源码:
GitHub - 18713341733/mysqlsync
一、使用场景
一个项目,有多套开发环境。有一套标准的数据库,不同的开发环境,有各自的一套数据库。
标准数据库的表结构经常发生变化,不同的开发环境中的数据库,需要与标准数据库的表结构保持一致。当标准数据库表结构发生变化时,其他开发环境的数据库需要进行表结构的同步,与标准数据库保持一致。
二、MySQL 索引
MySQL 索引:
是一个单独的、存储在 磁盘 上的 数据库结构 ,包含着对数据表里 所有记录的 引用指针。
MySQL中索引的存储类型有两种:
即 BTree 和 Hash。
索引是在存储引擎中实现的:
(MySQL 的存储引擎有:InnoDB、MyISAM、Memory、Heap)
- InnoDB / MyISAM 只支持 BTree 索引
- Memory / Heap 都支持 BTree 和 Hash 索引
2.1 MYSQL 索引 的分类
1、普通索引 和 唯一索引
普通索引:MySQL 中的基本索引类型,允许在定义索引的列中插入 重复值 和 空值
唯一索引:要求索引列的值必须 唯一,但允许 有空值
如果是组合索引,则列值的组合必须 唯一
主键索引是一种特殊的唯一索引,不允许 有空值
2、单列索引 和 组合索引
单列索引:一个索引只包含单个列,一个表可以有多个单列索引
组合索引:在表的 多个字段 组合上 创建的 索引
只有在查询条件中使用了这些字段的 左边字段 时,索引才会被使用(最左前缀原则)
3、全文索引
全文索引 的类型为 fulltext
在定义索引的 列上 支持值的全文查找,允许在这些索引列中插入 重复值 和 空值
全文索引 可以在 char、varchar 和 text 类型的 列 上创建
4、空间索引
空间索引 是对 空间数据类型 的字段 建立的索引
MySQL中的空间数据类型有4种,分别是 Geometry、Point、Linestring 和 Polygon
MySQL 使用 Spatial 关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引
创建空间索引的列,不允许为空值,且只能在 MyISAM 的表中创建。
5、前缀索引
在 char、varchar 和 text 类型的 列 上创建索引时,可以指定索引 列的长度
三、information_schema库
information_schema库 :
用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等。
1、当我们对比,2个数据库是否一样时,我们只需要对比这两个数据库名称是否一致就可以了。
2、当我们对比,2个表是否一致时,我们需要去
1、表里,所有的字段属性
2、表里,索引。
我们通过这两个条件,来判断表与表是否一致,具体哪里不一致。
表information_schema.COlUMNS 记录了,某个表中,所有字段的属性。
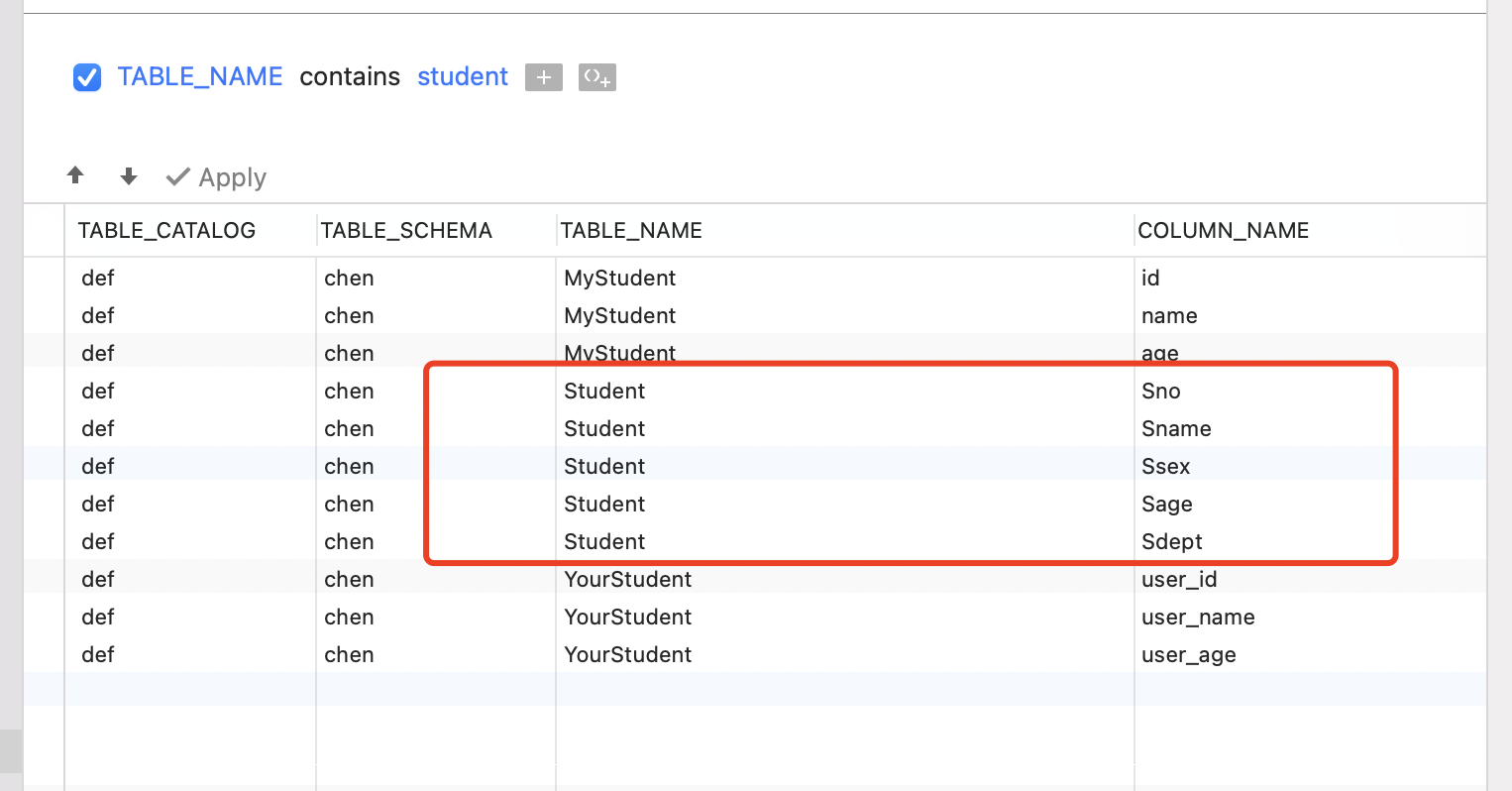
我们在information_schema.COlUMNS,中查看表Student中,所有字段的属性。
