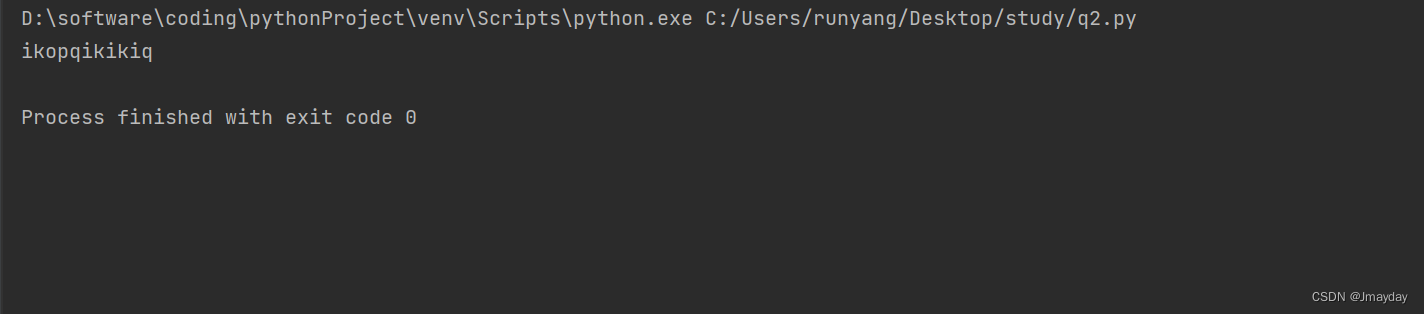
ikopqikikiq
代码如下:
a = "dfjkldfdfdl"
b = 5
# 定义一个空的字符串,用于保存结果
result = ""
# 遍历a中的每个字符,并对其加5
for letter in a:
# 计算出字母表中比letter大b(这里是5)的字符
# 首先我们要得到 ascii码(使用ord函数)
letter_new_code = (ord(letter) - ord('a') + b) % 26 + ord('a')
# 然后我们将 ascii 码转为字母(使用chr函数)
letter_new = chr(letter_new_code)
result += letter_new
# 打印结果
print(result)运行结果:
3. 给定整数a,计算a在二进制表示下1的个数,并输出。
输入样例:
a = 39
输出样例:
4
代码如下:
a = 39
# 定义一个计数器,来统计1的个数
counter = 0
# 遍历 a 的二进制表示中的每一位
for i in range(128):
# 使用位运算符 & 来监测第i位是否为1
if a & (1 << i) != 0:
# 说明第i位上a有1, 那么计数器加1
counter += 1
# 输出结果
print(counter)运行结果:
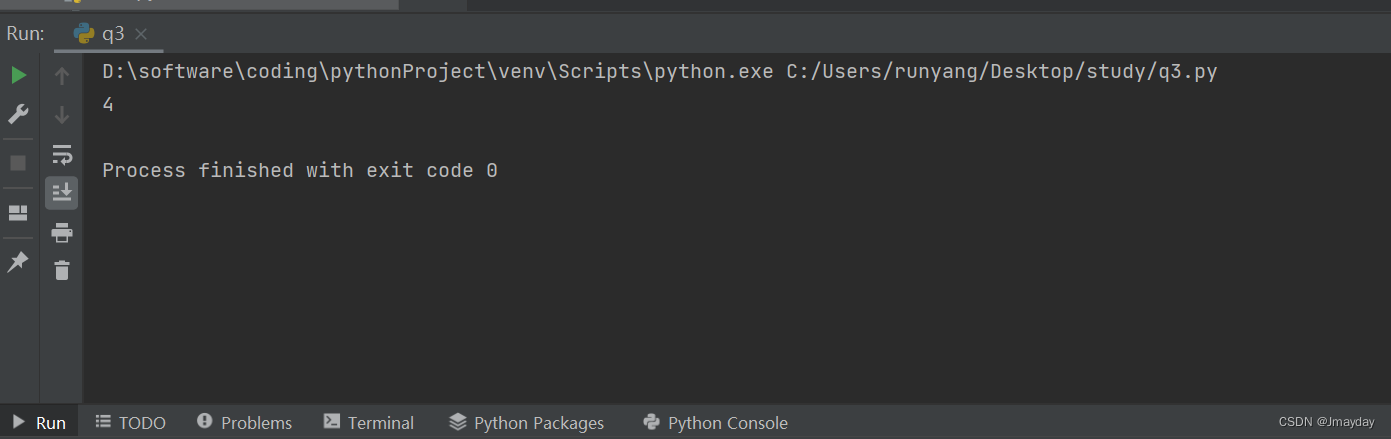
4. 克拉兹猜想:任取一正整数(大于2),如果是偶数,将其除以2。如果是奇数,将其乘以3再加1,然后重复这个过程,最后结果都会陷入4 2 1 的循环。
请通过编程实现,当4,2,1重复第二次的时候,结束循环,并打印整数为16时的输出列表。(编写完程序后,讲数值未16的后续打印出来)
输入样例:
a = 19
输出样例:
19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1, 4, 2, 1
代码如下:
# 定义一个克拉兹猜想(数学家杀手)的函数
def collaz_conjecture(a):
# 定义一个输出的列表,来保存“线路”
result = []
while True:
# 如果是偶数: 除以2
if a % 2 == 0:
a = a // 2
# 如果是奇数: 乘3再加1
else:
a = 3 * a + 1
# 将每次运算的记录保存起来
result.append(a)
# 停止循环:只要出现了两次1(相当于是出现了两次4-2-1),我们就停止循环
if a == 1 and result.count(1) == 2:
break
# 返回输出列表
return result
