目录
前言
一、基础语法与功能
二、参数说明和代码演示
1.path_or_buf 选择文件/文件路径写入
2.sep 指定分隔符
3.na_rep 指定缺少数据表示
4.float_format 指定浮点型字符串输出格式
5. columns 指定要写入的列
6.header 是否需要写入列名
7.index 是否写入行名称(索引)。
8.index_label 是否写入列标签(索引)。
9.mode 指定写入的模式
10.encoding 表示输出文件中使用的编码的字符串
11.compression 输出数据的动态压缩
12.quoting 设置引用格式
13.quotechar 引用字符
14.lineterminator 输出文件中使用的换行符或字符序列
15.chunksize 指定一次写入的行
16.date_format 指定日期时间对象的格式字符串
17.doublequote 控制字段内quotechar的引用。
18.escapechar
19.decimal 字符识别为十进制分隔符
20.errors 指定如何处理编码和解码错误
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
Pandas常用作数据分析工具库以及利用其自带的DataFrame数据类型做一些灵活的数据转换、计算、运算等复杂操作,但都是建立在我们获取数据源的数据之后。因此作为读取数据源信息的接口函数必然拥有其强大且方便的能力,在读取不同类源或是不同类数据时都有其对应的read函数可进行先一步处理,这会减少我们相当大的一部分数据处理操作。每一个read()和to()函数,作为一名数据分析师我个人认为都应该掌握且熟悉它对应的参数,相对应的read()函数博主已有四篇文章详细解读了read_json、read_excel和read_sq、read_csv(),to()函数有两篇to_sql和to_json。
纵观整个数据源路径来看,最常用的数据存储对象:SQL、JSON、EXCEL以及这次要详解的CSV都遍及全了。 如果能够懂得该函数参数的使用可以减少大量后续处理DataFrame数据结构的代码,仅需要设置几个to_csv参数就可实现,因此本篇文章初衷为详细介绍并运用此函数来达到彻底掌握的目的。希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新,希望大家喜欢。
一、基础语法与功能
to_csv基础语法格式为:
DataFrame.to_csv(path_or_buf=None,
sep=',',
na_rep='',
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode='w',
encoding=None,
compression='infer',
quoting=None,
quotechar='"',
lineterminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal='.',
errors='strict',
storage_options=None)可以看到参数是相当多的,比起read_excel、read_json和read_sql加起来还要多。说明了使用csv文件存储数据的频率是其他记录数据文件的几倍之高,因此关于csv文件的处理参数也会有如此之多。这是好事,等到我们将csv文件转换为了DataFrame数据再处理时,就需要写很多代码去处理,提供了这么多参数可以大大加快我们处理文件的效率。
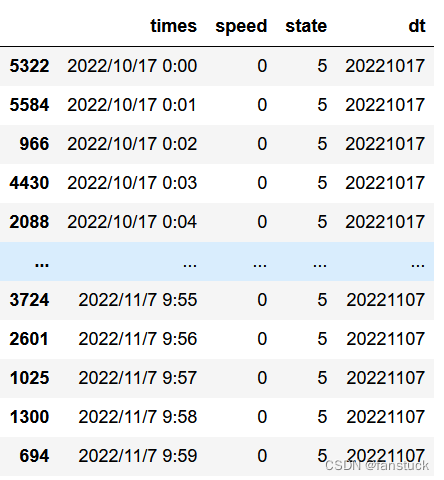
我们将要转为csv的数据dataframe为:
二、参数说明和代码演示
以下为官方文档,推荐直接点目录看:
pandas.DataFrame.to_csv — pandas 1.5.2 documentation
1.path_or_buf 选择文件/文件路径写入
接收类型:str, path object, file-like object, or None, default None
参数说明:字符串、路径对象(实现os.PathLike[str])或实现write()函数的类似文件的对象。如果无,结果将作为字符串返回。如果传递了非二进制文件对象,则应使用换行符=“”打开该对象,禁用通用换行符。如果传递了二进制文件对象,则模式可能需要包含“b”。
2.sep 指定分隔符
接收类型:str, default ‘,’
参数说明:长度为1的字符串。输出文件的字段分隔符。
test_df.to_csv('./test_df.csv',sep=';')
3.na_rep 指定缺少数据表示
接收类型:str, default ‘’
参数说明:缺少数据表示。可以理解为填充空值,使用fillnan也可以。
4.float_format 指定浮点型字符串输出格式
接收类型:str, Callable, default None
参数说明:设置浮点数的字符串格式。如果给定Callable,则它优先于其他数字格式参数,如十进制。
test_df.to_csv('./test_df.csv',sep=';',float_format='%.0f') 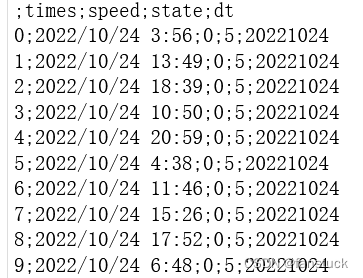
5. columns 指定要写入的列
接收类型:sequence, optional
参数说明:指定要写入的列
test_df.to_csv('./test_df.csv',sep=';',float_format='%.0f',columns=['speed','dt']) 
6.header 是否需要写入列名
接收类型:bool or list of str, default True