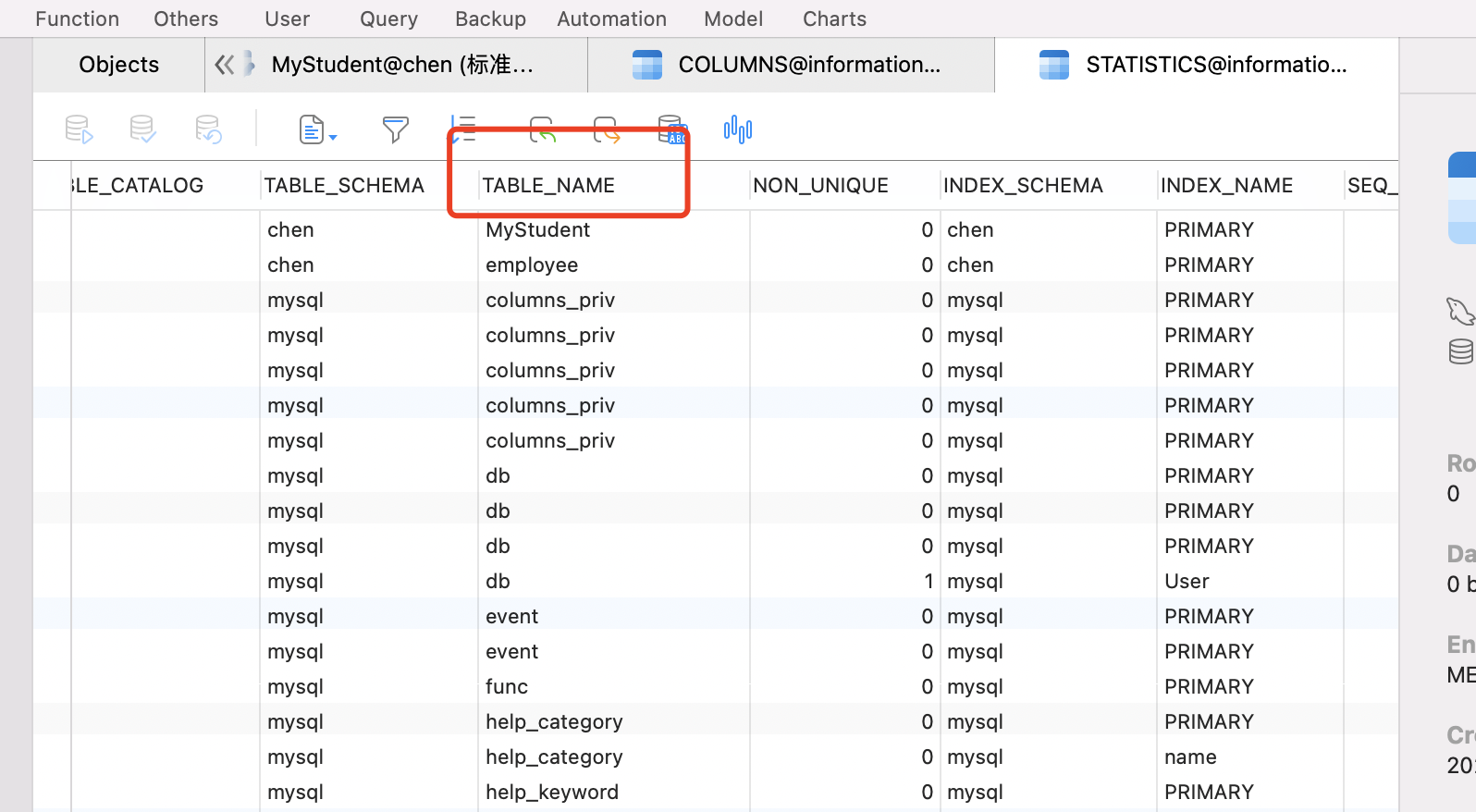
在information_schema.statistics 表中,可以查看某个表下所有的索引。
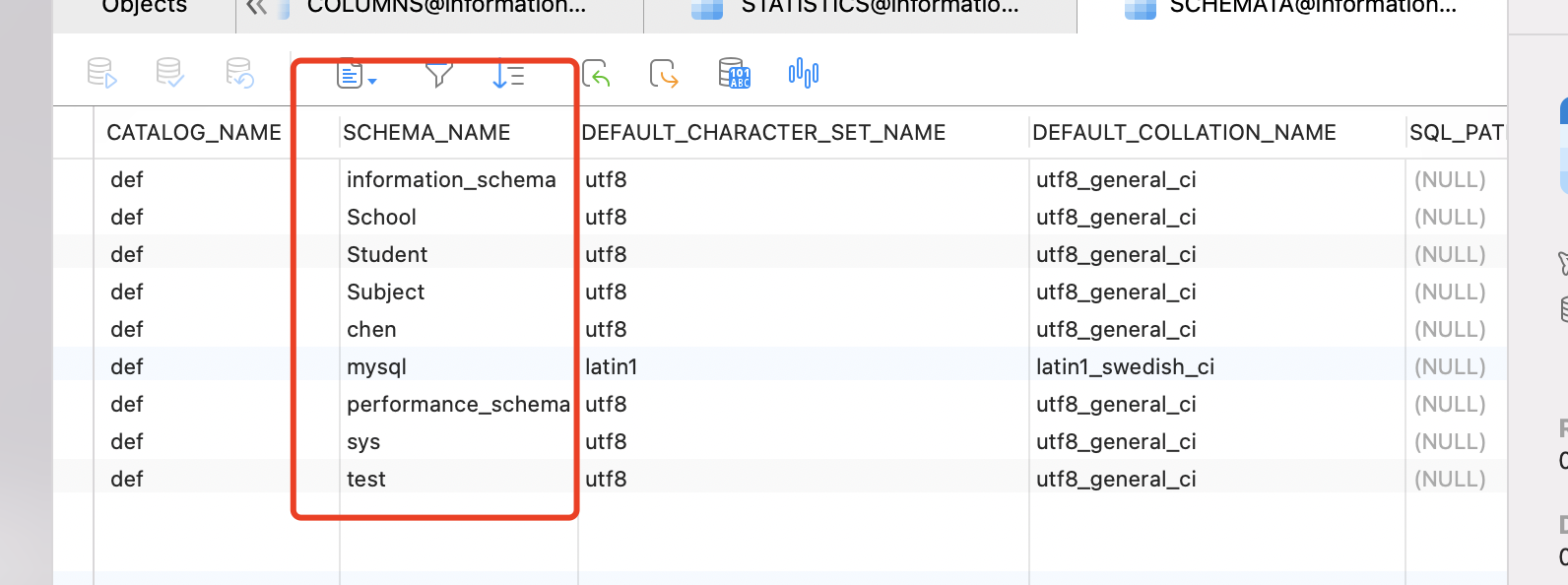
在information_schema.SCHEMATA表中,可以查看这个实例下,都存在哪些数据库。
select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME from information_schema.SCHEMATA这个命令,就是查看我们实例下,所有的数据库。其实就是相当于
show databases; 在information_schema.tables表中,可以查看某个数据库下,都存在哪些表。
select TABLE_SCHEMA,TABLE_NAME,ENGINE from information_schema.tables where schema_name = #{dbName}其实就相当于命令:
use chen;
show tables;四、整体思路
如数据库A为标准数据库。数据库B为我们本地的数据库。当数据库A表结构发生变化时,数据库B的表结构需要与A保持一致。
4.1 同步规则
我们拿本地的库与标准库做比较,
1、同步库:
1.1 将标准库中存在的库,但是本地不存在的库,同步到本地
1.2 标准库与本地库,都存在的库,只需要同步库里的表就可以了
1.3 在标准库中不存在的库,但是本地有的库,这种情况我们不进行考虑
2、同步表:
2.1 将标准库中存在的表,但是本地不存在的库,同步到本地
2.2 将标准库与本地库同时存在的表,但是表的结构不一样,将标准库的表结构同步到本地
2.3 同一个表中,本地表比标准表多余的字段,我们不考虑。
4.2 同步库
举例:
标准数据库A
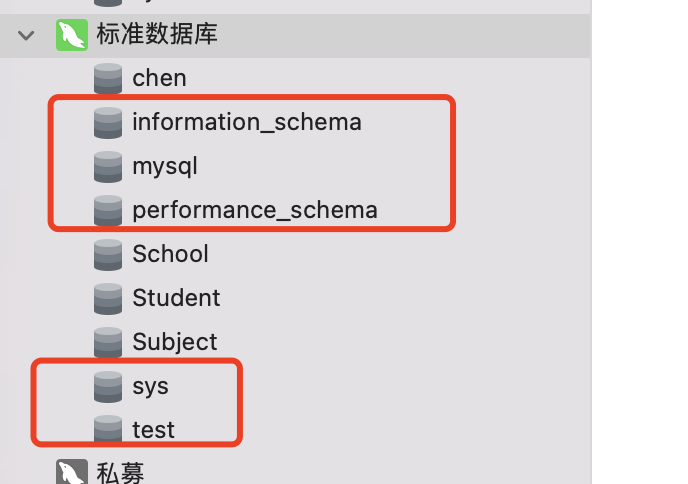
这个数据库实例下,一共有9个库。其中有5个库:
"information_schema","performance_schema","sys","mysql","test"
属于系统自带的库,我们进行同步时,不需要进行同步。我们只同步除了这5个系统之外的所有库。
数据库的属性:
1、只有数据库的名称。
所以,在对比标准库与本地库时,只需要比较数据库的名称就可以了。
标准库中有的库名,本地库没有该库名,我们在本地新增该数据库。
标准库与本地库,同时存在的库名,我们需要去校验同步库里面的表。
4.3 同步表
1 将标准库中存在的表,但是本地不存在的库,同步到本地
2 将标准库与本地库同时存在的表,但是表的结构不一样,将标准库的表结构同步到本地
3 同一个表中,本地表比标准表多余的字段,我们不考虑。
判断表与表是否一致时,我们需要比较2个条件。
1、表里,所有的字段属性
2、表里,索引。
我们通过这两个条件,来判断表与表是否一致,具体哪里不一致。
4.3.1 字段的属性:
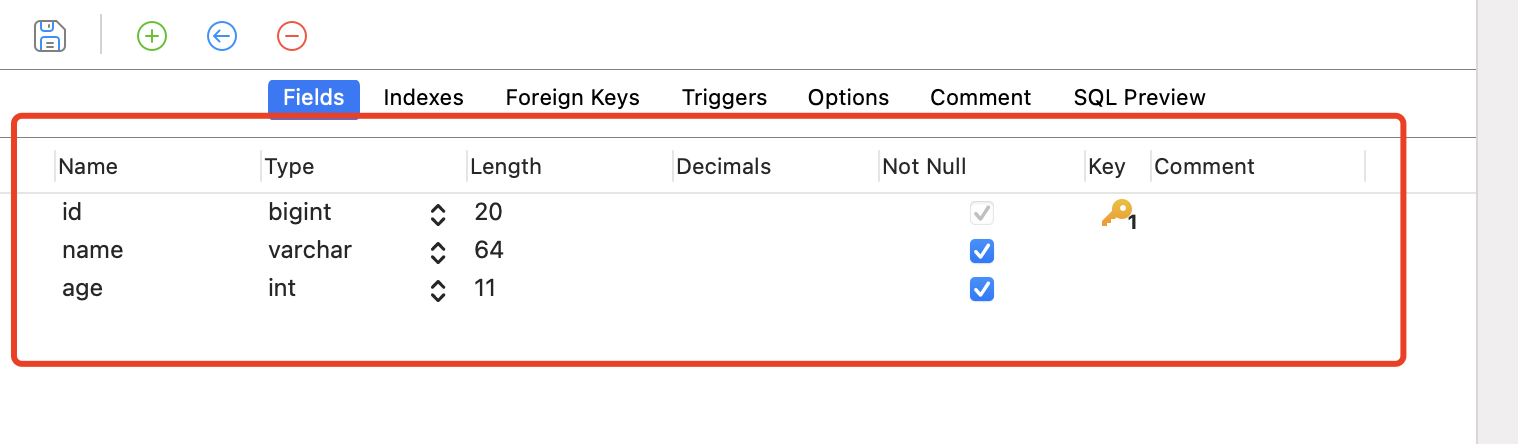
查看表information_schema.COlUMNS
每个列,对应一条数据。
每个列数据,我们需要取哪些属性值?
