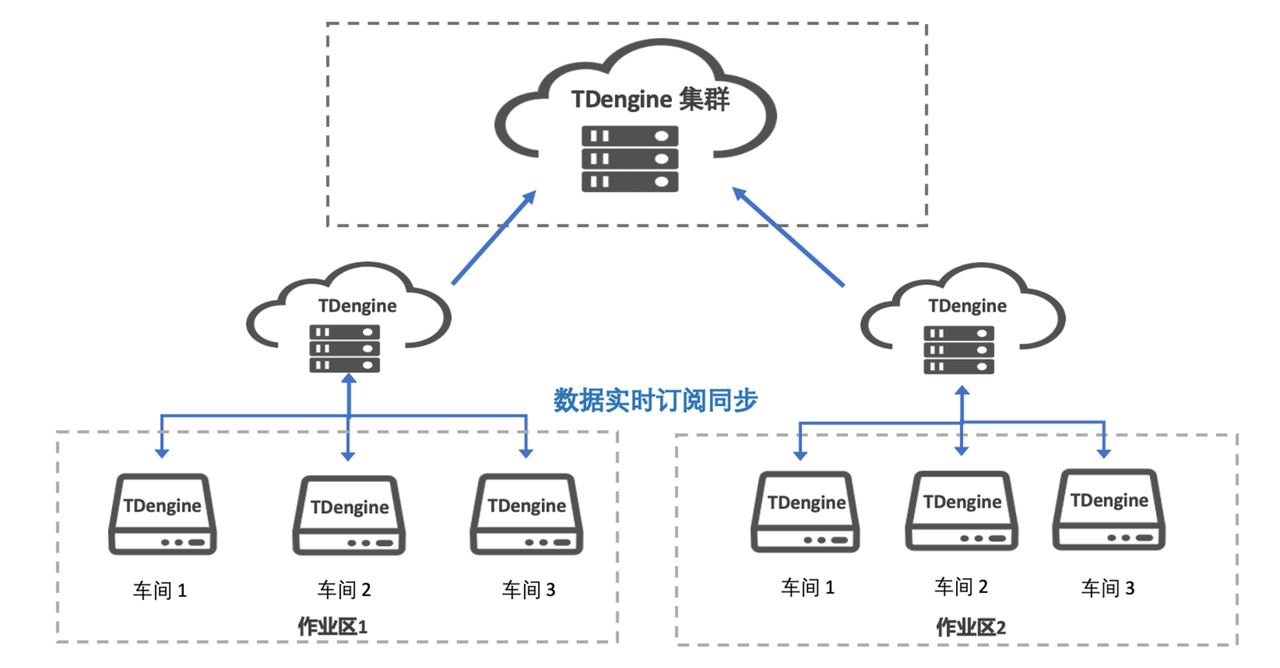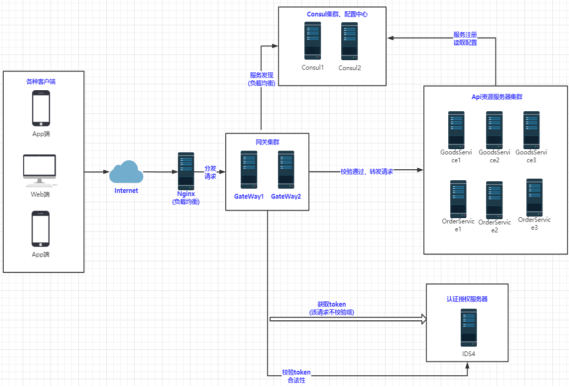
这是一个涵盖客户端访问、网关处理、服务注册发现、业务服务及鉴权授权的系统架构图,各部分解析如下:
客户端层
App 端、Web 端:代表不同类型的客户端,涵盖手机 App、电脑 Web 页面等。用户通过这些客户端发起请求,访问系统提供的服务,是系统与用户交互的入口。
网络接入层
Internet:作为客户端与后端服务通信的网络媒介。
Nginx(负载均衡):接收来自客户端的请求,通过负载均衡算法,将请求分发给不同的网关实例,提升系统整体性能和可用性,避免单个节点压力过大。
网关层
Gateway1、Gateway2:网关服务器,起到统一入口的作用。一方面,对请求进行初步处理,如协议转换、请求过滤、流量控制等;另一方面,根据配置将请求路由到对应的后端服务,是客户端请求进入内部服务的关键枢纽。
服务注册发现层
Consul1、Consul2:Consul 服务器组成集群,作为服务注册与发现中心。后端的业务服务和其他相关服务会将自身信息(如地址、端口等)注册到 Consul 集群中。网关可从 Consul 获取服务列表及地址信息,以便准确地将请求路由到相应服务。同时,Consul 还可进行健康检查,监测服务实例的运行状态。
业务服务层
Api 实际服务集群(Gateway-api、Order-api 等 ):包含多个实际提供业务功能的 API 服务实例,如网关相关服务(Gateway-api )、订单服务(Order-api )等。这些服务处理网关转发过来的请求,执行业务逻辑并返回结果,是系统业务功能实现的核心部分。
鉴权授权层
认证授权服务器(IDS4 ):负责用户身份验证和权限管理。当客户端请求到达网关后,网关会与 IDS4 交互,验证用户是否合法以及是否具备访问相应资源的权限,防止非法访问和越权操作,保障系统安全。
consul在微服务中的作用
Consul 是一个用于实现服务发现和配置管理的工具,在微服务架构中具有至关重要的作用,属于基于gateway的第三方管理服务集群的平台,网关只做转发和调用,Consul主要体现在以下几个方面:
- 服务发现
- 提供服务注册与查询:微服务架构中存在大量服务,Consul 允许服务实例在启动时向其注册自身的相关信息,如服务名称、IP 地址、端口号等。其他服务可以通过 Consul 提供的查询接口,快速获取到所需服务的实例列表及详细信息,从而实现服务间的动态发现与调用。
- 健康检查:Consul 会定期对注册的服务实例进行健康检查,通过发送心跳请求或执行特定的检查脚本等方式,判断服务是否正常运行。如果发现某个服务实例出现故障,Consul 会将其从服务列表中剔除,避免其他服务向其发送请求,从而保证整个系统的稳定性和可靠性。
- 配置管理
- 集中配置存储:Consul 可以作为微服务架构中的集中配置中心,存储各个微服务的配置信息。这些配置信息可以包括数据库连接字符串、缓存服务器地址、日志级别等。将配置信息集中存储在 Consul 中,方便对配置进行统一管理和修改,避免了在每个微服务实例中单独修改配置的繁琐过程。
- 动态配置更新:当配置信息发生变化时,Consul 能够实时将更新后的配置推送给相关的微服务实例,无需重启服务。微服务实例可以通过监听 Consul 的配置变更事件,及时获取最新的配置信息并应用到自身,实现配置的动态更新,提高了系统的灵活性和可维护性。
- gateway的服务治理
- API Gateway(API 网关)在服务治理中扮演着关键角色,它是系统对外的统一入口,承担着诸多服务治理的功能,以下为你详细介绍:
- 1. 路由与转发
- 规则定义:网关可依据不同的规则(如请求的 URL、HTTP 方法、请求头等)把请求路由到对应的后端服务。例如,把所有以/user开头的请求转发至用户服务,以/order开头的请求转发至订单服务。
- 动态路由:在微服务架构里,服务的数量和地址可能频繁变动。网关支持动态路由配置,能实时依据服务的注册与发现信息更新路由规则。
- 2. 负载均衡
- 算法实现:网关可以集成负载均衡算法,把请求均匀地分发到多个后端服务实例上,从而避免单个服务实例过载。常见的负载均衡算法有轮询、随机、加权轮询、IP 哈希等。
- 服务健康检查:结合服务的健康检查结果进行负载均衡决策。对于不健康的服务实例,网关会自动将其从负载均衡列表中移除,保证请求只被发送到健康的服务实例上。
- 3. 限流与熔断
- 限流:为防止后端服务因流量过大而崩溃,网关可对请求进行限流。限流策略可以按照请求的速率(如每秒请求数)、并发连接数等进行设置。例如,限制某个服务每秒最多处理 100 个请求。
- 熔断:当后端服务出现故障或响应时间过长时,网关能够自动触发熔断机制,直接返回预设的错误响应,避免大量请求阻塞在故障服务上,影响整个系统的可用性。待服务恢复正常后,再自动恢复对该服务的请求转发。
- 4. 认证与授权
- 认证:网关可对请求进行身份验证,确保只有经过授权的用户或服务才能访问后端资源。常见的认证方式有基于令牌(Token)的认证、OAuth 2.0 认证等。
- 授权:在完成认证后,网关会根据用户或服务的角色和权限,决定是否允许其访问特定的资源。例如,普通用户只能访问自己的个人信息,而管理员用户可以访问所有用户的信息。
- 5. 监控与日志
- 监控:网关能够收集请求的各种指标数据,如请求响应时间、吞吐量、错误率等,通过监控这些指标,可以及时发现系统中的性能瓶颈和潜在问题。
- 日志记录:记录所有请求的详细信息,包括请求的 URL、请求参数、响应状态码等。这些日志信息有助于问题的排查和审计。
- 6. 协议转换
- 协议适配:在不同的服务之间,可能使用了不同的通信协议。网关可以进行协议转换,将客户端的请求协议转换为后端服务支持的协议,反之亦然。例如,将 HTTP 请求转换为 gRPC 请求。
- 7. 服务聚合
- 数据整合:网关可以将多个后端服务的响应数据进行整合,然后返回给客户端。这样客户端只需与网关进行一次交互,就可以获取到多个服务的信息,减少了客户端与服务之间的通信次数。
gateway的弹性收缩
Gateway 弹性收缩是指在网关负载降低时,自动减少资源占用以节省成本 ,主要通过以下方式实现:
基于容器编排
Kubernetes:利用 K8s 的 HPA(Horizontal Pod Autoscaling,水平 Pod 自动伸缩)功能,依据 CPU、内存使用率等指标或自定义指标(如每秒请求数、响应时间等),自动调整网关 Pod 数量。当流量下降,指标低于设定阈值,K8s 自动减少 Pod 数量。比如,网关 Pod 初始有 5 个,流量降低后,HPA 检测到 CPU 使用率持续低于 20%,自动将 Pod 数量缩减为 2 个。
Docker Swarm:通过设置服务的副本数,并根据监控指标手动或自动调整。当监测到请求量、资源利用率等指标下降,手动或由自动化脚本减少副本数量。例如,原本设置 10 个网关服务副本,发现流量减少、资源利用率低,将副本数调整为 5 个。
云服务弹性伸缩
AWS:在 AWS 上部署网关,使用 Auto Scaling 组。配置好伸缩策略和触发条件,如以 CPU 利用率、网络流量等为指标。当流量降低,指标满足收缩条件,Auto Scaling 组自动移除部分实例。例如,设置 CPU 利用率低于 30% 且持续 15 分钟,自动减少一个 EC2 实例。
阿里云:借助弹性伸缩(Auto Scaling)服务,可按时间、监控指标(如 CPU、内存使用率、请求数等)伸缩。当监控到网关资源利用率低、请求量少,触发收缩策略,减少 ECS 实例数量。比如,设定每 5 分钟检测一次,若连续 3 次内存使用率低于 25%,减少一台 ECS 实例。
代码层面优化
连接池管理:动态调整连接池大小。流量低时,减少连接池中的连接数量,释放资源。例如,Java 网关应用中,使用数据库连接池技术,当业务请求量少,将连接池最大连接数从 100 调整为 20。
线程池调整:根据负载动态调整线程池线程数量。流量降低,减少线程池线程数,避免资源浪费。比如,在多线程处理请求的网关中,原本线程池最大线程数为 50,负载降低后,将其调整为 10 。
consul的安装
Consul 可在 Linux、Windows、Mac OS 等多系统安装,以下介绍常见安装方式:
二进制安装(以 Linux 为例 )
下载安装包:前往 Consul 官网(Install | Consul | HashiCorp Developer ),依据操作系统和位数选择合适版本,如consul_1.10.2_linux_amd64.zip 。
解压安装包:使用命令unzip consul_1.10.2_linux_amd64.zip 解压到任意目录。
移动二进制文件:将解压后的consul二进制文件移动到系统PATH环境变量包含的目录,比如执行sudo mv consul /usr/local/bin 。
验证安装:执行consul version ,若安装成功会输出版本号,如Consul v1.10.2 。
配置与启动:可通过命令行参数、环境变量或配置文件指定启动参数。例如启动一个服务器节点,指定数据中心为dc1 ,节点名为server-1 ,绑定 IP 为192.168.1.100 ,允许任意客户端访问 HTTP 接口并启动 Web UI 界面,命令为consul agent -server -bootstrap-expect=1 -datacenter=dc1 -node=server-1 -bind=192.168.1.100 -client=0.0.0.0 -ui 。
Docker 方式安装
拉取镜像:在终端执行docker pull consul ,拉取最新 Consul 镜像。
创建挂载目录(可选 ):根据需求创建,用于数据持久化等,如mkdir -p /data/consul 。
运行容器:使用命令docker run -d -p 8500:8500 -v /data/consul:/data/consul consul 。其中,-d表示后台运行;-p 8500:8500将容器 8500 端口映射到主机 8500 端口;-v /data/consul:/data/consul是挂载目录 。运行成功后,可通过http://本机IP:8500/ui 访问 Consul 界面。
Windows 安装
下载:从官网下载对应 Windows 版本安装包,解压得到consul.exe 。
启动:在解压目录打开命令行,执行consul agent -dev 启动开发模式(适合测试 )。可通过http://localhost:8500/ui/dc1/services 在浏览器查看运行结果。
集群安装(以 Linux 为例 )
规划节点:确定各机器的 agent 类型(server 或 client )、数据中心名称等,如规划三台服务器10.49.196.10 、10.49.196.11 、10.49.196.12 均为 server,数据中心为dc1 。
配置启动:一般通过配置文件启动。
在10.49.196.10 上创建agent.hcl ,内容如下:
plaintext
