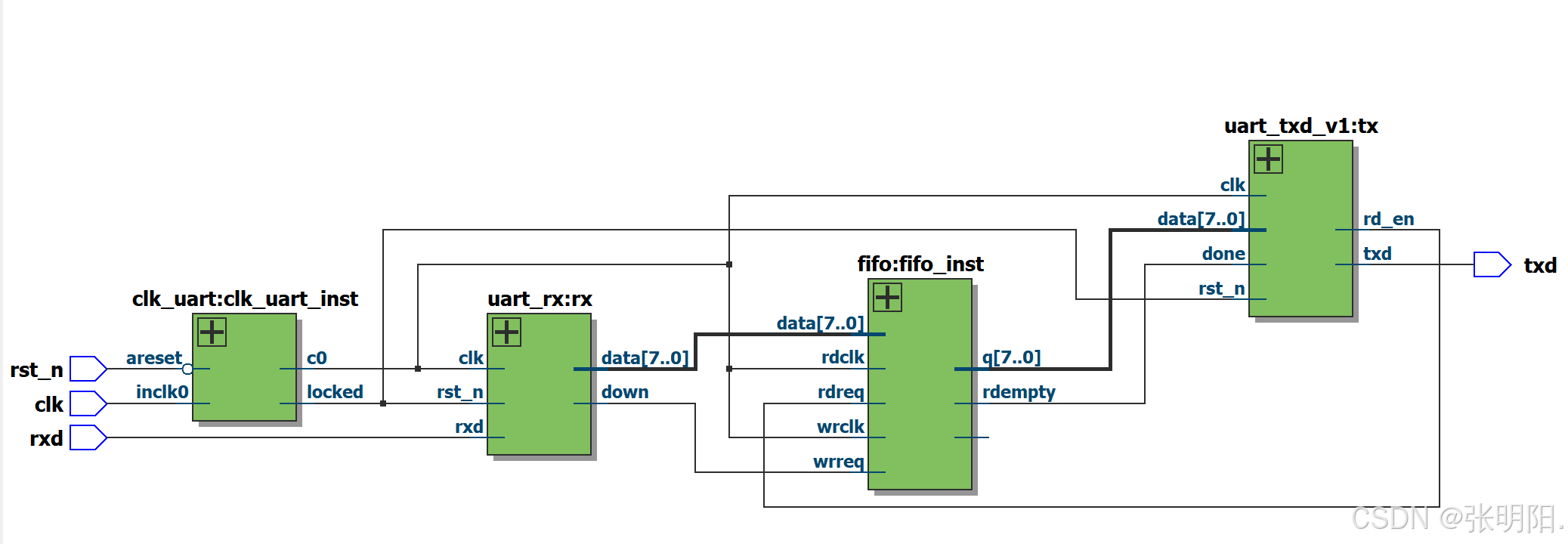
MaskNet 是微博团队 2021 年提出的 CTR 预测模型,相关论文:《MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask》。MaskNet 通过掩码自注意力机制,在推荐系统中实现了高效且鲁棒的特征交互学习,特别适用于需处理长序列及噪声数据的场景。其动态过滤与多层次交互的思想,为推荐模型设计提供了新方向。MaskNet 在 Twitter、阿里巴巴等巨头均有工业级应用实践。本文基于 MaskNet 实现一个CTR模型。
1.MaskNet 简介
1.1 核心思想
推荐系统的关键在于从用户行为(如点击、购买序列)和上下文特征中挖掘有效的特征交互。传统方法(如FM、DeepFM)依赖浅层交互或全连接网络,可能无法充分捕捉复杂的高阶模式,且容易受噪声干扰。MaskNet 的创新点在于:
- 动态特征过滤:通过掩码机制(如门控结构)区分重要与噪声交互,增强模型鲁棒性。
- 高效交互学习:利用自注意力并行计算优势,避免类似 CrossNetwork 的阶数限制。
- 多层次特征融合:堆叠多个掩码自注意力块,提取不同抽象层次的特征表示。
1.2 模型结构
MaskNet 主要包含以下模块:
a. 输入与嵌入层
输入包括用户行为序列、物品属性、上下文特征等,通过嵌入层转换为稠密向量。
b. 掩码自注意力块(Masked Self-Attention Block)
- 自注意力机制:计算特征间的注意力权重,捕捉全局依赖关系。
- 动态掩码:引入可学习的门控单元(如Sigmoid),生成0-1的掩码值,抑制不重要交互
c.前馈网络(FFN)
每个注意力块后接 FFN,增强非线性表达能力。
d. 特征聚合与预测
对不同层的输出进行拼接或加权求和,最后通过 MLP 输出预测分数(如点击率)。
1.3. 关键优势
- 抗噪声能力:掩码机制自动过滤低效交互,提升模型鲁棒性。
- 灵活的高阶交互:通过堆叠模块捕捉任意阶数特征组合,优于 DCN 等固定阶数模型。
- 计算高效:自注意力复杂度为 (O(n^2)),适用于中等长度序列,优于RNN的 (O(n^3))。
1.4 同类比较
MaskNet 在 Criteo、Avazu 等公开点击率预测数据集上表现优异,AUC提升显著。特别适用于用户行为序列较长的推荐场景(如电商、短视频推荐)。以下是 MaskNet 与几种典型方案的比较。

2.基于 MaskNet 的 CTR 模型实现
2.1 模拟数据生成
# ====================
# 1. 模拟数据生成
# ====================
def generate_mock_data(num_users=100, num_items=200, num_interactions=1000):
"""生成模拟用户、商品及交互数据"""
# 设置随机种子保证可复现性
np.random.seed(42)
tf.random.set_seed(42)
# 用户特征
user_data = {
'user_id': np.arange(1, num_users + 1),
'user_age': np.random.randint(18, 65, size=num_users),
'user_gender': np.random.choice(['male', 'female'], size=num_users),
'user_occupation': np.random.choice(['student', 'worker', 'teacher'], size=num_users),
'city_code': np.random.randint(1, 2856, size=num_users),
'device_type': np.random.randint(0, 5, size=num_users)
}
# 商品特征
item_data = {
'item_id': np.arange(1, num_items + 1),
'item_category': np.random.choice(['electronics', 'books', 'clothing'], size=num_items),
'item_brand': np.random.choice(['brandA', 'brandB', 'brandC'], size=num_items),
'item_price': np.random.randint(1, 199, size=num_items)
}
# 交互数据
interactions = []
for _ in range(num_interactions):
user_id = np.random.randint(1, num_users + 1)
item_id = np.random.randint(1, num_items + 1)
# 点击标签。0: 未点击, 1: 点击。在真实场景中可通过客户端埋点上报获得用户的点击行为数据
click_label = np.random.randint(0, 2)