private String tableSchema;
private String tableName;
private String columnName;
private String columnType;
private String columnComment;
private String dataType;
private String columnDefault;
private String isNullable;4.3.2 mysql索引
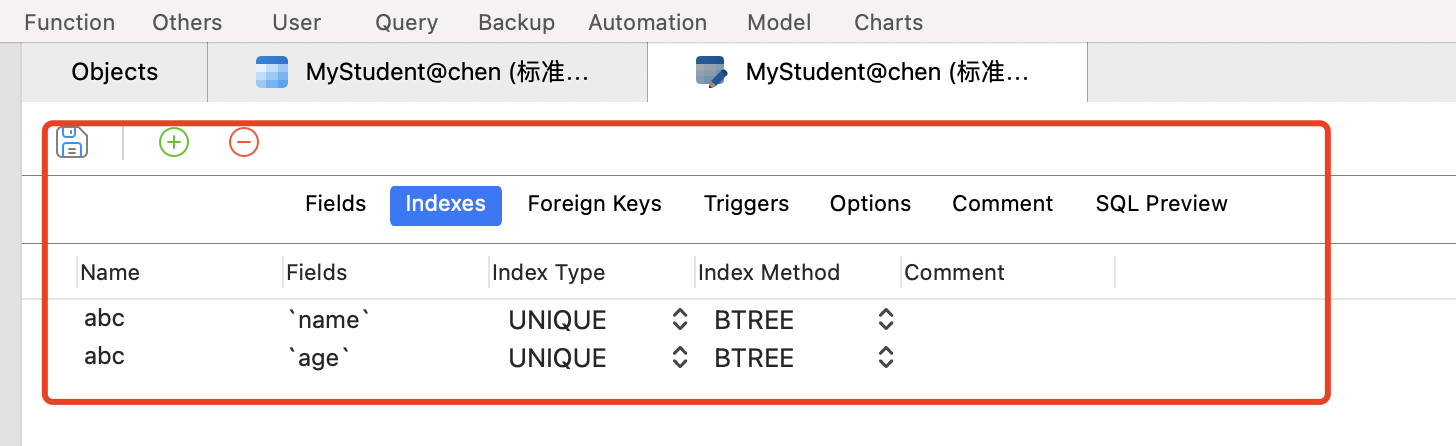
在information_schema.statistics 表中,可以查看某个表下所有的索引。
一个索引,就是一条数据。一个索引,都有哪些属性值呢?
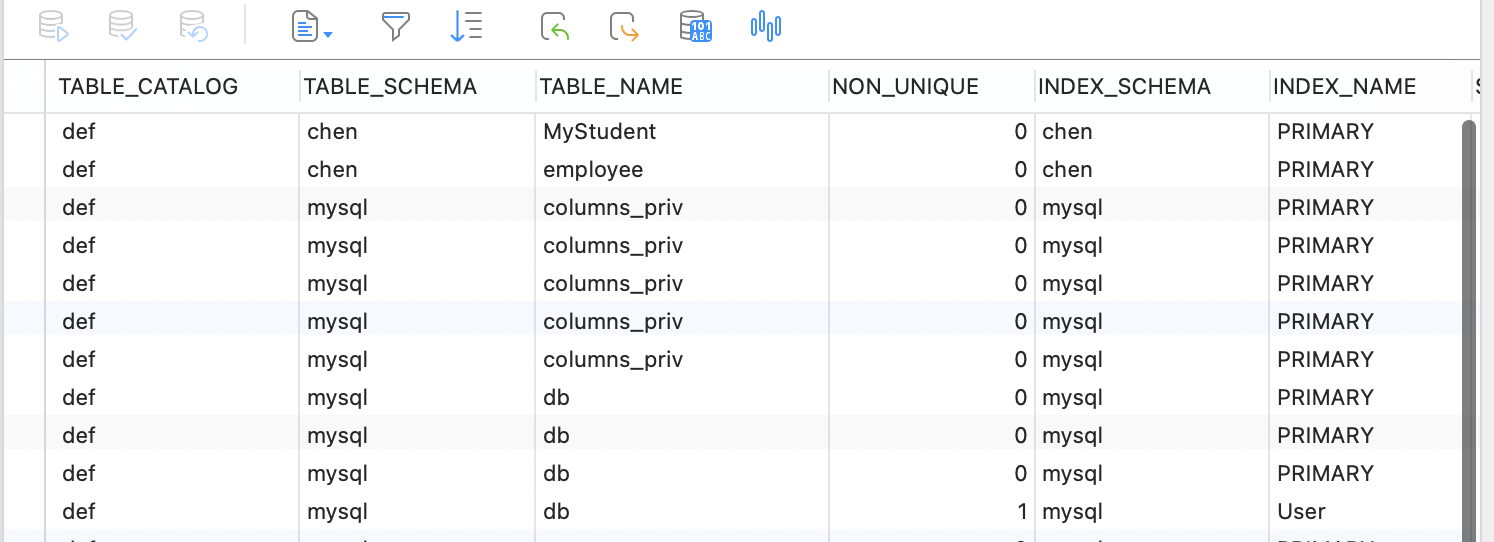
private String tableSchema;
private String tableName;
private String indexName;
private int seqInIndex;
private String columnName;
private int nonUnique;
private String indexType;
注意:
索引不能进行修改,只能先删除,后增加。
4.4 整体思路
1、我们拿本地的库与标准库做比较
2、先同步库
2.1 找到库与库的区别,生成对应的sql
2.2 去执行同步sql
3、再同步表
3.1 找到表与表的区别,生成对应的sql
3.2 去执行同步sql
4.5 最终效果
我们使用spring boot最终提供三个接口。
/instance 接口,同步两个实例。
/db 接口,只同步相应的数据库
/table 接口,只同步指定的表
五、 技术点
1、区分表与表,哪里不一致。哪些字段是新增的,哪些字段是修改的。
对索引的判断,哪些索引是新增的。这里技术难度不大,但是琐碎。
2、对于数据库的连接,我们使用的是mybatis。不同的是,以往spring boot 应用mybatis
在项目配置文件application.yml中,配置数据库的连接信息。
但是我们本次数据库连接信息需要用户传入,就不能使用application.yml配置。
六、项目代码、 项目整体结构
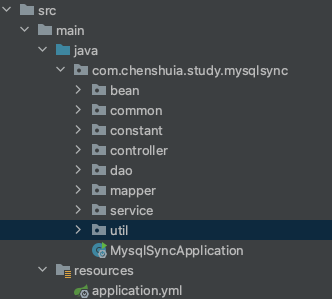
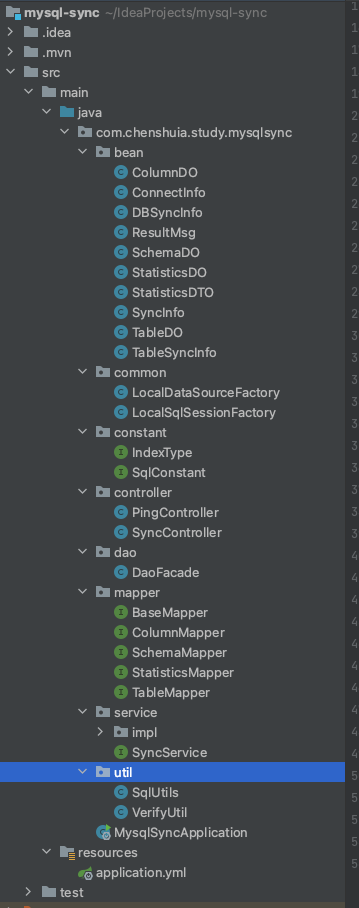
七、 pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.chenshuia.study</groupId>
<artifactId>mysql-sync</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>mysql-sync</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
八、 controller层
对外提供的三个同步接口。
/instance 接口,同步两个实例。
/db 接口,只同步相应的数据库
/table 接口,只同步指定的表
package com.chenshuia.study.mysqlsync.controller;
import com.chenshuia.study.mysqlsync.bean.DBSyncInfo;
import com.chenshuia.study.mysqlsync.bean.ResultMsg;
import com.chenshuia.study.mysqlsync.bean.SyncInfo;
import com.chenshuia.study.mysqlsync.bean.TableSyncInfo;
import com.chenshuia.study.mysqlsync.service.SyncService;
import org.apache.logging.log4j.util.Strings;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import java.util.Objects;
@RequestMapping("/sync")
@RestController
public class SyncController {
@Autowired
private SyncService syncService;
// 同步实例
@RequestMapping(value = "/instance",method = RequestMethod.POST)
public ResultMsg sync(@RequestBody SyncInfo syncInfo){
// 参数校验
try {
syncInfo.verify();
syncService.syncInstance(syncInfo);
return ResultMsg.success();
} catch (Exception e){
e.printStackTrace();
return ResultMsg.fail(ResultMsg.FAILED_CODE,e.getMessage());
}
}
// 同步库
@RequestMapping(value = "/db",method = RequestMethod.POST)
public ResultMsg sync(@RequestBody DBSyncInfo dbSyncInfo){
try {
dbSyncInfo.verify();
syncService.syncDB(dbSyncInfo);
return ResultMsg.success();
} catch (Exception e){
e.printStackTrace();
return ResultMsg.fail(ResultMsg.FAILED_CODE,e.getMessage());
}
}
// 同步表
@RequestMapping(value = "/table",method = RequestMethod.POST)
public ResultMsg sync(@RequestBody TableSyncInfo tableSyncInfo){
try {
// 校验参数
tableSyncInfo.verify();
// 调用业务,处理数据
syncService.syncTable(tableSyncInfo);
return ResultMsg.success();
} catch (Exception e){
e.printStackTrace();
return ResultMsg.fail(ResultMsg.FAILED_CODE,e.getMessage());
}
}
}
1、三个接口,都是post方法
2、具体的同步方法,都在
@Autowired
private SyncService syncService;通过spring注入
3、同步实例时,需要传入所有的信息。本地库与标准库的连接信息。
同步库,需要传入2个库的连接信息,与数据库的名称。
同步表,需要传入2个库的连接信息,与数据库的名称、表的名称。
4、我们在同步数据库之前,先对用户传参进行了一个校验。
九、 bean层
bean层存放了整个项目,需要的所有实例。
9.1 返回结果的实例ResultMsg<T>
定义了一个返回结果的实例,用到了泛型。(没有什么逻辑)
package com.chenshuia.study.mysqlsync.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import org.omg.CORBA.PUBLIC_MEMBER;
@Data
@AllArgsConstructor
public class ResultMsg<T> {