# 最后,调用函数, 并打印结果
result = collaz_conjecture(39)
idx = result.index(19)
print(result[idx:]) 运行结果:

5. 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,编程将其转换成整数。
输入样例:
III
输出样例:
3
代码如下:
# 定义一个字典,用于保存罗马数字和整数的映射关系
romans = {
"I": 1,
"V": 5,
"X": 10,
"L": 50,
"C": 100,
"D": 500,
"M": 1000,
}
# 定义一个函数,将罗马数字转换成整数
def roman_to_integer(roman):
# 初始化整数0
result = 0
# 遍历一下罗马数字的每一位,再根据映射关系来求和
for i in range(len(roman)):
# 获取当前罗马数字及其下一个罗马数字
current = romans[roman[i]]
if i < len(roman) -1:
next = romans[roman[i+1]]
else:
next = 0
# 如果当前罗马数字比下一个罗马数字大,则加上当前的数字;
# 否则就减去当前的数字
if current >= next:
result += current
else:
result -= current
# 返回结果
return result
# 测试代码
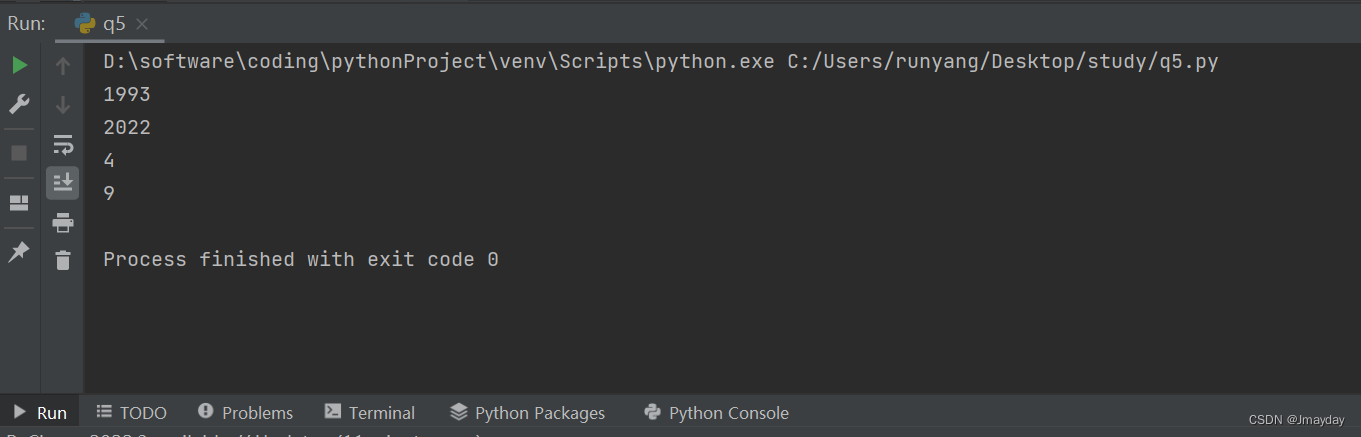
print(roman_to_integer("MCMXCIII"))
print(roman_to_integer("MMXXII"))
print(roman_to_integer("IV"))
print(roman_to_integer("IX"))运行结果:
6. 给定一个链表,请在不修改节点内部值的情况下,两两交换其中相邻的节点,并返回交换后链表的头节点,例如:
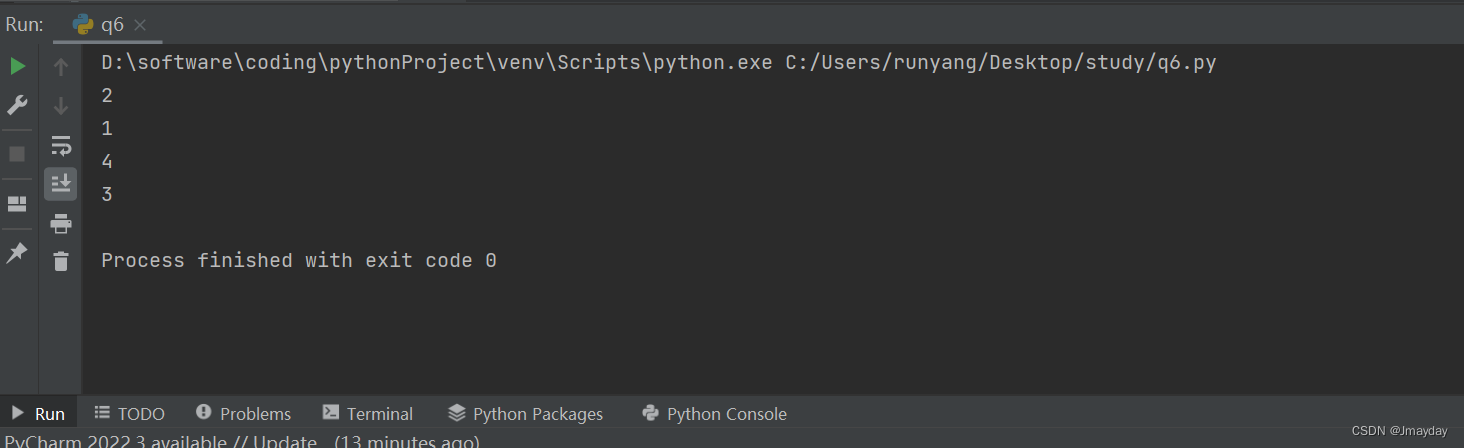
原链表转换为列表:[1, 2, 3, 4]
最终的链表转换为列表:[2, 1, 4, 3]
原链表转换为列表:[1, 2, 3, 4, 5]
最终的链表转换为列表:[2, 1, 4, 3, 5]
原链表转换为列表:[]
最终的链表转换为列表:[]
已知 链表节点的定义代码如下,请实现交换过程,并打印[1, 2, 3, 4]交换后的结果:
class ListNode:
def __init__(self,val,next=None):
if isinstance(val,int):
self.val = val
self.next = next
