批处理系统
批处理系统 (Batch System) ,它可用来管理无需或仅需少量用户交互即可运行的程序,在资源允许的情况下它可以自动安排程序的执行,这被称为“批处理作业”。
特权机制
实现特权级机制的根本原因是应用程序运行的安全性不可充分信任。
确保操作系统的安全,对应用程序而言,需要限制的主要有两个方面:
- 应用程序不能访问任意的地址空间
- 应用程序不能执行某些可能破坏计算机系统的指令
为了实现这样的特权级机制,需要进行软硬件协同设计。一个比较简洁的方法就是,处理器设置两个不同安全等级的执行环境:用户态特权级的执行环境和内核态特权级的执行环境。且明确指出可能破坏计算机系统的内核态特权级指令子集,规定内核态特权级指令子集中的指令只能在内核态特权级的执行环境中执行。处理器在执行指令前会进行特权级安全检查,如果在用户态执行环境中执行这些内核态特权级指令,会产生异常。
为了让应用程序获得操作系统的函数服务,采用传统的函数调用方式(即通常的 call 和 ret 指令或指令组合)将会直接绕过硬件的特权级保护检查。所以可以设计新的机器指令:执行环境调用(Execution Environment Call,简称 ecall )和执行环境返回(Execution Environment Return,简称 eret )):
-
ecall :具有用户态到内核态的执行环境切换能力的函数调用指令
-
eret :具有内核态到用户态的执行环境切换能力的函数返回指令
RISC-V 特权级架构
RISC-V 架构中一共定义了 4 种特权级:
RISC-V 特权级
| 级别 | 编码 | 名称 |
|---|---|---|
| 0 | 00 | 用户/应用模式 (U, User/Application) |
| 1 | 01 | 监督模式 (S, Supervisor) |
| 2 | 10 | 虚拟监督模式 (H, Hypervisor) |
| 3 | 11 | 机器模式 (M, Machine) |
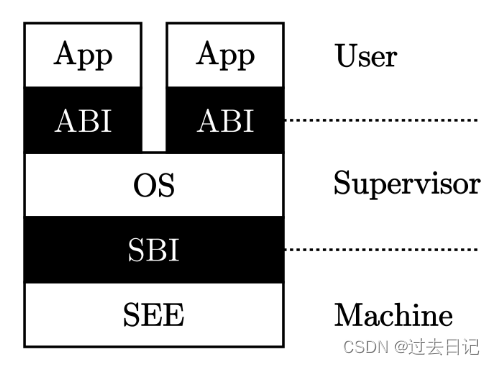
白色块表示一层执行环境,黑色块表示相邻两层执行环境之间的接口。这张图片给出了能够支持运行 Unix 这类复杂系统的软件栈。其中操作系统内核代码运行在 S 模式上;应用程序运行在 U 模式上。运行在 M 模式上的软件被称为 监督模式执行环境 (SEE, Supervisor Execution Environment),如在操作系统运行前负责加载操作系统的 Bootloader – RustSBI。站在运行在 S 模式上的软件视角来看,它的下面也需要一层执行环境支撑,因此被命名为 SEE,它需要在相比 S 模式更高的特权级下运行,一般情况下 SEE 在 M 模式上运行。
RISC-V的特权指令
与特权级无关的一般的指令和通用寄存器 x0 ~ x31 在任何特权级都可以执行。而每个特权级都对应一些特殊指令和 控制状态寄存器 (CSR, Control and Status Register) ,来控制该特权级的某些行为并描述其状态。当然特权指令不仅具有读写 CSR 的指令,还有其他功能的特权指令。
| 指令 | 含义 |
|---|---|
| sret | 从 S 模式返回 U 模式:在 U 模式下执行会产生非法指令异常 |
| wfi | 处理器在空闲时进入低功耗状态等待中断:在 U 模式下执行会产生非法指令异常 |
| sfence.vma | 刷新 TLB 缓存:在 U 模式下执行会产生非法指令异常 |
| 访问 S 模式 CSR 的指令 | 通过访问 sepc/stvec/scause/sscartch/stval/sstatus/satp等CSR 来改变系统状态:在 U 模式下执行会产生非法指令异常 |
实现应用程序
应用程序的设计实现要点是:
-
应用程序的内存布局
-
应用程序发出的系统调用
应用程序设计
应用程序、用户库(包括入口函数、初始化函数、I/O 函数和系统调用接口等多个 rs 文件组成)放在项目根目录的 user 目录下,它和第一章的裸机应用不同之处主要在项目的目录文件结构和内存布局上:
-
user/src/bin/*.rs :各个应用程序
-
user/src/*.rs :用户库(包括入口函数、初始化函数、I/O 函数和系统调用接口等)
-
user/src/linker.ld :应用程序的内存布局说明。
项目结构
我们看到 user/src 目录下面多出了一个 bin 目录。bin 里面有多个文件,目前里面至少有三个程序(一个文件是一个应用程序),分别是:
-
hello_world :在屏幕上打印一行 Hello world from user mode program!