参数说明:写出列名。如果给定了字符串列表,则假定为列名的别名。如果需要追加写入的话该选项要设置为False。
test_df.to_csv('./test_df.csv',sep=';',float_format='%.0f',columns=['speed','dt'],header=False) 
7.index 是否写入行名称(索引)。
接收类型:bool, default True
参数说明:写入行名称(索引)。如果需要追加写入的话该选项要设置为False。

8.index_label 是否写入列标签(索引)。
接收类型:str or sequence, or False, default None
参数说明:索引列的列标签(如果需要)。如果给定None,并且头和索引为True,则使用索引名称。如果对象使用MultiIndex,则应给出序列。如果为False,则不打印索引名称的字段。使用index_label=False可以更容易地在R中导入。
test_df.to_csv('./test_df.csv',sep=';',float_format='%.0f',header=True,index_label=False) 
9.mode 指定写入的模式
接收类型:str, default ‘w’
参数说明:Python编写模式。可用的写入模式与open()是一样的。
| 只读模式r | 文件不存在报错 |
|---|---|
| r(rt) | 只读方式打开文本文件,光标位于文件开头(默认模式) |
| rb | 读取二进制格式文件,光标位于文件开头 |
| r+ | 读写文件,光标位于文件开头 |
| rb+ | 读写二进制文件,光标位于文件开头 |
| 写入模式 w | 文件存在则覆盖,否则创建新文件 |
|---|---|
| w(wt) | 写入文本文件 |
| wb | 写入二进制文件 |
| w+ | 写入和读取文件 |
| wb+ | 写入和读取二进制文件 |
| 追加写入模式 a | 文件存在则末尾追加,否则创建新文件 |
|---|---|
| a(at) | 追加写入文本文件 |
| ab | 追加写入二进制文件 |
| a+ | 追加写入和读取文件 |
| ab+ | 追加写入和读取二进制文件 |
10.encoding 表示输出文件中使用的编码的字符串
接收类型:str, optional
参数说明:表示输出文件中使用的编码的字符串,默认为“utf-8”。如果path_or_buf是非二进制文件对象,则不支持编码。
11.compression 输出数据的动态压缩
接收类型:str or dict, default ‘infer’
参数说明:用于输出数据的动态压缩。如果“infect”和“path_or_buf”是类似路径的,则从以下扩展名检测压缩:“.gz”、“.bz2”、“.zip”、“.xz”、”.zst“、”.tar“、”.tar.gz“、”.star.xz“或”.tar.bz2“(否则不压缩)。设置为“无”表示无压缩。也可以是关键字“method”设置为{“zip”、“gzip”、“bz2”、“zstd”、“tar”}之一的dict,其他键值对分别转发到zipfile.zipfile、gzip.GzipFile、bz2.BZ2File、zstandard.ZstdCompressor或tarfile.tarfile。例如,为了更快地压缩并创建可复制的gzip存档,可以传递以下命令:compress={‘method‘:‘gzip‘,‘compresslevel‘:1,‘mtime‘:1}。
12.quoting 设置引用格式
接收类型:optional constant from csv module
参数说明:默认值为csv.QUOTE_MINIMAL。如果设置了float_format,则float将转换为字符串,因此csv.QUITE_NONNUMERIC将它们视为非数字。
13.quotechar 引用字符
接收类型:str, default ‘"’
参数说明:长度为1的字符串。用于引用字段的字符。
14.lineterminator 输出文件中使用的换行符或字符序列
接收类型:str, optional
参数说明:要在输出文件中使用的换行符或字符序列。默认为os.lineep,这取决于调用此方法的操作系统(“\n”表示linux,“\r\n”表示Windows,即)。
15.chunksize 指定一次写入的行
接收类型:int or None
参数说明:一次写入的行。
16.date_format 指定日期时间对象的格式字符串
接收类型:str, default None
参数说明:日期时间对象的格式字符串。
test_df.to_csv('./test_df.csv',sep=';',date_format='yyyy/mm/dd') 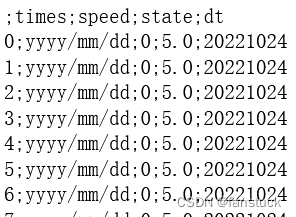
17.doublequote 控制字段内quotechar的引用。
接收类型:bool, default True
参数说明:控制字段内quotechar的引用。
18.escapechar
接收类型:str, default None
参数说明:长度为1的字符串。适当时用于转义sep和quotechar的字符。
19.decimal 字符识别为十进制分隔符
接收类型:str, default ‘.’
参数说明:字符被识别为十进制分隔符。E、 g.欧洲数据使用“,”。
20.errors 指定如何处理编码和解码错误
接收类型:str, default ‘strict’
参数说明:指定如何处理编码和解码错误。有关选项的完整列表,可参阅open()的errors参数。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见