elif isinstance(val,list):
self.val = val[0]
self.next = None
head = self
for i in range(1,len(val)):
node = ListNode(val[i])
head.next = node
head = head.next
代码如下:
class ListNode:
def __init__(self,val,next=None):
if isinstance(val,int):
self.val = val
self.next = next
elif isinstance(val,list):
self.val = val[0]
self.next = None
head = self
for i in range(1,len(val)):
node = ListNode(val[i])
head.next = node
head = head.next
# 定义链表(示例化ListNode类)
list_node = ListNode([1, 2, 3, 4])
# 定义一个函数,来实现两两交换的功能 -- 递归函数
def swap_pairs(head):
# 如果链表为空或者只有一个节点,那么就无需交换
if head is None or head.next is None:
return head
# 交换头节点和下一个节点
temp = head.next
head.next = temp.next
temp.next = head
# 以递归的方式交换后面其余的节点
head.next = swap_pairs(head.next)
# 返回交换后的头节点
return temp
# 打印交换后的链表
head = swap_pairs(list_node)
while head is not None:
print(head.val)
head = head.next运行结果:
7. 给定一个字符串,请从这个字符串中找出所有最长的没有重复字符的子串,并返回最长不重复子串的长度,例如:
字符串:asdfwedferrf ==> 最长不重复子串:asdfwe,长度6
字符串:wpwswekedw ==> 最长不重复子串:swek, kedw,长度4
代码如下:
def lengthOfLongestSubstring(string):
# 定义一个字典,用于存储输入字符串string中每个字符最后出现的位置
last_idx = {}
max_len = 0 # 初始化最大长度
# 定义一个指针, 表示当前不重复子串的开头位置
start_idx = 0
for i in range(len(string)):