-
store_fault :访问一个非法的物理地址,测试批处理系统是否会被该错误影响
-
power :不断在计算操作和打印字符串操作之间进行特权级切换
批处理系统会按照文件名开头的数字编号从小到大的顺序加载并运行它
每个应用程序的实现都在对应的单个文件中。打开其中一个文件,会看到里面只有一个 main 函数和若干相关的函数所形成的整个应用程序逻辑。
在 lib.rs 中我们定义了用户库的入口点 _start :
#[no_mangle]
#[link_section = ".text.entry"]
pub extern "C" fn _start() -> ! {
clear_bss();
exit(main());
panic!("unreachable after sys_exit!");
}
第 2 行使用 Rust 的宏将 _start 这段代码编译后的汇编代码中放在一个名为 .text.entry 的代码段中,方便我们在后续链接的时候调整它的位置使得它能够作为用户库的入口。
从第 4 行开始,进入用户库入口之后,手动清空需要零初始化的 .bss 段;然后调用 main 函数得到一个类型为 i32 的返回值,最后调用用户库提供的 exit 接口退出应用程序,并将 main 函数的返回值告知批处理系统。
我们还在 lib.rs 中看到了另一个 main :
#[linkage = "weak"]
#[no_mangle]
fn main() -> i32 {
panic!("Cannot find main!");
}
第 1 行,我们使用 Rust 的宏将其函数符号 main 标志为弱链接。这样在最后链接的时候,虽然在 lib.rs 和 bin 目录下的某个应用程序都有 main 符号,但由于 lib.rs 中的 main 符号是弱链接,链接器会使用 bin 目录下的应用主逻辑作为 main 。这里我们主要是进行某种程度上的保护,如果在 bin 目录下找不到任何 main ,那么编译也能够通过,但会在运行时报错。
为了支持上述这些链接操作,我们需要在 lib.rs 的开头加入:
#![feature(linkage)]
内存布局
在 user/.cargo/config 中,设置链接时使用链接脚本 user/src/linker.ld 。在其中我们做的重要的事情是:
将程序的起始物理地址调整为 0x80400000 ,三个应用程序都会被加载到这个物理地址上运行;
将 _start 所在的 .text.entry 放在整个程序的开头,也就是说批处理系统只要在加载之后跳转到 0x80400000 就已经进入了 用户库的入口点,并会在初始化之后跳转到应用程序主逻辑;
提供了最终生成可执行文件的 .bss 段的起始和终止地址,方便 clear_bss 函数使用。
系统调用
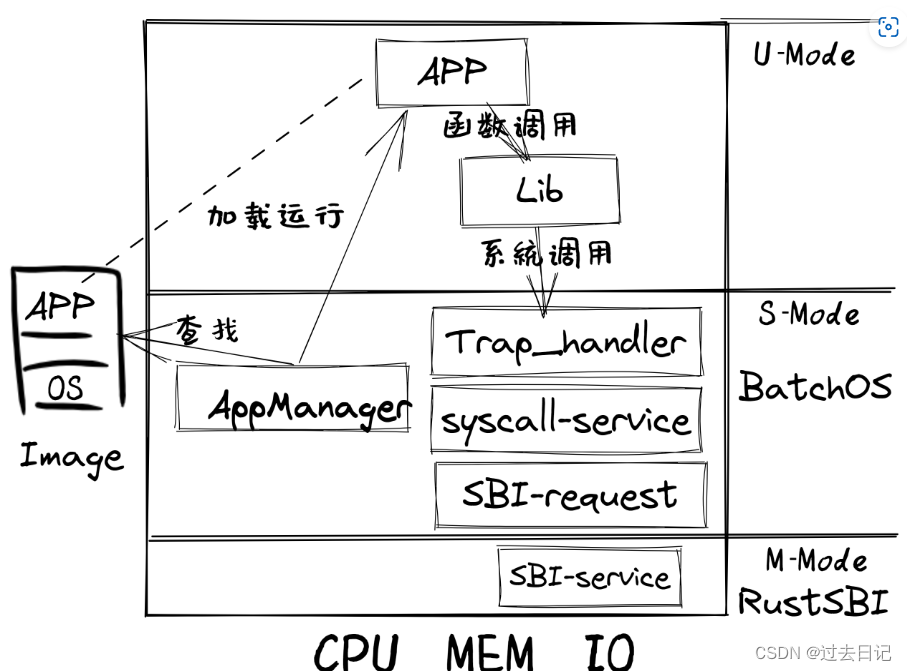
在子模块 syscall 中,应用程序通过 ecall 调用批处理系统提供的接口,由于应用程序运行在用户态(即 U 模式), ecall 指令会触发 名为 Environment call from U-mode 的异常,并 Trap 进入 S 模式执行批处理系统针对这个异常特别提供的服务代码。由于这个接口处于 S 模式的批处理系统和 U 模式的应用程序之间,这个接口可以被称为 ABI 或者系统调用。现在我们不关心底层的批处理系统如何提供应用程序所需的功能,只是站在应用程序的角度去使用即可。
在本章中,应用程序和批处理系统之间按照 API 的结构,约定如下两个系统调用:
/// 功能:将内存中缓冲区中的数据写入文件。
/// 参数:`fd` 表示待写入文件的文件描述符;
/// `buf` 表示内存中缓冲区的起始地址;