private String code;
private String msg;
private T data;
public static final String SUCCESS_CODE = "200";
public static final String FAILED_CODE = "999";
public static final String SUCCESS_MSG = "success";
public static final String FAILED_MSG = "failed";
public ResultMsg(String code, String msg) {
this.code = code;
this.msg = msg;
}
public static <T> ResultMsg<T> success(T t){
return new ResultMsg<>(SUCCESS_CODE,SUCCESS_MSG,t);
}
public static ResultMsg success(){
return new ResultMsg<>(SUCCESS_CODE,SUCCESS_MSG);
}
public static ResultMsg fail(){
return new ResultMsg<>(FAILED_CODE,FAILED_MSG);
}
public static ResultMsg fail(String code,String msg){
return new ResultMsg<>(code,msg);
}
}
9.2 数据库连接信息(用户传入信息)
一共有4个实体类。ConnectInfo、SyncInfo 、DBSyncInfo 、TableSyncInfo
ConnectInfo
package com.chenshuia.study.mysqlsync.bean;
import com.chenshuia.study.mysqlsync.util.VerifyUtil;
import com.mysql.cj.jdbc.Driver;
import lombok.Data;
@Data
public class ConnectInfo {
/*
数据库链接信息
*/
private String driver = Driver.class.getName();
private String url ;
private String userName ;
private String password ;
public void verify(){
VerifyUtil.verifyString(url,userName,password,driver);
}
}
SyncInfo
package com.chenshuia.study.mysqlsync.bean;
import lombok.Data;
import java.util.Objects;
@Data
public class SyncInfo {
/*
进行同步的信息。2个数据库的链接方式,同步的库和表
*/
private ConnectInfo src;
private ConnectInfo dst;
public void verify(){
// 判断属性src与dst 是否为空
Objects.requireNonNull(src);
Objects.requireNonNull(dst);
// 判断对象src的属性是否为空
src.verify();
dst.verify();
}
}
DBSyncInfo
package com.chenshuia.study.mysqlsync.bean;
import com.chenshuia.study.mysqlsync.util.VerifyUtil;
import lombok.Data;
@Data
public class DBSyncInfo extends SyncInfo{
private String dbName;
@Override
public void verify() {
super.verify();
VerifyUtil.verifyString(dbName,"dbName is not null");
}
}
TableSyncInfo
package com.chenshuia.study.mysqlsync.bean;
import com.chenshuia.study.mysqlsync.util.VerifyUtil;
import lombok.Data;
@Data
public class TableSyncInfo extends DBSyncInfo{
private String tableName;
@Override
public void verify() {
super.verify();
VerifyUtil.verifyString(tableName,"tableName is not null");
}
}
设计思路:
1、数据库的连接信息,实体类ConnectInfo,包含数据库的url、账号密码等。
里面还有对这些字段为空的校验。
2、TableSyncInfo 继承了DBSyncInfo,DBSyncInfo 继承了SyncInfo

因为我们在同步表结构的时候,会遇到三种情况。1同步整个实例,2同步某个库,3只同步某个表。所以把用户传入的实体类也对应做了3个类。
SyncInfo 存放的是两个数据库的连接实例。
DBSyncInfo 只存放了数据库的名字。但是DBSyncInfo继承了SyncInfo,所以也包含了两个数据库的连接实例。
TableSyncInfo 只存放了表的名字。但是TableSyncInfo 继承了DBSyncInfo,所以也包含了两个数据库的连接实例及数据库的名字。
3、为啥要使用继承?
a、为了少写点代码。(类的属性)
b、我们在类中,封装了对应的字段校验方法。这样以后校验输入字段的时候,调用父类的也会方便一些。
9.3 对应表的实体类
9.3.1 表字段的属性
information_schema.COlUMNS 对应的实体类ColumnDO。(表中字段的属性)
package com.chenshuia.study.mysqlsync.bean;
import lombok.Data;
import lombok.EqualsAndHashCode;
@Data
@EqualsAndHashCode(exclude = {"isAdd"})
public class ColumnDO {
private String tableSchema;
private String tableName;
private String columnName;
private String columnType;
private String columnComment;
private String dataType;
private String columnDefault;
private String isNullable;
// 自己添加的属性,这个列是否为新增(还是修改)
private boolean isAdd;
/**
* 注意,isAdd 这个属性是我们自己添加的,不是列自带的属性
* 所以我们判断两个列的实体类时,不应该用isAdd去判断相等
* 判断相等,用的是equals和hashcode。所以生成hashcode时,应该去除isAdd这个属性
*/
}
表COlUMNS 中,存放的就是 表的每个字段的属性。
在这个实体类中,我们还单独加了一个 private boolean isAdd; 属性。
注意,isAdd 这个属性是我们自己添加的,不是列自带的属性。
所以我们判断两个列的实体类时,不应该用isAdd去判断相等
判断相等,用的是equals和hashcode。所以生成hashcode时,应该去除isAdd这个属性。
为啥要加isAdd属性?