interactions.append([user_id, item_id, click_label])
return user_data, item_data, interactions
# 生成数据
num_users = 100
num_items = 200
user_data, item_data, interactions = generate_mock_data(num_users, num_items, 1000)
2.2 合并、划分数据集
# ====================
# 2. 合并、划分数据集
# ====================
# 合并用户特征、商品特征和交互数据
interaction_df = pd.DataFrame(interactions, columns=['user_id', 'item_id', 'click_label'])
user_df = pd.DataFrame(user_data)
item_df = pd.DataFrame(item_data)
df = interaction_df.merge(user_df, on='user_id').merge(item_df, on='item_id')
# 划分数据集:训练集、测试集
labels = df[['click_label']]
features = df.drop(['click_label'], axis=1)
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2,
random_state=42)
2.3 特征工程
# ====================
# 3. 特征工程
#
# 本部分对原始用户数据、商品数据、用户-商品交互数据进行分类处理,加工为模型训练需要的特征
# 1.数值型特征:如用户年龄、价格,少数场景下可直接使用,但最好进行标准化,从而消除量纲差异
# 2.类别型特征:需要进行 Embedding 处理
# 3.交叉特征:由于维度高,需要哈希技巧处理高维组合特征
# ====================
"""
用户特征处理
"""
user_id = feature_column.categorical_column_with_identity('user_id', num_buckets=num_users + 1)
user_id_emb = feature_column.embedding_column(user_id, dimension=8)
scaler_age = StandardScaler()
df['user_age'] = scaler_age.fit_transform(df[['user_age']])
user_age = feature_column.numeric_column('user_age')
user_gender = feature_column.categorical_column_with_vocabulary_list('user_gender', ['male', 'female'])
user_gender_emb = feature_column.embedding_column(user_gender, dimension=2)
user_occupation = feature_column.categorical_column_with_vocabulary_list('user_occupation',
['student', 'worker', 'teacher'])
user_occupation_emb = feature_column.embedding_column(user_occupation, dimension=2)
city_code_column = feature_column.categorical_column_with_identity(key='city_code', num_buckets=2856)
city_code_emb = feature_column.embedding_column(city_code_column, dimension=8)
device_types_column = feature_column.categorical_column_with_identity(key='device_type', num_buckets=5)
device_types_emb = feature_column.embedding_column(device_types_column, dimension=8)
"""
商品特征处理
"""
item_id = feature_column.categorical_column_with_identity('item_id', num_buckets=num_items + 1)
item_id_emb = feature_column.embedding_column(item_id, dimension=8)
scaler_price = StandardScaler()
df['item_price'] = scaler_price.fit_transform(df[[