/// `len` 表示内存中缓冲区的长度。
/// 返回值:返回成功写入的长度。
/// syscall ID:64
fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize;
/// 功能:退出应用程序并将返回值告知批处理系统。
/// 参数:`exit_code` 表示应用程序的返回值。
/// 返回值:该系统调用不应该返回。
/// syscall ID:93
fn sys_exit(exit_code: usize) -> !;
我们知道系统调用实际上是汇编指令级的二进制接口,因此这里给出的只是使用 Rust 语言描述的 API 版本。在实际调用的时候,我们需要按照 RISC-V 调用规范(即ABI格式)在合适的寄存器中放置系统调用的参数,然后执行 ecall 指令触发 Trap。在 Trap 回到 U 模式的应用程序代码之后,会从 ecall 的下一条指令继续执行,同时我们能够按照调用规范在合适的寄存器中读取返回值。
在 RISC-V 调用规范中,和函数调用的 ABI 情形类似,约定寄存器 a0~a6 保存系统调用的参数, a0 保存系统调用的返回值。有些许不同的是寄存器 a7 用来传递 syscall ID,这是因为所有的 syscall 都是通过 ecall 指令触发的,除了各输入参数之外我们还额外需要一个寄存器来保存要请求哪个系统调用。由于这超出了 Rust 语言的表达能力,我们需要在代码中使用内嵌汇编来完成参数/返回值绑定和 ecall 指令的插入:
// user/src/syscall.rs
use core::arch::asm;
fn syscall(id: usize, args: [usize; 3]) -> isize {
let mut ret: isize;
unsafe {
asm!(
"ecall",
inlateout("x10") args[0] => ret,
in("x11") args[1],
in("x12") args[2],
in("x17") id
);
}
ret
}
第 3 行,我们将所有的系统调用都封装成 syscall 函数,可以看到它支持传入 syscall ID 和 3 个参数。
syscall 中使用从第 5 行开始的 asm! 宏嵌入 ecall 指令来触发系统调用。
从 RISC-V 调用规范来看,就像函数有着输入参数和返回值一样, ecall 指令同样有着输入和输出寄存器: a0~a2 和 a7 作为输入寄存器分别表示系统调用参数和系统调用 ID ,而当系统调用返回后, a0 作为输出寄存器保存系统调用的返回值。在函数上下文中,输入参数数组 args 和变量 id 保存系统调用参数和系统调用 ID ,而变量 ret 保存系统调用返回值,它也是函数 syscall 的输出/返回值。这些输入/输出变量可以和 ecall 指令的输入/输出寄存器一一对应。如果完全由我们自己编写汇编代码,那么如何将变量绑定到寄存器则成了一个难题:比如,在 ecall 指令被执行之前,我们需要将寄存器 a7 的值设置为变量 id 的值,那么我们首先需要知道目前变量 id 的值保存在哪里,它可能在栈上也有可能在某个寄存器中。
有些时候不必将变量绑定到固定的寄存器,此时 asm! 宏可以自动完成寄存器分配。某些汇编代码段还会带来一些编译器无法预知的副作用,这种情况下需要在 asm! 中通过 options 告知编译器这些可能的副作用,这样可以帮助编译器在避免出错更加高效分配寄存器。事实上,
上面这一段汇编代码的含义和内容与 第一章中的 RustSBI 输出到屏幕的 SBI 调用汇编代码 涉及的汇编指令一样,但传递参数的寄存器的含义是不同的。
于是 sys_write 和 sys_exit 只需将 syscall 进行包装:
// user/src/syscall.rs
const SYSCALL_WRITE: usize = 64;
const SYSCALL_EXIT: usize = 93;
pub fn sys_write(fd: usize, buffer: &[u8]) -> isize {
syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()])
}
pub fn sys_exit(xstate: i32) -> isize {
syscall(SYSCALL_EXIT, [xstate as usize, 0, 0])
}
注意 sys_write 使用一个 &[u8] 切片类型来描述缓冲区,这是一个 胖指针 (Fat Pointer),里面既包含缓冲区的起始地址,还 包含缓冲区的长度。我们可以分别通过 as_ptr 和 len 方法取出它们并独立地作为实际的系统调用参数。
我们将上述两个系统调用在用户库 user_lib 中进一步封装,从而更加接近在 Linux 等平台的实际系统调用接口:
// user/src/lib.rs
use syscall::*;
pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) }
pub fn exit(exit_code: i32) -> isize { sys_exit(exit_code) }
我们把 console 子模块中 Stdout::write_str 改成基于 write 的实现,且传入的 fd 参数设置为 1,它代表标准输出, 也就是输出到屏幕。目前我们不需要考虑其他的 fd 选取情况。这样,应用程序的 println! 宏借助系统调用变得可用了。 参考下面的代码片段:
// user/src/console.rs
const STDOUT: usize = 1;
impl Write for Stdout {
fn write_str(&mut self, s: &str) -> fmt::Result {
write(STDOUT, s.as_bytes());
Ok(())
}
}
exit 接口则在用户库中的 _start 内使用,当应用程序主逻辑 main 返回之后,使用它退出应用程序并将返回值告知 底层的批处理系统。
编译生成应用程序二进制码
这里简要介绍一下应用程序的自动构建。只需要在 user 目录下 make build 即可:
实现操作系统前执行应用程序
假定我们已经完成了编译并生成了 ELF 可执行文件格式的应用程序,我们就可以来试试。首先看看应用程序执行 RV64 的 S 模式特权指令 会出现什么情况,对应的应用程序可以在 user/src/bin 目录下找到。
// user/src/bin/03priv_inst.rs
use core::arch::asm;
#[no_mangle]
fn main() -> i32 {
println!("Try to execute privileged instruction in U Mode");
println!("Kernel should kill this application!");
unsafe {
asm!("sret");
}
0
}
// user/src/bin/04priv_csr.rs
use riscv::register::sstatus::{self, SPP};
#[no_mangle]
fn main() -> i32 {
println!("Try to access privileged CSR in U Mode");
println!("Kernel should kill this application!");
