在深度学习模型训练中,权重初始值极为重要,一个好的初始值会使得模型收敛速度提高,使模型准确率更准确,一般情况下,我们不使用全零初始值训练网络,为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化, P y t o r c h Pytorch Pytorch也在 t o r c h . n n . i n i t torch.nn.init torch.nn.init中为我们提供了常用的初始化方法,通过本章学习,你将学习到以下内容。
- 常见的初始化函数。
- 初始化函数的使用。
torch.nn.init的内容
我们发现初始化模块提供了以下的初始化方法:
- torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
- torch.nn.init.normal_(tensor, mean=0.0, std=1.0) 3 . *
- torch.nn.init.constant_(tensor, val) 4 .
- torch.nn.init.ones_(tensor) 5
- torch.nn.init.zeros_(tensor)
- torch.nn.init.eye_(tensor)
- torch.nn.init.dirac_(tensor, groups=1)
- torch.nn.init.xavier_uniform_(tensor, gain=1.0)
- torch.nn.init.xavier_normal_(tensor, gain=1.0)
- torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan__in’, nonlinearity=‘leaky_relu’)
- torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
- torch.nn.init.orthogonal_(tensor, gain=1)
- torch.nn.init.sparse_(tensor, sparsity, std=0.01)
- torch.nn.init.calculate_gain(nonlinearity, param=None)
具体分布解释
均匀分布
- torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
- tensor – an n-dimensional torch.Tensor
- a – the lower bound of the uniform distribution
- b – the upper bound of the uniform distribution
高斯分布
- torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
* tensor – an n-dimensional torch.Tensor
* mean – the mean of the normal distribution
* std – the standard deviation of the normal distribution
初始化为常数
- torch.nn.init.constant_(tensor, val)
- tensor – an n-dimensional torch.Tensor
- val – the value to fill the tensor with
初始化全为1
- torch.nn.init.ones_(tensor)
- tensor – an n-dimensional torch.Tensor
初始化全为0
- torch.nn.init.zeros_(tensor)
- tensor – an n-dimensional torch.Tensor
初始化为对角单位矩阵
- torch.nn.init.eye_(tensor)
- tensor – a 2-dimensional torch.Tensor
.Xavier 均匀分布
- torch.nn.init.xavier_uniform_(tensor, gain=1.0)
- tensor – an n-dimensional torch.Tensor
- gain – an optional scaling factor
.Xavier 高斯分布

- torch.nn.init.xavier_normal_(tensor, gain=1.0)
- tensor – an n-dimensional torch.Tensor
- gain – an optional scaling factor
He 均匀分布
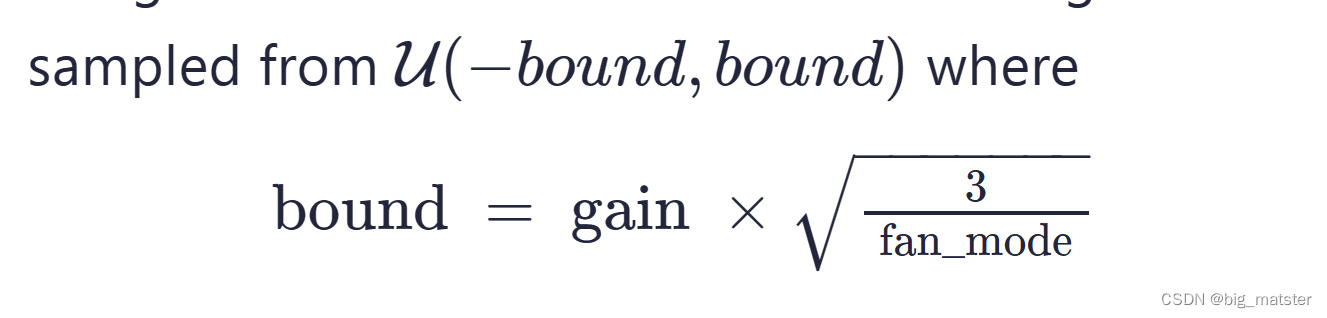
- torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
- tensor – an n-dimensional torch.Tensor
- a – the negative slope of the rectifier used after this layer (only used with ‘leaky_relu’

He 高斯分布
- torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
初始化函数的使用
初始化函数的封装
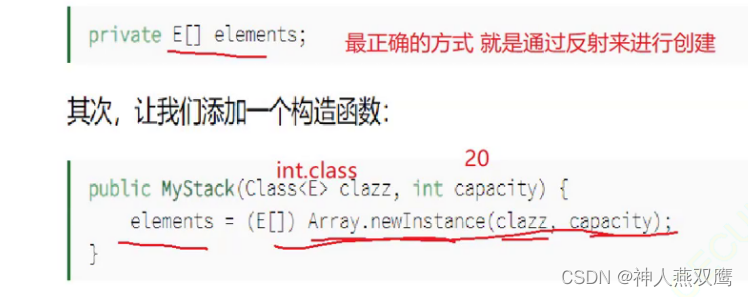
def initialize_weights(self):
for m in self.modules():
# 判断是否属于Conv2d
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
# 判断是否有偏置
if m.bias is not None:
torch.nn.init.constant_(m.bias.data,0.3)
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0.1)
if m.bias is not None:
torch.nn.init.zeros_(m.bias.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zeros_()
模型定义,调用初始化函数。
# 模型的定义
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Conv2d(1,1,3)
self.act = nn.ReLU()
self.output = nn.Linear(10,1)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
mlp = MLP()
print(list(mlp.parameters()))
print("-------初始化-------")
initialize_weights(mlp)
print(list(mlp.parameters()))
总结
慢慢的会自己编写初始化模块,将初始化,全部都将其搞透彻,。
了解一个模型架构需要那些函数,以及那些模块,会自己将其搞清楚。