server = true
ui_config = {
enabled = true
}
bootstrap_expect = 3
data_dir = "./data"
datacenter = "dc1"
node_name = "node10"
client_addr = "0.0.0.0"
bind_addr = "10.49.196.10"
使用nohup ./consul agent -config-file=./agent.hcl & 启动。
在10.49.196.11 上创建agent.hcl :
plaintext
server = true
ui_config = {
enabled = true
}
bootstrap_expect = 3
data_dir = "./data"
datacenter = "dc1"
node_name = "node11"
client_addr = "0.0.0.0"
bind_addr = "10.49.196.11"
start_join = ("10.49.196.10")
retry_join = ("10.49.196.10")
同样命令启动。
在10.49.196.12 上创建agent.hcl ,与10.49.196.11类似,修改对应 IP 和节点名后启动。
管理集群:
查看节点信息:执行./consul members 。
查看集群状态:执行./consul operator raft list-peers 。
节点退出集群:执行./consul leave (-http-addr=<address>) ,优雅离开,http-addr默认为http://127.0.0.1:8500 。
Gateway配置

这段代码是网关配置文件的一部分,以 Ocelot 网关为例进行解析:
路由配置(Routes )
Routes是一个数组,用于定义网关的路由规则,当前配置了一条规则 。
下游服务配置(Downstream 相关 )
DownstreamPathTemplate:定义下游服务(即实际业务服务)的请求路径模板,/api/{url} 表示请求路径以/api/开头,后面跟着一个变量{url} ,这个变量在请求转发时会被替换为实际值。
DownstreamScheme:指定下游服务使用的协议,这里是http 。
DownstreamHostAndPorts:是一个数组,列出了下游服务的主机地址和端口。这里有三个相同主机192.168.3.230 ,不同端口5726 、5727 、5728 ,表示这些是同一服务的不同实例 。
上游网关配置(Upstream 相关 )
UpstreamPathTemplate:定义网关接收请求的路径模板,/T/{url} 表示网关接收以/T/开头,后面跟着变量{url} 的请求。注释提到冲突时可加权(但代码未体现加权配置 )。
UpstreamHttpMethod:指定该路由支持的 HTTP 方法,这里允许Get和Post 。
负载均衡配置(LoadBalancerOptions )
Type:指定负载均衡算法,当前配置为RoundRobin (轮询 ),即依次将请求分发给下游服务实例。注释中还提到其他算法,如LeastConnection (最少连接数 ),会将请求优先发给当前连接数最少的服务实例;NoLoadBalancer (无负载均衡 );CookieStickySessions (会话粘滞 ),会根据指定的 Cookie(如注释中的ASP.NET_SessionId )将同一客户端请求始终转发到同一个服务实例,Expiry (过期时间 )指定会话粘滞的有效期(单位毫秒 ),这里为1800000 (即 30 分钟 ) 。
image.png
ocelot.provider.consul.dll
ocelot.provider.consul.dll 是 Ocelot.Provider.Consul 包中的一个动态链接库文件 。以下是相关介绍:
所属组件及功能
Ocelot.Provider.Consul 是用于.NET 项目的 NuGet 包 ,ocelot.provider.consul.dll 包含其中。Ocelot 是一个基于.NET Core 的开源 API 网关,提供路由、负载均衡、请求聚合等功能;Consul 是分布式的服务注册与发现工具。该 DLL 实现了 Ocelot 与 Consul 的集成,让 Ocelot 网关能借助 Consul 完成:
服务发现:Ocelot 通过它从 Consul 获取服务实例信息,将请求转发到正确后端服务。比如电商系统中,商品服务实例注册到 Consul,Ocelot 利用该 DLL 查询 Consul,把商品查询请求转发到对应商品服务实例。
负载均衡:结合 Consul 中服务实例信息,依据配置的负载均衡算法(如轮询、最少连接数等 ),在多个服务实例间分配请求,提升系统性能与可用性。
使用场景
在微服务架构项目里,当使用 Ocelot 作为 API 网关,Consul 进行服务注册与发现时,会用到 ocelot.provider.consul.dll 。例如构建一个分布式的订单管理系统,各微服务(订单服务、支付服务、物流服务等 )向 Consul 注册,Ocelot 网关借助该 DLL 与 Consul 交互,实现对这些服务的路由和负载均衡管理。
安装与配置
安装:通过 NuGet 包管理器安装 Ocelot.Provider.Consul 包到.NET 项目。如在.NET CLI 中执行 dotnet add package ocelot.provider.consul --version <版本号> ;在 Visual Studio 的包管理器控制台执行 nuget install -package ocelot.provider.consul -version <版本号> 。
配置:安装后,在 Ocelot 配置文件(如 ocelot.json )中配置 Consul 相关信息,像 Consul 服务器地址、端口等,让 Ocelot 能连接 Consul 并获取服务信息。同时在代码中启用相关中间件,例如在ASP.NET Core 应用的 Startup.cs 中添加代码来使用 Ocelot 和 Consul 集成功能 。
ocelot.provider.consul.dll
ocelot.provider.consul.dll 是 Ocelot.Provider.Consul 包中的一个动态链接库文件 。以下是相关介绍:
所属组件及功能
Ocelot.Provider.Consul 是用于.NET 项目的 NuGet 包 ,ocelot.provider.consul.dll 包含其中。Ocelot 是一个基于.NET Core 的开源 API 网关,提供路由、负载均衡、请求聚合等功能;Consul 是分布式的服务注册与发现工具。该 DLL 实现了 Ocelot 与 Consul 的集成,让 Ocelot 网关能借助 Consul 完成:
服务发现:Ocelot 通过它从 Consul 获取服务实例信息,将请求转发到正确后端服务。比如电商系统中,商品服务实例注册到 Consul,Ocelot 利用该 DLL 查询 Consul,把商品查询请求转发到对应商品服务实例。
负载均衡:结合 Consul 中服务实例信息,依据配置的负载均衡算法(如轮询、最少连接数等 ),在多个服务实例间分配请求,提升系统性能与可用性。
使用场景
在微服务架构项目里,当使用 Ocelot 作为 API 网关,Consul 进行服务注册与发现时,会用到 ocelot.provider.consul.dll 。例如构建一个分布式的订单管理系统,各微服务(订单服务、支付服务、物流服务等 )向 Consul 注册,Ocelot 网关借助该 DLL 与 Consul 交互,实现对这些服务的路由和负载均衡管理。
安装与配置
安装:通过 NuGet 包管理器安装 Ocelot.Provider.Consul 包到.NET 项目。如在.NET CLI 中执行 dotnet add package ocelot.provider.consul --version <版本号> ;在 Visual Studio 的包管理器控制台执行 nuget install -package ocelot.provider.consul -version <版本号> 。
配置:安装后,在 Ocelot 配置文件(如 ocelot.json )中配置 Consul 相关信息,像 Consul 服务器地址、端口等,让 Ocelot 能连接 Consul 并获取服务信息。同时在代码中启用相关中间件,例如在ASP.NET Core 应用的 Startup.cs 中添加代码来使用 Ocelot 和 Consul 集成功能 。
consul的监测服务
Consul 可以监测服务器是否异常,主要通过其健康检查功能实现:
检查方式
HTTP 检查:定期向服务器指定 URL 发送 HTTP 请求,若返回状态码为 200 OK 等正常范围状态码 ,则认为服务健康。例如,可配置 Consul 每隔 30 秒向服务器的/health 端点发送请求,若响应为 200,就判定服务器上对应服务正常运行。
TCP 检查:通过尝试与服务器的指定端口建立 TCP 连接来判断。能连通则表明服务处于正常监听状态,服务器上相关服务可能无异常。比如检查数据库服务的 3306 端口(MySQL 默认端口 ),能成功连接则说明数据库服务大概率正常。
Script 检查:执行预先设定的脚本或命令,依据其返回值判断。通常返回值为 0 代表健康,非 0 值表示不健康。比如编写脚本检查服务器磁盘空间,若空间低于阈值脚本返回非 0 值,Consul 就判定服务器相关状态异常。
GRPC 检查:针对使用 gRPC 协议的服务,通过 gRPC 协议来检测服务健康状态。
告警与处理
告警:当 Consul 监测到服务器上服务异常时,可触发多种告警。如 Webhook 告警,通过 HTTP POST 请求向指定 URL 发送告警信息;Email 告警,借助 SMTP 协议给指定邮箱发告警邮件;PagerDuty 告警,经 PagerDuty API 向相关服务发告警;Slack 告警,通过 Slack API 往指定频道推送告警消息。
自动修复(部分情况 ):检测到服务异常后,在一些场景下 Consul 可自动尝试修复。像 TCP 检查发现连接失败、HTTP 检查发现响应异常、Script 检查脚本执行失败时,可配置 Consul 自动重启服务。若检测失败,一般会进行 3 次重试,每次间隔一段时间(如 30 秒 ),检查超时时间(如 5 秒 )后判定失败 。
查看状态
可通过 Consul 的 Dashboard 直观展示每个服务健康状态和注册情况,运维人员能快速定位异常服务;也能通过 API 获取服务实时状态信息,方便集成到自定义监控系统 。 此外,还可结合 Prometheus 和 Grafana 等工具,实现对 Consul 监控数据的收集、可视化展示和报警 。
从服务列表移除:Consul 会将该异常服务从服务实例列表中剔除,不再向其他服务推荐。