# 跟新 当前窗口的开头 start_idx为:
# start_idx 和 last_idx[string[i]] + 1 中的最大值
if string[i] in last_idx: # 判断一下当前字符是否是已经在前面出现过,
# 如果出现过(出现重复的字符),则跟新start_idx
start_idx = max(start_idx, last_idx[string[i]] + 1)
# 跟新max_len
max_len = max(max_len, i - start_idx + 1)
# 跟新当前字符最后出现的位置
last_idx[string[i]] = i
return max_len
# 调用函数, 打印测试结果
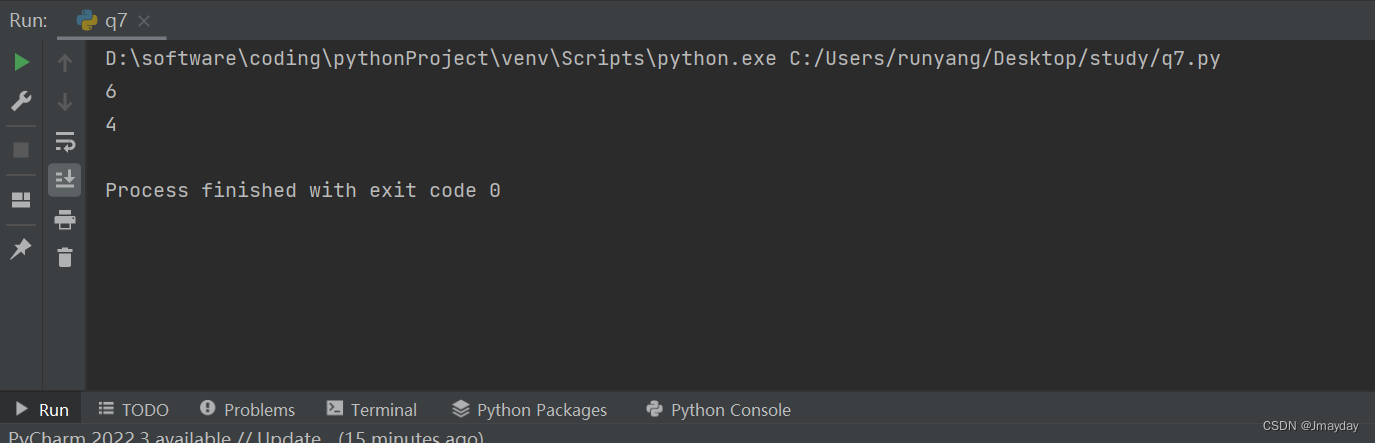
print(lengthOfLongestSubstring("asdfwedferrf "))
print(lengthOfLongestSubstring("wpwswekedw"))运行结果:
8.请设计一个单链表,单链表中的节点应该具有两个属性:val 和 next,val 是当前节点的值,next 是指向下一个节点的指针或引用,并在链表类中实现下列操作:
get(index):获取链表中索引 index 节点的值。如果索引无效,则返回-1。
add_at_head(val):在链表的第一个节点之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
add_at_tail(val):将值为 val 的节点追加到链表的最后一个节点。
add_at_index(index,val):在链表中的索引 index 节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将追加到链表的末尾;如果 index 大于链表长度,则不会插入节点;如果 index 小于0,则在头部插入节点。
delete_at_index(index):如果索引 index 有效,则删除链表中的索引 index 的节点。
说明:链表节点的索引 index 是从 0 开始计算,比如链表中索引 1 下的节点,指的是链表中的第二个节点。
# 先定义节点的类
class Node:
def __init__(self, val, next=None):
self.val = val
self.next = next
# 定义单链表的类
class SingleLinkedList:
def __init__(self,head=None):
self.head = head
def get(self, index):
curr = self.head
for i in range(index):