unsafe {
sstatus::set_spp(SPP::User);
}
0
}
在上述代码中,两个应用都会打印提示信息,随后应用 03priv_inst 会尝试在用户态执行内核态的特权指令 sret ,而应用 04priv_csr 则会试图在用户态修改内核态 CSR sstatus 。
接下来,我们尝试在用户态模拟器 qemu-riscv64 执行这两个应用:
cd user
make build
cd target/riscv64gc-unknown-none-elf/release/
确认待执行的应用为 ELF 格式
file 03priv_inst
03priv_inst: ELF 64-bit LSB executable, UCB RISC-V, version 1 (SYSV), statically linked, not stripped
执行特权指令出错
qemu-riscv64 ./03priv_inst
Try to execute privileged instruction in U Mode
Kernel should kill this application!
Illegal instruction (core dumped)
执行访问特权级 CSR 的指令出错
qemu-riscv64 ./04priv_csr
Try to access privileged CSR in U Mode
Kernel should kill this application!
Illegal instruction (core dumped)
看来RV64的特权级机制确实有用。那对于一般的用户态应用程序,在 qemu-riscv64 模拟器下能正确执行吗?
实现批处理操作系统
应用放置采用“静态绑定”的方式,而操作系统加载应用则采用“动态加载”的方式:
-
静态绑定:通过一定的编程技巧,把多个应用程序代码和批处理操作系统代码“绑定”在一起。
-
动态加载:基于静态编码留下的“绑定”信息,操作系统可以找到每个应用程序文件二进制代码的起始地址和长度,并能加载到内存中运行。
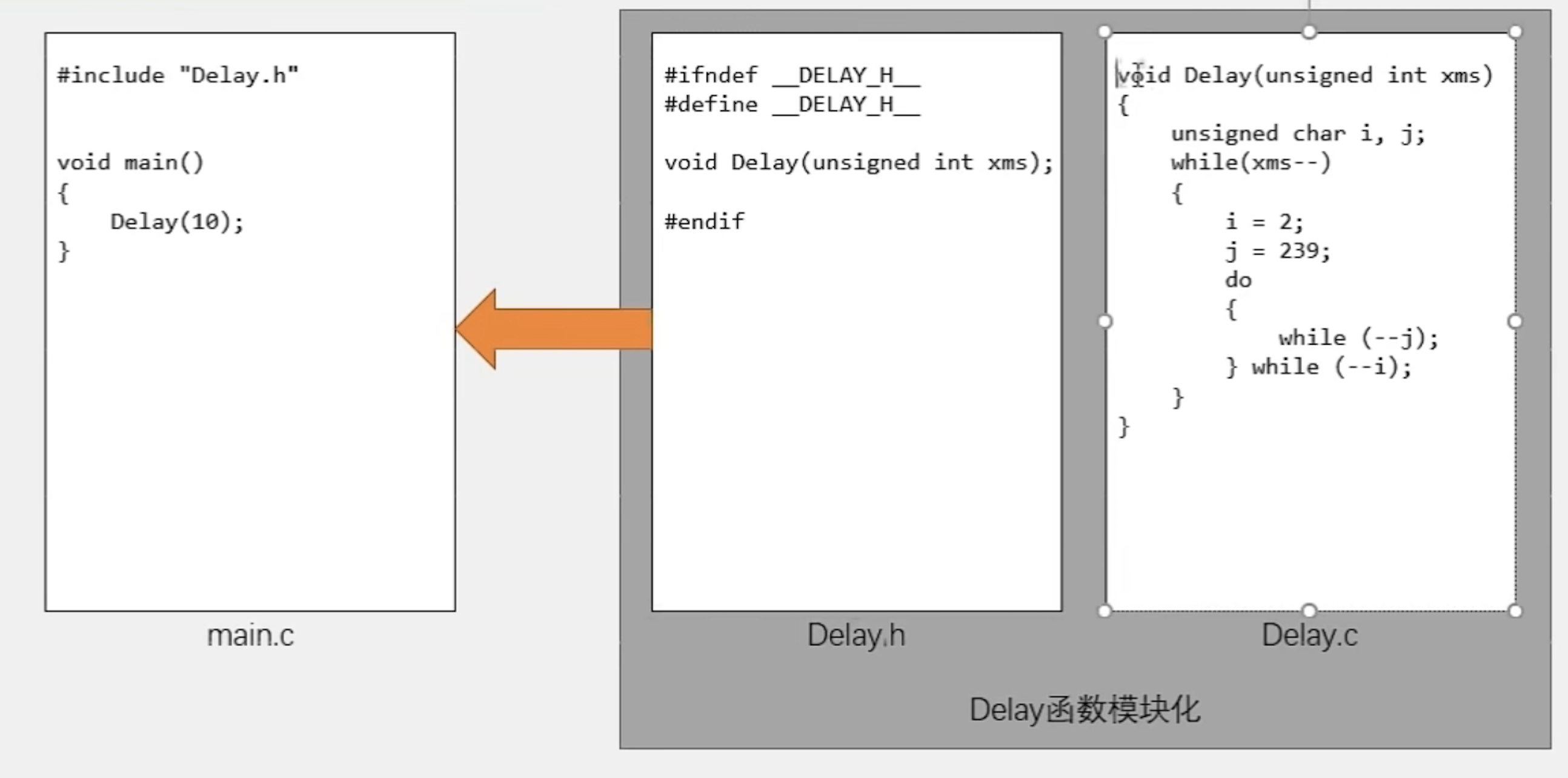
将应用程序链接到内核
我们把应用程序的二进制镜像文件作为内核的数据段链接到内核里面,因此内核需要知道内含的应用程序的数量和它们的位置,这样才能够在运行时对它们进行管理并能够加载到物理内存。
在 os/src/main.rs 中能够找到这样一行:
global_asm!(include_str!("link_app.S"));
这里我们引入了一段汇编代码 link_app.S ,它一开始并不存在,而是在构建操作系统时自动生成的。当我们使用 make run 让系统运行的过程中,这个汇编代码 link_app.S 就生成了。我们可以先来看一看 link_app.S 里面的内容:
# os/src/link_app.S
.align 3
.section .data
.global _num_app
_num_app:
.quad 5
.quad app_0_start
.quad app_1_start
.quad app_2_start
.quad app_3_start
.quad app_4_start
.quad app_4_end
.section .data
.global app_0_start
.global app_0_end
app_0_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/00hello_world.bin"
app_0_end:
.section .data
.global app_1_start
.global app_1_end
