目录
- 临界点critical point
- 基本介绍
- 临界点两种情况的区分
- g和H的举例介绍
- 根据H区分Saddle Point和local minima
- 批次Batch
- batch大小的比较
- 时间的开销
- 训练集和测试集的效果
- 训练集效果
- 测试集效果
- batch大小的比较
- 动量Momentum
- 一般的Gradient Descent
- 带有动量的Gradient Descent
2021 - 类神经网络训练不起来怎么办(一) 局部最小值 (local minima) 与鞍点 (saddle point)
临界点critical point
基本介绍
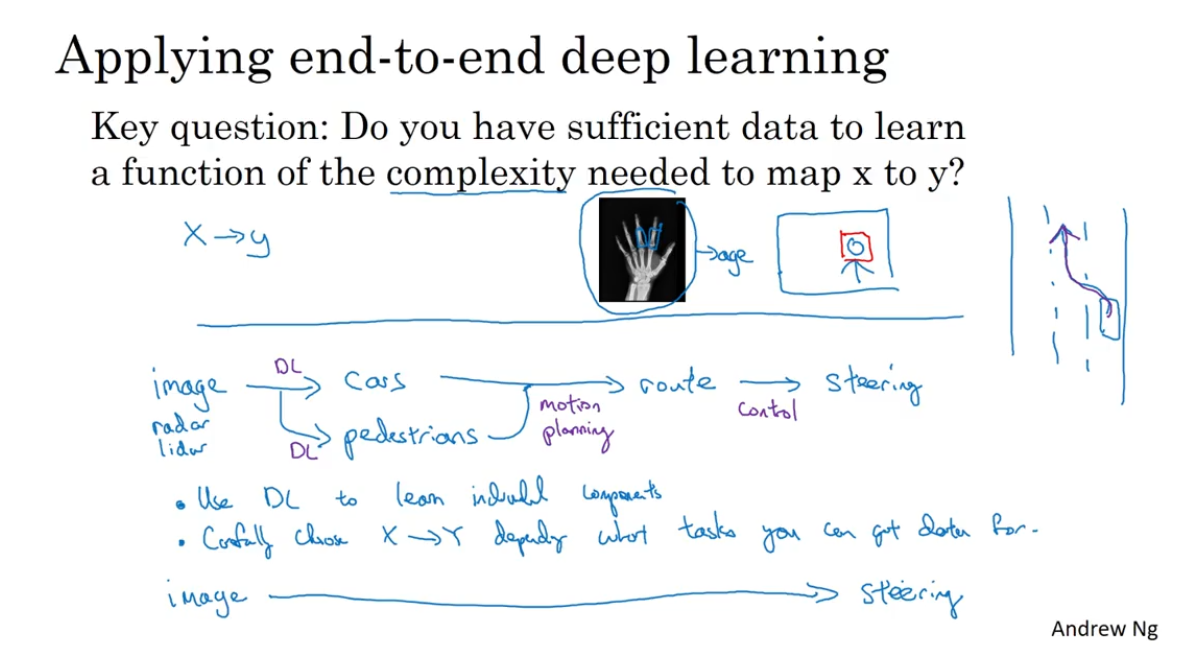
导致更复杂的model并没有充分发挥它的作用造成训练集loss较大的原因主要是训练过程中过早地出现偏导gradient=0(因为参数更新的公式为$
w_{i+1}=w_i-\eta \times \frac{\partial loss}{\partial w}|_{w=w^0}
$)。而偏导gradient=0的情况既有遇到了局部最优解local minima也有遇到了鞍点saddle
point。这两种情况统称为遇到了**临界点critical point.**local
minima时没有可选的更新路径。而saddle point仍有另外方向的更新路径,如下图。

临界点两种情况的区分
利用泰勒级数逼近(函数在某一点的泰勒展开)的方法
函数在某一点x0的泰勒展开的公式为: f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 + … … f(x)=f(x_0)+f'(x_0)(x-x_0)+\frac 1 2f''(x_0)(x-x_0)^2+…… f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+……
则Loss在某一点θ0附近的泰勒展开公式为L o s s ( θ ) = L o s s ( θ 0 ) + ( θ − θ 0 ) × g + 1 2 ( θ − θ 0 ) T H ( θ − θ 0 ) , g = L o s s 对每个参数的一阶导向量 , H 为 L o s s 的黑塞 H e s s i a n 矩阵 Loss(\theta)=Loss(\theta_0)+(\theta-\theta_0) \times g+\frac 1 2 (\theta-\theta_0)^TH(\theta-\theta_0), g=Loss对每个参数的一阶导向量,H为Loss的黑塞Hessian矩阵 Loss(θ)=Loss(θ0)+(θ−θ0)×g+21(θ−θ0)TH(θ−θ0),g=Loss对每个参数的一阶导向量,H为Loss的黑塞Hessian矩阵