网关获取不到:Gateway(网关)通常定期从 Consul 获取服务列表信息,异常服务已不在列表,网关后续获取时自然不会得到其地址,进而不会将请求转发到该异常服务 。
不过,在实际场景中,存在一些特殊情况:
缓存问题:如果网关对服务地址有本地缓存,且缓存未及时更新,在缓存有效期内,网关可能仍持有异常服务地址。但一般可通过合理设置缓存过期时间、采用缓存刷新机制等方式避免。
短暂故障恢复:服务只是短暂异常,在网关下次从 Consul 获取服务列表前又恢复正常。此时 Consul 会重新将其加入列表,网关后续能获取到恢复后的服务地址 。
consul与nginx应用中的session的区别
Consul 与 Nginx 应用中的 session 区别如下:
应用场景
Consul:其 session 主要用于构建分布式锁,辅助实现选主等分布式协调功能 。比如多个客户端竞争获取锁来确定 leader,通过创建 session 并利用相关机制来实现 。
Nginx:主要用于会话保持 ,在负载均衡场景下,让同一客户端的后续请求能始终转发到之前交互过的后端服务器,以维持会话状态 。比如用户在电商网站登录后,后续操作请求能持续发到同一服务器处理 。
实现原理
Consul:一个 session 包含节点名称、健康性、行为、TTL(过期时间 )和 lock - delay(锁定延迟 )等信息 。通过 Gossip 协议在集群内传播相关状态信息,基于这些信息实现锁机制及相关分布式操作 。当 session TTL 到期,若无更新则会过期;锁定延迟可防止无效 session 在一定时间内重新获取锁 。
Nginx:通常基于 cookie 实现会话保持 。Nginx 会在客户端首次请求时,给其下发包含特定标识(如 session ID )的 cookie 。后续客户端请求携带此 cookie,Nginx 依据 cookie 中的标识判断,将请求转发到对应的后端服务器 。也可基于 IP 地址等其他方式实现会话保持 。
数据存储
Consul:session 相关数据存储在 Consul 服务器集群中 ,由各个服务器节点共同维护和管理 。
Nginx:本身不存储大量 session 数据 。基于 cookie 实现会话保持时,关键的 session 标识信息存储在客户端 cookie 中 ;若采用其他方式(如基于服务器内存记录 ),也是在后端服务器上记录少量与客户端会话关联的数据 。
生命周期管理
Consul:session 可由客户端主动创建和销毁 。在创建时可指定相关参数(如 TTL )。除正常 TTL 到期销毁外,也可通过 API 主动删除 。
Nginx:session 生命周期与客户端请求及后端服务器会话状态相关 。若客户端 cookie 被清除或过期,对应会话保持关系可能失效 ;后端服务器重启等情况也可能影响会话状态 。
Nginx 的 session 主要是为了保证客户端访问服务器的一致性。在负载均衡的场景中,当有多个后端服务器处理客户端请求时,Nginx 通过 session 可以确保来自同一个客户端的所有请求都被路由到同一台后端服务器上,主要有以下作用:
维持会话状态:许多 Web 应用程序依赖于会话来跟踪用户的登录状态、购物车内容、用户偏好等信息。如果客户端的请求在不同的服务器之间随机分配,那么这些会话信息就无法正确地在多次请求之间保持一致,用户可能会遇到登录状态丢失、购物车内容丢失等问题。通过使用 Nginx 的 session 机制,客户端的请求会始终被发送到同一个后端服务器,从而保证了会话状态的连续性和一致性。
避免数据不一致:在一些应用中,后端服务器可能会在内存中缓存一些与客户端相关的数据,如果客户端请求被分发到不同的服务器,可能会导致数据不一致的情况。例如,服务器 A 缓存了用户的最新信息,而服务器 B 没有及时更新,当客户端请求在 A、B 之间切换时,就可能获取到不一致的数据。Nginx 的 session 机制可以避免这种情况发生,确保客户端始终从同一个服务器获取数据,从而保证数据的一致性。
Nginx 实现 session 的方式有多种,常见的是基于 cookie 的会话保持,Nginx 在客户端首次请求时会下发一个包含特定标识(如 session ID)的 cookie,后续客户端请求携带此 cookie,Nginx 根据其中的标识将请求转发到对应的后端服务器。此外,也可以基于 IP 地址等其他方式实现会话保持,但这种方式可能会受到客户端 IP 地址变化等因素的影响。
gateway保证访问服务器的一致性
网关(Gateway)保证访问服务器一致性的方式有多种,以下是一些常见的方法:
会话亲和性(Session Affinity)
基于 Cookie 的会话保持:与 Nginx 类似,网关可以在客户端首次请求时,由后端服务器生成一个唯一的 session ID,并通过网关将其以 Cookie 的形式返回给客户端。客户端后续请求都会携带此 Cookie,网关根据 Cookie 中的 session ID 来判断请求应转发到哪台后端服务器,从而实现将同一客户端的请求始终路由到同一台后端服务器。
基于 IP 哈希的会话保持:网关根据客户端的 IP 地址,通过哈希算法计算出一个哈希值,然后根据这个哈希值将请求路由到特定的后端服务器。这样,来自同一 IP 地址的客户端请求会始终被路由到同一台后端服务器。不过,这种方式在客户端通过代理服务器或负载均衡器访问时可能会出现问题,因为多个客户端可能具有相同的源 IP 地址。
分布式会话管理
集中式会话存储:将所有客户端的会话数据存储在一个集中式的存储系统中,如 Redis 等。当客户端请求到达网关时,网关可以根据请求中的会话标识从集中式存储中获取会话数据,并根据会话数据中的信息将请求转发到正确的后端服务器。这种方式可以实现多个后端服务器之间的会话共享,并且能够方便地进行会话的管理和维护。
会话复制:将会话数据在多个后端服务器之间进行复制,每个后端服务器都保存了所有客户端的会话数据副本。当客户端请求到达网关时,网关可以根据负载均衡算法选择任意一台后端服务器进行处理,因为每台服务器都具有完整的会话信息。不过,这种方式可能会导致内存占用较高,并且在会话数据更新时需要进行同步操作,以保证数据的一致性。
服务发现与健康检查
服务发现:网关通过与服务发现组件(如 Consul、Eureka 等)集成,实时获取后端服务器的列表和状态信息。当客户端请求到达时,网关可以根据服务发现组件提供的信息,选择一个可用的后端服务器进行请求转发。这样可以确保请求被路由到正常运行的服务器上,提高系统的可靠性和一致性。
健康检查:网关定期对后端服务器进行健康检查,通过发送心跳包或其他检测请求来判断服务器的运行状态。如果发现某个服务器出现故障或异常,网关会将其从可用服务器列表中移除,不再将请求转发到该服务器,从而避免请求被路由到不可用的服务器上,保证了访问的一致性。
不同的网关实现可能会采用不同的组合方式来保证访问服务器的一致性,具体的实现方式会根据实际的业务需求、系统架构和技术选型等因素进行调整。
案例示意
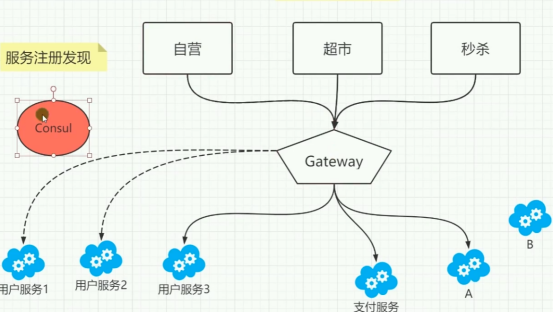
这是一幅微服务架构示意图,展示了 Consul、Gateway 与各类服务间的关系:
Consul:位于左侧红色椭圆内,承担服务注册发现功能。用户服务 1、用户服务 2、用户服务 3 通过虚线箭头向 Consul 注册自身信息,使 Consul 掌握这些服务的位置、状态等详情。
Gateway(网关):处于架构中心位置,是系统对外统一入口。自营、超市、秒杀等服务以及支付服务、服务 A、服务 B 等,通过实线箭头与 Gateway 相连。Gateway 接收外部请求,依据规则将请求转发到对应的后端服务,还可进行负载均衡、安全校验等操作 。
各类服务
业务服务:自营、超市、秒杀这类业务服务,接收 Gateway 转发的请求,处理具体业务逻辑。
基础服务:用户服务 1、用户服务 2、用户服务 3 ,为其他服务提供用户相关基础功能,先在 Consul 注册,便于被其他服务发现调用;支付服务等提供特定领域功能,通过 Gateway 与外部交互。
案例示意
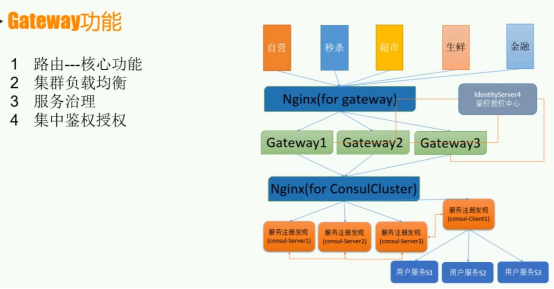
这张图介绍了 Gateway 的功能及其架构关系:
功能说明
路由:作为核心功能,指网关依据规则(如请求 URL、HTTP 方法等 )将外部请求转发到对应的后端服务。例如将以/user开头的请求转发至用户服务,以/order开头的请求转发至订单服务 。
集群负载均衡:在后端存在多个服务实例时,网关能将请求均匀分发到不同实例上,避免单个实例过载。可采用轮询、随机、加权轮询等算法,保障系统整体性能 。
服务治理:涵盖对服务的管理与控制,包括服务的注册、发现、健康检查等。通过与 Consul 等服务注册发现组件协作,实现对后端服务状态的监控与管理 。
集中鉴权授权:借助 IdentityServer4 等鉴权授权中心,网关统一处理客户端请求的身份验证和权限检查,只有通过验证的请求才能被转发到后端服务,保障系统安全 。
架构关系
上层服务:自营、秒杀、超市、生鲜、金融等业务服务,通过 Nginx(for gateway)与网关交互,网关接收这些服务相关请求并处理 。
网关层:Nginx(for gateway)作为网关入口,连接多个 Gateway 实例(Gateway1、Gateway2、Gateway3 ),这些实例进一步处理请求并与后端交互 。
服务注册发现层:Nginx(for ConsulCluster)连接 Consul 集群(由 consul - Server1、consul - Server2、consul - Server3 等组成 ),用户服务(用户服务 S1、用户服务 S2、用户服务 S3 )等后端服务在 Consul 中进行注册和发现 。
鉴权授权:IdentityServer4 作为鉴权授权中心,与网关交互,为网关提供集中鉴权授权支持 。
Ocelot
数据缓存功能
缓存原理
Ocelot 可对下游服务请求的结果进行缓存处理。当客户端请求到达 Ocelot 网关,若该请求已被缓存且在有效期内,Ocelot 直接从缓存中获取响应结果返回给客户端,避免重复调用下游服务,从而提升服务性能 。
实现方式
默认内存缓存:Ocelot 自身默认提供基于内存的缓存实现。老版本通过 Dictionary 以键值对形式存储;新版本借助 AspMemoryCache 的 IMemoryCache 实现。只需在配置文件中添加相关配置即可开启,配置项包括:
TtlSeconds:设置缓存有效期,单位为秒 。比如设为 60,代表缓存 1 分钟后过期。
Region:用于分区缓存数据,可通过 Ocelot 提供的缓存管理接口,指定区域清除缓存 。
集成 CacheManager :
CacheManager 功能:不仅能管理缓存,还封装了事件、性能计数器、并发更新等功能,便于开发人员处理和配置缓存 。
集成步骤:首先引入 Ocelot.Cache.CacheManager 包;接着添加配置文件,配置 FileCacheOptions ;完成配置后,运行网关和服务接口即可使用 。
集成 CacheManager 配合 Redis 做分布式缓存:在集成 CacheManager 基础上,将缓存数据存储在 Redis 中,实现分布式缓存,适用于分布式系统场景,满足多节点数据共享需求 。