app_1_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/01store_fault.bin"
app_1_end:
.section .data
.global app_2_start
.global app_2_end
app_2_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/02power.bin"
app_2_end:
.section .data
.global app_3_start
.global app_3_end
app_3_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/03priv_inst.bin"
app_3_end:
.section .data
.global app_4_start
.global app_4_end
app_4_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/04priv_csr.bin"
app_4_end:
可以看到第 15 行开始的五个数据段分别插入了五个应用程序的二进制镜像,并且各自有一对全局符号 app_start, app_end 指示它们的开始和结束位置。而第 3 行开始的另一个数据段相当于一个 64 位整数数组。数组中的第一个元素表示应用程序的数量,后面则按照顺序放置每个应用程序的起始地址,最后一个元素放置最后一个应用程序的结束位置。这样每个应用程序的位置都能从该数组中相邻两个元素中得知。这个数组所在的位置同样也由全局符号 _num_app 所指示。
找到并加载应用程序二进制码
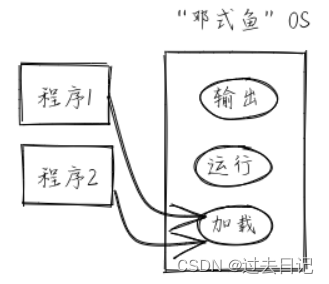
能够找到并加载应用程序二进制码的应用管理器 AppManager 是“邓式鱼”操作系统的核心组件。我们在 os 的 batch 子模块中实现一个应用管理器,它的主要功能是:
-
保存应用数量和各自的位置信息,以及当前执行到第几个应用了。
-
根据应用程序位置信息,初始化好应用所需内存空间,并加载应用执行。
应用管理器 AppManager 结构体定义如下:
// os/src/batch.rs
struct AppManager {
num_app: usize,
current_app: usize,
app_start: [usize; MAX_APP_NUM + 1],
}
这里我们可以看出,上面提到的应用管理器需要保存和维护的信息都在 AppManager 里面。这样设计的原因在于:我们希望将 AppManager 实例化为一个全局变量,使得任何函数都可以直接访问。但是里面的 current_app 字段表示当前执行的是第几个应用,它是一个可修改的变量,会在系统运行期间发生变化。因此在声明全局变量的时候,采用 static mut 是一种比较简单自然的方法。但是在 Rust 中,任何对于 static mut 变量的访问控制都是 unsafe 的,而我们要在编程中尽量避免使用 unsafe ,这样才能让编译器负责更多的安全性检查。因此,我们需要考虑如何在尽量避免触及 unsafe 的情况下仍能声明并使用可变的全局变量。
如果单独使用 static 而去掉 mut 的话,我们可以声明一个初始化之后就不可变的全局变量,但是我们需要 AppManager 里面的内容在运行时发生变化。这涉及到 Rust 中的 内部可变性 (Interior Mutability),也即在变量自身不可变或仅在不可变借用的情况下仍能修改绑定到变量上的值。我们可以通过用上面提到的 RefCell 来包裹 AppManager ,这样 RefCell 无需被声明为 mut ,同时被包裹的 AppManager 也能被修改。
