目录
原理:
初始化数据结构时的线程安全
put 操作时的线程安全
原理:
多段锁+cas+synchronize
初始化数据结构时的线程安全
在 JDK 1.8 中,初始化 ConcurrentHashMap 的时候这个 Node[] 数组是还未初始化的,会等到第一次 put() 方法调用时才初始化
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 判断Node数组为空
if (tab == null || (n = tab.length) == 0)
// 初始化Node数组
tab = initTable();
......
}
此时会有并发问题的,如果多个线程同时调用 initTable() 初始化 Node[] 数组怎么办?看看 Doug Lea 大师是如何处理的
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// 每次循环都获取最新的Node[]数组引用
while ((tab = table) == null || tab.length == 0) {
// sizeCtl是一个标记位,若为-1,代表有线程在进行初始化工作了
if ((sc = sizeCtl) < 0)
// 让出CPU时间片
Thread.yield();
// 此时,代表没有线程在进行初始化工作,CAS操作,将本实例的sizeCtl变量设置为-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// 如果CAS操作成功了,代表本线程将负责初始化工作
try {
// 再检查一遍数组是否为空
if ((tab = table) == null || tab.length == 0) {
// 在初始化ConcurrentHashMap时,sizeCtl代表数组大小,默认16
// 所以此时n默认为16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将其赋值给table变量
table = tab = nt;
// 通过位运算,n减去n二进制右移2位,相当于乘以0.75
// 例如16经过运算为12,与乘0.75一样,只不过位运算更快
sc = n - (n >>> 2);
}
} finally {
// 将计算后的sc(12)直接赋值给sizeCtl,表示达到12长度就扩容
// 由于这里只会有一个线程在执行,直接赋值即可,没有线程安全问题,只需要保证可见性
sizeCtl = sc;
}
break;
}
}
return tab;
}
总结:就算有多个线程同时进行 put 操作,在初始化 Node[] 数组时,使用了 CAS 操作来决定到底是哪个线程有资格进行初始化,其他线程只能等待。用到的并发技巧如下
- volatile 修饰 sizeCtl 变量:它是一个标记位,用来告诉其他线程这个坑位有没有线程在进行初始化工作,其线程间的可见性由 volatile 保证
- CAS 操作:CAS 操作保证了设置 sizeCtl 标记位的原子性,保证了在多线程同时进行初始化 Node[] 数组时,只有一个线程能成功
put 操作时的线程安全
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// K,V 都不能为空
if (key == null || value == null) throw new NullPointerException();
// 取得 key 的 hash 值
int hash = spread(key.hashCode());
// 用来计算在这个节点总共有多少个元素,用来控制扩容或者转换为树
int binCount = 0;
// 数组的遍历,自旋插入结点,直到成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 当Node[]数组为空时,进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// Unsafe类volatile的方式取出hashCode散列后通过与运算得出的Node[]数组下标值对应的Node对象
// 此时 Node 位置若为 null,则表示还没有线程在此 Node 位置进行插入操作,说明本次操作是第一次
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果这个位置没有元素的话,则通过 CAS 的方式插入数据
if (casTabAt(tab, i, null,
// 创建一个 Node 添加到数组中,null 表示的是下一个节点为空
new Node<K,V>(hash, key, value, null)))
