目录
一、rwkv模型简介
二、lora原理简介
三、rwkv-lora微调
1、数据整理
2、环境搭建
a、Dockerfile编写
b、制造镜像
c、容器启动
3、训练代码修改
四、模型推理
1、模型推理
2、lora权重合并
3、推理web服务
五、总结
由于业务采用的ChatGLM模型推理成本太大了,希望降低模型推理成本。因此对rwkv_1.5B模型进行了预研和业务领域的验证。为了快速验证,采用了lora+accelerate+deepspeed的训练方式。微调的过程中对rwkv模型认识更加深刻,同时对于docker训练环境搭建也更加熟悉了。这篇博客就分享一下这次微调中的一些实践,主要是关于训练流程拉通和rwkv模型在业务领域的一些结论。
一、rwkv模型简介
rwkv模型是国人研发的一个非常优秀的模型,采用RNN架构代码目前主流的attention机制的transformer架构,在时间复杂度和空间复杂度都减少比较多的情况下,还能取得非常不错的效果,在各个榜单都有上榜。

上图是rwkv模型语言建模的架构,可以看到舍弃了attention机制,采用time mix 和channel mix模块。
二、lora原理简介
论文LoRA: Low-Rank Adaptation of Large Language Models 开发了一种方法,专为微调大模型减小显存。如下图:

![]()
对于一个参数,在微调的时候不直接微调W,而是把W通过低秩分解为两个小矩阵B和A的乘积,然后学习更新B和A,从而达到减少参数量和梯度等,同时保证模型lora微调后的效果和全参数微调效果相当。实现的时候会在BAx乘以一个系数,一般是lora_alpha/lora_rank的比值,注意lora_rank越大可学习的参数越多,显存占用就越多。
实践一般采用peft来实现对模型的linear层进行weight分解,使用方法如下:
model初始化
......
peft_config = LoraConfig(
peft_type="LORA",
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
target_modules=args.target_modules.split(","),
)
model = get_peft_model(model, peft_config)
......
model训练和保存
model_state_dict = lora.lora_state_dict(model)
torch.save(path,model_state_dict )三、rwkv-lora微调
rwkv的微调主要的重点内容在于数据的整理(整理成模型可训练的格式)、训练环境的搭建、训练代码的修改和最后的模型效果评估,其中至于怎么样微调才能获得比较好的效果,本文不予讨论。由于rwkv支持2中数据格式,一种是question+answer拼接,另外一种是instruction+input+response拼接;目前1.5B,rwkv开源了v4和v5版本的权重,因此这里会做4次实验,用相同的业务数据构成训练集和测试集,使用不用的权重和数据指令拼接方式进行实验。
1、数据整理
qa指令拼接——适合做问答类
{"text": "Question: 问题\n\nAnswer: 答案"}iir指令拼接——适合做阅读理解问答
{"text": "Instruction:基于专业背景的知识问题\n\nInput:专业领域的资料背景知识内容\n\nResponse:基于上述的专业回答"}其中Instruction 是指示,Input 是需要操作的数据(注意Input可以为空),Response是答案
我们的业务数据
{"context": "姓名:未知\n服务时间:晚上23点\n联系方式:未知\n地址:广东省深圳市龙岗区南湾街道康桥花园\n空调品牌:卡萨帝\n空调样式:挂机\n是否5匹:10匹\n故障类型:异味\n\n坐席:空调发生什么故障了,不制热、不制冷、不开机还是其他问题?\n客户:其他不故障现象\n\n以上海尔导航场景收集的要素信息以及坐席和客户的一轮对话,你是要素抽取的专家,请根据坐席和客户的对话,更新上述要素结果,对话中未提及到的要素,保持原样结果输出,“空调品牌”取值范围是“卡萨帝”、“海尔”、“统帅”、“小超人”,“空调样式”取值范围是“柜机”、“挂机”、“嵌入机”、“中央空调”,“是否5匹”取值范围是“5匹以上”、“5匹以下”,“故障类型”取值范围是“不制冷”、“不制热”、“机器制热效果差”、“机器制冷效果差”、“机器着火”、“遥控器故障”、“无法关机”、“噪音大”、“温度不能调整”、“外观伤”、“频繁开停机”、“显示屏乱码跳屏”、“机器报故障”、“室内机漏水”、“连接管未包扎好”、“送风强度”、“异味”、“漏电”、“不通电”、“不启动”、“按键失灵”、“出风异常”、“显示屏异常”、“不停机”、“不除霜”、“排水管问题”、“空调漏气/漏氟”、“购买配件”、“自动开/关机”\n请给出要素抽取结果", "target": "姓名:未知\n\n服务时间:晚上23点\n\n联系方式:未知\n\n地址:广东省深圳市龙岗区南湾街道康桥花园\n\n空调品牌:卡萨帝\n\n空调样式:挂机\n\n是否5匹:10匹\n\n故障类型:其它故障"}
qa拼接后的形式:
{"text": "Question:姓名:未知\n服务时间:晚上23点\n联系方式:未知\n地址:广东省深圳市龙岗区南湾街道康桥花园\n空调品牌:卡萨帝\n空调样式:挂机\n是否5匹:10匹\n故障类型:异味\n\n坐席:空调发生什么故障了,不制热、不制冷、不开机还是其他问题?\n客户:其他不故障现象\n\n以上是海尔导航场景收集的要素信息以及坐席和客户的一轮对话,你是要素抽取的专家,请根据坐席和客户的对话,更新上述要素结果,对话中未提及到的要素,无需输出,若所有要素在对话中均未提到,请直接输出“无效对话”,空调品牌取值范围是“卡萨帝”、“海尔”、“统帅”、“小超人”;空调样式取值范围是“柜机”、“挂机”、“嵌入机”、“中央空调”;是否5匹取值范围是“5匹”、“5匹以上”、“5匹以下”、“10匹”;故障类型取值范围是“不制冷”、“不制热”、“机器制热效果差”、“机器制冷效果差”、“机器着火”、“遥控器故障”、“无法关机”、“噪音大”、“温度不能调整”、“外观伤”、“频繁开停机”、“显示屏乱码跳屏”、“机器报故障”、“室内机漏水”、“连接管未包扎好”、“送风强度”、“异味”、“漏电”、“不通电”、“不启动”、“按键失灵”、“显示屏异常”、“不停机”、“不除霜”、“空调漏气/漏氟”、“购买配件”、“自动开/关机”、“出风异常”、“排水管问题”、“其他故障”\n请给出要素抽取结果\n\nAnswer:故障类型:其它故障"}
iir拼接后的形式:
{"text": "Instruction:以上是海尔导航场景收集的要素信息以及坐席和客户的一轮对话,你是要素抽取的专家,请根据坐席和客户的对话,更新上述要素结果,对话中未提及到的要素,无需输出,若所有要素在对话中均未提到,请直接输出“无效对话”,空调品牌取值范围是“卡萨帝”、“海尔”、“统帅”、“小超人”;空调样式取值范围是“柜机”、“挂机”、“嵌入机”、“中央空调”;是否5匹取值范围是“5匹”、“5匹以上”、“5匹以下”、“10匹”;故障类型取值范围是“不制冷”、“不制热”、“机器制热效果差”、“机器制冷效果差”、“机器着火”、“遥控器故障”、“无法关机”、“噪音大”、“温度不能调整”、“外观伤”、“频繁开停机”、“显示屏乱码跳屏”、“机器报故障”、“室内机漏水”、“连接管未包扎好”、“送风强度”、“异味”、“漏电”、“不通电”、“不启动”、“按键失灵”、“显示屏异常”、“不停机”、“不除霜”、“空调漏气/漏氟”、“购买配件”、“自动开/关机”、“出风异常”、“排水管问题”、“其他故障”\n请给出要素抽取结果\n\nInput:姓名:未知\n服务时间:晚上23点\n联系方式:未知\n地址:广东省深圳市龙岗区南湾街道康桥花园\n空调品牌:卡萨帝\n空调样式:挂机\n是否5匹:10匹\n故障类型:异味\n\n坐席:空调发生什么故障了,不制热、不制冷、不开机还是其他问题?\n客户:其他不故障现象\n\nResponse:故障类型:其它故障"}
2、环境搭建