除了 Sync 的问题之外,看起来 RefCell 已经非常接近我们的需求了,因此我们在 RefCell 的基础上再封装一个 UPSafeCell ,它名字的含义是:允许我们在 单核 上安全使用可变全局变量。
// os/src/sync/up.rs
use core::cell::{RefCell, RefMut};
pub struct UPSafeCell<T> {
inner: RefCell<T>,
}
unsafe impl<T> Sync for UPSafeCell<T> {}
impl<T> UPSafeCell<T> {
pub unsafe fn new(value: T) -> Self {
Self {
inner: RefCell::new(value),
}
}
pub fn exclusive_access(&self) -> RefMut<'_, T> {
self.inner.borrow_mut()
}
}
UPSafeCell 对于 RefCell 简单进行封装,它和 RefCell 一样提供内部可变性和运行时借用检查,只是更加严格:调用 exclusive_access 可以得到它包裹的数据的独占访问权。因此当我们要访问数据时,需要首先调用 exclusive_access 获得数据的可变借用标记,通过它可以完成数据的读写,在操作完成之后我们需要销毁这个标记,此后才能开始对该数据的下一次访问。相比 RefCell 它不再允许多个读操作同时存在。
这段代码里面出现了两个 unsafe :
-
首先 new 被声明为一个 unsafe 函数,是因为我们希望使用者在创建一个 UPSafeCell 的时候保证在访问 UPSafeCell 内包裹的数据的时候始终不违背上述模式:即访问之前调用 exclusive_access ,访问之后销毁借用标记再进行下一次访问。这只能依靠使用者自己来保证,但我们提供了一个保底措施:当使用者违背了上述模式,比如访问之后忘记销毁就开启下一次访问时,程序会 panic 并退出。
-
另一方面,我们将 UPSafeCell 标记为 Sync 使得它可以作为一个全局变量。这是 unsafe 行为,因为编译器无法确定我们的 UPSafeCell 能否安全的在多线程间共享。而我们能够向编译器做出保证,第一个原因是目前我们内核仅运行在单核上,因此无需在意任何多核引发的数据竞争/同步问题;第二个原因则是它基于 RefCell 提供了运行时借用检查功能,从而满足了 Rust 对于借用的基本约束进而保证了内存安全。
这样,我们就以尽量少的 unsafe code 来初始化 AppManager 的全局实例 APP_MANAGER :
// os/src/batch.rs
lazy_static! {
static ref APP_MANAGER: UPSafeCell<AppManager> = unsafe { UPSafeCell::new({
extern "C" { fn _num_app(); }
let num_app_ptr = _num_app as usize as *const usize;
let num_app = num_app_ptr.read_volatile();
let mut app_start: [usize; MAX_APP_NUM + 1] = [0; MAX_APP_NUM + 1];
let app_start_raw: &[usize] = core::slice::from_raw_parts(
num_app_ptr.add(1), num_app + 1
);