if not curr:
return -1 # 按照题目要求这里是-1
curr = curr.next
return curr.val if curr else -1 # 按照题目要求这里是-1
def add_at_head(self, val):
self.head = Node(val, next=self.head)
def add_at_tail(self, val):
curr = self.head
if not curr:
self.head = Node(val)
return
while curr.next:
curr = curr.next
curr.next = Node(val)
def add_at_index(self, index, val):
if index == 0:
self.add_at_head(val)
return
curr = self.head
for i in range(index-1):
if not curr:
print('index 超过范围,请选用更小的index')
return
curr = curr.next
# 循环已结束,抵达指定位置
curr.next = Node(val, curr.next)
def delete_at_index(self, index):
curr = self.head
if index == 0:
self.head = self.head.next
return
for i in range(index -1):
if not curr:
print('index 超过范围,请选用更小的index')
return
curr = curr.next
# 循环已结束,抵达指定位置
if curr.next:
curr.next = curr.next.next
# 测试
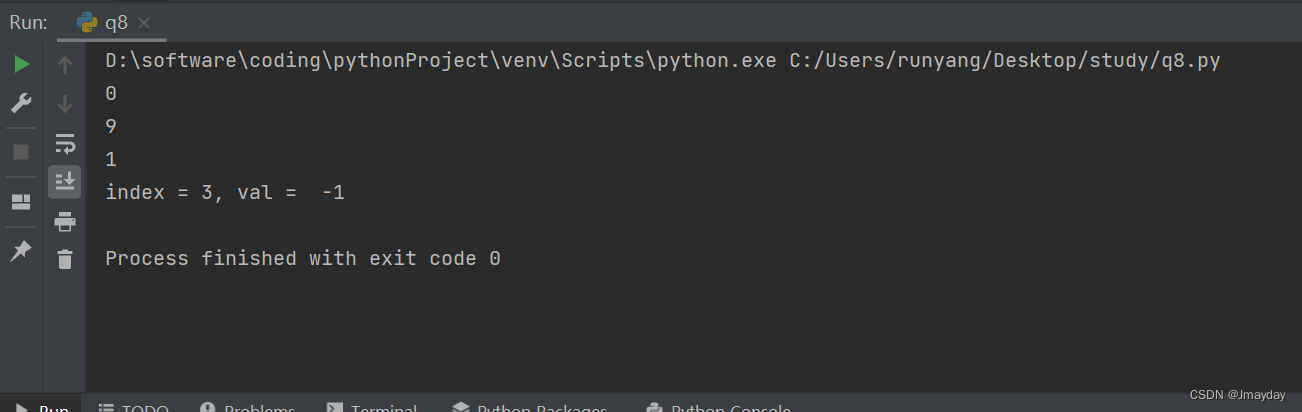
linked_list = SingleLinkedList()
linked_list.add_at_head(0)
linked_list.add_at_head(0)
linked_list.add_at_tail(1)
linked_list.add_at_index(1,9)
linked_list.delete_at_index(2)
# 打印链表
head = linked_list.head
while head is not None:
print(head.val)
head = head.next
# 测试 get 函数
idx = 3
print("index = {}, val = ".format(idx),linked_list.get(idx))
运行结果:
9.给定N个不同的数A[0,...,N-1]以及某定值sum,找到这个N个数中的两个数,使得他们的和为sum,要求时间复杂度为O(N)。
实现此查找函数,并使用参数验证,如:N=[12,35,4,7,9,13,19,43,27,61,32],
sum=65。
思路步骤:
将数组N进行排序,从小到大的顺序 N_sorted
初始化两个位置(指针),分别指向数组N_sorted的首和尾,
如果两个指针的和小于sum: 将左边的指针往右移动一格
如果两个指针的和大于sum: 将右边的指针往左移动一格
如果两个指针的等于sum:保存下来两个指针的位置信息
代码如下:
def solution(N,S):
N_sorted = sorted(N) # 从小到大对列表进行排序
leftIdx = 0 # 初始化左边指针的索引:初始时刻指向最左边
rightIdx = len(N) -1 # 初始化右边指针的索引:初始时刻指向最右边
result = [] #一个空的列表,用来保存结果
while leftIdx < rightIdx: # 从两端进行遍历,如果左边的指针和右边的指针相遇,则停止循环
if N_sorted[leftIdx] + N_sorted[rightIdx] == S:
result.append((N_sorted[leftIdx], N_sorted[rightIdx])) # 满足条件,保存结果
# 更新一下指针
leftIdx += 1 # 左边指针右移一格
rightIdx -= 1 # 右边指针左移一格
elif N_sorted[leftIdx] + N_sorted[rightIdx] > S:
rightIdx -= 1 # 右边指针左移一格, 使的两个数的和变小
else:
leftIdx += 1 # 左边指针右移一格, 使的两个数的和变大
return result # 返回结果
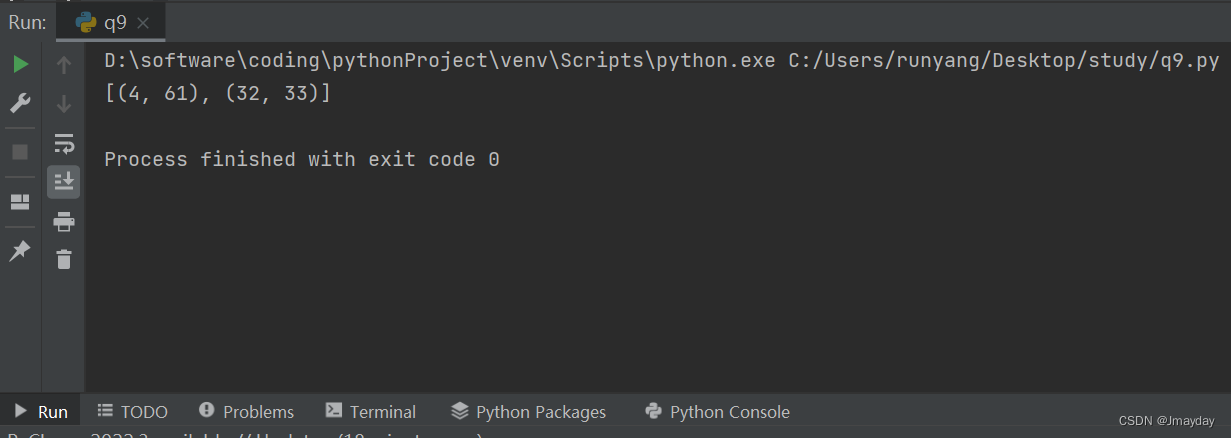
N = [12,33,4,7,9,13,19,43,27,61,32]
S = 65
print(solution(N,S))
# 结果应该是:(33,32), (4,61)运行结果:
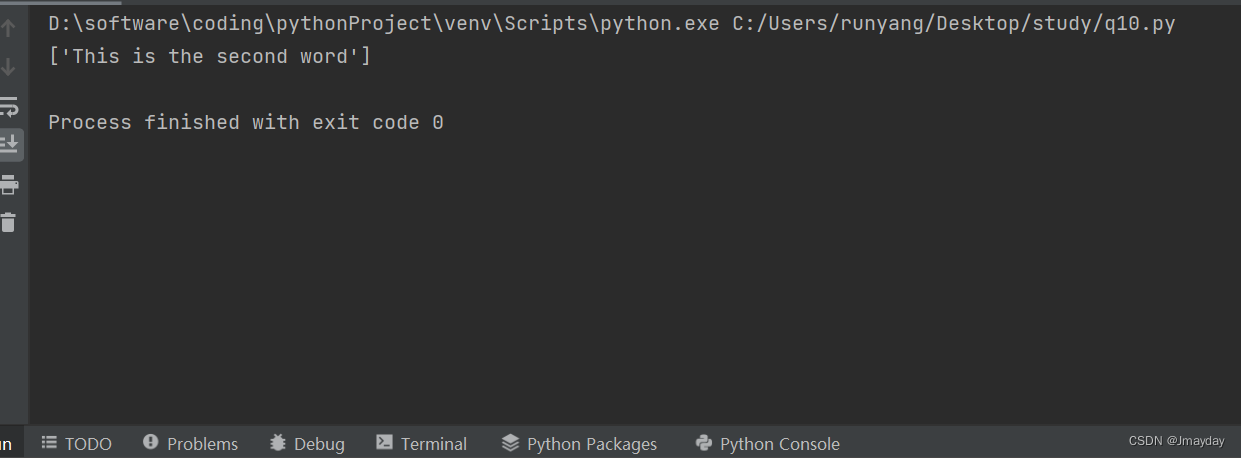
10.给定一个文本列表sentences,它包含n个语句,再任意给出一个关键词keywords列表,包含m个关键词,请使用倒排索引的思想实现一个算法,返回包含所有关键词的句子。
请使用下面的参数验证。
sentences = ['This is the first word',
'This is the second word',
'This is the third word']
keywords = ['This', 'second ']