是用来标记表中某个字段,是新增的还是修改的。我们对应的同步处理方式 也是不同的。
9.3.2 表中的索引 StatisticsDO
在同步两个表时,不仅仅需要同步表中变更的字段,还需要同步这个表的索引。
在information_schema.statistics 表中,可以查看某个表下所有的索引。
对应的实体类 StatisticsDO
package com.chenshuia.study.mysqlsync.bean;
import lombok.Data;
// 索引的实体类
@Data
public class StatisticsDO {
private String tableSchema;
private String tableName;
private String indexName;
private int seqInIndex;
private String columnName;
private int nonUnique;
private String indexType;
}
索引的DTO StatisticsDTO
package com.chenshuia.study.mysqlsync.bean;
import lombok.Builder;
import lombok.Data;
import java.util.List;
// 索引的实体类
@Data
@Builder
public class StatisticsDTO {
private String tableSchema;
private String tableName;
private String indexName;
private List<String> columns;
private int nonUnique;
private String indexType;
}
为啥这里需要 StatisticsDTO,因为当存在联合索引时,同一个索引名称INDEX_NAME,会在information_schema.statistics 表中 存在两条数据,这两条数据的INDEX_NAME名称一致,但是对应的COLUMN_NAME 是表中不同的字段。如果存在联合索引的话,我们用这两个实体类做diff时,不太方便。
同一个INDEX_NAME 索引下,对应的COLUMN_NAME 是否相同,以及索引的顺序会影响我们判断两个索引是否相等,所以我们将名字一致的索引,放到了一个List中,这样整体去做diff。
9.3.4 表
在information_schema.tables表中,可以查看某个数据库下,都存在哪些表。
对应的表的实体类TableDO
package com.chenshuia.study.mysqlsync.bean;
import lombok.Data;
@Data
public class TableDO {
private String tableSchema;
private String tableName;
// engine 引擎
private String engine;
}
9.4 对应库的实体类
在information_schema.SCHEMATA表中,可以查看这个实例下,都存在哪些数据库。
对应的实体类 SchemaDO
package com.chenshuia.study.mysqlsync.bean;
import lombok.Data;
@Data
public class SchemaDO {
// 数据库名
private String schemaName;
// 默认字符集
private String defaultCharacterSetName;
}
我们需要的属性还是比较少的,只有数据库名字和默认字符集。其实我们需要的主要就是数据库的名称。
十、application.yml
我们只配置了服务的端口号。
server:
port: 8080十一、service层
具体的同步逻辑,都在这里
SyncService
package com.chenshuia.study.mysqlsync.service;
import com.chenshuia.study.mysqlsync.bean.DBSyncInfo;
import com.chenshuia.study.mysqlsync.bean.SyncInfo;
import com.chenshuia.study.mysqlsync.bean.TableSyncInfo;
public interface SyncService {
// 同步实例
void syncInstance(SyncInfo syncInfo);
// 同步库
void syncDB(DBSyncInfo dbSyncInfo);
// 同步表
void syncTable(TableSyncInfo tableSyncInfo);
}
SyncServiceImpl
package com.chenshuia.study.mysqlsync.service.impl;
import com.chenshuia.study.mysqlsync.bean.*;
import com.chenshuia.study.mysqlsync.common.LocalSqlSessionFactory;
import com.chenshuia.study.mysqlsync.constant.IndexType;
import com.chenshuia.study.mysqlsync.constant.SqlConstant;
import com.chenshuia.study.mysqlsync.dao.DaoFacade;
import com.chenshuia.study.mysqlsync.mapper.ColumnMapper;
import com.chenshuia.study.mysqlsync.mapper.SchemaMapper;
import com.chenshuia.study.mysqlsync.mapper.StatisticsMapper;
import com.chenshuia.study.mysqlsync.mapper.TableMapper;
import com.chenshuia.study.mysqlsync.service.SyncService;
import com.chenshuia.study.mysqlsync.util.SqlUtils;
import com.google.common.base.Joiner;
import com.google.common.collect.Lists;
import com.google.common.collect.Sets;
import org.apache.ibatis.session.SqlSession;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.stream.Collectors;
@Service
public class SyncServiceImpl implements SyncService {
// 同步实例
@Override
public void syncInstance(SyncInfo syncInfo) {
ConnectInfo srcInfo = syncInfo.getSrc();
ConnectInfo dstInfo = syncInfo.getDst();
// 获取所有库
List<SchemaDO> srcDBs = DaoFacade.ofMapper(srcInfo, SchemaMapper.class, m -> m.findAll());
List<SchemaDO> dstDBs = DaoFacade.ofMapper(dstInfo, SchemaMapper.class, m -> m.findAll());
// diff (新增)
// src 有, dst没有的库,属于新增,我们需要先新建库,然后再去同步表
// src 有,dst 也有的库,我们直接去同步库里的表
// addDBs 1、先去创建没有的库
// 2、然后对所有的库srcDbs都进行同步
Set<SchemaDO> addDbs = Sets.difference(new HashSet<>(srcDBs), new HashSet<>(dstDBs)).immutableCopy();
// 新建库
addDbs.stream()
.filter(db -> !SqlConstant.MYSQL_SYS_DBS.contains(db.getSchemaName()))
.forEach(db ->{
String sql = DaoFacade.getDBSql(srcInfo,db.getSchemaName());
DaoFacade.executeSql(dstInfo,sql);
});
// 同步所有的库
srcDBs.stream()
.filter(db -> !SqlConstant.MYSQL_SYS_DBS.contains(db.getSchemaName()))
.forEach(db->{
DBSyncInfo dbSyncInfo = new DBSyncInfo();
dbSyncInfo.setSrc(srcInfo);
dbSyncInfo.setDst(dstInfo);
dbSyncInfo.setDbName(db.getSchemaName());
// 进行同步库
syncDB(dbSyncInfo);
});
}
// 同步库
@Override
public void syncDB(DBSyncInfo dbSyncInfo) {
// 库的连接信息
ConnectInfo srcInfo = dbSyncInfo.getSrc();
ConnectInfo dstInfo = dbSyncInfo.getDst();
String dbName = dbSyncInfo.getDbName();
// 同步库,就是同步这个库下所有的表
// 查询库下所有的表
List<TableDO> srcTables = DaoFacade.ofMapper(srcInfo, TableMapper.class,m-> m.findByDBName(dbName));
List<TableDO> dstTables = DaoFacade.ofMapper(srcInfo, TableMapper.class,m-> m.findByDBName(dbName));
// 新增的表(求差集)
Set<TableDO> addTables = Sets.difference(new HashSet<>(srcTables), new HashSet<>(dstTables)).immutableCopy();
createTable(srcInfo,dstInfo,addTables);
// 非新增,需要进行同步的表(求交集)
Set<TableDO> syncTables = Sets.intersection(new HashSet<>(srcTables), new HashSet<>(dstTables)).immutableCopy();
// 具体对表进行同步
syncTables.stream().forEach(tableDO -> {
TableSyncInfo tableSyncInfo = new TableSyncInfo();
tableSyncInfo.setSrc(srcInfo);
tableSyncInfo.setDst(dstInfo);
tableSyncInfo.setDbName(dbName);
tableSyncInfo.setTableName(tableDO.getTableName());
syncTable(tableSyncInfo);
});
}
// 创建新表
private void createTable(ConnectInfo srcInfo, ConnectInfo dstInfo, Set<TableDO> addTables) {
addTables.stream().forEach(tableDO -> {
String tableSql = DaoFacade.getTableSql(srcInfo, tableDO.getTableSchema(), tableDO.getTableName());
String useDBSql = "use "+ tableDO.getTableSchema();
DaoFacade.executeSql(dstInfo, Lists.newArrayList(useDBSql,tableSql));
});
}
@Override
public void syncTable(TableSyncInfo tableSyncInfo) {
// 数据库链接信息
ConnectInfo srcInfo = tableSyncInfo.getSrc();
ConnectInfo dstInfo = tableSyncInfo.getDst();
// 数据库名称
String dbName = tableSyncInfo.getDbName();
// 表的名称
String tableName = tableSyncInfo.getTableName();
// 同步列
syncColumn(srcInfo,dstInfo,dbName,tableName);
// 同步索引
syncStatistics(srcInfo,dstInfo,dbName,tableName);
}
// 同步索引
private void syncStatistics(ConnectInfo srcInfo, ConnectInfo dstInfo, String dbName, String tableName) {
// 1、获取,在src原 数据库实例下库的表的结构(字段+索引)
List<StatisticsDO> srcStatisticDos = DaoFacade.ofMapper(srcInfo, StatisticsMapper.class, m -> m.findByTable(dbName, tableName));
// 2、获取,在dst目标 数据库实例下库的表的结构(字段+索引)
List<StatisticsDO> dstStatisticDos = DaoFacade.ofMapper(dstInfo, StatisticsMapper.class, m -> m.findByTable(dbName, tableName));
// 3、diff 差异
Map<Boolean, List<StatisticsDTO>> diffMap = diffStatistics(srcStatisticDos, dstStatisticDos);
// 4、基于差异,生成sql
List<String> addSqls = generateAddIndex(diffMap.get(true));
// 删除的索引
List<String> modifyDropSqls = generateDropIndex(diffMap.get(false));