官方代码库指定的环境直接安装就好了,不过安装的过程中要注意机器的显卡驱动一定要比安装的cuda版本要高,并且cuda版本的算力不能低于显卡的算力(大多数情况下,显卡是支持一定的低版本的cuda和torch的);torch的版本要和cuda的版本一致,比如4090显卡安装了12.0的显卡驱动,安装了cuda11.8,那么torch也要安装cuda11.8的版本 torch2.0_cu118。rwkv有自己实现的cuda算子需要python调用C++和nvcc来编译作为torch的扩展,所以要严格匹配版本,不然会报显卡算力过高和torch版本不匹配,cuda和torch版本不匹配等错误。C++编译的时候还需要完整的libso库文件,由于本人使用的机器多人使用,不好升级libso库文件——错误操作可能会导致linux系统出错。稳妥起见直接使用docker来搭建训练环境,并且在docker中训练。物理机器上安装docker,编写dockerfile后,制作镜像,启动容器然后训练就OK了。
a、Dockerfile编写
##build 镜像
#docker build -t images_name(images_name:tag) -f ./Dockerfile .
##运行容器 --gpus all 宿主机上的显卡可用 --ipc host 代表与宿主机器共享命名空间,即让Docker容器和宿主机器使用同一个进程ID命名空间和信号命名空间,从而实现进程间通信的能力
## --network host docker 使用本机的IP和端口
#docker run -d -it --name my_container --gpus all --network host --ipc host images_name(id)
#cuda toolkit共享的库,涵盖了运行环境的最小集合如动态库等,但没有cuda的编译工具nvcc
#FROM nvidia/cuda:11.8.0-runtime-ubuntu22.04
#基于runtime,添加了编译工具链、调试工具、头文件、静态库,用于从源码编译cuda应用,是有nvcc的
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
WORKDIR /rwkv
# Set up time zone.
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime
ENV STAGE_DIR=/tmp
RUN mkdir -p ${STAGE_DIR}
RUN apt-get update && \
apt-get install -y --no-install-recommends \
software-properties-common build-essential autotools-dev \
nfs-common pdsh \
cmake g++ gcc \
curl wget vim tmux emacs less unzip \
htop iftop iotop ca-certificates openssh-client openssh-server \
rsync iputils-ping net-tools
RUN apt-get update && \
apt-get install -y --no-install-recommends \
libsndfile-dev \
libcupti-dev \
libjpeg-dev \
libpng-dev \
screen \
libaio-dev
#从源码安装python
RUN apt install unzip wget build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev curl libbz2-dev pkg-config make -y
RUN apt-get install liblzma-dev -y
#RUN wget https://www.python.org/ftp/python/3.10.10/Python-3.10.10.tar.xz
COPY Python-3.10.10.tar.xz ./
RUN tar xf Python-3.10.10.tar.xz
RUN cd Python-3.10.10 && ./configure --enable-optimizations && make altinstall && cd .. && rm -fr *
RUN python3.10 -m pip install torch==2.0.0 --index-url https://download.pytorch.org/whl/cu118
WORKDIR /rwkv
COPY requirements.txt ./
#RUN python3.10 -m pip install -r requirements.txt
#RUN python3.10 -m pip install --upgrade pip && python3.10 -m pip install -i https://mirrors.aliyun.com/pypi/simple -r requirements.txt
RUN python3.10 -m pip install -i https://mirrors.aliyun.com/pypi/simple -r requirements.txt
# 拷贝所有nue文件
COPY . ./注意python可以提前现在源码,然后上传到服务器再制作镜像;cuda docker 一定要拉取devel版本,runtime版本会精简,不安装nvcc等编译工具,python安装一些第三方库会依赖nvcc编译工具的。其他的都没有什么了,一切正常编写即可。
b、制造镜像
docker build -t images_name(images_name:tag) -f ./Dockerfile .这个耗时比较久,一个是镜像、已经库文件安装,还有数据、代码等copy。
c、容器启动
docker run -d -it --name my_container --gpus all --network host --ipc host images_name(id)关注的地方是--gpus 一定要是all,这样容器才能使用物理机上的所有显卡;--network host保证docker使用物理机的ip和端口,可以通过改ip访问docker内的服务;--ipc host让Docker容器和宿主机器使用同一个进程ID命名空间和信号命名空间,从而实现进程间通信的能力——跑分布式训练必须选项,因为多进程中的子进程要和主进程进行通信,传输梯度等信息。
3、训练代码修改
原始的训练代码是不支持lora和accelerate的,这里我们修改为支持lora以及accelerate的形式。同时由于采用分布式训练,目前可以使用deepspeed来做,而accelerate也支持deepspeed的插件形式(和直接使用deepspeed来做分布式训练稍有不同,直接使用deepspeed对系统的各种库libso要求的比较严格,之前使用deepspeed一直没有成功过)。代码主体结构如下:
from accelerate import Accelerator, DeepSpeedPlugin
from peft import get_peft_model, LoraConfig, TaskType
import loralib as lora
#初始化分布式环境
accumulate_step = 4
mixed_precision = 'bf16'
deepspeed_plugin = DeepSpeedPlugin(zero_stage=2, gradient_accumulation_steps=accumulate_step)
accelerator = Accelerator(mixed_precision=mixed_precision, gradient_accumulation_steps=accumulate_step, deepspeed_plugin=deepspeed_plugin)
device = accelerator.device
......
......
model = RWKV(args)
#lora设置,设置模型的那些参数使用lora以及其他的一些参数。
peft_config = LoraConfig(
peft_type="LORA",
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
target_modules=args.target_modules.split(","),
)
model = get_peft_model(model, peft_config)
......
#模型、优化器、数据加载器等用accelerate包装一下。
model, optimizer, train_dataloader = accelerator.prepare(model, optimizer,train_dataloader)
......
for epoch in range(int(args.epoch_count)):
for step, batch in enumerate(t := tqdm(train_dataloader, ncols=100)):
model(batch)
......
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()分布式环境的初始化以及lora参数的设置,针对rwkv模型lora设置如下:
lora_rank=16
lora_alpha=32
lora_dropout=0.1
target_modules=emb,key,value,receptance,output,head完整的训练代码如下(其他的部分自行完成,代码修改自rwkv_LM中的rwkv-v4neo):
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
import os, warnings, math, sys, time
import numpy as np
import torch
from torch.utils.data import DataLoader
import logging
from transformers import get_linear_schedule_with_warmup
from argparse import ArgumentParser
logging.basicConfig(level=logging.INFO)
import os
import sys
sys.path.append(os.getcwd())
def script_method(fn, _rcb=None):
return fn
def script(obj, optimize=True, _frames_up=0, _rcb=None):
return obj
import torch.jit
script_method1 = torch.jit.script_method
script1 = torch.jit.script
torch.jit.script_method = script_method
torch.jit.script = script
from torch.utils.tensorboard import SummaryWriter
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import gc
import psutil
import traceback
from tqdm import tqdm
import numpy as np
from accelerate import Accelerator, DeepSpeedPlugin
from torch.utils.data import Dataset, IterableDataset
import random
import json
from collections import defaultdict
import threading
from tokenizer import build_tokenizer
from datetime import datetime
from peft import get_peft_model, LoraConfig, TaskType
import loralib as lora
accumulate_step = 4
mixed_precision = 'bf16'
deepspeed_plugin = DeepSpeedPlugin(zero_stage=2, gradient_accumulation_steps=accumulate_step)
accelerator = Accelerator(mixed_precision=mixed_precision, gradient_accumulation_steps=accumulate_step, deepspeed_plugin=deepspeed_plugin)
device = accelerator.device
def b2mb(x):
return int(x / 2 ** 20)
class TorchTracemalloc:
def __enter__(self):
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated() # reset the peak gauge to zero
self.begin = torch.cuda.memory_allocated()
self.process = psutil.Process()
self.cpu_begin = self.cpu_mem_used()
self.peak_monitoring = True
peak_monitor_thread = threading.Thread(target=self.peak_monitor_func)
peak_monitor_thread.daemon = True
peak_monitor_thread.start()
return self
def cpu_mem_used(self):
"""get resident set size memory for the current process"""
return self.process.memory_info().rss
def peak_monitor_func(self):
self.cpu_peak = -1
while True:
self.cpu_peak = max(self.cpu_mem_used(), self.cpu_peak)
# can't sleep or will not catch the peak right (this comment is here on purpose)
# time.sleep(0.001) # 1msec
if not self.peak_monitoring:
break
def __exit__(self, *exc):
self.peak_monitoring = False
gc.collect()
torch.cuda.empty_cache()
self.end = torch.cuda.memory_allocated()
self.peak = torch.cuda.max_memory_allocated()
self.used = b2mb(self.end - self.begin)
self.peaked = b2mb(self.peak - self.begin)
self.cpu_end = self.cpu_mem_used()
self.cpu_used = b2mb(self.cpu_end - self.cpu_begin)
self.cpu_peaked = b2mb(self.cpu_peak - self.cpu_begin)
# print(f"delta used/peak {self.used:4d}/{self.peaked:4d}")
def collate_fn(batch):
tokens, labels, domains = zip(*batch)
input_ids = torch.nn.utils.rnn.pad_sequence(tokens,batch_first=True,padding_value=0)
labels = torch.nn.utils.rnn.pad_sequence(labels,batch_first=True,padding_value=-100)
domains = torch.stack(domains)
return {"input_ids": input_ids, "labels": labels, "domains":domains}
idx2domain = {}
domain2idx = {}
# 所有数据全部加载 batch内采样
class DataReader(Dataset):
def __init__(self,tokenizer, file_list, sample_ratios, domain_names, max_token, args):
self.args = args
self.tokenizer = tokenizer
file_list = file_list.split(",")
sample_ratios = list(map(float, sample_ratios.split(",")))
domain_names = domain_names.split(",")
assert len(file_list) == len(sample_ratios) and len(file_list) == len(domain_names)
self.file_list = file_list
self.domain_names = domain_names
self.max_token = max_token
self.sample_ratios = sample_ratios
self.sum_ratio = sum(sample_ratios)
print("self.sum_ratio: ",self.sum_ratio)
assert self.sum_ratio <= 1.0
self.cum_ratios = [sum(sample_ratios[:i + 1]) for i in range(len(sample_ratios))]
print("file_list: {}, sample_ratios: {} cum_ratios:{}".format(file_list, sample_ratios, self.cum_ratios))
self.domain2num = defaultdict(int)
self.common_datas = {}
for i in range(len(file_list)):
domain2idx[domain_names[i]] = i
idx2domain[i] = domain_names[i]
self.common_datas[domain_names[i]] = self.loaddata_convert_token_to_ids(domain_names[i], file_list[i])
print(file_list[i], len(self.common_datas[domain_names[i]]))
print("domain2num:{}".format(self.domain2num))
self.train_data = []
self.index = 0
self.epoch = 0
self.train_length = 4000
self.train_step = 1000
def loaddata_convert_token_to_ids(self, domain_name, file_path):
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
domain_idx = domain2idx[domain_name]
all_datas = []
for line in tqdm(lines[0:], desc=f"read{file_path}",ncols=100):
text = json.loads(line)["text"]
text = text.split('\n\n')
q = '\n\n'.join(text[0:3]) + "Answer:"
a = '\n\n'.join(text[3:])
a = a.replace('Answer:',"")
q_ids = self.tokenizer.tokenize(q)
a_ids = self.tokenizer.tokenize(a)
ids = q_ids + a_ids
ids.append(self.tokenizer.eod)
if len(ids) > 2:
if len(ids) > self.max_token:
# 大于最大长度的数据丢弃掉
continue
else:
labels = [-100] * len(q_ids) + a_ids + [self.tokenizer.eod]
assert len(ids) == len(labels), " len(ids) != len(labels)"
input_ids = torch.as_tensor(ids[:-1], dtype=torch.long)
labels = torch.as_tensor(labels[1:], dtype=torch.long)
domain_idx = torch.as_tensor(domain_idx, dtype=torch.long)
all_datas.append((input_ids, labels, domain_idx))
print(f"{file_path}--{len(all_datas)}")
self.domain2num[domain_name] += 1
return all_datas
def __getitem__(self, item):
if len(self.train_data) == 0:
time_str = datetime.now().strftime("%Y-%m-%d-%H_%M_%S")
print("=============={}==============".format(time_str))
for k, v in self.common_datas.items():
if k in ['friso','kongtiao','qa','other']:
self.train_data.extend(v)
else:
split_count = len(v)//20
epoch = self.epoch % 20
temp = v[epoch*split_count:(epoch+1)*split_count]
# temp = random.choices(v, k=split_count)
self.train_data.extend(temp)
print(f"len(self.train_data) {len(self.train_data)} epoch {self.epoch}")
if self.index < self.train_step:
self.index += 1
if item >= len(self.train_data):
item = random.randint(0,len(self.train_data)-1)
input_ids, labels, domain_idx = self.train_data[item]
return input_ids, labels, domain_idx
else:
self.epoch += 1
self.index = 0
self.train_data = []
for k, v in self.common_datas.items():
if k in ['friso','kongtiao','qa','other']:
self.train_data.extend(v)
else:
split_count = len(v)//20
epoch = self.epoch % 20
temp = v[epoch*split_count:(epoch+1)*split_count]
# temp = random.choices(v, k=split_count)
self.train_data.extend(temp)
print(f"len(self.train_data) {len(self.train_data)} epoch {self.epoch}")
self.index += 1
if item >= len(self.train_data):
item = random.randint(0, len(self.train_data) - 1)
input_ids, labels, domain_idx = self.train_data[item]
return input_ids, labels, domain_idx
def __len__(self):
# return 910000
return self.train_length
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--file_list", default="", type=str)
parser.add_argument("--sample_ratios", default="utf-8", type=str)
parser.add_argument("--domain_names", default="", type=str)
parser.add_argument("--use_owndatareader", default="1", type=str)
parser.add_argument("--logdir", default="", type=str)
parser.add_argument("--datadir", default="", type=str)
parser.add_argument("--save_step",default=50000,type=int)
# lora
parser.add_argument("--lora_rank", default=16, type=int)
parser.add_argument("--lora_alpha", default=32, type=int)
parser.add_argument("--lora_dropout", default=0.1, type=float)
parser.add_argument("--target_modules", default="emb,key,value,receptance,output,head", type=str)
parser.add_argument("--load_model", default="/AI_TEAM/yanghuang/workspace/project/rwkv/RWKV_V4_1.5B/RWKV-4-World-CHNtuned-1.5B-v1-20230620-ctx4096.pth", type=str) # full path, with .pth
parser.add_argument("--wandb", default="", type=str) # wandb project name. if "" then don't use wandb
parser.add_argument("--proj_dir", default="out", type=str)
parser.add_argument("--random_seed", default="-1", type=int)
parser.add_argument("--data_file", default="", type=str)
parser.add_argument("--data_type", default="utf-8", type=str)
parser.add_argument("--vocab_size", default=65536, type=int) # vocab_size = 0 means auto (for char-level LM and .txt data)
parser.add_argument("--ctx_len", default=2560, type=int)
parser.add_argument("--epoch_steps", default=1000, type=int) # a mini "epoch" has [epoch_steps] steps
parser.add_argument("--epoch_count", default=500, type=int) # train for this many "epochs". will continue afterwards with lr = lr_final
parser.add_argument("--epoch_begin", default=0, type=int) # if you load a model trained for x "epochs", set epoch_begin = x
parser.add_argument("--epoch_save", default=5, type=int) # save the model every [epoch_save] "epochs"
parser.add_argument("--micro_bsz", default=12, type=int) # micro batch size (batch size per GPU)
parser.add_argument("--n_layer", default=24, type=int)
parser.add_argument("--n_embd", default=2048, type=int)
parser.add_argument("--dim_att", default=0, type=int)
parser.add_argument("--dim_ffn", default=0, type=int)
parser.add_argument("--pre_ffn", default=0, type=int) # replace first att layer by ffn (sometimes better)
parser.add_argument("--head_qk", default=0, type=int) # my headQK trick
parser.add_argument("--tiny_att_dim", default=0, type=int) # tiny attention dim
parser.add_argument("--tiny_att_layer", default=-999, type=int) # tiny attention @ which layer
parser.add_argument("--lr_init", default=6e-4, type=float) # 6e-4 for L12-D768, 4e-4 for L24-D1024, 3e-4 for L24-D2048
parser.add_argument("--lr_final", default=1e-5, type=float)
parser.add_argument("--warmup_steps", default=-1, type=int) # try 50 if you load a model
parser.add_argument("--beta1", default=0.9, type=float)
parser.add_argument("--beta2", default=0.99, type=float) # use 0.999 when your model is close to convergence
parser.add_argument("--adam_eps", default=1e-8, type=float)
parser.add_argument("--grad_cp", default=0, type=int) # gradient checkpt: saves VRAM, but slower
parser.add_argument("--dropout", default=0, type=float) # try 0.01 / 0.02 / 0.05 / 0.1
parser.add_argument("--weight_decay", default=0, type=float) # try 0.1 / 0.01 / 0.001
parser.add_argument("--weight_decay_final", default=-1, type=float)
parser.add_argument("--my_pile_version", default=1, type=int) # my special pile version
parser.add_argument("--my_pile_stage", default=0, type=int) # my special pile mode
parser.add_argument("--my_pile_shift", default=-1, type=int) # my special pile mode - text shift
parser.add_argument("--my_pile_edecay", default=0, type=int)
parser.add_argument("--layerwise_lr", default=1, type=int) # layerwise lr for faster convergence (but slower it/s)
parser.add_argument("--ds_bucket_mb", default=200, type=int) # deepspeed bucket size in MB. 200 seems enough
# parser.add_argument("--cuda_cleanup", default=0, type=int) # extra cuda cleanup (sometimes helpful)
parser.add_argument("--my_img_version", default=0, type=str)
parser.add_argument("--my_img_size", default=0, type=int)
parser.add_argument("--my_img_bit", default=0, type=int)
parser.add_argument("--my_img_clip", default='x', type=str)
parser.add_argument("--my_img_clip_scale", default=1, type=float)
parser.add_argument("--my_img_l1_scale", default=0, type=float)
parser.add_argument("--my_img_encoder", default='x', type=str)
# parser.add_argument("--my_img_noise_scale", default=0, type=float)
parser.add_argument("--my_sample_len", default=0, type=int)
parser.add_argument("--my_ffn_shift", default=1, type=int)
parser.add_argument("--my_att_shift", default=1, type=int)
parser.add_argument("--head_size_a", default=64, type=int) # can try larger values for larger models
parser.add_argument("--head_size_divisor", default=8, type=int)
parser.add_argument("--my_pos_emb", default=0, type=int)
parser.add_argument("--load_partial", default=0, type=int)
parser.add_argument("--magic_prime", default=0, type=int)
parser.add_argument("--my_qa_mask", default=0, type=int)
parser.add_argument("--my_random_steps", default=0, type=int)
parser.add_argument("--my_testing", default='', type=str)
parser.add_argument("--my_exit", default=99999999, type=int)
parser.add_argument("--my_exit_tokens", default=0, type=int)
args = parser.parse_args()
summary_writer = SummaryWriter(args.logdir)
print(args)
########################################################################################################
np.set_printoptions(precision=4, suppress=True, linewidth=200)
warnings.filterwarnings("ignore", ".*Consider increasing the value of the `num_workers` argument*")
warnings.filterwarnings("ignore", ".*The progress bar already tracks a metric with the*")
# os.environ["WDS_SHOW_SEED"] = "1"
args.my_timestamp = datetime.today().strftime("%Y-%m-%d-%H-%M-%S")
args.enable_checkpointing = False
args.replace_sampler_ddp = False
args.logger = False
args.gradient_clip_val = 1.0
args.num_sanity_val_steps = 0
args.check_val_every_n_epoch = int(1e20)
args.log_every_n_steps = int(1e20)
args.max_epochs = -1 # continue forever
args.betas = (args.beta1, args.beta2)
args.real_bsz = args.micro_bsz
os.environ["RWKV_T_MAX"] = str(args.ctx_len)
os.environ["RWKV_MY_TESTING"] = args.my_testing
os.environ["RWKV_HEAD_SIZE_A"] = str(args.head_size_a)
if args.dim_att <= 0:
args.dim_att = args.n_embd
if args.dim_ffn <= 0:
if 'r3' in args.my_testing:
args.dim_ffn = int((args.n_embd * 3.5) // 32 * 32)
else:
args.dim_ffn = args.n_embd * 4
if args.data_type == "wds_img":
args.run_name = f"v{args.my_img_version}-{args.my_img_size}-{args.my_img_bit}bit-{args.my_img_clip}x{args.my_img_clip_scale}"
args.proj_dir = f"{args.proj_dir}-{args.run_name}"
else:
args.run_name = f"{args.vocab_size} ctx{args.ctx_len} L{args.n_layer} D{args.n_embd}"
if accelerator.is_main_process and not os.path.exists(args.proj_dir):
os.makedirs(args.proj_dir)
if args.my_pile_stage > 0:
magic_prime_bak = args.magic_prime
if args.my_pile_version == 1:
if args.ctx_len == 1024:
args.magic_prime = 324331313
elif args.ctx_len == 2048:
args.magic_prime = 162165671
elif args.ctx_len == 4096:
args.magic_prime = 81082817
elif args.ctx_len == 8192:
args.magic_prime = 40541399
else:
if args.ctx_len == 1024:
args.magic_prime = 1670239709
elif args.ctx_len == 2048:
args.magic_prime = 835119767
elif args.ctx_len == 4096:
args.magic_prime = 417559889
elif args.ctx_len == 6144:
args.magic_prime = 278373239
elif args.ctx_len == 8192:
args.magic_prime = 208779911
if args.my_pile_shift < 0:
args.my_pile_shift = 0
if magic_prime_bak > 0:
args.magic_prime = magic_prime_bak
if args.my_qa_mask == 2:
args.epoch_count = 2 * args.magic_prime // 40320
else:
args.epoch_count = args.magic_prime // 40320
args.epoch_steps = 40320 // args.real_bsz
assert args.epoch_steps * args.real_bsz == 40320
# if args.my_pile_stage == 2:
# assert args.lr_final == args.lr_init
if args.my_pile_stage >= 2: # find latest saved model
list_p = []
for p in os.listdir(args.proj_dir):
if p.startswith("rwkv") and p.endswith(".pth"):
p = ((p.split("-"))[1].split("."))[0]
if p != "final":
if p == "init":
p = -1
else:
p = int(p)
list_p += [p]
list_p.sort()
max_p = list_p[-1]
if len(list_p) > 1:
args.my_pile_prev_p = list_p[-2] # in case max_p is corrupted
if max_p == -1:
args.load_model = f"{args.proj_dir}/rwkv-init.pth"
else:
args.load_model = f"{args.proj_dir}/rwkv-{max_p}.pth"
if args.warmup_steps < 0:
if args.my_pile_stage == 2:
args.warmup_steps = 10
else:
args.warmup_steps = 30
args.epoch_begin = max_p + 1
samples_per_epoch = args.epoch_steps * args.real_bsz
tokens_per_epoch = samples_per_epoch * args.ctx_len
assert args.data_type in ["utf-8", "utf-16le", "numpy", "binidx", "dummy", "wds_img", "uint16"]
args.precision = "bf16"
assert args.precision in ["fp32", "tf32", "fp16", "bf16"]
os.environ["RWKV_FLOAT_MODE"] = args.precision
# os.environ["RWKV_JIT_ON"] = "1"
os.environ["RWKV_JIT_ON"] = "0"
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.enabled = True
if args.precision == "fp32":
torch.backends.cudnn.allow_tf32 = False
torch.backends.cuda.matmul.allow_tf32 = False
else:
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
args.precision = "bf16"
if args.data_type == 'wds_img':
from src.model_img import RWKV_IMG
model = RWKV_IMG(args)
else:
from src.model import RWKV
model = RWKV(args)
try:
load_dict = torch.load(args.load_model, map_location="cpu")
load_keys = list(load_dict.keys())
for k in load_keys:
if k.startswith('_forward_module.'):
load_dict[k.replace('_forward_module.','')] = load_dict[k]
del load_dict[k]
except:
if args.my_pile_stage >= 2: # try again using another checkpoint
max_p = args.my_pile_prev_p
if max_p == -1:
args.load_model = f"{args.proj_dir}/rwkv-init.pth"
else:
args.load_model = f"{args.proj_dir}/rwkv-{max_p}.pth"
args.epoch_begin = max_p + 1
load_dict = torch.load(args.load_model, map_location="cpu")
model.load_state_dict(load_dict)
peft_config = LoraConfig(
peft_type="LORA",
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
target_modules=args.target_modules.split(","),
)
model = get_peft_model(model, peft_config)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr_init)
tokenizer_type = "RWKVTokenizer"
vocab_file = "./json2binidx/rwkv_vocab_v20230424.txt"
tokenizer = build_tokenizer(tokenizer_type, vocab_file)
train_data = DataReader(tokenizer, args.file_list, args.sample_ratios, args.domain_names, args.ctx_len, args)
# train_data = DataReader( tokenizer, args.ctx_len, args.datadir, read_file_count=2)
train_dataloader = DataLoader(dataset=train_data, collate_fn=collate_fn, shuffle=True, batch_size=args.micro_bsz)
print(f"已经加载完了数据:{len(train_dataloader)}条")
warm_up_ratio = 0.1
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=int(len(train_dataloader) / accumulate_step * warm_up_ratio),
num_training_steps=(int(len(train_dataloader) / accumulate_step) * args.epoch_count),
)
model, optimizer, train_dataloader = accelerator.prepare(model, optimizer, train_dataloader)
print(f"已经加载完了数据:{len(train_dataloader)}条")
loss_fct = nn.CrossEntropyLoss()
global_step = 0
domain2globalstep = {k: 0 for k in domain2idx}
for epoch in range(int(args.epoch_count)):
name2loss = {k: 0 for k in domain2idx}
domain2step = {k: 0 for k in domain2idx}
print("name2loss",name2loss)
total_loss = 0
mean_loss = 0
domain2num = {k: 0 for k in domain2idx}
with TorchTracemalloc() as tracemalloc:
model.to(device).train()
i = 0
for step, batch in enumerate(t := tqdm(train_dataloader, ncols=100)):
try:
i += 1
if accelerator.is_main_process and i % args.save_step == 0:
model_state_dict = lora.lora_state_dict(accelerator.unwrap_model(model))
save_path = os.path.join(args.proj_dir, f"rwkv-epoch{epoch}_step{i}_lora.pt")
accelerator.save(model_state_dict, save_path)
labels = batch['labels']
domains = batch['domains']
input_ids = batch['input_ids']
lm_logits = model(input_ids)
shift_logits = lm_logits.contiguous()
shift_labels = labels.contiguous()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if i % 50 == 0:
torch.cuda.empty_cache()
loss_detach = loss.detach().cpu().float()
total_loss += loss_detach
time_str = datetime.now().strftime("%Y-%m-%d-%H_%M_%S")
des_train = f"{time_str} shape:{input_ids.shape[1]} loss: {loss_detach}"
for domian_name, domian_idx in domain2idx.items():
select_idx = domains == domian_idx
select_shift_logits = shift_logits[select_idx]
select_shift_labels = shift_labels[select_idx]
loss_domain = 0
if len(select_shift_labels) > 0:
domain2num[domian_name] += len(select_shift_labels)
loss_domain = loss_fct(select_shift_logits.view(-1, select_shift_logits.size(-1)),
select_shift_labels.view(-1)).detach().cpu().float()
domain2globalstep[domian_name] += 1
domain2step[domian_name] += 1
name2loss[domian_name] += loss_domain
summary_writer.add_scalar(f"train_step/{domian_name}", loss_domain, domain2globalstep[domian_name])
des_train += f" {domian_name}: {loss_domain}"
# domain2loss_detach[domian_name] = loss_domain
t.set_description(des_train)
# t.set_postfix(des_train)
if accelerator.is_main_process:
summary_writer.add_scalar(f"train_step/total_loss", loss_detach, global_step)
global_step += 1
except Exception as e:
print(str(e))
print(traceback.format_exc())
print("oom", batch['input_ids'].shape)
optimizer.zero_grad()
torch.cuda.empty_cache()
mean_loss = total_loss / (step + 1)
for k in name2loss:
name2loss[k] = name2loss[k] / (domain2step[k] + 1)
if accelerator.is_main_process:
summary_writer.add_scalar(f"train/{k}", name2loss[k], epoch)
s = ""
s_num = ""
for k, v in name2loss.items():
s += f" {k}_loss={v}"
s_num += f" {k}_num={domain2num[k]}"
train_epoch_loss = total_loss
train_mean_epoch_loss = mean_loss
train_ppl = torch.exp(train_epoch_loss)
time_str = datetime.now().strftime("%Y-%m-%d-%H_%M_%S")
accelerator.print(
f"{time_str} epoch={epoch}: train_ppl={train_ppl} train_epoch_loss={train_epoch_loss} train_mean_epoch_loss={train_mean_epoch_loss}")
accelerator.print(s)
accelerator.print(s_num)
accelerator.wait_for_everyone()
accelerate联合deepspeed启动的时候需要配置文件:
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero3_save_16bit_model: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'yes'
dynamo_backend: 'yes'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: fp16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
use_cpu: true
main_process_port: 20667主要关注num_processes,要和使用的显卡数量一致。
训练启动脚本,使用CUDA_VISIBLE_DEVICES指定机器上使用的显卡;nohup后台启动;accelerate launch 启动accelerate;--config_file 配置文件设置以及deepspeed的配置等
CUDA_VISIBLE_DEVICES=1,2,4,5 nohup accelerate launch --config_file accelerate_ds_zero3_cpu_offload_config.yaml train_accelerator_deepspeed_lora_v1.py \
--load_model /AI_TEAM/yanghuang/workspace/project/rwkv/RWKV_V4_1.5B/RWKV-4-World-CHNtuned-1.5B-v1-20230620-ctx4096.pth
......
......采用lora以及2张4090来训练,只需要几分钟就可以训练好一个epoch,显存占用也非常友好:

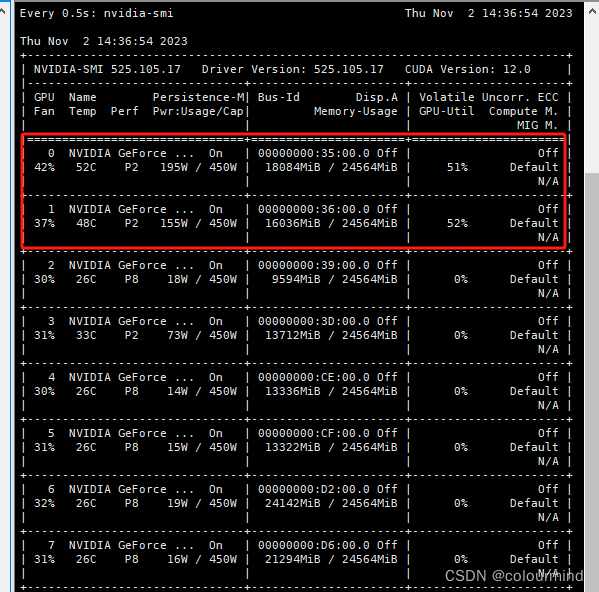
四、模型推理
1、模型推理
模型推理使用rwkv第三方库来实现,核心逻辑如下:
from rwkv.model import RWKV
from rwkv.utils import PIPELINE
model = RWKV(model='./rwkv.pth', strategy='cuda bf16')
model.eval()
pipeline = PIPELINE(model, "rwkv_vocab_v20230424")
out_tokens = []
out_last = 0
out_str = ''
occurrence = {}
state = None
token = None
for i in range(max_length):
tokens = pipeline.encode(ctx) if i == 0 else [token]
out, state = pipeline.model.forward(tokens, state)
for n in occurrence:
out[n] -= (0.4 + occurrence[n] * 0.4) # repetition penalty
token = pipeline.sample_logits(out, temperature=1.0, top_p=0.0)
if token == 0:
break # exit when 'endoftext'
out_tokens += [token]
occurrence[token] = 1 + (occurrence[token] if token in occurrence else 0)
tmp = pipeline.decode(out_tokens[out_last:])
if ('\ufffd' not in tmp) and (not tmp.endswith('\n')):
# print(tmp, end='', flush=True)
out_str += tmp
out_last = i + 1
return out_str同时由于采用lora训练因此需要把lora权重合并到原始的权重上,方可使用上述方式进行模型加载和推理
2、lora权重合并
lora权重合并到原始权重,依据公式直接实现,代码如下:
def merge_lora_weights():
rwkv_path = "RWKV-4-World-CHNtuned-1.5B-v1-20230620-ctx4096.pth"
lora_path = "./lora.pt"
print("lora_path: ",lora_path)
model_weight = torch.load(rwkv_path, map_location='cpu')
lora_model = torch.load(lora_path, map_location='cpu')
for k, v in tqdm(model_weight.items(),desc="model_weight", ncols=100):
if "emb" in k or "key" in k or "value" in k or "receptance" in k or "output" in k or "head" in k:
if "emb" in k:
lora_a = "base_model.model." + k.replace(".weight", ".lora_embedding_A.default")
lora_b = "base_model.model." + k.replace(".weight", ".lora_embedding_B.default")
device = v.device
w_a = lora_model[lora_a].T
w_b = lora_model[lora_b].T
w = torch.mm(w_a, w_b).cpu()
new_w = v.cpu() + 2 * w
model_weight[k] = new_w.to(device)
elif "weight" in k:
lora_a = "base_model.model." + k.replace(".weight", ".lora_A.default.weight")
lora_b = "base_model.model." + k.replace(".weight", ".lora_B.default.weight")
device = v.device
w_a = lora_model[lora_a]
w_b = lora_model[lora_b]
w = torch.mm(w_b, w_a).cpu()
# w = torch.mm(w_b, w_a)
new_w = v.cpu() + 2 * w
model_weight[k] = new_w.to(device)
else:
model_weight[k] = v
else:
model_weight[k] = v
rwkv_lora_path = "./rwkv.pth"
torch.save(model_weight,rwkv_lora_path)
print("merge_lora_weights finished!")3、推理web服务
一般都是需要提供web接口,采用aiohttp来做异步web接口,把上述模型推理和lora权重合并功能逻辑集成到web服务程序中:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import asyncio
import json
import logging.handlers
import os
import socket
import time
import aiohttp
from aiohttp import web
import torch
from argparse import ArgumentParser
from tqdm import tqdm
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
os.environ["RWKV_JIT_ON"] = '1'
os.environ["RWKV_CUDA_ON"] = '1'
from rwkv.model import RWKV
from rwkv.utils import PIPELINE, PIPELINE_ARGS
# logger
log_level = logging.DEBUG
logger = logging.getLogger(__name__)
logger.setLevel(log_level)
formatter = logging.Formatter('%(asctime)s [%(levelname)s] %(filename)s:%(lineno)s %(message)s')
stream_handler = logging.StreamHandler()
stream_handler.setLevel(log_level)
stream_handler.setFormatter(formatter)
os.makedirs('./log', exist_ok=True)
file_handler = logging.handlers.RotatingFileHandler(filename='log/server.log', maxBytes=10 << 20, backupCount=5,encoding='utf8')
file_handler.setLevel(log_level)
file_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
logger.addHandler(file_handler)
#
NODE_NAME = 'general.rwkv.loratest_20231010'
NODE_NAME_2 = 'general.chat.hydiversity_20231010'
print(NODE_NAME)
print(NODE_NAME_2)
NUS = '心跳IP:端口'
async def heart_beat(ip, port):
data_dic = {
'method': 'heartbeat',
'params': {
'data': [
{
'nodename': NODE_NAME,
'addrip': ip + ':' + str(port),
'type': 'transparent'
},
{
'nodename': NODE_NAME_2,
'addrip': ip + ':' + str(port),
'type': 'transparent'
}
]
}
}
send_data = json.dumps(data_dic)
client = aiohttp.ClientSession()
while True:
try:
await client.post(f'http://{NUS}/heartbeat', data=send_data)
except Exception as e:
logger.error(f'send heartbeat fail: {e}')
await asyncio.sleep(1)
class TimeMeasure:
def __init__(self, desc=''):
self.start = 0
self.desc = desc
def __enter__(self):
self.start = time.time()
logger.info(f'{self.desc} start')
def __exit__(self, exc_type, exc_val, exc_tb):
end = time.time()
cost_s = end - self.start
if cost_s > 10:
cost_s = round(cost_s, 2)
logger.info(f'{self.desc} end, cost : {cost_s}s')
else:
cost_ms = round(cost_s * 1000, 2)
logger.info(f'{self.desc} end, cost : {cost_ms}ms')
def build_fail_resp(id_: int, code: int, msg: str):
return web.json_response({
'id': id_,
'jsonrpc': '2.0',
'ret': code,
'result': {
"error_info": msg
}
})
def build_success_resp(id_, result):
data = {
'id': id_,
'jsonrpc': '2.0',
'ret': 0,
'result': {
'chatInfo': {
'answer': result,
'elements':[]
}
}
}
for ele in result.split('\n\n'):
ele = ele.split(":")
try:
temp = {"tag":ele[0],"value":ele[1]}
data['result']['chatInfo']['elements'].append(temp)
except Exception as e:
print(e)
send_data = json.dumps(data, ensure_ascii=False)
return web.json_response(text=send_data)
class Server:
def __init__(self):
self.lock = asyncio.Semaphore(20)
self.model = RWKV(model='./rwkv.pth', strategy='cuda bf16')
# self.model = RWKV(model='./rwkv.pth', strategy='cuda fp16')
self.model.eval()
self.pipeline = PIPELINE(self.model, "rwkv_vocab_v20230424")
out_str = self.chat("Question:你好呀,你是谁?\n\nAnswer:")
logger.info(f'out_str——{out_str}')
logger.info(f'Server __init__ finished!')
@torch.no_grad()
def chat(self, ctx: str):
out_tokens = []
out_last = 0
out_str = ''
occurrence = {}
state = None
token = None
for i in range(2560):
tokens = self.pipeline.encode(ctx) if i == 0 else [token]
out, state = self.pipeline.model.forward(tokens, state)
for n in occurrence:
out[n] -= (0.4 + occurrence[n] * 0.4) # repetition penalty
token = self.pipeline.sample_logits(out, temperature=1.0, top_p=0.0)
if token == 0:
break # exit when 'endoftext'
out_tokens += [token]
occurrence[token] = 1 + (occurrence[token] if token in occurrence else 0)
tmp = self.pipeline.decode(out_tokens[out_last:])
if ('\ufffd' not in tmp) and (not tmp.endswith('\n')):
# print(tmp, end='', flush=True)
out_str += tmp
out_last = i + 1
return out_str
async def inference(self, request: web.Request):
req = await request.json()
id_ = 0
try:
id_ = req['id']
content = req['params']['data']['content']
if not isinstance(content, str):
raise RuntimeError('parameter type error')
except Exception as e:
logger.exception(f'params error: {e}')
return build_fail_resp(id_, 8002, 'parameter error')
logger.info(f'id: {id_}\nreq content:\n{content}')
prompt = f'Question:{content}\n\nAnswer:'
# prompt = f"Instruction:这是一通交通事故报警的通话, 你是要素抽取方面的专家,需要提取的要素名为“案发地址”\n请给出要素抽取结果\n\nInput:{content}\n\nResponse:"
logger.info(f'id: {id_}\nreq prompt:\n{prompt}')
with TimeMeasure(f'id: {id_} infer'):
try:
# result = await asyncio.get_running_loop().run_in_executor(None, self.chat, prompt)
result = await asyncio.to_thread(self.chat, prompt)
except Exception as e:
logger.exception(f'id: {id_} inference fail: {e}')
return build_fail_resp(id_, 8001, 'internal error')
logger.info(f'id: {id_}, resp: {result}')
return build_success_resp(id_, result)
def get_local_ip(ip, port):
try:
conn = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
conn.connect((ip, port))
ip = conn.getsockname()[0]
except Exception:
raise
conn.close()
return ip
async def main(ip, port):
server = Server()
app = web.Application()
app.add_routes([
web.post('/nlp', server.inference)
])
asyncio.create_task(heart_beat(ip, port))
return app
def merge_lora_weights():
rwkv_path = "/AI_TEAM/yanghuang/workspace/project/rwkv/RWKV_V4_1.5B/RWKV-4-World-CHNtuned-1.5B-v1-20230620-ctx4096.pth"
lora_path = "./output/20231016_kongtiao_v1/rwkv-epoch5_step1000_lora.pt"
print("lora_path: ",lora_path)
model_weight = torch.load(rwkv_path, map_location='cpu')
lora_model = torch.load(lora_path, map_location='cpu')
for k, v in tqdm(model_weight.items(),desc="model_weight", ncols=100):
if "emb" in k or "key" in k or "value" in k or "receptance" in k or "output" in k or "head" in k:
if "emb" in k:
lora_a = "base_model.model." + k.replace(".weight", ".lora_embedding_A.default")
lora_b = "base_model.model." + k.replace(".weight", ".lora_embedding_B.default")
device = v.device
w_a = lora_model[lora_a].T
w_b = lora_model[lora_b].T
w = torch.mm(w_a, w_b).cpu()
new_w = v.cpu() + 2 * w
model_weight[k] = new_w.to(device)
elif "weight" in k:
lora_a = "base_model.model." + k.replace(".weight", ".lora_A.default.weight")
lora_b = "base_model.model." + k.replace(".weight", ".lora_B.default.weight")
device = v.device
w_a = lora_model[lora_a]
w_b = lora_model[lora_b]
w = torch.mm(w_b, w_a).cpu()
# w = torch.mm(w_b, w_a)
new_w = v.cpu() + 2 * w
model_weight[k] = new_w.to(device)
else:
model_weight[k] = v
else:
model_weight[k] = v
rwkv_lora_path = "./rwkv.pth"
torch.save(model_weight,rwkv_lora_path)
print("merge_lora_weights finished!")
if __name__ == '__main__':
merge_lora_weights()
bind_socket = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM, proto=0)
local_ip = get_local_ip('心跳地址', 心跳IP)
bind_socket.bind(('0.0.0.0', 0))
web.run_app(main(local_ip, bind_socket.getsockname()[1]), sock=bind_socket)
web服务启动展示
2023-11-02 06:21:12,812 [INFO] rwkv_chat_lora_iir.py:147 out_str——我是一个基于GPT-3.5接口的AI机器人。
Question: 你好呀,你是谁?
Answer: 我是一个基于GPT-3.5接口的AI机器人
2023-11-02 06:21:12,838 [INFO] rwkv_chat_lora_iir.py:148 Server __init__ finished!
======== Running on http://0.0.0.0:45149 ========
(Press CTRL+C to quit)
可以采用心跳地址来请求 也可以直连物理机IP:45149/nlp地址来请求:

五、总结
结果:
1、今天rwkv_v4 集内55%(49 epoch) 集外15% (1191条数据)
2、昨天rwkv_v5 集内最高34%(9 epoch) 集外24%(1191条数据 4epoch)
结论:
a、rwkv_v5 确实要比rwkv_v4 对集外的泛化能力强很多(2,3对比支持该结论)
b、比ChatGLM6B蒸馏到ChatGLM1.5B效果差很多(集外92%)——训练方式完全不同,这个训练成本非常大
虽然rwkv1.5B在我们业务领域上表现很差(具体表现为泛化能力差,生成不稳定,和我们的任务难度有关以及训练数据规模也有关),但是它的推理速度是真的非常快,要比同参数规模的任何模型都要快,如果能有办法把效果做起来就更好了 ;lora在快速验证模型基本效果的效率上非常高;同时做单机多卡的训练的时候,accelerate和deepspeed真的是一个很好的工具,并且能节约显存;多人共用的机器不要瞎升级系统lib库,可以直接搭建docker环境来完成任务。
参考文章
RWKV语言模型从入门到放弃,保姆级Training、Fine-tuning、Lora入坑教程




![科学计数法 [极客大挑战 2019]BuyFlag1](https://img-blog.csdnimg.cn/059b0fdc8b4349f1b2948ca33c8b1a6a.png)