g和H的举例介绍
以Loss(w,b)为例,则g和H见下
g = [ ∂ L o s s ∂ w , ∂ L o s s ∂ b ] , H = ( ∂ 2 L o s s ∂ w 2 ∂ 2 L o s s ∂ w ∂ b ∂ 2 L o s s ∂ b ∂ w ∂ 2 L o s s ∂ b 2 ) g=[\frac{\partial Loss}{\partial w},\frac{\partial Loss}{\partial b}],H=\left( \begin{array} {cc} \frac{\partial ^2 Loss}{\partial w^2} & \frac{\partial ^2 Loss}{\partial w \partial b} \\ \frac{\partial ^2 Loss}{\partial b \partial w} & \frac{\partial ^2 Loss}{\partial b^2} \\ \end{array} \right) g=[∂w∂Loss,∂b∂Loss],H=(∂w2∂2Loss∂b∂w∂2Loss∂w∂b∂2Loss∂b2∂2Loss)
根据H区分Saddle Point和local minima
特征值的求法:矩阵A的特征值:|λE-A|=0的λ解
特征向量:将求出来的每个特征值λ代入(A-λE)x=0,解出所有的x即为特征向量临界点的gradient为0,即g为0。故Loss的泰勒逼近函数只剩下了H项,函数如下。若对于θ0附近的所有θ:
L o s s ( θ ) = L o s s ( θ 0 ) + 1 2 ( θ − θ 0 ) T H ( θ − θ 0 ) , H 为 L o s s 的黑塞 H e s s i a n 矩阵 Loss(\theta)=Loss(\theta_0)+\frac 1 2 (\theta-\theta_0)^TH(\theta-\theta_0),H为Loss的黑塞Hessian矩阵 Loss(θ)=Loss(θ0)+21(θ−θ0)TH(θ−θ0),H为Loss的黑塞Hessian矩阵
若**(θ-θ0)TH(θ-θ0)>0** **,则对于任意附近的θ 有Loss(θ)>Loss(θ0),θ0为Local Minima。此时H的特征值均为正——正定矩阵**
若**(θ-θ0)TH(θ-θ0)<0** ,则对于任意附近的θ 有Loss(θ)<Loss(θ0),θ0为Local Maxima。此时H的特征值均为负
若**(θ-θ0)TH(θ-θ0)>0与(θ-θ0)TH(θ-θ0)<0同时存在** ,则θ0为saddle point,此时H的特征值有正有负
**此时可根据负根的特征向量往更小的地方更新参数,原理如下:**设x=θ-θ0,若x为特征向量,则xTHx=xT(Hx)=xT(λx)=λ(xTx)=λ|x||x|。此时若λ为负,则Loss(θ)<Loss(θ0)实现了Loss的减少,而θ=θ0+x
θ = θ 0 + x \theta=\theta_0+x θ=θ0+x

实际上不会用H去区分,因为计算量大 低维度的local minima很多都是高纬度的saddle point,因此日常训练中saddle point更为常见
批次Batch
一个batch内有一定量的样本,每个batch内样本数相同。batch内的所有样本计算一次loss,用于更新模型内参数。所有的batch全计算过一遍后称为一次迭代epoch。每次epoch前都需要随机选择参数初始值,随机划分batch。

batch大小的比较
batch内的大小决定了一次epoch内更新参数的次数也决定了batch内所有样本计算loss的时间开销
时间的开销


若不采用GPU并行计算,则batch内样本数量越多,花费时间越多,否则花费时间越少。若采用GPU并行计算,则batch内样本在一定大数内计算花费时间是几乎一样的。
而在一次epoch内,batch内样本数量越多,batch的数量越少,一次epoch花费的时间越少,参数的更新也越相对稳定。而batch内样本数量越少,batch的数量越多,一次epoch花费的时间越多,参数的更新越noise。
📌从花费时间上来说,大的batch size更好
训练集和测试集的效果
训练集效果


小的batch size的noise更有利于训练,大的batch size反而会导致optimization的问题 原因:小的batch size会有更多的batch
num。因为不同的batch的Loss函数不同,从而使得临界点不同,从而能够更多次地更新参数,比大的batch
size更能避免gradient=0的情况
测试集效果


原因:小的batch
size会产生更有容错的model(盆地),从而会使结果与实际结果相差较小。而大的batch
size会有较低的容错可能(峡谷),从而与实际结果相差较大。
小的batch更有利于训练集的训练和测试集的预测

动量Momentum

动量的定义是给模型一个动力,让其在gradient=0的local minima仍能走出
一般的Gradient Descent
w i + 1 = w i − η × ∂ l o s s ∂ w ∣ w = w 0 w_{i+1}=w_i-\eta \times \frac{\partial loss}{\partial w}|_{w=w^0} wi+1=wi−η×∂w∂loss∣w=w0

带有动量的Gradient Descent
带有动量的Gradient Descent每次更新时更新的量是上一次的更新量*λ减去这一次的η*gradient
θ 0 , m 0 = 0 , θ 1 = θ 0 + m 1 , m 1 = λ m 0 − η g 0 , θ 2 = θ 1 + m 2 , m 2 = λ m 1 − η g 1 \theta^0,m^0=0, \theta^1=\theta^0+m^1,m^1=\lambda m^0-\eta g^0, \theta^2=\theta^1+m^2,m^2=\lambda m^1-\eta g^1 θ0,m0=0,θ1=θ0+m1,m1=λm0−ηg0,θ2=θ1+m2,m2=λm1−ηg1
总结公式如下:
θ i = θ i − 1 − η λ i − 1 g 0 − η λ i − 2 g 1 − … … − η g i − 1 , 初始时为 θ 0 , 且后续不重复 \theta^i=\theta^{i-1}-\eta \lambda ^{i-1}g^0-\eta \lambda ^{i-2}g^1-……-\eta g^{i-1},初始时为\theta^0,且后续不重复 θi=θi−1−ηλi−1g0−ηλi−2g1−……−ηgi−1,初始时为θ0,且后续不重复