// 再增加
List<String> modifyCreateSqls = generateAddIndex(diffMap.get(false));
// 5、执行sql
DaoFacade.executeSql(dstInfo,addSqls);
DaoFacade.executeSql(dstInfo,modifyDropSqls);
DaoFacade.executeSql(dstInfo,modifyCreateSqls);
}
// 生成新增索引的sql
private List<String> generateAddIndex(List<StatisticsDTO> statisticsDTOS){
// "ALTER TABLE %s.%s ADD %s INDEX %s (%s)";
List<String> collect = statisticsDTOS.stream()
.map(dto -> String.format(SqlConstant.ADD_INDEX,
dto.getTableSchema(),
dto.getTableName(),
SqlUtils.indexTypeSet(dto),
dto.getIndexName().equals(IndexType.PRIMARY)?"":dto.getIndexName(),
// dto.getColumns().stream().collect(Collectors.joining(","))
Joiner.on(",").join(dto.getColumns())
))
.collect(Collectors.toList());
return collect;
}
// 删除索引
private List<String> generateDropIndex(List<StatisticsDTO> statisticsDTOS){
List<String> collect = statisticsDTOS.stream()
.map(statisticsDTO -> String.format(SqlConstant.DROP_INDEX,
statisticsDTO.getTableSchema(),
statisticsDTO.getTableName(),
statisticsDTO.getIndexName()))
.collect(Collectors.toList());
return collect;
}
// diff 索引的差异
private Map<Boolean, List<StatisticsDTO>> diffStatistics(List<StatisticsDO> srcStatisticDos, List<StatisticsDO> dstStatisticDos){
// 将do 转成dto
List<StatisticsDTO> srcDtos = fromStatisticsDOToDTO(srcStatisticDos);
List<StatisticsDTO> dstDtos = fromStatisticsDOToDTO(dstStatisticDos);
// diff,diffStatisticsDTOs 是包含新增与修改的,所有的DTO实例
Set<StatisticsDTO> diffStatisticsDTOs = Sets.difference(new HashSet<>(srcDtos), new HashSet<>(dstDtos)).immutableCopy();
// 区分哪些索引是新增的,哪些索引是变动的
// 将src 源集合中的,IndexName所有索引名称,组成一个集合
Set<String> srcNames = srcDtos.stream().map(sdto -> sdto.getIndexName()).collect(Collectors.toSet());
// 将dst 源集合中的,IndexName所有索引名称,组成一个集合
Set<String> dstNames = dstDtos.stream().map(sdto -> sdto.getIndexName()).collect(Collectors.toSet());
// 在diffNames 中的实例,都是添加的。
Set<String> diffNames = Sets.difference(srcNames, dstNames).immutableCopy();
Map<Boolean, List<StatisticsDTO>> collect = diffStatisticsDTOs.stream()
// partitioning 分区。只能分两个区,true与false
.collect(Collectors.partitioningBy(statisticsDTO -> diffNames.contains(statisticsDTO)));
// Map,为true则是所有新增的。为false,是所有修改的。
return collect;
}
// 将StatisticsDo 转成 StatisticsDTO
private List<StatisticsDTO> fromStatisticsDOToDTO(List<StatisticsDO> statisticDos){
// 按照索引的名称进行分组 根据IndexName 对List<StatisticsDo> 分组。因为联合索引的原因。
// 联合索引,索引名称一样,但是对应的列和SeqInIndex的值不一样
Map<String, List<StatisticsDO>> dos = statisticDos.stream().collect(Collectors.groupingBy(s -> s.getIndexName()));
List<StatisticsDTO> collect = dos.entrySet().stream()
.map(entry -> {
//
StatisticsDO sdo = entry.getValue().get(0);
List<String> columns = entry.getValue().stream()
.sorted((x,y)->x.getSeqInIndex() - y.getSeqInIndex())
.map(s -> s.getColumnName()).collect(Collectors.toList());
return StatisticsDTO.builder()
.tableSchema(sdo.getTableSchema())
.tableName(sdo.getTableName())
.indexName(sdo.getIndexName())
.nonUnique(sdo.getNonUnique())
.indexType(sdo.getIndexType())
.columns(columns)
.build();
})
.collect(Collectors.toList());
return collect;
}
// 同步列
private void syncColumn(ConnectInfo srcInfo,ConnectInfo dstInfo,String dbName,String tableName){
// 1、获取,在src原 数据库实例下库的表的结构(字段+索引)
SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(srcInfo);
ColumnMapper mapper = sqlSession.getMapper(ColumnMapper.class);
List<ColumnDO> srcColumns = mapper.findByTable(dbName, tableName);
// 2、获取,在dst目标 数据库实例下库的表的结构(字段+索引)
List<ColumnDO> dstColumnDOS = DaoFacade.ofMapper(dstInfo, ColumnMapper.class, m -> m.findByTable(dbName, tableName));
// 1与2 实现的功能是一摸一样的,只不过2这里又封装了一下。
// 3、diff 差异
List<ColumnDO> columnDOS = diffColumn(srcColumns, dstColumnDOS);
// 4、基于差异,生成sql
List<String> sqls = generateSql(columnDOS);
// 5、执行sql
DaoFacade.executeSql(dstInfo,sqls);
}
// 做差集,使用第三方包guava
private List<ColumnDO> diffColumn(List<ColumnDO> srcColumns , List<ColumnDO> dstColumnDOS){
// 1、区分列的是实体类,是新增的还是修改的
// 如何判断是新增的:列的名字不一致,就是新增的
// 将List转成Set集合,然后求差值
Set<ColumnDO> diffColumns = Sets.difference(new HashSet<>(srcColumns), new HashSet<>(dstColumnDOS)).immutableCopy();
// 将src 列的集合,每个实体的类的名字组合成一个集合
Set<String> srcNames = srcColumns.stream().map(columnDO -> columnDO.getColumnName()).collect(Collectors.toSet());
// 将src 列的集合,每个实体的类的名字组合成一个集合
Set<String> dstNames = dstColumnDOS.stream().map(columnDO -> columnDO.getColumnName()).collect(Collectors.toSet());
// 将src 列名字的集合与dst列名字的集合求差值.判断哪些列是新增的
Set<String> addNames = Sets.difference(new HashSet<>(srcNames),new HashSet<>(dstNames)).immutableCopy();
// 给Column 设置 isAdd。
List<ColumnDO> collects = diffColumns.stream()
.peek(columnDO -> {
if (addNames.contains(columnDO.getColumnName())){
columnDO.setAdd(true);
}
})
.collect(Collectors.toList());
return collects;
}
private List<String> generateSql(List<ColumnDO> columnDOS){
// ALTER TABLE Student MODIFY COLUMN id VARCHAR(32) NOT NULL DEFAULT "000" COMMENT '备注';
// ALTER TABLE %s.%s MODIFY COLUMN %s %s %s %s %s;
// 将ColumnDo 的list 转成 String 语句的list,转换型,使用map
List<String> sqls = columnDOS.stream()
.map(columnDO -> {
// String sqlModel;
// if (columnDo.isAdd()){
// sqlModel = SqlModel.ADD_COLUMN;
// } else {
// sqlModel = SqlModel.MODIFY_COLUMN;
// }
String sql = String.format(columnDO.isAdd()? SqlConstant.ADD_COLUMN: SqlConstant.MODIFY_COLUMN,
columnDO.getTableSchema(), //库名
columnDO.getTableName(), // 表名
columnDO.getColumnName(),// 列名
columnDO.getColumnType(),// 列的类型
SqlUtils.nullableSet(columnDO.getIsNullable()),// 列是否为空
SqlUtils.defaultSet(columnDO.getColumnDefault()),// 列的默认值设置
SqlUtils.commentSet(columnDO.getColumnComment())// 设置列的备注
);
return sql;
})
.collect(Collectors.toList());
return sqls;
}
}
这里主要就是同步实例、同步库、同步表的具体方式。
主要用到了lambda表达式,对数据流做处理。没有太复杂的逻辑,就是有些琐碎。
做两个表直接的对比,用的是Sets.difference
十二、mapper层
接口BaseMapper
package com.chenshuia.study.mysqlsync.mapper;
public interface BaseMapper {
}我们这个项目的Mapper接口,都继承了这个BaseMapper。BaseMapper 没啥实际的作用,这里只是用来做标志用的。
接口ColumnMapper
package com.chenshuia.study.mysqlsync.mapper;
import com.chenshuia.study.mysqlsync.bean.ColumnDO;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface ColumnMapper extends BaseMapper{
// 根据表的名称,查询表的列。一个列数,对应一条ColumnDo
@Select("select table_schema,table_name,column_name,column_type,column_comment,data_type," +
"column_default,is_nullable from information_schema.columns where table_schema = #{dbName} and table_name =#{tableName}" )
List<ColumnDO> findByTable(@Param("dbName") String dbName, @Param("tableName") String tableName );
}
在 information_schema.COlUMNS 对应的实体类ColumnDO。(表中字段的属性)
接口StatisticsMapper
package com.chenshuia.study.mysqlsync.mapper;