代码如下:
def solution(sentences,keywords):
# 第一步:遍历所有的句子,得到词汇集
word_set = set() # 一个空的集合,来保存所有的单词
for sentence in sentences: # 遍历所有句子
words = sentence.lower().strip().split() # 得到当前句子的单词,结果是列表
for word in words:
word_set.add(word) # 把每个出现的单词都加到单词集合里面去,重复的会自动去重
# 第二步: 构建倒排索引的字典(原理可以参考一下维基百科或者百度百科)
word_index_dict = {} # 初始化一个空的字典
for word in word_set:
word_index_dict[word] = set() # 初始化当前单词对应的值key为一个空的集合
for i in range(len(sentences)): # 遍历一下所有的句子,看看当前词都在哪个句子里出现过
if word in sentences[i].lower(): # 如果单词在第i个句子里面出现过
word_index_dict[word].add(i) # 那就把句子索引i加入到word对应的集合里
# 第三步,通过集合的交集运算,去查找同时出现keywords所有单词的句子。
keywords = [word.strip().lower() for word in keywords] # 预处理:把关键词变为小写,并且去除不必要的空格
sets = [] # 把keywords里面所有单词对应的集合(上一步得到的word_index_dict里面的值)保存起来
for keyword in keywords: # 遍历所有的关键词
sets.append(word_index_dict[keyword]) # 把每个词对应的集合放到sets列表里
# 最后,求交集
intersection_sets = set.intersection(*sets) # 求交集,得到的是同时出现keywords的句子的索引
# 将索引还原为句子
result = [sentences[idx] for idx in intersection_sets] # (索引还原)结果为句子
return result
sentences = ['This is the first word','This is the second word','This is the third word']
keywords = ['This', 'second ']
print(solution(sentences,keywords))运行结果: