
文章目录
- Abstract
- Introduction
- 过去工作存在的不足
- 我们的工作
- 主要贡献(待参考)
- Related work
- CNN
- ViT, MLP, and variants
- Design of PConv and FasterNet
- Preliminary
- Partial convolution as a basic operator
- PConv followed by PWConv
- FasterNet as a general backbone
- Experimental Results
- PConv is fast with high FLOPS
- PConv is effective together with PWConv
- FasterNet on ImageNet-1k classification
- FasterNet on downstream tasks
- Ablation study
- Conclusion
论文链接
源代码
Abstract
为了设计快速的神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,我们观察到FLOPs的这种减少并不一定会导致类似程度的延迟减少。这主要源于低效率的每秒浮点操作数(FLOPS)。为了实现更快的网络,我们回顾了流行的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,特别是深度卷积。
因此,我们提出了一种新的部分卷积(PConv),通过减少冗余计算和同时存储访问,更有效地提取空间特征。在我们的PConv的基础上,我们进一步提出了FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他神经网络更高的运行速度,而不会影响各种视觉任务的准确性
例如,在ImageNet- 1k上,我们的微型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT-XXS快2.8倍、3.3倍和2.4倍,同时准确率提高2.9%。我们的大型fastnet - L实现了令人印象深刻的83.5%的top-1精度,与新兴的swing - b相当,同时在GPU上具有更高的36%的参考吞吐量,以及在CPU上节省37%的计算时间
Introduction
神经网络在图像分类、检测和分割等计算机视觉任务中得到了迅速的发展
研究人员和实践者不需要更昂贵的计算设备,他们更愿意设计具有成本效益的快速神经网络,并降低计算复杂性,主要是通过计算节点的数量来衡量浮点运算数(FLOPs)
过去工作存在的不足
MobileNets、ShuffleNets和GhostNet等利用深度卷积(DWConv)[55]和/或群卷积(GConv)[31]提取空间特征。然而,在努力减少FLOPs的过程中,操作符往往会受到内存访问增加的副作用的影响。MicroNet进一步分解和稀疏网络,将其FLOPs推至极低的水平。尽管在FLOPs方面有所改进,但这种方法的碎片计算效率很低。此外,上述网络通常伴随着额外的数据操作,例如串联, shuffling, and pooling,而运行时间对于小型模型来说往往很重要
除了上述纯卷积神经网络(cnn)之外,人们对Vision Transformer(vit)和多层感知器(mlp)架构越来越感兴趣。例如,MobileViTs[48,49,70]和MobileFormer[6]通过将DWConv与改进的注意力机制相结合来降低计算复杂度,然而,它们仍然受到DWConv的上述问题的困扰,并且还需要为修改后的注意力机制提供专用的硬件支持,使用高级但耗时的规范化和激活层也可能限制它们在设备上的速度
所有这些问题一起导致了以下问题:这些“快速”神经网络真的快吗?为了回答这个问题,我们检查延迟和FLOPs之间的关系,这是由:

即 延迟 等于 浮点运算次数 除以 每秒浮点操作数
FLOPS是每秒浮点操作数的缩写,用来衡量有效的计算速度。虽然有许多减少FLOPs的尝试,但他们很少考虑同时优化FLOPS以实现真正的低延迟。为了更好地理解这种情况,我们比较了典型的神经网络在英特尔CPU上的FLOPS。图2的结果显示,许多现有的神经网络FLOPS都很低,它们的FLOPS普遍低于流行的ResNet50。由于FLOPS如此之低,这些“快速”的神经网络实际上还不够快,它们在FLOPs上的减少不能转化为延迟减少的确切数量。在某些情况下,没有任何改进,甚至会导致更糟的延迟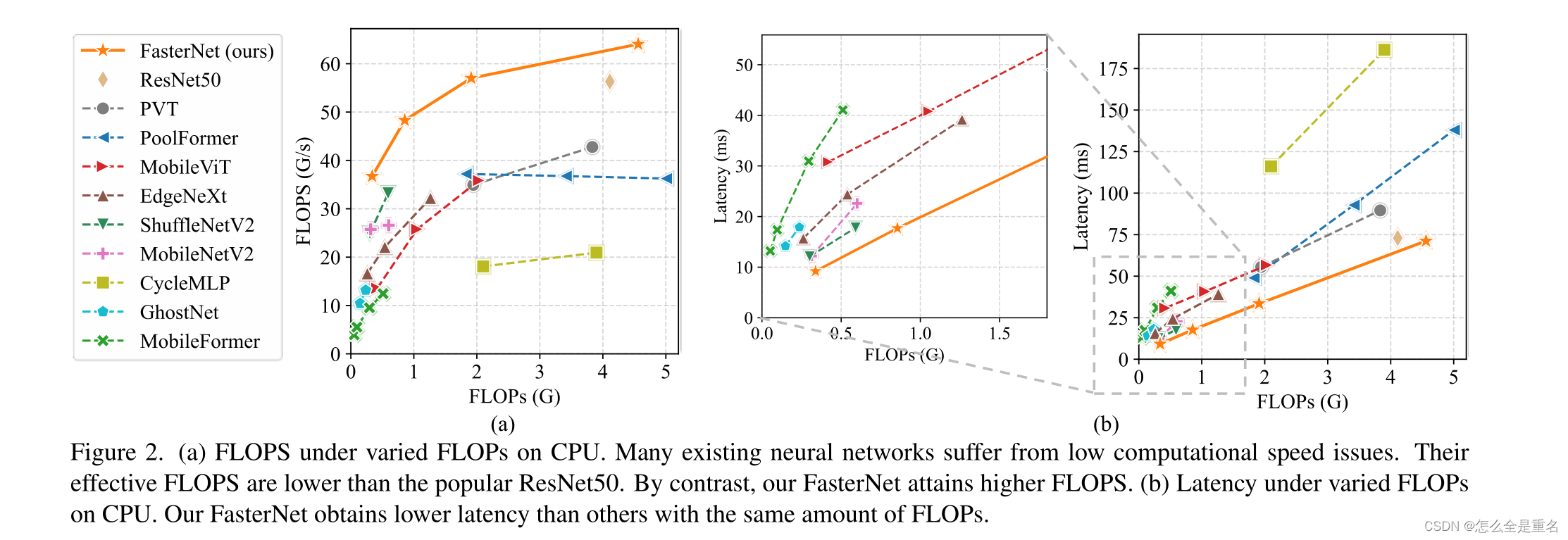
(a) CPU上不同FLOPs下的FLOPS。许多现有的神经网络都存在计算速度低的问题。它们的有效FLOPS低于流行的ResNet50。相比之下,我们的fastnet获得更高的FLOPS。(b) CPU不同FLOPs下的时延。我们的FasterNet获得比其他相同数量的FLOPs更低的延迟
我们的工作
本文旨在通过开发一种简单、快速、有效的运算符来消除这种差异,该运算符可以在减少FLOPs的情况下保持高FLOPS。具体来说,我们在计算速度方面- FLOPS重新审视了现有的运算符,特别是DWConv,。我们发现导致低FLOPS问题的主要原因是频繁的内存访问
然后,我们提出了一种新的部分卷积(PConv)作为一种有竞争力的替代方案,减少了计算冗余以及内存访问的数量。图1展示了我们的PConv的设计。它利用特征映射中的冗余性,系统地对部分输入通道应用常规卷积(Conv),而其余的通道保持不变。从本质上讲,PConv比常规Conv具有更低的FLOPs,而比DWConv/GConv具有更高的FLOPS。换句话说,PConv更好地利用了设备上的计算能力。PConv在提取空间特征方面也很有效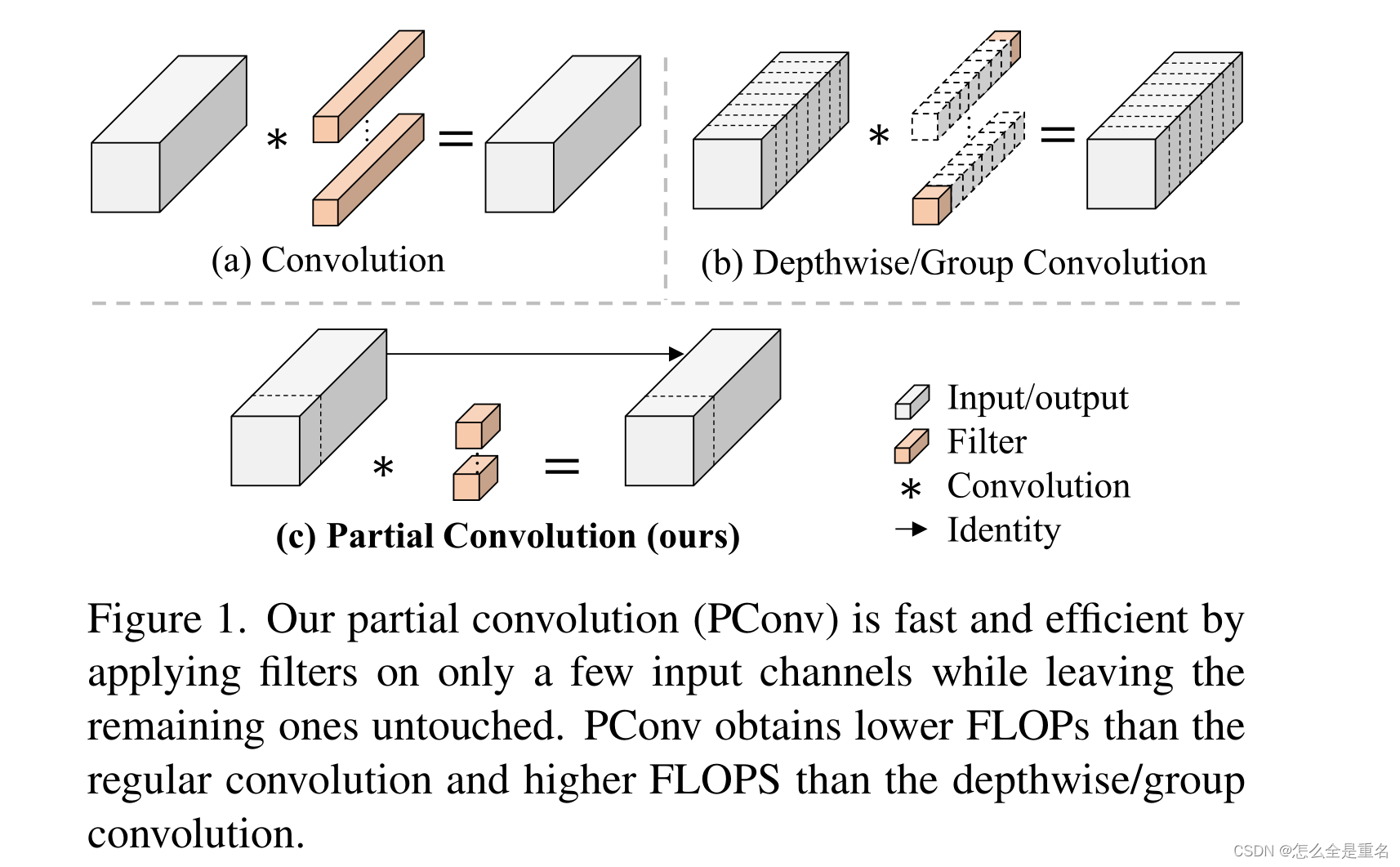
(我们的部分卷积(PConv)是快速和高效的,它只对少数几个输入通道应用滤波器,而其余的通道保持不变。PConv获得比常规卷积更低的FLOPs,比深度/群卷积更高的FLOPS)
我们进一步介绍FasterNet,它主要建立在我们的PConv之上,作为一个在各种设备上运行速度非常快的新网络系列。特别是,我们的FasterNet在分类、检测和分割任务方面实现了最先进的性能,同时具有更低的延迟和更高的吞吐量
主要贡献(待参考)
我们指出了实现更高的FLOPS的重要性,而不是简单地降低更快的神经网络的FLOPs
我们介绍了一种简单、快速、有效的操作方法PConv,它有很大的潜力取代现有的首选方法DWConv
我们推出的FasterNet运行有利和普遍快速的各种设备,如GPU, CPU和ARM处理器
我们对各种任务进行了广泛的实验,并验证了我们的PConv和FasterNet的高速度和有效性
Related work
我们简要回顾了之前关于快速和高效神经网络的研究工作,并将其与它们区分开来
CNN
cnn是计算机视觉领域的主流架构,群卷积和深度可分卷积已广泛应用于移动/边缘网络。虽然它们利用滤波器中的冗余来减少参数和FLOPs的数量,但当增加网络带宽以补偿精度下降时,它们会增加内存访问。相比之下,我们考虑了特征映射中的冗余性,并提出了部分卷积来同时减少FLOPs和内存访问
ViT, MLP, and variants
自从Transformer从机器翻译或预测扩展到计算机视觉领域以来,人们对ViT的研究越来越感兴趣。一个值得注意的趋势是通过降低注意力算子的复杂性,将卷积合并到ViTs,或两者兼顾来追求更好的准确性和延迟权衡
在本文中,我们重点分析卷积操作,特别是DWConv,原因如下:首先,注意力相对于卷积的优势尚不清楚或有争议。其次,基于注意力的机制通常比卷积机制运行得慢,因此对当前行业不太有利。最后,在许多混合动力车型中,DW- Conv仍然是一个流行的选择,因此值得仔细研究
Design of PConv and FasterNet
在本节中,我们首先回顾DWConv并分析其频繁内存访问的问题。然后,我们引入PConv作为一个有竞争力的替代运算符来解决这个问题。之后,我们将介绍fastnet并解释其细节,包括设计注意事项。
Preliminary
DWConv是Conv的一种流行变体,已被广泛采用为许多神经网络的关键构建块。对于输入I∈R c×h×w, DWConv应用c个过滤器W∈R k×k来计算输出O∈R c×h×w。如图1(b)所示,每个滤波器在一个输入通道上空间滑动,并贡献一个输出通道。与具有h × w × k² × c²的常规Conv相比,这种深度计算使得DWConv具有较慢的FLOPs,为h × w × k² × c。虽然DWConv(通常后跟逐点卷积或PWConv)可以有效地减少FLOPs,但不能简单地用于取代常规Conv,因为它会导致严重的精度下降。因此,在实践中,DWConv的通道数c(或网络宽度)增加到c ’ (c ’ > c)补偿精度下降,例如,将倒转残块[54]中的DWConv的宽度扩大6倍。然而,这会导致更高的内存访问,这可能导致不可忽略的延迟,并降低整体计算速度,特别是对于I/ o绑定设备。特别是,内存访问的数量现在升级到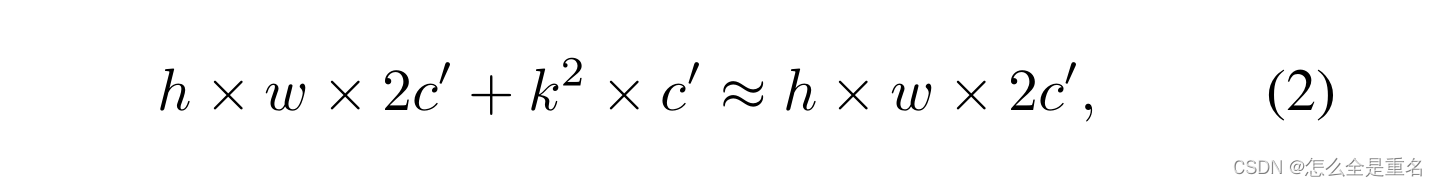
这比普通的Conv都要高(c ’ > c)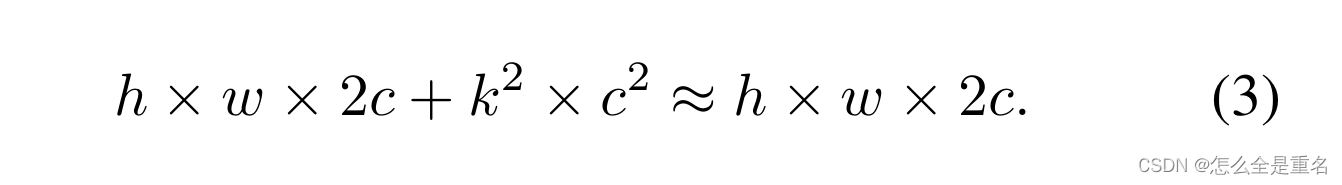
请注意,h×w×2c '内存访问花费在I/O操作上,这被认为已经是最小的成本,并且很难进一步优化
Partial convolution as a basic operator
下面我们将演示利用特征映射的冗余可以进一步优化成本。如图3所示,不同通道之间的特征映射具有很高的相似性

(以左上角的图像作为输入,在预训练的ResNet50的中间层中可视化特征地图。定性地说,我们可以看到不同渠道之间的高冗余)
具体来说,我们提出了一个简单的PConv来同时减少计算冗余和内存访问。图4的左下角说明了我们的PConv是如何工作的
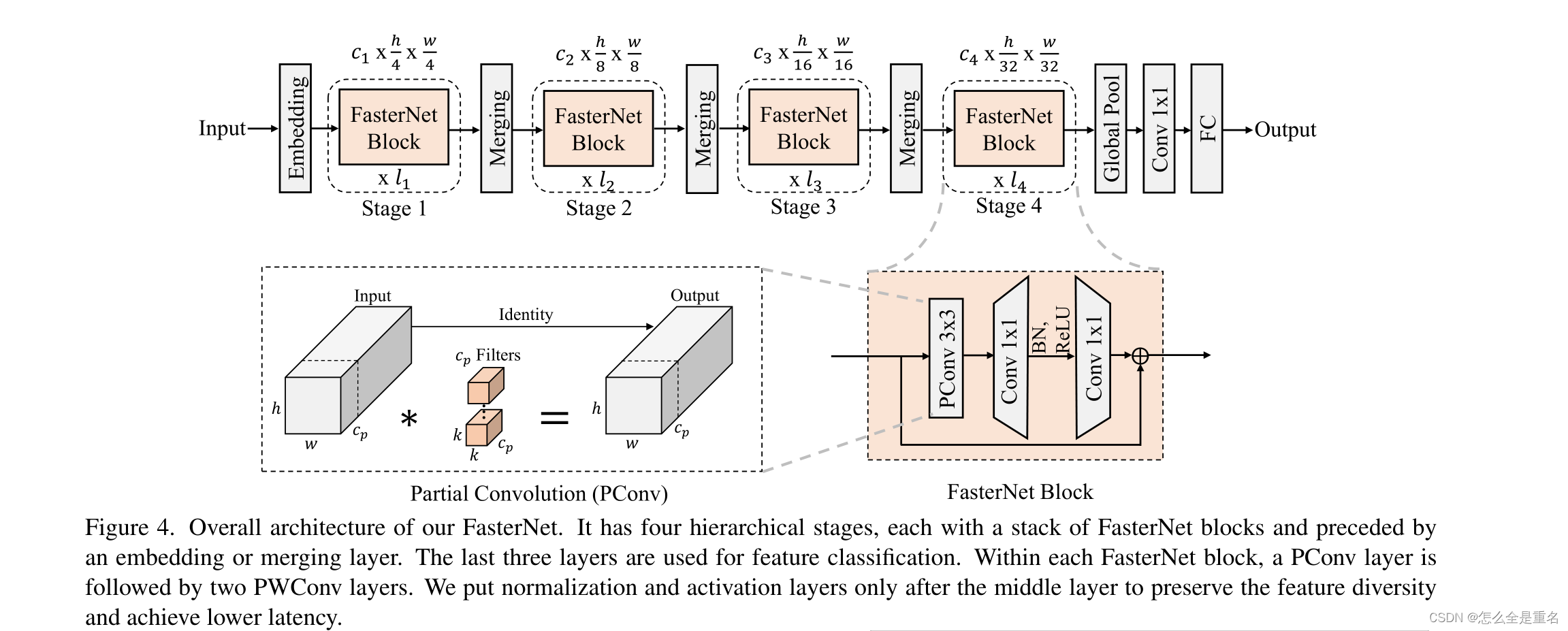
(我们fastnet的整体架构。它有四个分层阶段,每个阶段都有一堆FasterNet块,前面有一个嵌入或合并层。最后三层用于特征分类。在每个fastnet块中,一个PConv层后面跟着两个PWConv层。我们将归一化层和激活层放在中间层之后,以保持特征的多样性并实现较低的延迟)
它只对部分输入通道应用常规的Conv进行空间特征提取,其余通道保持不变。对于连续或常规的内存访问,我们将第一个或最后一个连续的cp通道作为整个特征映射的代表进行计算**。在不损失通用性的情况下,我们认为输入和输出特征映射具有相同数量的通道**。因此,PConv的FLOPs只有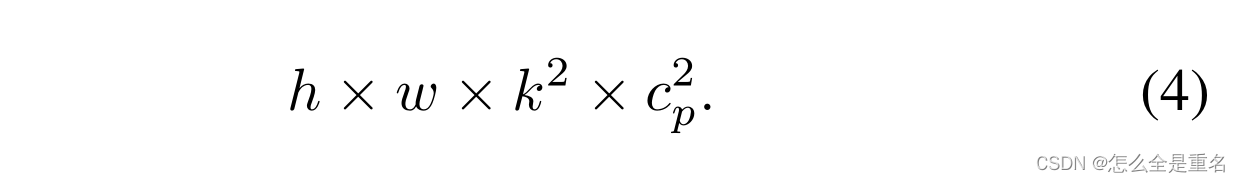
在典型的部分比率r = cp / c = 1/4时,PConv的FLOPs仅为普通Conv的1 / 16。此外,PConv具有更小的内存访问量,即
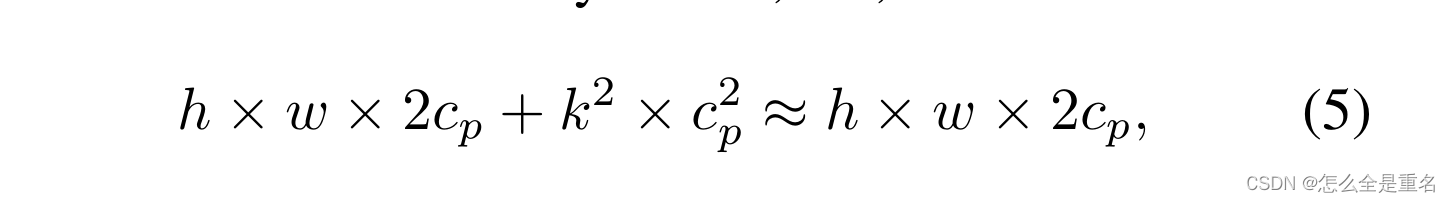
由于只有cp通道用于空间特征提取,有人可能会问,我们是否可以简单地删除剩余的(c−c p)通道?如果是这样,PConv将退化为具有更少通道的常规Conv,这偏离了我们减少冗余的目标。请注意,我们保持剩余的通道不变,而不是从特征映射中删除它们。这是因为它们对于后续的pwv层是有用的,它允许特征信息通过所有通道流动
PConv followed by PWConv
为了充分有效地利用来自所有通道的信息,我们进一步在PConv上附加了一个** pointwise convolution逐点卷积(PWConv)。它们共同在输入特征图上的有效接受场看起来像一个T形的Conv**,与均匀处理一个patch的规则Conv相比,它更关注中心位置,如图5所示。为了证明这个T形接受野的合理性,我们首先通过计算位置相关的Frobenius norm来评估每个位置的重要性。我们假设,如果一个位置比其他位置具有更大的Frobenius规范,那么它往往更重要。
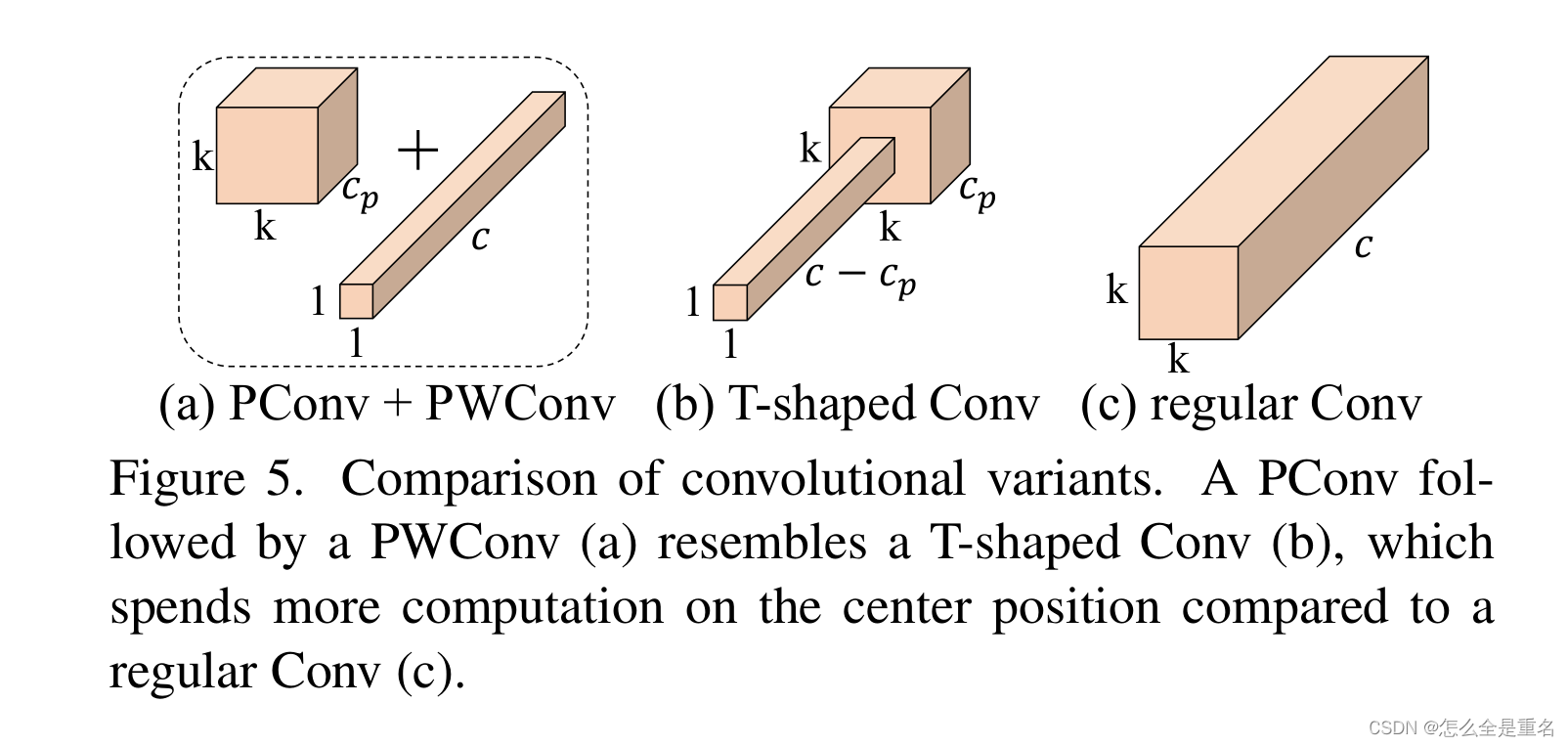
(卷积变体的比较。PConv后面跟着PWConv (A),类似于T形Conv (b),与常规Conv ©相比,它在中心位置上花费更多的计算)
我们认为显著位置是具有最大Frobenius规范的位置。然后,我们在预训练的ResNet18中共同检查每个过滤器,找出它们的显著位置,并绘制显著位置的直方图。从图6的结果可以看出,中心位置是滤波器中出现频率最高的突出位置,换句话说,中心位置的权重比它周围的邻居更大,这与集中在中心位置的t形计算一致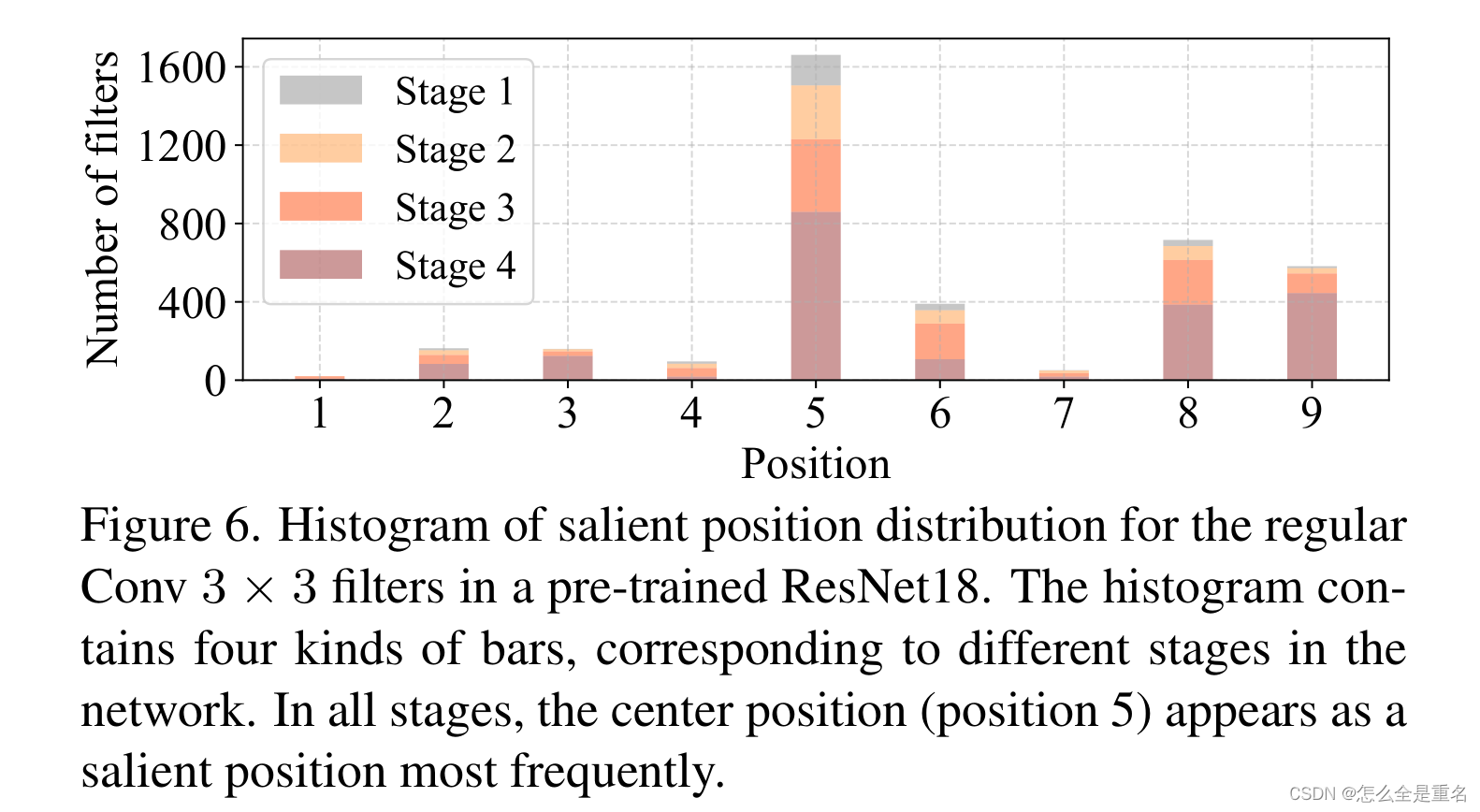
(正则Conv 3 × 3滤波器在预训练的ResNet18中的显著位置分布直方图。直方图包含四种柱状图,分别对应网络的不同阶段。在所有阶段中,中心位置(位置5)作为突出位置出现的频率最高)
虽然t形Conv可以直接用于高效计算,但我们表明将t形Conv分解为PConv和PWConv更好,因为分解利用了滤波器间冗余并进一步节省了FLOPs。对于相同的输入I∈R c×h×w,输出O∈R c×h×w, t形Conv的FLOPs可以计算为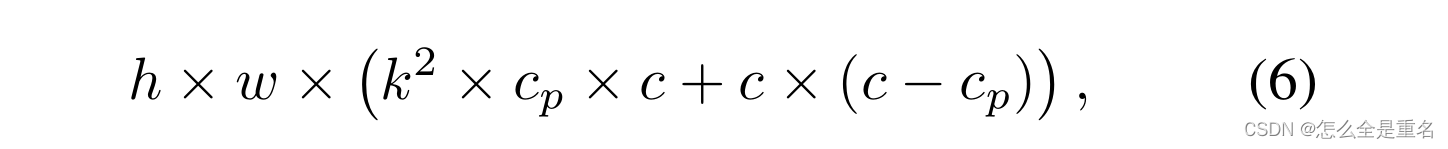
这比PConv和PWConv的FLOPs要高
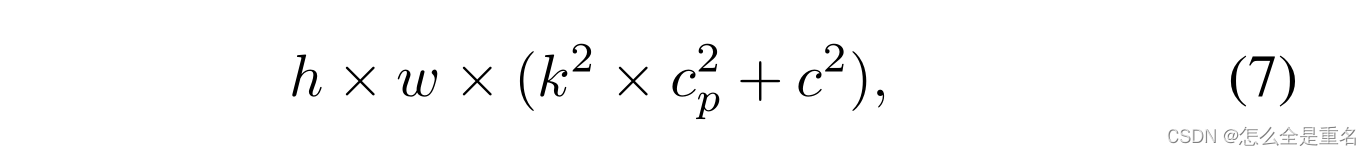
式中(k²−1)c > k²cp.此外,我们可以很容易地利用常规的Conv进行两步实现
FasterNet as a general backbone
我们在图4中展示了整体架构。它有四个分层阶段,每个阶段之前都有一个嵌入层(一个常规的Conv 4 × 4,步幅4)或一个合并层(一个常规的Conv 2 × 2,步幅2),用于空间下采样和通道数扩展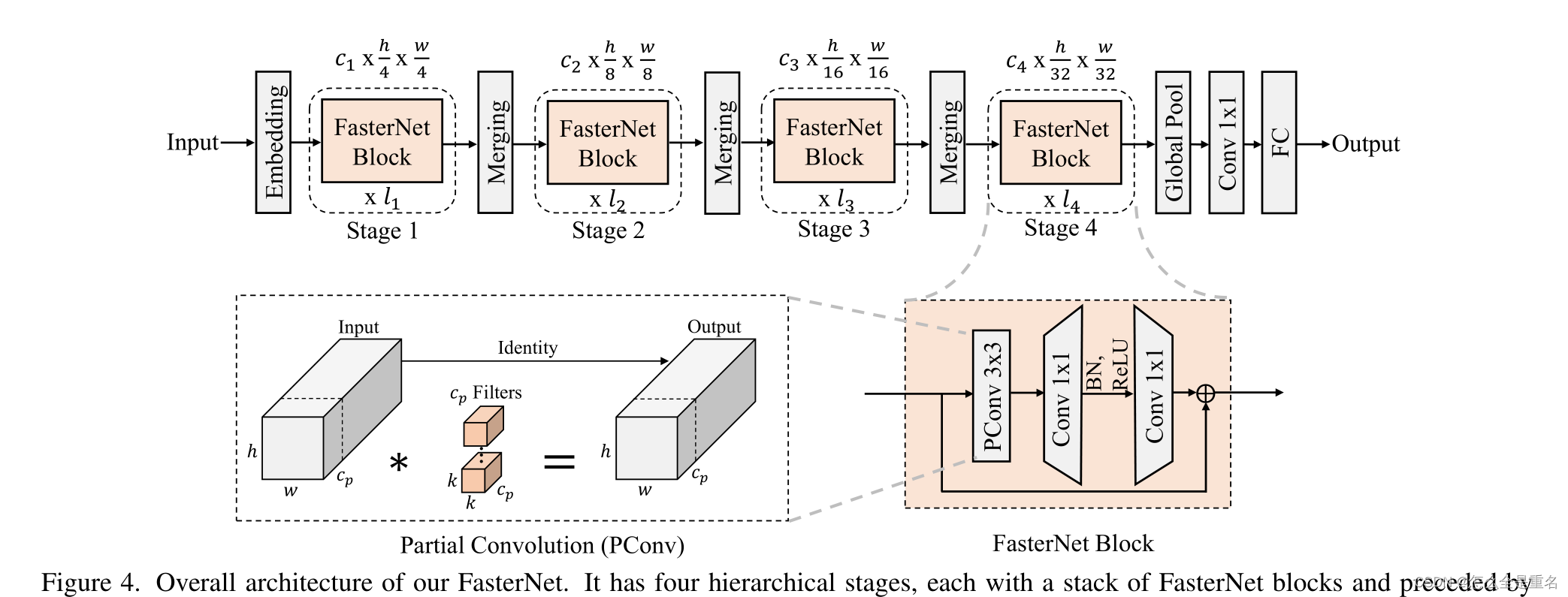
每个阶段都有一堆FasterNet块。我们观察到,最后两个阶段的块消耗较少的内存访问,并且倾向于具有更高的FLOPS,如表1中经验验证的那样。因此,我们放置了更多的fastnet块,并相应地在最后两个阶段分配了更多的计算。每个FasterNet块都有一个PConv层,然后是两个PWConv(或Conv 1 × 1)层,它们一起呈现为倒置的残差块,其中中间层具有扩展的通道数量,并且放置了一个快捷连接以重用输入特征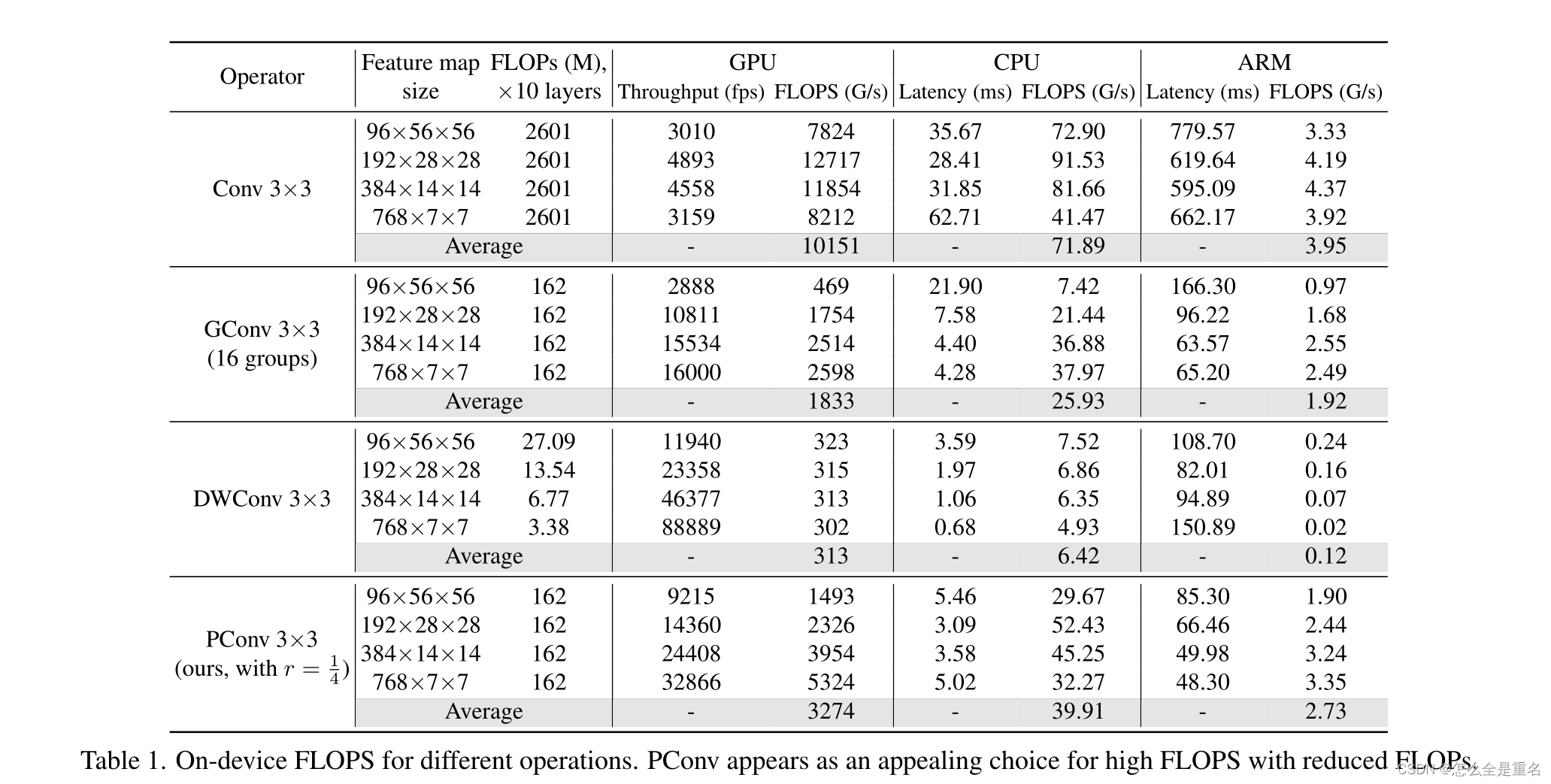
除了上述算子之外,对于高性能的神经网络来说,归一化层和激活层也是必不可少的。然而,许多先前的工作[17,20,54]在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能,它还会降低整体计算速度。相比之下,我们只将它们放在每个中间PWConv之后,以保持特征多样性并实现更低的延迟。此外,我们使用批归一化(BN)[30]代替其他替代方法[2,67,75]。BN的好处是它可以合并到相邻的Conv层中,从而更快地进行推理,同时与其他层一样有效。
至于激活层,考虑到运行时间和有效性,我们经验地选择GELU[22]用于较小的FasterNet变体,ReLU[51]用于较大的FasterNet变体。最后三层,即全局平均池化,Conv 1×1和全连接层,一起用于特征转换和分类
为了在不同的计算预算下服务于广泛的应用程序,我们提供了微型、小型、中型和大型FasterNet变体,称为FasterNet-
分别为T0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。它们具有相似的架构,但深度和宽度有所不同
Experimental Results
我们首先检查了我们的PConv的计算速度及其与PWConv结合时的有效性。然后,我们全面评估我们的fastnet在分类、检测和分割任务方面的性能。最后,我们进行了一个简短的消融研究
为了对延迟和吞吐量进行基准测试,我们选择了以下三种典型的处理器,它们涵盖了广泛的计算能力:GPU(2080Ti)、CPU(Intel i9-9900X,使用单线程)和ARM (Cortex-A72,使用单线程)。我们报告了它们对批大小为1的输入的延迟和批大小为32的输入的吞吐量。在推理过程中,BN层在适用的情况下与相邻层合并
PConv is fast with high FLOPS
我们在下面展示了我们的PConv是快速的,并且更好地利用了设备上的计算能力。具体来说,我们将10层纯PConv叠加起来,并将典型维度的特征映射作为输入。然后我们测量GPU、CPU和ARM处理器上的FLOPs和延迟/吞吐量,这也允许我们进一步计算FLOPs。我们对其他卷积变量重复相同的过程并进行比较
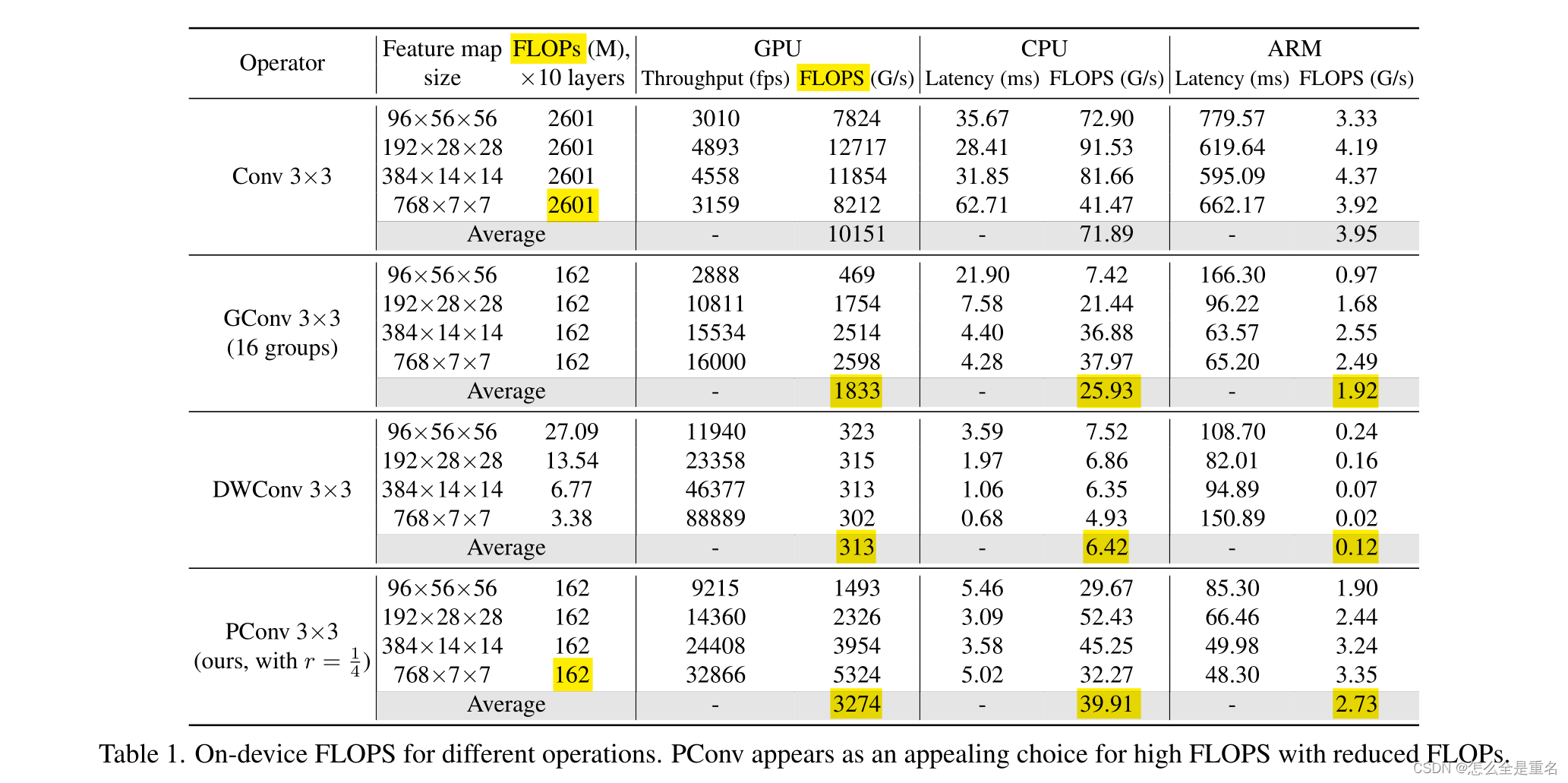
表1中的结果显示,PConv总体上是一个具有较低FLOPs的高FLOPS的有吸引力的选择。它只有普通Conv的1/16个FLOPs,在GPU、CPU和ARM上的FLOPS分别是DWConv的10.5倍、6.2倍和22.8倍。我们并不惊讶地看到,常规Conv有最高的FLOPS,因为它已经不断优化了多年,然而,它的总FLOPs和延迟/吞吐量是无法承受的。GConv和DWConv,尽管它们的FLOPs显著减少,但FLOPS却急剧下降。此外,它们倾向于增加通道的数量来补偿性能下降,然而,这增加了它们的延迟
PConv is effective together with PWConv
接下来,我们证明了PConv和PWConv可以有效地近似正则Conv来变换特征映射。为此,我们首先通过将ImageNet-1k值分割图像馈送到预训练的ResNet50中来构建四个数据集,并在每个阶段提取第一个Conv 3 × 3前后的特征图。每个特征映射数据集进一步划分为训练(70%)、val(10%)和test(20%)子集。然后,我们构建了一个简单的网络,由一个PConv和一个PWConv组成,并在具有均方误差损失的特征映射数据集上训练它。为了比较,我们还在相同的设置下构建和训练了DWConv + PWConv和GConv + PWConv的网络。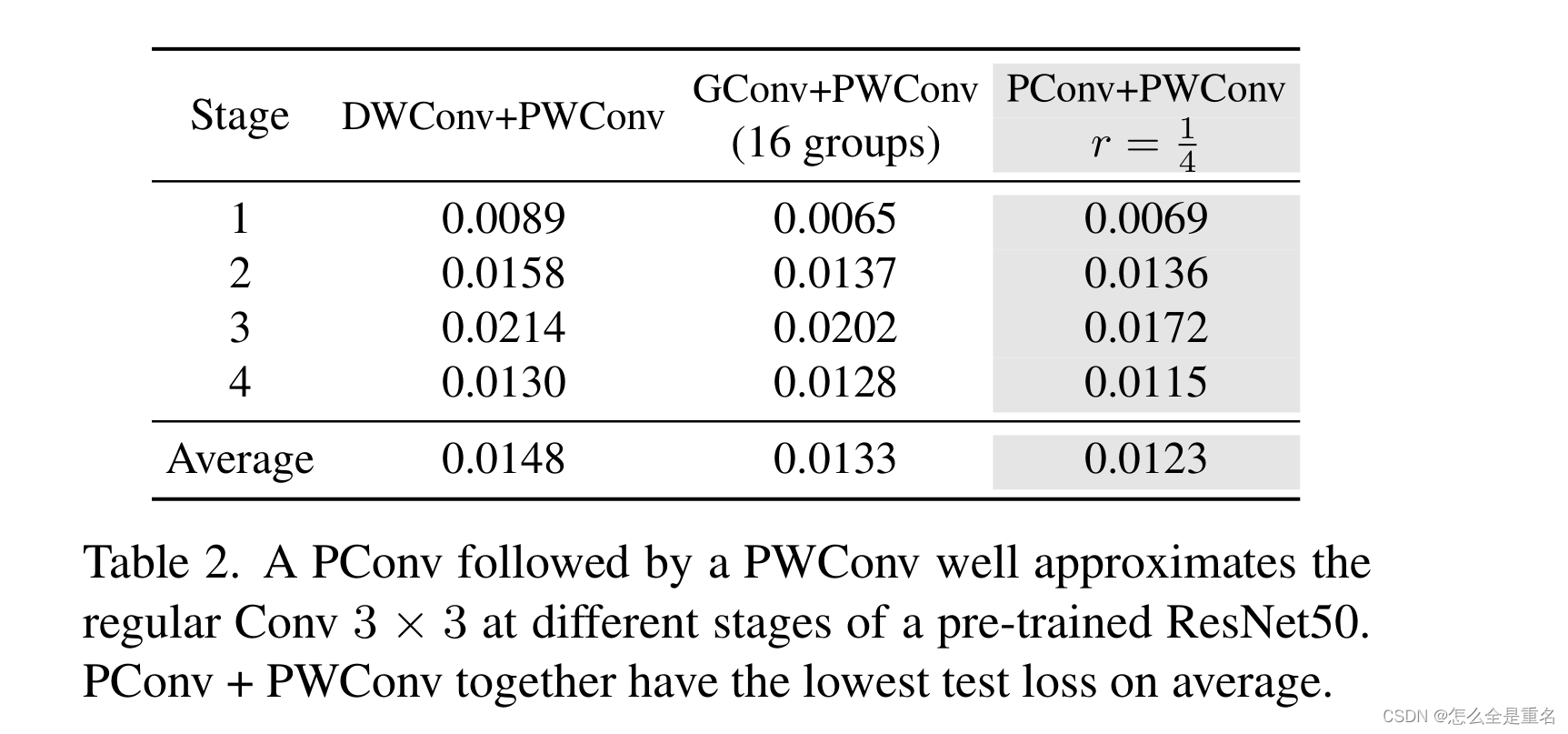
(在预训练的ResNet50的不同阶段,PConv和PWConv很好地近似于常规Conv 3 × 3。PConv + PWConv组合的平均测试损耗最低)
从表2可以看出,PConv + PWConv的测试损失最低,说明它们在特征变换中更接近常规Conv。结果还表明,仅从部分特征图中捕获空间特征是足够和有效的。PConv在设计快速有效的神经网络方面显示出巨大的潜力
FasterNet on ImageNet-1k classification
为了验证FasterNet的有效性和效率,我们首先在大规模ImageNet-1k分类数据集上进行了实验。它涵盖了1k个常见物体类别,包含约130万张用于训练的标记图像和5万张用于验证的标记图像。
我们使用AdamW优化器[44]训练了300个epoch的模型。我们将fastnet-M/L的批处理大小设置为2048,将其他变体的批处理大小设置为4096。我们使用了余弦学习率调度器[43],其峰值为0.001·批大小/1024,并进行了20 epoch的线性预热。
我们应用了常用的正则化和增强技术,包括权重衰减[32]、随机深度[28]、标签平滑[59]、Mixup[81]、Cutmix[80]和Rand Augment[9],这些技术对不同的FasterNet变体具有不同的量级。为了减少训练时间,我们对前280个训练周期使用192×192分辨率and224×224forthe剩余的20个周期。
为了便于比较,我们没有使用知识蒸馏[23]和神经结构搜索[87]。我们在224 × 224分辨率的中心裁剪和0.9裁剪比的验证集上报告了我们的前1精度。详细的培训和验证设置在附录中提供
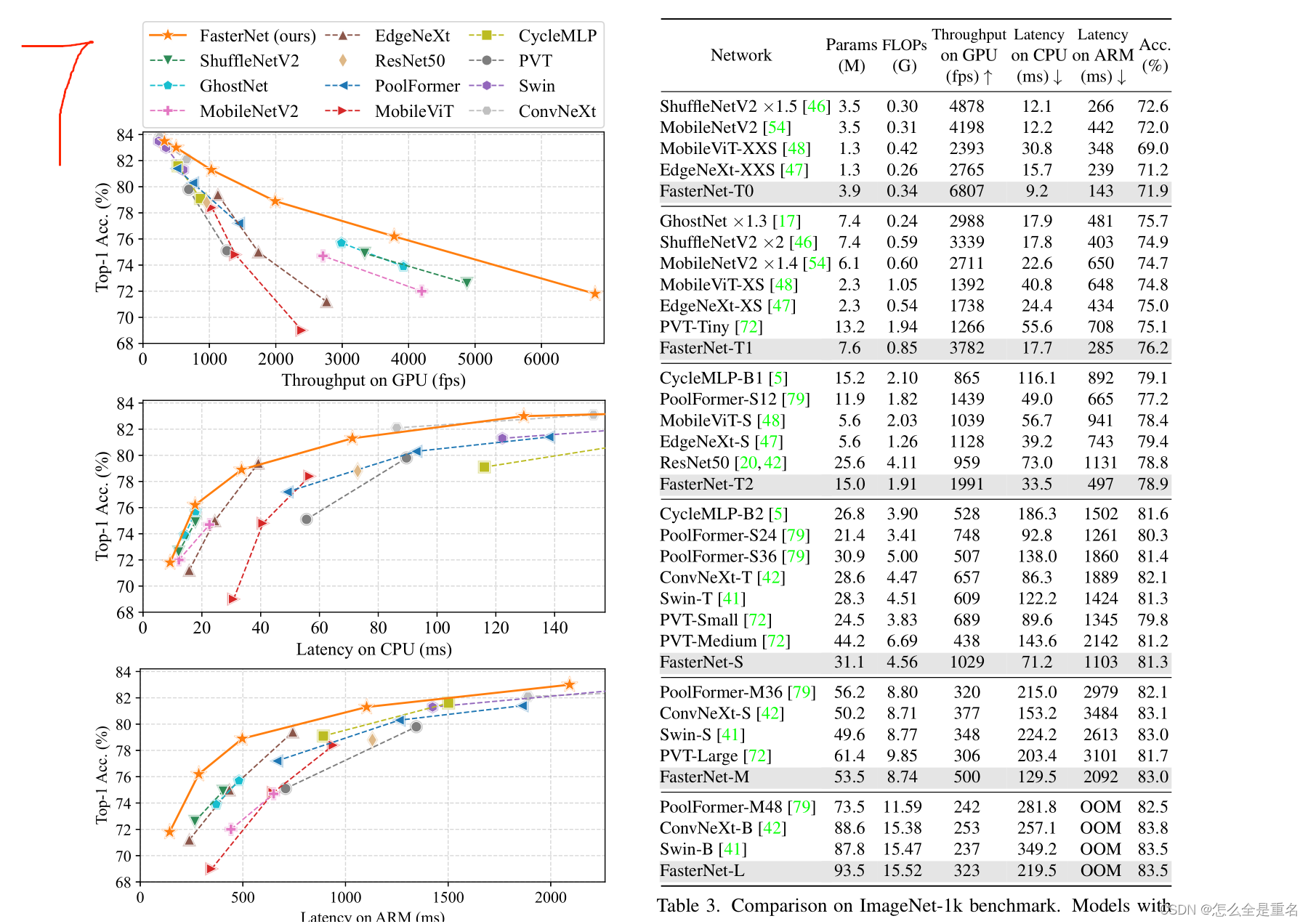
(图7.FasterNet在平衡不同设备的准确性-吞吐量和准确性-延迟权衡方面具有最高的效率。为了节省空间并使图更具比例性,我们展示了在一定延迟范围内的网络变体。完整的图表可以在附录中找到,显示了一致的结果)
(表3。ImageNet-1k基准的比较。具有相似top-1精度的模型被分组在一起。对于每个组,我们的FasterNet在GPU上实现了最高的吞吐量,在CPU和ARM上实现了最低的延迟。除了MobileViT和EdgeNeXt的256 × 256分辨率外,所有模型都以224×224分辨率进行评估。OOM是内存不足的缩写)
图7和表3展示了我们的FastNet 优于最先进的分类模型。图7中的权衡曲线清楚地表明,在所有被检查的网络中,FasterNet在平衡精度和延迟/吞吐量方面是最先进的设置。从另一个角度来看,FasterNet在许多设备上的运行速度都快于各种CNN、ViT和MLP模型,同时具有相似的top-1精度。如表3所示,在GPU、CPU和ARM处理器上,FastNet - T0分别比MobileViT-XXS[48]快2.8倍、3.3倍和2.4倍,准确率提高2.9%。我们的大型FastNet - L达到了83.5%的top-1精度,与新兴的swing - b[41]和ConvNeXt-B[42]相当,同时在GPU上的推理吞吐量提高36%和28%,在CPU上节省37%和15%的计算时间
鉴于这些有希望的结果,我们强调我们的fastnet在架构设计方面比许多其他模型简单得多,这表明了设计简单而强大的神经网络的可行性
FasterNet on downstream tasks
为了进一步评估Faster- Net的泛化能力,我们在具有挑战性的COCO数据集[36]上进行了目标检测和实例分割的实验。作为一种常见的做法,我们采用ImageNet预训练的FasterNet作为骨干,并为其配备流行的Mask R-CNN检测器。为了突出骨干本身的有效性,我们简单地遵循PoolFormer[79],采用AdamW优化器,1×训练计划(12个epoch), 16个批处理大小和其他训练设置,而无需进一步超参数调优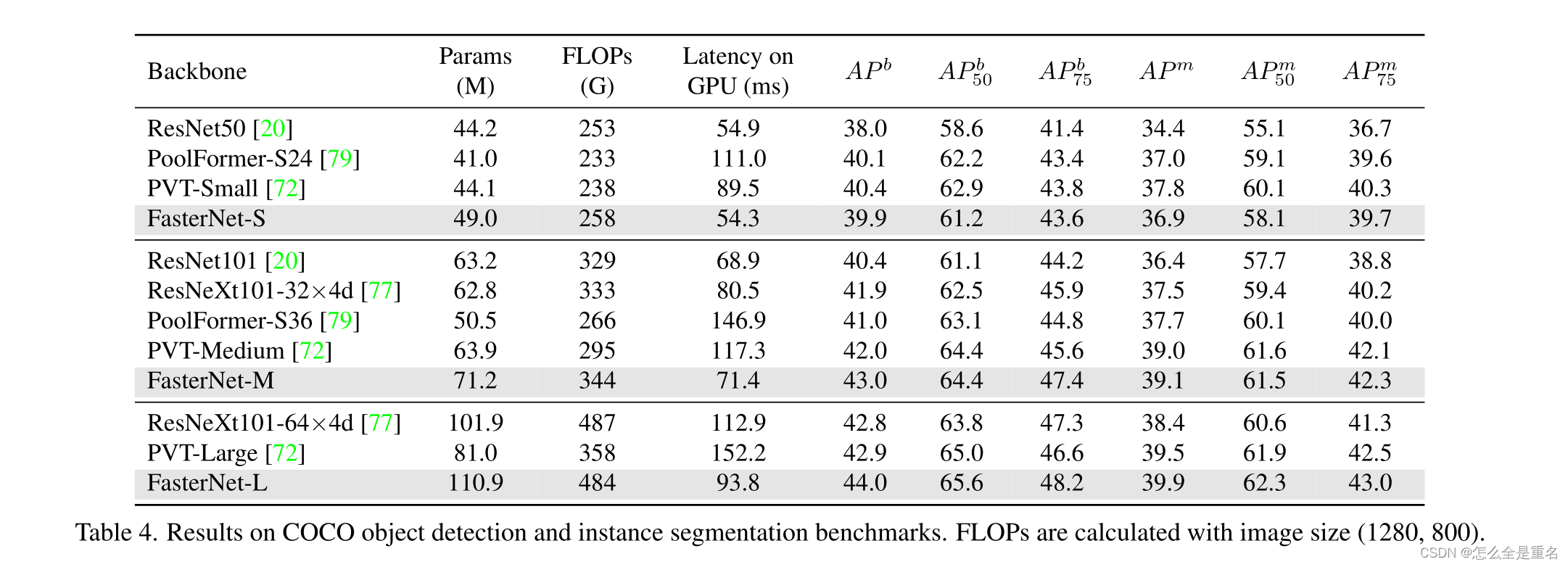
表4显示了Faster- Net与代表性模型的比较结果。FasterNet具有更高的平均精度(AP)和相似的延迟,始终优于ResNet和ResNext。具体来说,与标准基线ResNet50相比,FasterNet- S的 box AP和mask AP分别高出1.9和2.4。FasterNet也与ViT变体竞争。在相同的FLOPs下,FastNet - L将PVT - large的延迟降低了38%,即在GPU上从152.2 ms降低到93.8 ms,并且实现了+1.1更高的box AP和+0.4更高的mask AP
Ablation study
我们对部分值r的取值以及激活层和归一化层的选择进行了简要的研究。我们在ImageNet top-1精度和设备上延迟/吞吐量方面比较了不同的变体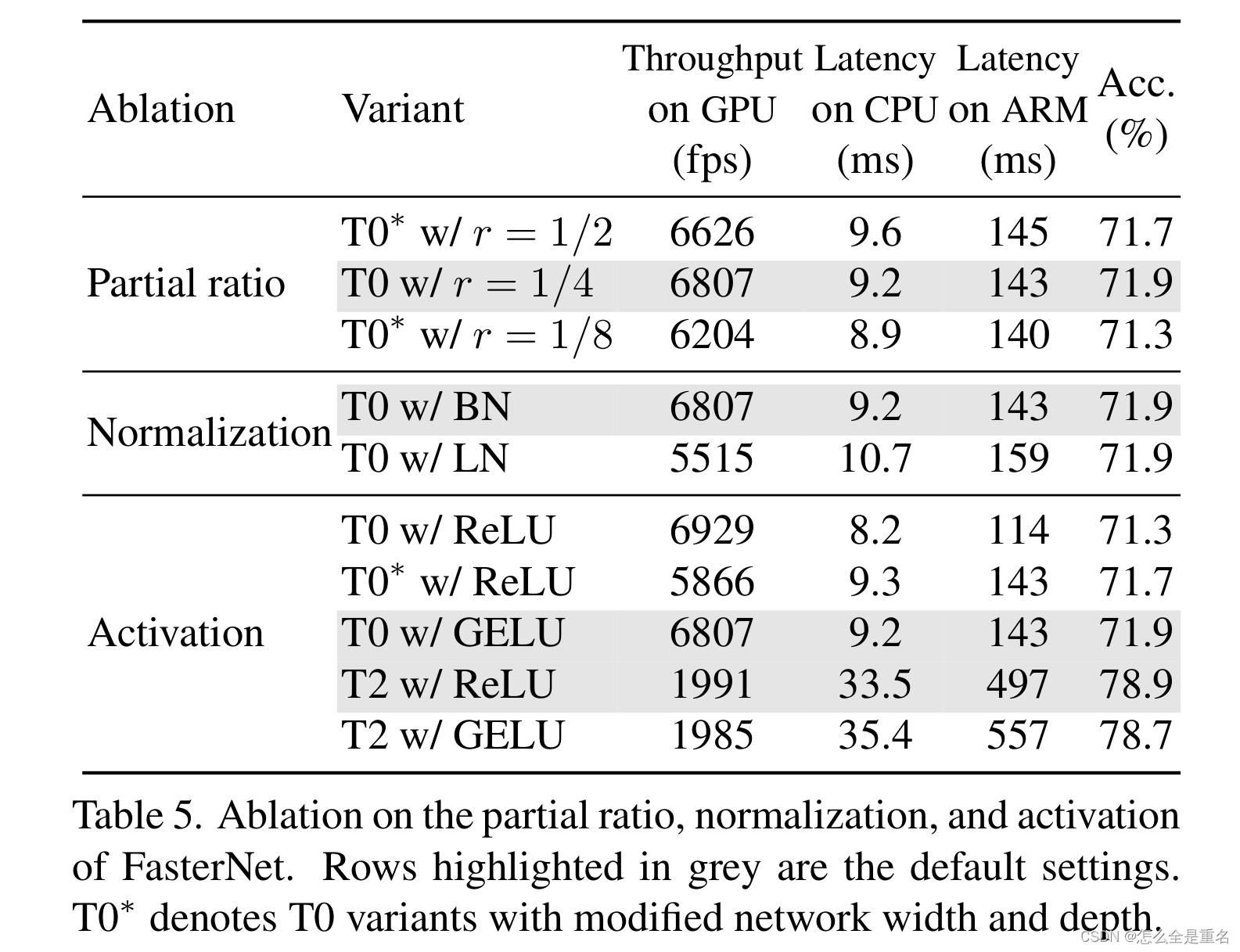
(消融对FasterNet部分比值、归一化和激活的影响。以灰色突出显示的行是默认设置。*T0 表示改变了网络宽度和深度的T0变量)
结果汇总见表5。对于部分比r,我们默认将所有FasterNet变体的部分比率r设置为1/4,这样可以在相同的复杂性下实现更高的准确性、更高的吞吐量和更低的延迟。部分比r过大会使PConv退化为常规的Conv,而偏比r过小则会使PConv在捕捉空间特征时效果较差
对于归一化层,我们选择BatchNorm而不是LayerNorm,因为BatchNorm可以合并到相邻的卷积层中以更快的速度进行推理,而在我们的实验中它与LayerNorm一样有效。对于激活函数,有趣的是,我们通过经验发现GELU比ReLU更有效地拟合FasterNet-T0/T1模型。然而,对于FasterNet- T2/S/M/L来说,情况正好相反。由于篇幅限制,我们在表5中只展示两个示例。我们推测GELU通过具有更高的非线性来增强FasterNet- t0 /T1,而对于更大的FasterNet变体,好处逐渐消失
Conclusion
在本文中,我们研究了许多已建立的神经网络普遍存在的和尚未解决的问题,即每秒浮点运算(FLOPS)低。我们重新讨论了瓶颈运算符DWConv,并分析了它导致速度变慢的主要原因——频繁的内存访问。为了克服这个问题并实现更快的神经网络,我们提出了一种简单而快速有效的算子PConv,它可以很容易地插入到许多现有的网络中。我们进一步介绍了我们的通用FasterNet,它建立在我们的PConv之上,在各种设备和视觉任务上实现了最先进的速度和精度权衡。我们希望我们的PConv和Faster- Net能够激发更多关于简单而有效的神经网络的研究,超越学术界,直接影响工业界和社区


![科学计数法 [极客大挑战 2019]BuyFlag1](https://img-blog.csdnimg.cn/059b0fdc8b4349f1b2948ca33c8b1a6a.png)