自定义缓存:通过继承接口 IOcelotCache 自定义缓存类,然后将自定义缓存类注册到容器中,可根据具体业务需求灵活定制缓存逻辑 。
配置示例
在路由配置中添加如下设置可启用缓存:
json
{
"FileCacheOptions": {
"TtlSeconds": 15, // 缓存15秒后过期
"Region": "europe - central" // 缓存区域
}}
此外,若在 header 属性中定义了头信息名称,Ocelot 会在 HTTP 请求头中查找该头信息的值,并将其包含在缓存键中。当该头信息值变化时,会使缓存失效 。 还可通过调用 Ocelot 的管理 API 来清除某个 Region 的缓存 。
Ocelot基础配置
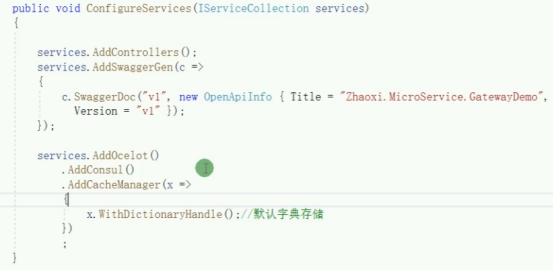
这段 C# 代码位于ASP.NET Core 项目的Startup.cs文件中,作用是配置服务。具体解析如下:
services.AddControllers()
这行代码用于注册 MVC 控制器相关服务,允许项目处理基于控制器的 HTTP 请求,使控制器能够接收和处理客户端请求,并返回相应响应。例如,定义一个HomeController,其中包含Index方法,通过路由配置,客户端访问对应 URL 时,就能由该控制器方法处理请求。
services.AddSwaggerGen(...)
用于添加 Swagger 服务来生成 API 文档。c.SwaggerDoc("v1", ...)创建一个名为v1的 Swagger 文档,OpenApiInfo对象设置文档的标题为 “Zhaoxi.MicroService.GatewayDemo” ,版本为v1 。借助 Swagger,开发人员可以方便地查看和测试项目提供的 API 接口,包括接口的请求参数、响应格式等信息。
services.AddOcelot()
添加 Ocelot 网关服务,Ocelot 是.NET 下的 API 网关组件,能实现路由、负载均衡、认证授权等功能。在微服务架构中,通过 Ocelot 可以统一管理对外暴露的 API,将客户端请求转发到对应的后端微服务。
.AddConsul()
在添加 Ocelot 服务的基础上,集成 Consul 服务。Consul 是服务注册与发现工具,此配置让 Ocelot 能够与 Consul 交互,从 Consul 获取后端服务的注册信息,实现基于 Consul 的服务发现功能。比如后端有多个用户服务实例注册到 Consul,Ocelot 就能通过该配置获取这些实例信息,将请求转发到合适的服务实例。
.AddCacheManager(x => {... })
为 Ocelot 添加缓存管理功能,通过CacheManager实现。x.WithDictionaryHandle();配置使用字典作为缓存存储方式,即默认在内存中以字典结构存储缓存数据。这意味着 Ocelot 可以对请求结果进行缓存,当下次相同请求到来时,直接从缓存中获取结果返回给客户端,提高响应速度,减轻后端服务压力。

这是 Ocelot 配置文件中的一部分,用于配置文件缓存相关选项,具体解析如下:
FileCacheOptions
这是一个配置节名称,用于专门配置文件缓存相关参数。在 Ocelot 中,通过这个配置节来管理缓存行为。
TtlSeconds
含义:Time To Live Seconds 的缩写,即缓存的存活时间(以秒为单位)。这里设置为15 ,表示缓存的内容在 15 秒后会过期。
作用:控制缓存数据的有效期,过期后再次请求相同资源时,Ocelot 会重新向后端服务请求数据,并更新缓存,保证缓存数据的时效性。
Region
含义:缓存区域名称,这里设置为UserCache 。通过设置不同的缓存区域,可以对缓存数据进行分组管理。
作用:便于后续对特定区域的缓存进行操作,比如可以调用相关 API 清理指定区域(如UserCache )的缓存内容,方便灵活地管理缓存数据。
ocelot缓存配置
配置 Ocelot 的缓存功能可按以下步骤进行:
1. 安装相关 NuGet 包
若使用 CacheManager 来实现缓存功能,需在项目中安装Ocelot.Cache.CacheManager包 。在 Visual Studio 中,通过 NuGet 包管理器搜索并安装该包;也可在项目目录下,使用命令行dotnet add package Ocelot.Cache.CacheManager 进行安装。
2. 在Startup.cs中配置服务
在ConfigureServices方法中,添加以下代码配置 Ocelot 与缓存相关服务:
csharp
using Ocelot.Cache.CacheManager;
services.AddOcelot()
.AddConsul()
.AddCacheManager(x =>
{
x.WithDictionaryHandle();//默认字典存储,可根据需求更换存储方式,如Redis等
});
上述代码中,AddOcelot添加 Ocelot 网关服务;AddConsul集成 Consul 服务用于服务发现;AddCacheManager配置缓存管理器,WithDictionaryHandle设置以字典方式存储缓存数据。
3. 在配置文件中设置缓存选项
在 Ocelot 的配置文件(如ocelot.json 或configuration.json )的路由配置部分,添加FileCacheOptions节点来设置缓存参数,示例如下:
json
{
"Routes": [
{
"DownstreamPathTemplate": "/api/values",
"DownstreamScheme": "http",
"DownstreamHostAndPorts": [
{
"Host": "localhost",
"Port": 5001
}
],
"UpstreamPathTemplate": "/values",
"UpstreamHttpMethod": ["Get", "Post"],
"FileCacheOptions": {
"TtlSeconds": 30, //缓存有效期为30秒,可按需调整
"Region": "valuesCache", //缓存区域名称,用于分组管理缓存,可自定义
"Header": "authorization" //可选,若定义,Ocelot会根据HTTP请求头中该头信息的值参与缓存键计算,值变化时缓存失效
}
}
],
"GlobalConfiguration": {
"BaseUrl": "http://localhost:5000",
"RequestIdKey": "OcRequestId"
}}
4. 其他缓存配置拓展
自定义缓存:若默认缓存功能不满足需求,可实现IOcelotCache<ICachedResponse>接口来自定义缓存逻辑,然后在Startup.cs的ConfigureServices方法中注册自定义缓存服务,如services.AddSingleton<IOcelotCache<ICachedResponse>, MyCache>(); 。
分布式缓存:可将 CacheManager 与 Redis 等分布式缓存系统集成,实现多节点间缓存数据共享。需先安装相关 Redis 集成包,再调整AddCacheManager配置 。
配置完成后,Ocelot 会根据设置对下游服务请求结果进行缓存,相同请求在缓存有效期内可直接获取缓存内容,提升响应性能 。 此外,还可通过 Ocelot 的管理 API 来清理指定区域的缓存 。
ocelot的ioc注入
Ocelot 中的 IOC(Inversion of Control,控制反转 )注入是指利用依赖注入机制,将 Ocelot 相关服务及依赖项注入到应用程序中,便于管理和使用这些服务。主要涉及以下两个关键方法:
AddOcelot 方法
功能:将默认的ASP.NET服务以及 Ocelot 应用服务隐式或显式地注入到依赖注入(DI)容器中。在不需要额外自定义启动设置的情况下,调用此方法即可复用默认设置构建 Ocelot 核心。
签名:
IOcelotBuilder AddOcelot(this IServiceCollection services)
IOcelotBuilder AddOcelot(this IServiceCollection services, IConfiguration configuration)
示例:在ASP.NET Core 项目的Startup.cs文件的ConfigureServices方法中,可通过services.AddOcelot();将 Ocelot 的默认服务注入到 DI 容器中,后续应用程序就能使用这些注入的服务来处理请求等操作。
AddOcelotUsingBuilder 方法
功能:除了添加 Ocelot 应用服务外,还允许使用自定义的构建器(通过IMvcCoreBuilder接口对象 )来添加自定义的ASP.NET服务,并将配置隐式或显式地注入到 DI 容器中。此方法给予开发者更多控制权,可在构建ASP.NET MVC 管道时自定义各项设置来构建 Ocelot 核心。
签名:
IOcelotBuilder AddOcelotUsingBuilder(this IServiceCollection services, Func<IMvcCoreBuilder, Assembly, IMvcCoreBuilder> customBuilder)
IOcelotBuilder AddOcelotUsingBuilder(this IServiceCollection services, IConfiguration configuration, Func<IMvcCoreBuilder, Assembly, IMvcCoreBuilder> customBuilder)
示例:假设要为 Ocelot 添加自定义的中间件服务,可使用AddOcelotUsingBuilder方法,传入自定义构建器逻辑,在构建器中添加自定义中间件相关服务的注册逻辑,从而实现对 Ocelot 管道的定制化。
通过这两种 IOC 注入方式,开发者能方便地将 Ocelot 集成到项目中,并根据需求对其进行扩展和定制,管理 Ocelot 与其他组件间的依赖关系,提升代码的可维护性和可扩展性 。例如,结合 Consul 实现服务发现时,可通过 IOC 注入将 Consul 相关服务与 Ocelot 整合起来 。
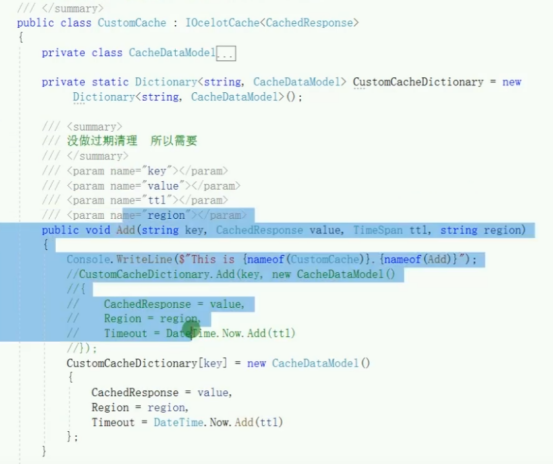
这段 C# 代码定义了一个自定义缓存类CustomCache ,实现了IOcelotCache<CachedResponse> 接口,用于在 Ocelot 网关中进行自定义缓存管理,以下是详细解析:
类定义与接口实现
public class CustomCache : IOcelotCache<CachedResponse> :定义了CustomCache 类,它实现了IOcelotCache<CachedResponse> 接口,意味着该类需实现接口中定义的方法,以提供自定义的缓存功能。