// 插入成功,退出循环
break;
}
// 如果检测到某个节点的 hash 值是 MOVED,则表示正在进行数组扩容
else if ((fh = f.hash) == MOVED)
// 帮助扩容
tab = helpTransfer(tab, f);
// 此时,说明已经有线程对Node[]进行了插入操作,后面的插入很有可能会发生Hash冲突
else {
V oldVal = null;
// ----------------synchronized----------------
synchronized (f) {
// 二次确认此Node对象还是原来的那一个
if (tabAt(tab, i) == f) {
// ----------------table[i]是链表结点----------------
if (fh >= 0) {
// 记录结点数,超过阈值后,需要转为红黑树,提高查找效率
binCount = 1;
// 遍历这个链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 要存的元素的 hash 值和 key 跟要存储的位置的节点的相同的时候,替换掉该节点的 value 即可
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将新值放到链表的最末端
Node<K,V> pred = e;
// 如果不是同样的 hash,同样的 key 的时候,则判断该节点的下一个节点是否为空
if ((e = e.next) == null) {
// ----------------“尾插法”插入新结点----------------
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// ----------------table[i]是红黑树结点----------------
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 调用putTreeVal方法,将该元素添加到树中去
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 当在同一个节点的数目达到8个的时候,则扩张数组或将给节点的数据转为tree
if (binCount >= TREEIFY_THRESHOLD)
// 链表 -> 红黑树 转换
treeifyBin(tab, i);
// 表明本次put操作只是替换了旧值,不用更改计数值
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);// 计数值加1
return null;
}
总结:
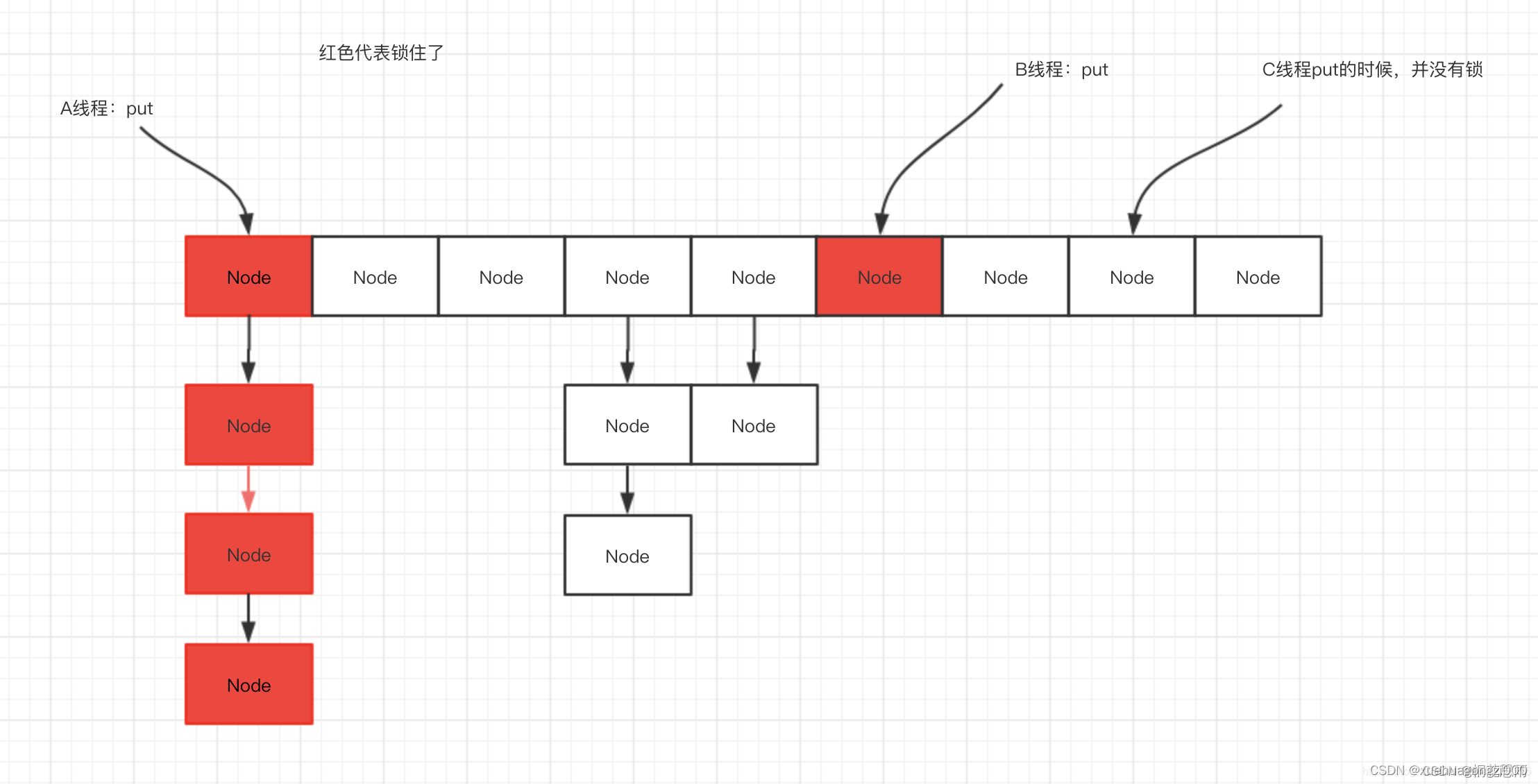
put() 方法的核心思想:由于其减小了锁的粒度,若 Hash 完美不冲突的情况下,可同时支持 n 个线程同时 put 操作,n 为 Node 数组大小,在默认大小 16 下,可以支持最大同时 16 个线程无竞争同时操作且线程安全
当 Hash 冲突严重时,Node 链表越来越长,将导致严重的锁竞争,此时会进行扩容,将 Node 进行再散列,下面会介绍扩容的线程安全性。总结一下用到的并发技巧
- 减小锁粒度:将 Node 链表的头节点作为锁,若在默认大小 16 情况下,将有 16 把锁,大大减小了锁竞争(上下文切换),就像开头所说,将串行的部分最大化缩小,在理想情况下线程的 put 操作都为并行操作。同时直接锁住头节点,保证了线程安全
- 使用了 volatile 修饰 table 变量,并使用 Unsafe 的 getObjectVolatile() 方法拿到最新的 Node
- CAS 操作:如果上述拿到的最新的 Node 为 null,则说明还没有任何线程在此 Node 位置进行插入操作,说明本次操作是第一次
- synchronized 同步锁:如果此时拿到的最新的 Node 不为 null,则说明已经有线程在此 Node 位置进行了插入操作,此时就产生了 hash 冲突;此时的 synchronized 同步锁就起到了关键作用,防止在多线程的情况下发生数据覆盖(线程不安全),接着在 synchronized 同步锁的管理下按照相应的规则执行操作
参考:
【精选】ConcurrentHashMap是如何实现线程安全的_concurrenthashmap如何保证线程安全-CSDN博客






![[LeetCode] 2.两数相加](https://img-blog.csdnimg.cn/0b28e0acd1a74e1ca7a12d90a79a70bd.jpeg#pic_center)