import com.chenshuia.study.mysqlsync.bean.StatisticsDO;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface StatisticsMapper extends BaseMapper{
@Select("select TABLE_SCHEMA,TABLE_NAME,INDEX_NAME,SEQ_IN_INDEX,COLUMN_NAME,NON_UNIQUE,INDEX_TYPE from information_schema.statistics " +
"where table_schema = #{dbName} and table_name = #{tableName}")
List<StatisticsDO> findByTable(@Param("dbName") String dbName, @Param("tableName") String tableName);
}
表中的索引,对应的表information_schema.statistics
接口SchemaMapper
对应的库
package com.chenshuia.study.mysqlsync.mapper;
import com.chenshuia.study.mysqlsync.bean.SchemaDO;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface SchemaMapper extends BaseMapper{
@Select("select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME from information_schema.SCHEMATA")
List<SchemaDO> findAll();
@Select("select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME from information_schema.SCHEMATA where schema_name = #{dbName}")
SchemaDO findByDBName(String dbName);
}
TableMapper
package com.chenshuia.study.mysqlsync.mapper;
import com.chenshuia.study.mysqlsync.bean.TableDO;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface TableMapper extends BaseMapper{
@Select("select TABLE_SCHEMA,TABLE_NAME,ENGINE from information_schema.tables where TABLE_SCHEMA= #{dbName}")
List<TableDO> findByDBName(String dbName);
}
十三、constant 常量层
IndexType 索引的类型
package com.chenshuia.study.mysqlsync.constant;
public interface IndexType {
String PRIMARY = "PRIMARY";
String BTREE = "BTREE";
String FULLTEXT = "FULLTEXT";
}
SqlConstant
同步表的时候,执行的这些sql
package com.chenshuia.study.mysqlsync.constant;
import com.google.common.collect.Lists;
import java.util.List;
public interface SqlConstant {
// 修改列的sql模版
String MODIFY_COLUMN = "ALTER TABLE %s.%s MODIFY COLUMN %s %s %s %s %s";
// 新增列的sql模版
String ADD_COLUMN = "ALTER TABLE %s.%s ADD COLUMN %s %s %s %s %s";
// 添加索引的模版(区分唯一/不唯一索引)
// ALTER TABLE %s.%s ADD %s INDEX %s (列名)
// ALTER TABLE %s.%s ADD PRIMARY KEY (id);
// ALTER TABLE %s.%s ADD FULLTEXT xxx(NAME);
String ADD_INDEX = "ALTER TABLE %s.%s ADD %s %s (%s)";
// 索引没有修改,只能先删除,再添加
String DROP_INDEX = "ALTER TABLE %s.%s DROP INDEX %s";
// mysql系统自带库,是不需要进行同步的。
List<String> MYSQL_SYS_DBS = Lists.newArrayList("information_schema","performance_schema","sys","mysql","test");
}
十四、util 层 工具层
VerifyUtil
对数据进行为空校验
package com.chenshuia.study.mysqlsync.util;
import org.apache.logging.log4j.util.Strings;
public class VerifyUtil {
public static void verifyString(String data,String msg){
if (Strings.isEmpty(data)){
throw new IllegalArgumentException(msg);
}
}
public static void verifyString(String... datas){
for (String data:datas){
verifyString(data,"data is not null");
}
}
}
SqlUtils 拼接sql的工具
对数据库进行修改时,执行的这些sql。拼接这些sql时,需要做一些逻辑处理。
package com.chenshuia.study.mysqlsync.util;
import com.chenshuia.study.mysqlsync.bean.StatisticsDTO;
import java.util.Objects;
public class SqlUtils {
// 列是否为空的处理
public static String nullableSet(String nullable){
if ("NO".equals(nullable)){
return "not null";
}
return "null";
}
// 列,默认值的处理,(可能为空,null,0)
public static String defaultSet(String defaultValue){
if (Objects.isNull(defaultValue)){
return "";
}
return "DEFAULT '"+defaultValue+"'";
}
// 列,备注的处理
public static String commentSet(String comment){
if (Objects.isNull(comment)){
return "";
}
return "COMMENT '"+comment+"'";
}
//
public static String indexTypeSet(StatisticsDTO dto){
// 1、主键 index_name 为 PRIMARY
// 2、唯一索引 unique = 0 并且 index_name != PRIMARY
// 3、普通索引 unique = 1 并且 index_type = BTREE
// 4、全文索引 unique = 1 并且 index_type = FULLTEXT
if(("PRIMARY").equals(dto.getIndexName())){
return "PRIMARY KEY";
}
if(dto.getNonUnique() == 0){
return "UNIQUE";
}
if("BTREE".equals(dto.getIndexType())){
return "INDEX";
} else {
return "FULLTEXT";
}
}
}
十五、common 层
LocalSqlSessionFactory
使用mybatis进行数据库连接,非常重要的一点就是获取SqlSession。这里用到了单例模式。
package com.chenshuia.study.mysqlsync.common;
import com.chenshuia.study.mysqlsync.bean.ConnectInfo;
import org.apache.ibatis.mapping.Environment;
import org.apache.ibatis.session.Configuration;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.apache.ibatis.transaction.jdbc.JdbcTransactionFactory;
public class LocalSqlSessionFactory {
private LocalSqlSessionFactory(){}
// 构造器,私有,不能被new
// ClassHolder属于静态内部类,在加载类Demo03的时候,只会加载内部类ClassHolder,
// 但是不会把内部类的属性加载出来
private static class ClassHolder{
// 这里执行类加载,是jvm来执行类加载,它一定是单例的,不存在线程安全问题
// 这里不是调用,是类加载,是成员变量
private static final LocalSqlSessionFactory holder =new LocalSqlSessionFactory();
}
public static LocalSqlSessionFactory of(){
//第一次调用getInstance()的时候赋值
return ClassHolder.holder;
}
public SqlSession getSqlSession(ConnectInfo connectInfo){
// 这里我们要做的就是通过数据库的配置,对数据库进行连接。拿到sqlSession
Configuration configuration = new Configuration();
// 驼峰映射
configuration.setMapUnderscoreToCamelCase(true);
// Mapper的包名
configuration.addMappers("com.chenshuia.study.mysqlsync.mapper");
//
Environment environment = new Environment.Builder("development")
.transactionFactory(new JdbcTransactionFactory())
.dataSource(LocalDataSourceFactory.of().getPoolDataSource(connectInfo))
.build();
configuration.setEnvironment(environment);
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession = build.openSession(true);
return sqlSession;
}
}
LocalDataSourceFactory
package com.chenshuia.study.mysqlsync.common;
import com.chenshuia.study.mysqlsync.bean.ConnectInfo;
import org.apache.ibatis.datasource.pooled.PooledDataSource;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
public class LocalDataSourceFactory {
private Map<String,DataSource> dataSourceMap;
private LocalDataSourceFactory(){
dataSourceMap = new HashMap<>();
}
// 构造器,私有,不能被new
// ClassHolder属于静态内部类,在加载类Demo03的时候,只会加载内部类ClassHolder,
// 但是不会把内部类的属性加载出来
private static class ClassHolder{
// 这里执行类加载,是jvm来执行类加载,它一定是单例的,不存在线程安全问题
// 这里不是调用,是类加载,是成员变量
private static final LocalDataSourceFactory holder =new LocalDataSourceFactory();
}
public static LocalDataSourceFactory of(){//第一次调用getInstance()的时候赋值
return ClassHolder.holder;
}
public DataSource getPoolDataSource(ConnectInfo connectInfo){
String key = getDataSourceKey(connectInfo);
if (dataSourceMap.containsKey(key)){
return dataSourceMap.get(key);
}
PooledDataSource dataSource = new PooledDataSource();
dataSource.setUrl(connectInfo.getUrl());
dataSource.setUsername(connectInfo.getUserName());
dataSource.setPassword(connectInfo.getPassword());
dataSource.setDriver(connectInfo.getDriver());
dataSourceMap.put(key,dataSource);
return dataSource;
}
private String getDataSourceKey(ConnectInfo connectInfo){
return String.format("%s-%s-%s",connectInfo.getUrl(),connectInfo.getUserName(),connectInfo.getPassword());
}
}
这里也用到了单例模式。
DataSource 是干啥的?