内部类与字段
private class CacheDataModel :定义了一个私有内部类CacheDataModel ,用于存储缓存相关的数据模型。但代码中该类的具体定义部分缺失(仅显示了省略号 )。
private static Dictionary<string, CacheDataModel> CustomCacheDictionary = new Dictionary<string, CacheDataModel>(); :声明了一个静态的字典类型字段CustomCacheDictionary ,用于存储缓存数据。以字符串key 为索引,值为CacheDataModel 类型,即每个缓存项对应一个CacheDataModel 实例。
Add 方法
方法签名:public void Add(string key, CachedResponse value, TimeSpan ttl, string region) ,该方法用于向缓存中添加数据。接收缓存键key 、缓存值CachedResponse value (符合 Ocelot 缓存响应格式 )、缓存有效期ttl (以时间间隔表示 )以及缓存区域region 作为参数。
方法实现:
Console.WriteLine($"This is {nameof(CustomCache)}.{nameof(Add)}"); :在控制台输出当前方法的相关信息,主要用于调试或日志记录,方便开发者了解该方法被调用的情况。
原注释掉的代码CustomCacheDictionary.Add(key, new CacheDataModel() {... }); 原本意图是直接向字典中添加新的缓存项,但存在问题,因为没有处理键冲突(若键已存在会引发异常 )。
后续代码CustomCacheDictionary[key] = new CacheDataModel() {... }; 采用了更安全的方式,直接通过索引器设置键对应的值。创建一个新的CacheDataModel 实例,将传入的CachedResponse value 、region 以及根据ttl 计算出的过期时间(DateTime.Now.Add(ttl) )赋值给该实例,完成缓存项的添加操作。
总体来看,这段代码实现了自定义缓存类中添加缓存数据的功能,但目前未处理缓存过期清理逻辑(如代码注释中所提到 ),后续可能需要进一步完善,例如添加检查过期缓存项并进行清理的机制 。 此外,若要在 Ocelot 项目中使用该自定义缓存类,还需在项目的依赖注入配置中进行注册 。
雪崩效应
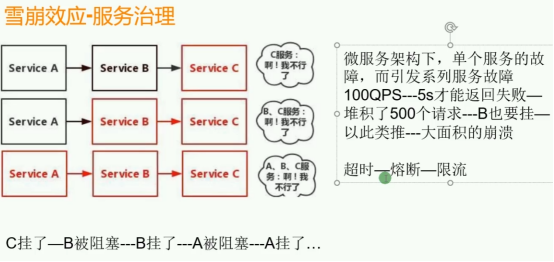
这张图主要介绍了微服务架构中的雪崩效应及相关服务治理概念:
雪崩效应原理
服务依赖与故障传递:微服务架构中,服务间存在依赖关系,如图中 Service A 依赖 Service B ,Service B 依赖 Service C 。当 Service C 出现故障(图中以红色标识 )无法正常响应时,会导致依赖它的 Service B 的请求堆积。因为 Service B 可能在等待 Service C 的响应,随着请求不断涌入,Service B 资源被耗尽,最终也发生故障。进而,依赖 Service B 的 Service A 同样会因请求阻塞而受到影响,最终可能导致整个系统大面积崩溃,这就是雪崩效应 。
具体示例说明:图中提到每秒有 100 个请求(100QPS ),而 Service C 故障后需要 5 秒才能返回失败结果。这 5 秒内就会堆积 500 个请求,大量请求积压使 Service B 不堪重负,引发连锁反应,导致故障在服务间蔓延 。
服务治理手段
- 超时:为服务调用设置时间限制,当调用 Service C 的时间超过设定值,Service B 不再等待,直接返回错误或执行备用逻辑,避免长时间阻塞 。
- 熔断:类似于电路保险丝,当 Service C 的错误率或延迟达到一定阈值,熔断器断开,后续对 Service C 的请求不再实际调用,而是快速返回默认值或错误信息,防止故障扩散到 Service B 和 Service A 。
3.限流:限制对 Service B 和 Service A 的请求流量,比如限制每秒只允许一定数量的请求进入,防止因大量请求同时涌入而导致服务过载,减轻服务压力,保障服务可用性 。
雪崩效应并不一定都是串行的 。
在不同场景下,其表现形式有所不同:
1.串行引发的雪崩效应
在微服务架构等场景中,服务间存在明确调用顺序,常以串行方式引发雪崩。比如服务 A 调用服务 B ,服务 B 调用服务 C 。当服务 C 出现故障,请求在 B 处堆积,进而影响 A ,故障沿调用链路依次传递,像多米诺骨牌一样,一个服务的问题串行传导至其他服务 。以电商系统为例,订单服务依赖库存服务获取商品库存信息,库存服务又依赖数据库服务读取数据。若数据库服务故障,库存服务请求阻塞,订单服务也会受影响无法正常处理订单,造成整个订单处理流程崩溃 。
2.并行引发的雪崩效应
在一些高并发场景下,多个请求或任务并行执行,也可能引发雪崩效应。例如在大型网站的首页,会并行加载广告、推荐商品、用户信息等多个模块。若其中广告模块的外部广告服务出现问题,导致广告加载缓慢或失败,浏览器为获取完整页面资源会持续等待,占用连接资源。当大量用户同时访问首页,众多并行请求因广告模块问题受阻,可能耗尽服务器连接资源,使其他正常模块也无法响应,引发雪崩 。
所以,雪崩效应既可能在串行的服务调用链中产生,也可能因并行任务处理异常而引发 。
Gateway 的限流作用类似于削峰,二者有相似之处,也存在区别:
相似点
目的相同:限流和削峰本质上都是为了保护系统,防止系统因流量过大而崩溃 。比如在电商大促秒杀场景中,大量用户同时抢购商品,流量瞬间激增,限流通过限制请求速率,削峰通过分散流量峰值,避免系统被高并发流量压垮 。
实现手段相关:一些限流算法(如令牌桶算法 ),在限制流量的同时,也具备一定削峰能力。令牌桶以固定速率生成令牌,允许一定突发流量,当流量超出桶容量时限制请求,能在一定程度上减缓流量峰值对系统的冲击 。
区别
侧重点不同:
限流:侧重于控制单位时间内的请求数量或速率 ,强调对流量的精确控制。例如,限制某个接口每分钟只能接收 100 个请求,无论是否处于流量高峰,都按此速率限制 。
削峰:更关注将瞬时的高流量分散到一段时间内 ,重点处理流量峰值问题。比如通过消息队列暂存高并发请求,然后逐步处理,将瞬间的流量高峰分散开来 。
解决问题的阶段不同:
限流:是一种常态化的流量控制手段,在系统运行的各个阶段都起作用,用于保障系统资源合理分配和稳定运行 。
削峰:主要用于应对突发的流量高峰情况,是一种应对特殊场景(如秒杀、大型活动 )下高并发流量的策略 。
celot与Polly
celot 整合了 Polly ,通过集成 Polly 可实现强大的服务治理功能。以下是相关说明:
集成方式
引入包:需安装Ocelot.Provider.Polly包 。以.NET 项目为例,可在项目中使用 NuGet 包管理器进行安装,或者通过命令行Install - package Ocelot.Provider.Polly (针对.NET Framework 项目 )或dotnet add package Ocelot.Provider.Polly (针对.NET Core 项目 )安装。
添加依赖注入:在项目的Startup.cs文件中,于ConfigureServices方法里添加如下代码:
services.AddOcelot()
.AddPolly();
这行代码将 Polly 相关的服务注册到依赖注入容器中,使 Ocelot 能够使用 Polly 提供的各种策略。
配置文件设置 :在 Ocelot 的配置文件(如ocelot.json )中配置 Polly 相关策略参数。以熔断策略配置为例:
json
{
"Routes": [
{
"DownstreamPathTemplate": "/api/your - service - path",
"UpstreamPathTemplate": "/api/your - service - path",
"UpstreamHttpMethod": ["Get", "Post"],
"QoSOptions": {
"ExceptionsAllowedBeforeBreaking": 3, //允许多少个异常请求后触发熔断
"DurationOfBreak": 5000, //熔断持续时间,单位为毫秒
"TimeoutValue": 5000 //下游请求处理超时时间,单位为毫秒
}
}
]}
实现的功能:
1.熔断机制:当服务调用的错误率或延迟达到一定阈值,Ocelot 借助 Polly 的熔断策略,可断开后续请求与故障服务的连接,快速返回失败结果,防止故障扩散。例如,下游服务出现异常,连续 3 次请求失败后(依据上述配置 ),熔断器断开,在 5 秒(DurationOfBreak设置 )内请求该服务直接返回失败,5 秒后尝试半开状态,允许少量请求检测服务是否恢复。
2.超时设置:能为服务间的调用设置合理的超时时间,一旦请求处理时间超过TimeoutValue设定值,Ocelot 将请求视为超时,进行相应处理,避免请求长时间阻塞。
3.重试策略:Polly 的重试策略可使 Ocelot 在遇到可恢复性故障(如网络闪断 )时,自动重试请求,提升服务调用的成功率。例如,在调用下游服务因网络问题失败时,按照设定的重试规则重新发起请求。
gateway授权机制
Gateway 通常是具备授权机制的。
常见的授权方式
基于令牌的授权:客户端在登录或获取服务时,会从认证服务器获取一个令牌(如 JWT 令牌)。之后,客户端在每次请求中携带该令牌,Gateway 通过验证令牌的有效性、过期时间、权限范围等来决定是否允许请求通过。例如,在 OAuth 2.0 协议中,客户端获取访问令牌后,将其放在请求的 Authorization 头中,Gateway 根据令牌信息进行授权判断。
基于角色的访问控制(RBAC):将用户分配到不同的角色,每个角色被赋予一组特定的权限。Gateway 根据用户的角色来决定是否允许其访问特定的资源或执行特定的操作。比如,系统中有管理员、普通用户等角色,管理员角色可以访问和操作所有功能,而普通用户只能访问部分功能,Gateway 会根据用户所属角色来进行访问控制。
基于属性的访问控制(ABAC):根据请求的各种属性(如用户的属性、资源的属性、环境属性等)来进行授权决策。例如,根据用户的部门、请求的时间、请求的来源 IP 等多个属性综合判断是否允许访问。这种方式更加灵活,可以根据复杂的业务规则进行授权。
作用
保护后端服务:防止未经授权的用户访问敏感资源,确保只有具有适当权限的用户或应用程序能够与后端服务进行交互,从而提高系统的安全性。
实现细粒度的访问控制:可以根据不同的用户角色、权限或其他条件,对不同的资源或接口进行精确的访问控制,满足各种复杂的业务需求。
不同的 Gateway 实现可能会有不同的授权机制和配置方式,例如 Spring Cloud Gateway 可以通过集成 Spring Security 等框架来实现强大的授权功能,而 Nginx Gateway 也有自己的一套授权配置方法。但总体来说,授权机制是 Gateway 保障系统安全和正常运行的重要组成部分。
无状态协议
HTTP 无状态协议是指 HTTP 协议在设计上不会在不同的请求之间记住或保留任何有关客户端状态的信息。以下是对它的详细介绍:
定义与特点
无状态性:每个 HTTP 请求都是独立的,服务器在处理当前请求时,不会参考之前的请求信息,也不会在处理完当前请求后保存相关状态供后续请求使用。例如,用户在一个页面登录后,服务器处理完登录请求并返回响应后,就会忘记用户的登录状态。当下一个请求到来时,服务器不知道该用户是否已经登录过,除非通过其他方式(如在请求中携带特定的认证信息)来告知服务器。
优点:这种无状态特性使得 HTTP 协议简单且易于实现。服务器不需要为每个客户端维护复杂的状态信息,从而可以轻松处理大量并发请求,提高了服务器的性能和可扩展性。同时,也便于浏览器等客户端与不同的服务器进行交互,因为客户端不需要担心服务器会记住一些意外的状态而导致后续交互出现问题。
缺点:对于需要跟踪用户状态的应用程序,如电子商务网站的购物车功能、用户登录后的一系列操作等,无状态性会带来一些挑战。因为服务器无法自动识别同一个用户的不同请求之间的关联,需要通过其他技术手段来弥补,如使用会话机制、Cookie、令牌等技术来在多个请求之间维护用户状态。
实现机制
请求 - 响应模型:HTTP 基于请求 - 响应模型工作。客户端发送请求到服务器,服务器接收请求并处理,然后返回响应给客户端。完成这个过程后,连接就会被关闭(在非持久连接的情况下),或者可以被复用(在持久连接的情况下,但服务器仍然不会在连接上保留请求相关的状态信息)。每个请求和响应都是完整独立的,包含了完成本次交互所需的所有信息。
在 HTTP 无状态协议中,一次请求和二次请求没有直接关系。具体表现如下:
连接独立性:每次 HTTP 请求都是一个独立的连接(在非持久连接模式下)或在同一个连接上被视为独立的操作(在持久连接模式下)。服务器在处理完一次请求后,不会保留与该请求相关的连接状态信息。当二次请求到来时,即使是同一个客户端发出的,服务器也会将其视为一个全新的请求,重新建立连接(非持久连接)或重新进行请求处理流程(持久连接)。
数据无关联:一次请求所携带的参数、数据与二次请求的参数、数据相互独立。服务器不会自动将一次请求中的数据传递给二次请求,也不会默认二次请求与一次请求有任何逻辑上的关联。例如,在一个 Web 应用中,用户在第一次请求中查询了商品列表,然后在第二次请求中访问某个商品的详细信息,这两个请求在 HTTP 层面上是完全独立的,服务器不会自动将第一次请求中查询的商品列表信息与第二次请求中商品详细信息的请求进行关联,需要通过客户端在请求中明确指定相关信息(如商品 ID)来建立联系。
状态不记忆:服务器不会记住一次请求处理后的状态,并将其应用到二次请求中。如前面提到的用户登录场景,用户在第一次请求中进行登录操作,服务器验证用户身份并返回登录成功的响应,但在第二次请求时,服务器不会自动识别该用户已经登录过,除非客户端通过某种方式(如在请求头中携带登录令牌)告知服务器用户的登录状态。
Cookie 和 Session
在 Web 应用中,Cookie 和 Session 是用于跟踪用户状态的常用技术,以下是关于如何实现一次请求服务获取 Cookie,后续请求携带该 Cookie 来请求数据的介绍:
获取 Cookie
当用户首次访问服务器时,服务器会根据用户的请求生成一个唯一的 Session ID,并将其作为 Cookie 发送给客户端。例如,在ASP.NET中,可以使用以下代码生成并设置 Cookie:
csharp
HttpCookie cookie = new HttpCookie("SessionID", "unique_session_id");
Response.Cookies.Add(cookie);
在 Java Servlet 中,可以这样设置 Cookie:
java
Cookie cookie = new Cookie("SessionID", "unique_session_id");
response.addCookie(cookie);
这里的"unique_session_id"是服务器生成的唯一标识用户会话的字符串。客户端收到响应后,会将该 Cookie 存储在本地。
后续请求携带 Cookie
当客户端再次向服务器发送请求时,浏览器会自动在请求头中携带之前存储的 Cookie。例如,在 HTTP 请求头中会包含类似以下的信息:
plaintext
Cookie: SessionID=unique_session_id
服务器接收到请求后,会从请求头中解析出 Cookie,并根据其中的 Session ID 来识别用户的会话状态,从而获取与该用户相关的信息,如用户登录状态、购物车内容等。
通过这种方式,就可以实现一次请求服务获取 Cookie,后续请求都携带该 Cookie 来让服务器识别用户身份和跟踪用户状态,从而实现有状态的 Web 应用功能。不同的编程语言和框架都提供了相应的 API 来方便地处理 Cookie 和 Session 相关的操作。
Cookie 和 Session 主要是为了解决用户识别问题,同时也用于解决在 HTTP 无状态协议下的用户状态管理问题,以下是具体介绍:
用户识别:在 Web 应用中,服务器需要区分不同的用户。通过 Cookie 和 Session 机制,服务器为每个用户分配唯一的标识(Session ID),并通过 Cookie 将其发送给客户端。客户端在后续请求中携带该 Cookie,服务器就能根据其中的 Session ID 识别出用户,从而提供个性化的服务,比如根据用户的身份显示不同的界面内容、提供用户特定的信息等。
状态管理:HTTP 协议是无状态的,这意味着服务器在处理完一个请求后不会记住用户的相关信息。而 Cookie 和 Session 可以在多个请求之间维护用户的状态。例如,用户在购物网站上添加商品到购物车,通过 Session 可以在不同页面的请求中记住购物车中的商品信息,用户登录后,也能通过 Session 保持登录状态,使服务器在后续请求中知道该用户已登录,而无需用户在每次请求时都重新输入登录信息。
可以说通过 Cookie 等技术的辅助,HTTP 在一定程度上实现了有状态的功能,但从本质上讲,HTTP 协议本身仍然是无状态的。
Cookie 是存储在客户端浏览器中的一小段数据,当客户端向服务器发送请求时,会在请求头中携带相应的 Cookie 信息。服务器可以根据这些 Cookie 来识别用户身份、记录用户的偏好设置或跟踪用户的会话状态等,从而在多个请求之间维持一定的状态信息,让用户体验到连续的、有状态的服务。
然而,HTTP 协议本身的基本特性并没有改变,它依然不具备内在的状态记忆和管理机制。只是借助 Cookie 以及与之配合的服务器端 Session 等技术,使得 Web 应用能够模拟出有状态的行为,以满足各种复杂应用场景的需求。
Session ID 来识别用户的会话状态的原理
生成与初始存储
当用户首次访问 Web 应用程序时,服务器会为该用户创建一个唯一的 Session 对象,并生成一个对应的 Session ID。这个 ID 通常是一个由字母、数字组成的随机字符串,具有足够的长度和随机性,以确保在整个系统中几乎不可能出现重复。
服务器将 Session ID 发送给客户端,一般是通过在 HTTP 响应中设置一个名为Set-Cookie的头部字段,将 Session ID 作为一个名为JSESSIONID(在 Java Web 应用中常见)或其他类似名称的 Cookie 值发送给客户端。
客户端存储与发送
客户端浏览器接收到包含 Session ID 的响应后,会将其存储在本地的 Cookie 中。
后续该客户端对同一 Web 应用程序的所有请求都会在 HTTP 请求头中包含这个 Session ID 的 Cookie。这样,服务器就能够通过读取请求中的 Session ID 来识别该请求属于哪个用户的会话。
服务器端识别与状态管理
服务器在接收到带有 Session ID 的请求后,会根据这个 ID 在服务器内存或其他存储介质(如数据库)中查找对应的 Session 对象。
如果找到匹配的 Session 对象,服务器就可以获取并更新该会话的状态信息,如用户的登录状态、购物车内容、浏览历史等。
如果没有找到对应的 Session 对象,可能是因为 Session ID 无效(如被篡改或已过期),服务器会根据具体的业务逻辑来处理,比如要求用户重新登录或创建一个新的会话。
通过这种方式,Session ID 实现了在多个 HTTP 请求之间跟踪和识别用户的会话状态,使得 Web 应用程序能够为每个用户提供个性化的服务和体验,同时保证了不同用户之间会话状态的隔离和安全性。
会话粘滞
会话粘滞(Session Stickiness),也叫会话亲和性(Session Affinity),是一种在分布式系统或负载均衡环境中用于确保同一个客户端的所有请求都被路由到同一个服务器实例上的技术。以下是关于它的详细介绍:
原理
在分布式系统中,通常会有多个服务器实例共同处理客户端的请求。当客户端发起一个请求时,负载均衡器会根据一定的算法将请求分发到其中一个服务器实例上。如果没有会话粘滞机制,后续客户端的其他请求可能会被分发到不同的服务器实例上。而会话粘滞通过某种方式(如基于 IP 地址、特定的 Cookie 或请求头信息等),使负载均衡器能够识别出是同一个客户端的请求,并始终将这些请求路由到之前处理过该客户端请求的同一服务器实例上,这样就保证了客户端与服务器之间的会话状态能够被正确维护,因为服务器实例在处理请求过程中可能会在内存或其他存储中保存与该客户端会话相关的信息,如用户登录状态、购物车内容等。
实现方式
基于 IP 地址:负载均衡器根据客户端的 IP 地址来进行会话粘滞。它会将来自同一个 IP 地址的请求始终路由到同一个服务器实例上。这种方式简单直接,但如果客户端处于一个共享 IP 的环境中(如通过代理服务器或在企业局域网中),可能会导致多个不同用户的请求被错误地路由到同一个服务器实例上。
基于 Cookie:服务器在客户端首次请求时,会在响应中设置一个特殊的 Cookie,其中包含了用于标识服务器实例的信息。后续客户端的请求都会携带这个 Cookie,负载均衡器根据 Cookie 中的信息将请求路由到对应的服务器实例。这种方式相对灵活且准确,但如果客户端禁用了 Cookie,就无法正常工作。
基于请求头信息:某些特定的请求头字段可以被用来实现会话粘滞。例如,服务器可以在响应中添加一个自定义的请求头,指示客户端后续请求应该被路由到的服务器实例。负载均衡器则根据这个请求头信息来进行请求的路由。这种方式需要客户端和服务器以及负载均衡器之间进行额外的配置和协作。
应用场景
有状态的 Web 应用:如电子商务网站、在线银行等,用户在进行一系列操作时需要保持会话状态,确保购物车内容、交易记录等信息在多个请求之间能够正确传递和处理。
分布式缓存系统:当客户端频繁访问分布式缓存中的数据时,会话粘滞可以确保客户端的请求始终到达同一个缓存节点,提高缓存命中率,减少数据在不同节点之间的传输和重复查找。
实时通信应用:例如在线客服系统、即时通讯应用等,需要保证同一个客户端的消息能够被准确地路由到对应的服务器实例进行处理,以维持实时通信的连贯性和稳定性。
session共享
session共享,可以通过redis来实施,确保多台服务器都可以被访问,而不是绝对的回话粘滞
Session 共享可以通过 Redis 来实现。以下是具体的实施方式及相关原理:
基本原理
将 Session 数据存储在 Redis 中,而不是传统的服务器本地内存或文件系统中。当用户发起请求时,服务器从 Redis 中读取对应的 Session 数据进行处理,并在 Session 数据发生变化时将其写回 Redis。这样,不同服务器实例在处理同一用户的请求时,都可以从 Redis 中获取到相同的 Session 数据,从而实现 Session 共享。
实施步骤
引入 Redis 客户端库:在项目中引入与所使用的编程语言对应的 Redis 客户端库,如在 Java 中可以使用 Jedis、Redisson 等,在 Python 中可以使用 redis-py 等。这些库提供了与 Redis 进行交互的 API。
配置 Redis 连接:在应用程序中配置 Redis 服务器的连接信息,包括主机地址、端口号、密码(如果有)等。确保应用程序能够正确连接到 Redis 服务器。
创建 Session 存储逻辑:当用户登录或创建新的 Session 时,生成一个唯一的 Session ID,并将相关的 Session 数据(如用户信息、登录状态、购物车内容等)以键值对的形式存储到 Redis 中。其中,键可以是 Session ID,值可以是序列化后的 Session 数据对象。例如,在 Java 中可以使用ObjectOutputStream将对象序列化为字节数组后存储,在 Python 中可以使用pickle模块进行序列化。
获取 Session 数据:在处理用户的后续请求时,从请求中提取 Session ID,然后根据 Session ID 从 Redis 中获取对应的 Session 数据。将获取到的字节数组或序列化数据反序列化为对象,以便在应用程序中使用。
更新 Session 数据:当 Session 数据发生变化时,如用户添加商品到购物车或修改个人信息,及时将更新后的 Session 数据写回 Redis。可以通过覆盖原来的键值对来实现。
设置 Session 过期时间:为了避免 Session 数据在 Redis 中无限期存储,需要设置合适的过期时间。可以在将 Session 数据存储到 Redis 时,使用EXPIRE命令设置过期时间,单位为秒。例如,设置 Session 的过期时间为 30 分钟,可以使用EXPIRE session_id 1800命令。这样,Redis 会自动在指定的时间后删除过期的 Session 数据。
通过以上步骤,就可以利用 Redis 实现 Session 共享,使得分布式系统中的多个服务器实例能够共享和管理用户的 Session 数据,提高系统的可扩展性和可靠性。
single sign on单点登录,多点生效
单点登录(Single Sign-On,SSO)是一种身份验证机制,允许用户在多个相关但独立的系统中进行身份验证,只需在一个系统中登录一次,就可以访问其他相互信任的系统,而无需再次输入用户名和密码。以下是单点登录在多个系统中生效的原理和常见实现方式的介绍:
原理
统一身份认证:单点登录系统(SSO Server)作为统一的身份认证中心,负责用户的登录认证和身份管理。用户访问多个相关系统中的任意一个时,若检测到用户未登录,会将用户重定向到单点登录系统进行登录。
票据生成与传递:用户在单点登录系统成功登录后,单点登录系统会为用户生成一个唯一的票据(Ticket),并将用户重定向回最初访问的系统,同时在重定向的 URL 中携带该票据。
系统间信任建立:各个相关系统与单点登录系统之间建立信任关系,这些系统能够验证单点登录系统颁发的票据的有效性。当用户携带票据访问其他系统时,被访问系统会向单点登录系统验证票据的合法性。如果票据有效,单点登录系统会返回用户的身份信息,被访问系统根据这些信息为用户创建本地会话,从而实现用户在该系统中的登录状态,用户即可访问相应的资源。
实现方式
基于 CAS 的单点登录:CAS(Central Authentication Service)是一种开源的单点登录系统。它包含一个服务器(CAS Server)和客户端(CAS Client)。CAS Server 负责用户的登录认证和票据管理,CAS Client 集成在各个需要单点登录的应用系统中,负责与 CAS Server 进行交互,完成用户的登录和注销等功能。当用户访问应用系统时,CAS Client 会检查用户是否已经登录,如果未登录则重定向到 CAS Server 进行登录。用户登录成功后,CAS Server 会为用户生成票据,并将用户重定向回应用系统,CAS Client 通过验证票据的有效性来确定用户的身份。
基于 OAuth 的单点登录:OAuth 是一种授权框架,也可以用于实现单点登录。在这种方式下,单点登录系统作为授权服务器,各个应用系统作为资源服务器。用户在单点登录系统上授权应用系统访问其资源,应用系统通过获取用户的授权令牌来访问单点登录系统提供的用户信息,从而实现用户在应用系统中的登录。例如,用户可以使用微信账号登录多个第三方应用,微信就是单点登录系统,第三方应用通过 OAuth 协议与微信进行交互,获取用户的身份信息进行登录。
基于 SAML 的单点登录:SAML(Security Assertion Markup Language)是一种基于 XML 的标准,用于在不同的安全域之间交换身份验证和授权信息。单点登录系统使用 SAML 来生成和发送用户的身份断言(Assertion),应用系统通过解析和验证 SAML 断言来确定用户的身份和权限。当用户登录单点登录系统后,单点登录系统会生成包含用户身份信息的 SAML 断言,并将其发送给应用系统,应用系统验证断言的有效性后,即可为用户建立登录状态。
HTTP 协议特性与用户识别需求
无状态性:Web 应用基于 HTTP 协议,它是无状态协议,即每次请求相互独立,第一次和第二次请求毫无关联 。比如在电商网站,用户首次请求商品列表页,第二次请求商品详情页,服务器不会自动关联这两次请求 。
用户识别手段:但实际应用有用户识别需求,于是引入 Cookie 和 Session 。用户首次请求服务器,服务器返回包含 Cookie 的响应,Cookie 是一小段文本 。每次 HTTP 请求都带上 Cookie ,服务器端依据 Cookie 创建并保存对应的 Session 标识 。以用户登录为例,登录时服务器生成包含用户信息的 Cookie ,后续请求携带该 Cookie ,服务器通过对应 Session 识别用户,让无状态的 HTTP 请求能处理用户状态相关事务,一定程度上模拟有状态请求 。
有状态实现的问题与应对方案
集群环境问题:在集群环境下,单纯基于 Cookie 和 Session 实现有状态请求会出问题。不同服务器实例各自维护 Session ,一个服务器保存的 Session 信息,其他服务器无法识别 。例如用户在服务器 A 登录并将商品加入购物车(保存在服务器 A 的 Session ),后续请求被转发到服务器 B ,服务器 B 无法获取服务器 A 上的购物车信息 。
解决方案:
会话粘滞:通过特定策略,如基于 IP 地址、Cookie 等,让负载均衡器将同一客户端请求始终路由到同一服务器实例,保证会话状态能被正确维护 。但存在局限性,如客户端 IP 共享或禁用 Cookie 时会失效 。
Redis 共享 Session:把 Session 数据存储在 Redis 中,各服务器实例都从 Redis 读写 Session 数据,实现 Session 共享 。像分布式电商系统,不同服务器处理同一用户请求时,都能从 Redis 获取相同购物车等 Session 信息 。
单点登录面临的挑战
即便有上述方案,仍可能面临 Session 无法共享的情况,比如技术实现门槛高,存在兼容性等问题 。
单点登录(Single Sign On)旨在实现用户一处登录,在多个系统、跨数据中心、跨机房都能生效 ,甚至涉及第三方支持 。但并非所有数据都能共享,难以进行集中式验证 。例如不同企业系统间进行单点登录集成,因数据安全、格式差异等,难以做到完美的数据共享和集中验证 。
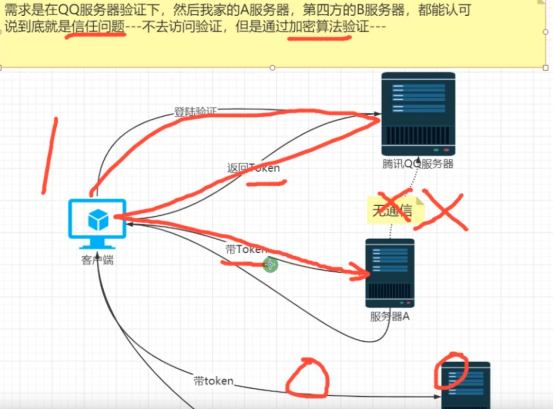
需求核心与问题本质
需求:实现用户在客户端登录时,借助 QQ 服务器进行验证,验证通过后,自家的 A 服务器以及第四方的 B 服务器都能认可该用户已通过验证的状态,从而允许用户访问相关服务或资源 。
问题本质:核心是信任问题 。即 A 服务器和 B 服务器如何在不直接与 QQ 服务器通信(图中 “无通信” 标识 )的情况下,信任 QQ 服务器给出的验证结果 。
解决方案思路
不直接访问验证:不采用 A 服务器和 B 服务器直接向 QQ 服务器询问 “该用户是否通过验证” 这种传统的访问验证方式 。
加密算法验证:期望利用加密算法来解决信任问题 。具体流程为:
登录验证与 Token 获取:客户端向 QQ 服务器发起登录验证请求。QQ 服务器验证用户身份信息(如账号、密码等 ),若验证通过,使用特定加密算法生成一个 Token(令牌 ),并返回给客户端 。这个 Token 包含了能证明用户已通过验证的相关信息,且通过加密保证其安全性和完整性 。
携带 Token 访问其他服务器:客户端携带从 QQ 服务器获取的 Token,分别向 A 服务器和 B 服务器发起请求 。A 服务器和 B 服务器接收到请求及其中的 Token 后,利用与 QQ 服务器约定好的加密算法(比如相同的密钥、哈希算法等 )对 Token 进行验证 。若验证通过,就认可用户已通过 QQ 服务器的验证,进而为用户提供相应服务 。 这样即使 A 服务器、B 服务器与 QQ 服务器之间没有直接通信,也能基于加密算法对 Token 的验证来信任 QQ 服务器的验证结果,实现跨服务器的用户身份认可 。
跨服务器的用户身份认可
跨服务器的用户身份认可,是指在多个不同服务器组成的系统环境下,确保用户在一处通过身份验证后,在其他服务器也能被正确识别并认可其身份 ,主要涉及以下方面:
实现方式
基于 Token 的方式:
原理:用户在某一服务器(如认证服务器 )上完成身份验证后,该服务器生成一个包含用户身份信息(如用户 ID、权限等 )的 Token ,通常采用 JWT(JSON Web Token) 。Token 使用加密算法进行签名,确保其不可篡改 。用户携带此 Token 访问其他服务器时,这些服务器通过验证 Token 的签名(利用与认证服务器共享的密钥 )来确认 Token 的合法性和真实性,进而认可用户身份 。
示例:在一个电商系统中,用户登录时由登录服务器进行身份验证,生成 JWT Token 。用户后续访问商品详情服务器、购物车服务器等,都携带该 Token ,这些服务器通过验证 Token,识别出用户身份,提供个性化服务,如显示用户收藏的商品、购物车内容等 。
基于 Cookie 和 Session 的方式:
原理:用户首次访问服务器时,服务器创建一个 Session ,并将 Session ID 以 Cookie 的形式返回给客户端 。客户端后续请求都携带此 Cookie 。若涉及多个服务器,可通过会话粘滞(负载均衡器将同一客户端请求始终路由到同一服务器 )确保 Session 被正确访问;或采用 Session 共享技术(如通过 Redis 存储 Session 数据 ),使不同服务器都能读取和更新相同的 Session 信息,从而实现对用户身份的一致认可 。
示例:在一个论坛系统中,用户登录后,服务器创建 Session 记录用户登录状态等信息,将 Session ID 存入 Cookie 。用户在不同页面跳转(涉及不同服务器处理 )时,服务器依据 Cookie 中的 Session ID,通过共享的 Redis 获取 Session 信息,确认用户身份及权限,如判断用户是否能发帖、回帖等 。
单点登录(SSO):
原理:存在一个统一的身份认证中心(SSO Server ) 。用户访问多个相关系统中的任意一个时,若未登录,被重定向到 SSO Server 登录 。登录成功后,SSO Server 生成票据或 Token ,并在用户访问其他系统时,由这些系统向 SSO Server 验证票据或 Token 有效性,或通过共享密钥直接验证 Token ,确认用户身份 。
示例:企业内部有办公系统、财务系统、人力资源系统等多个系统 。员工通过企业统一身份认证平台(SSO Server )登录后,访问其他系统时无需再次登录,各系统通过与 SSO Server 交互或验证 Token,认可员工身份并提供相应服务 。
面临挑战
安全性问题:在跨服务器传递身份信息过程中,若 Token 或 Cookie 被窃取,攻击者可能冒用用户身份 。需采用安全的加密算法、传输协议(如 HTTPS )等保障信息安全 。
兼容性问题:不同服务器可能采用不同技术栈和框架,在实现身份认可机制时,需解决技术差异带来的兼容性问题,确保身份信息能正确传递和验证 。
性能问题:频繁验证身份信息(如验证 Token 签名 )可能影响系统性能 。可通过合理缓存、优化算法等方式提升性能 。
非对称可逆加密
非对称可逆加密指非对称加密算法,它是一种密钥保密方法,加密和解密使用不同密钥,且加密后的数据能通过对应密钥还原为原始数据 。以下是详细介绍:
原理
非对称加密需要一对密钥,即公钥和私钥 ,二者成对出现,在数学上彼此关联 。公钥可公开分享,私钥由密钥所有者严格保密 。
若用公钥加密数据,只有对应的私钥能解密 ;反之,用私钥加密的数据,也只有对应的公钥可解密 。比如在安全通信中,信息发送方用接收方公钥加密信息,接收方收到后用自己的私钥解密获取原文 。
典型算法及应用
RSA:最经典的非对称加密算法之一,基于大整数分解难题 。常用于数字签名、密钥交换和数据加密等场景 。如 HTTPS 协议中,就常用 RSA 进行密钥交换,保障通信安全 。
椭圆曲线加密算法(ECC):基于椭圆曲线离散对数问题 。与 RSA 相比,在同等安全强度下,ECC 可用更短密钥实现更高安全性,计算效率高,常用于移动设备、资源受限环境及对安全性要求高的场景 。
优势
安全性高:因加密和解密密钥不同,且从公钥难以推算出私钥 ,攻击者即便截获密文和公钥,也无法解密数据 。
便于密钥管理:公钥可公开,无需像对称加密那样复杂地传输和管理共享密钥 ,解决了对称加密中密钥配送难题 。
可实现数字签名:用私钥加密数据可实现数字签名 ,接收方用公钥验证,能确认数据来源真实性和完整性,还能防止抵赖 。
不足
运算速度慢:相比对称加密,非对称加密算法复杂,加密和解密速度慢 ,不适合加密大量数据 。实际应用中常结合对称加密,用非对称加密传输对称加密的密钥,再用对称加密处理大量数据 。
计算资源消耗大:算法涉及复杂数学运算,对计算资源要求高 ,在资源受限设备上使用可能受限制 。
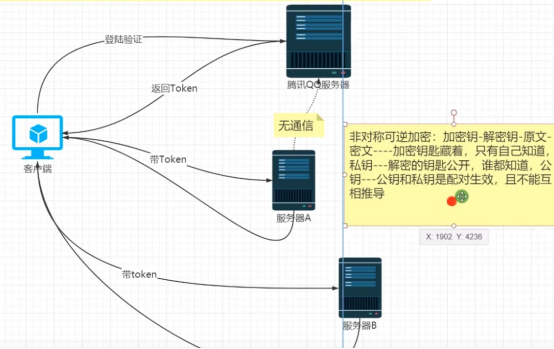
整体架构与流程
用户登录验证:客户端向腾讯 QQ 服务器发起登录验证请求 。QQ 服务器对用户身份进行验证,如检查账号密码是否正确 。
Token 返回:若验证通过,QQ 服务器生成一个 Token ,并返回给客户端 。这个 Token 包含了用户已通过验证的相关信息,用于证明用户身份 。
跨服务器访问:客户端携带从 QQ 服务器获取的 Token,分别向服务器 A 和服务器 B 发起请求 。服务器 A 和服务器 B 在接收到请求及 Token 后,需要对 Token 的合法性进行验证,以此认可用户身份并提供相应服务 。同时,图中表明腾讯 QQ 服务器与服务器 A、服务器 B 之间 “无通信”,意味着服务器 A 和 B 不能直接向 QQ 服务器询问 Token 的有效性 。
非对称可逆加密原理及应用关联
加密原理说明:图中右侧文字介绍了非对称可逆加密 ,其加密和解密使用不同密钥 。私钥由密钥所有者秘密持有,公钥则公开 。公钥和私钥配对使用,且无法从一个密钥推导出另一个 。
在该架构中的应用推测:在这个跨服务器身份认可场景中,QQ 服务器可能使用私钥对生成的 Token 进行签名(类似加密操作 ) 。服务器 A 和服务器 B 在接收到 Token 后,使用 QQ 服务器公开的公钥来验证 Token 的签名(类似解密操作 ) 。通过验证签名,服务器 A 和 B 就能确认 Token 确实是由 QQ 服务器生成且未被篡改,进而认可用户通过了 QQ 服务器的身份验证 。这样即使 QQ 服务器与服务器 A、B 之间没有直接通信,也能基于非对称加密的特性,实现对用户身份的跨服务器认可 。
HTTP 请求转换为 gRPC 请求
要将 HTTP 请求转换为 gRPC 请求,涉及理解两种通信方式差异,并按步骤进行转换,以下是具体说明:
了解 HTTP 与 gRPC
HTTP:超文本传输协议,是 Web 应用广泛使用的通信协议 ,基于请求 - 响应模式,以文本形式传输数据,如 JSON、XML 。
gRPC:Google 开源的高性能、通用的 RPC(远程过程调用)框架 ,基于二进制协议传输,使用 Protobuf 定义服务和消息结构,能在多种语言间高效通信。
转换步骤
定义服务和消息结构(使用 Protobuf )
编写.proto文件 ,定义 gRPC 服务接口和消息类型。例如,若原 HTTP 请求是获取用户信息,假设 HTTP 请求是GET /users/{id} ,响应是 JSON 格式的用户信息 。在.proto文件中可这样定义:
protobuf
syntax = "proto3";
package user_service;
// 定义请求消息,包含用户IDmessage GetUserRequest {
string user_id = 1;}
// 定义响应消息,包含用户信息message User {
string id = 1;
string name = 2;
string email = 3;}message GetUserResponse {
User user = 1;}
// 定义服务接口service UserService {
rpc GetUser(GetUserRequest) returns (GetUserResponse);}
生成代码
使用 Protobuf 编译器(protoc )结合对应语言插件,生成服务端和客户端代码。比如在 Go 语言中,安装相关插件后,执行protoc --go_out=./ --go-grpc_out=./ user_service.proto ,会生成与.proto文件定义对应的 Go 语言代码,包含服务接口和消息结构体等定义 。
实现 gRPC 服务端
依据生成的代码框架,编写服务端逻辑。如在 Go 语言中:
go
package main
import (
"context"
"github.com/[你的项目路径]/user_service"
"google.golang.org/grpc"
"log"
"net")
// 实现UserServiceServer接口type userServiceImpl struct {
user_service.UnimplementedUserServiceServer}
func (u *userServiceImpl) GetUser(ctx context.Context, req *user_service.GetUserRequest) (*user_service.GetUserResponse, error) {
// 这里编写获取用户信息的逻辑,比如从数据库查询
user := &user_service.User{
id: req.user_id,
name: "示例姓名",
email: "example@example.com",
}
return &user_service.GetUserResponse{user: user}, nil}
func main() {
lis, err := net.Listen("tcp", ":50051")
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
user_service.RegisterUserServiceServer(s, &userServiceImpl{})
if err := s.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}}
实现 gRPC 客户端
同样根据生成的代码,编写客户端调用逻辑。还是以 Go 语言为例:
go
package main
import (
"context"
"fmt"
"github.com/[你的项目路径]/user_service"
"google.golang.org/grpc")
func main() {
conn, err := grpc.Dial(":50051", grpc.WithInsecure())
if err != nil {
fmt.Printf("did not connect: %v", err)
return
}
defer conn.Close()
c := user_service.NewUserServiceClient(conn)
req := &user_service.GetUserRequest{user_id: "123"}
resp, err := c.GetUser(context.Background(), req)
if err != nil {
fmt.Printf("could not get user: %v", err)
return
}
fmt.Printf("User: %v", resp.user)}
注意事项
数据映射:需仔细将 HTTP 请求参数、请求体内容映射到 Protobuf 定义的消息结构中 ,响应数据同理。
错误处理:gRPC 有自己的错误处理机制,要妥善处理调用过程中的错误,如连接错误、服务端返回的业务错误等 。
兼容性:若系统仍有部分依赖 HTTP 通信,需考虑两种通信方式共存及数据交互的兼容性 。