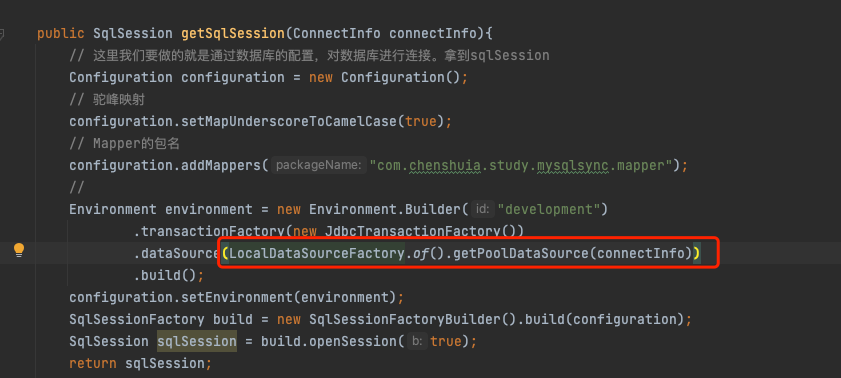
我们在生成sqlSession、Environment 的时候,需要用到DataSource。
在进行表同步的时候,我们每个表同步连接的时候,都需要拿到一个sqlSession。我们就需要大量的DataSource。 但是DataSource 很多情况下就是重复的。
这里将DataSource放到一个Map里,重复的就直接拿去用,没有的话,就生成一个。
十六、dao层
![]()
DaoFacade
package com.chenshuia.study.mysqlsync.dao;
import com.chenshuia.study.mysqlsync.bean.ConnectInfo;
import com.chenshuia.study.mysqlsync.common.LocalSqlSessionFactory;
import com.chenshuia.study.mysqlsync.mapper.BaseMapper;
import org.apache.ibatis.session.SqlSession;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.List;
import java.util.function.Function;
public class DaoFacade {
public static <R,M extends BaseMapper> R ofMapper(ConnectInfo connectInfo, Class<M> clazz, Function<M,R> function){
try(SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(connectInfo)){
M mapper = sqlSession.getMapper(clazz);
R result = function.apply(mapper);
return result;
} catch (Exception e){
e.printStackTrace();
throw new IllegalStateException("mapper failed");
}
}
public static void executeSql(ConnectInfo connectInfo,String sql){
try (SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(connectInfo);
Connection connection = sqlSession.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);){
ps.executeUpdate();
} catch (Exception e){
e.printStackTrace();
}
}
public static void executeSql(ConnectInfo connectInfo, List<String> sqls){
// 方式一
// try (SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(connectInfo);
// Connection connection = sqlSession.getConnection()){
// sqls.stream().forEach(sql ->{
// try(PreparedStatement ps = connection.prepareStatement(sql)) {
// ps.executeUpdate();
// } catch (Exception e){
// e.printStackTrace();
// }
// });
// } catch (Exception e){
// e.printStackTrace();
// }
// 方式二
try (SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(connectInfo);
Connection connection = sqlSession.getConnection();
Statement st = connection.createStatement()){
sqls.stream().forEach(sql ->{
try {
st.executeUpdate(sql);
} catch (Exception e){
e.printStackTrace();
}
});
} catch (Exception e){
e.printStackTrace();
}
}
// 获取创建表/创建库的sql
public static String getInfo(ConnectInfo connectInfo,String sql,String columnName){
try(SqlSession sqlSession = LocalSqlSessionFactory.of().getSqlSession(connectInfo);
Connection connection = sqlSession.getConnection();
Statement st = connection.createStatement();
ResultSet rs = st.executeQuery(sql);){
if (rs.next()){
return rs.getString(columnName);
}
throw new IllegalArgumentException();
} catch (Exception e){
e.printStackTrace();
throw new IllegalArgumentException();
}
}
// 获取创建表的sql
public static String getTableSql(ConnectInfo connectInfo,String dbName,String tableName){
String sql = String.format("show create table %s.%s",dbName,tableName);
String columnName = "Create Table";
return getInfo(connectInfo,sql,columnName);
}
// 获取创建库的sql
public static String getDBSql(ConnectInfo connectInfo,String dbName){
String sql = String.format("show create database %s",dbName);
String columnName = "Create Database";
return getInfo(connectInfo,sql,columnName);
}
}
执行sql的一些方法,以及生成mapper的方法(ofMapper)。
十七、工具使用
启动项目,我们执行对2个库的某个表的同步。
使用postman,post请求。
举例:
同步2个实例
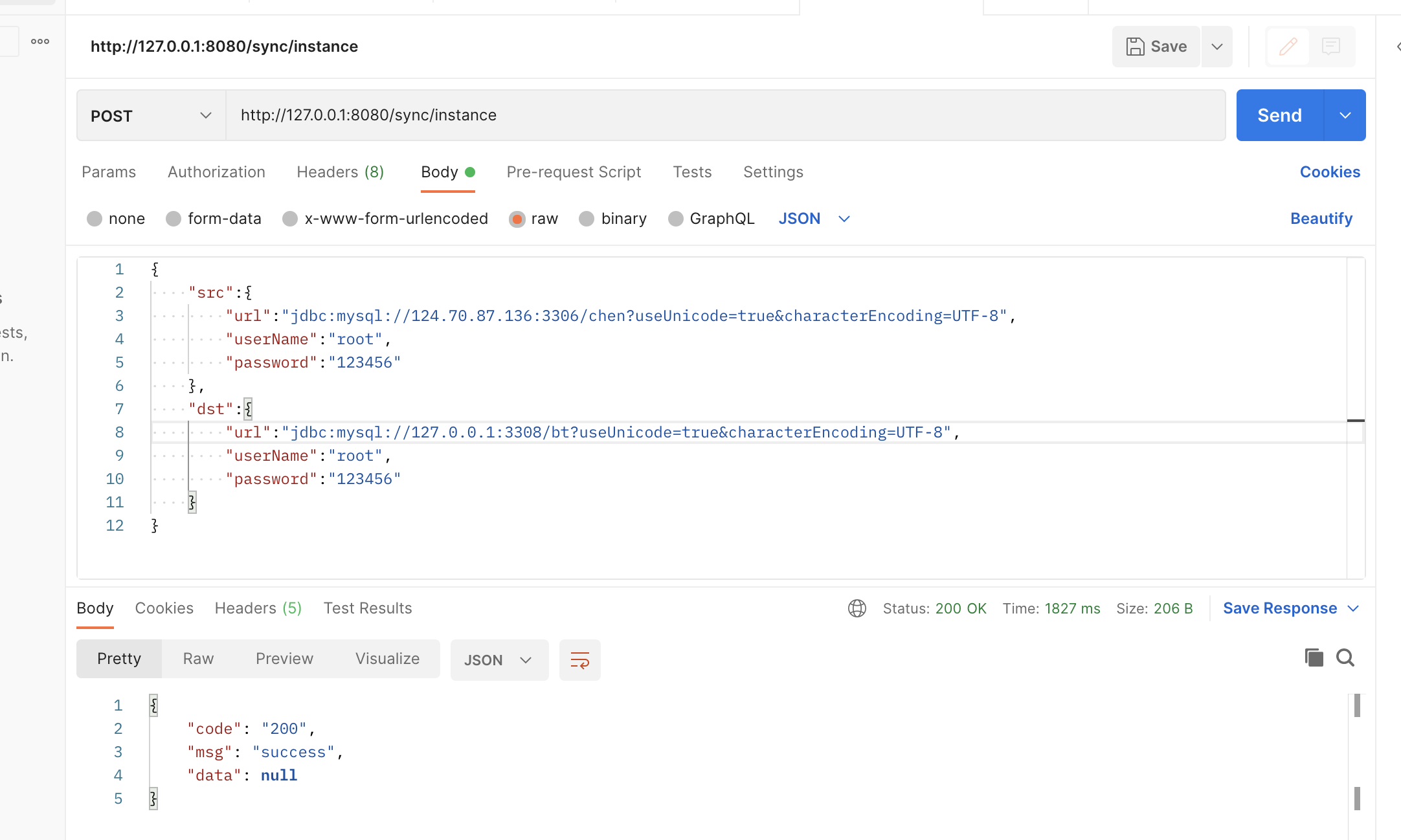
{
"src":{
"url":"jdbc:mysql://124.70.87.xx:3306/chen?useUnicode=true&characterEncoding=UTF-8",
"userName":"xxx",
"password":"xxx"
},
"dst":{
"url":"jdbc:mysql://127.0.0.1:3308/bt?useUnicode=true&characterEncoding=UTF-8",
"userName":"xx",
"password":"xxxxx"
}
}注意url的格式为:
jdbc:mysql://124.70.87.136:3306/chen?useUnicode=true&characterEncoding=UTF-8",url里需要加上编码,防止乱码。