app_start[..=num_app].copy_from_slice(app_start_raw);
AppManager {
num_app,
current_app: 0,
app_start,
}
})};
}
初始化的逻辑很简单,就是找到 link_app.S 中提供的符号 _num_app ,并从这里开始解析出应用数量以及各个应用的起始地址。注意其中对于切片类型的使用能够很大程度上简化编程。
这里我们使用了外部库 lazy_static 提供的 lazy_static! 宏。要引入这个外部库,我们需要加入依赖:
# os/Cargo.toml
[dependencies]
lazy_static = { version = "1.4.0", features = ["spin_no_std"] }
lazy_static! 宏提供了全局变量的运行时初始化功能。一般情况下,全局变量必须在编译期设置一个初始值,但是有些全局变量依赖于运行期间才能得到的数据作为初始值。这导致这些全局变量需要在运行时发生变化,即需要重新设置初始值之后才能使用。如果我们手动实现的话有诸多不便之处,比如需要把这种全局变量声明为 static mut 并衍生出很多 unsafe 代码 。这种情况下我们可以使用 lazy_static! 宏来帮助我们解决这个问题。这里我们借助 lazy_static! 声明了一个 AppManager 结构的名为 APP_MANAGER 的全局实例,且只有在它第一次被使用到的时候,才会进行实际的初始化工作。
因此,借助我们设计的 UPSafeCell<T> 和外部库 lazy_static!,我们就能使用尽量少的 unsafe 代码完成可变全局变量的声明和初始化,且一旦初始化完成,在后续的使用过程中便不再触及 unsafe 代码。
AppManager 的方法中, print_app_info/get_current_app/move_to_next_app 都相当简单直接,需要说明的是 load_app:
unsafe fn load_app(&self, app_id: usize) {
if app_id >= self.num_app {
panic!("All applications completed!");
}
println!("[kernel] Loading app_{}", app_id);
// clear app area
core::slice::from_raw_parts_mut(
APP_BASE_ADDRESS as *mut u8,
APP_SIZE_LIMIT
).fill(0);
let app_src = core::slice::from_raw_parts(
self.app_start[app_id] as *const u8,
self.app_start[app_id + 1] - self.app_start[app_id]
);
let app_dst = core::slice::from_raw_parts_mut(
APP_BASE_ADDRESS as *mut u8,
app_src.len()
);
app_dst.copy_from_slice(app_src);
// memory fence about fetching the instruction memory
asm!("fence.i");
}
这个方法负责将参数 app_id 对应的应用程序的二进制镜像加载到物理内存以 0x80400000 起始的位置,这个位置是批处理操作系统和应用程序之间约定的常数地址,我们也调整应用程序的内存布局以同一个地址开头。第 7 行开始,我们首先将一块内存清空,然后找到待加载应用二进制镜像的位置,并将它复制到正确的位置。它本质上是把数据从一块内存复制到另一块内存,从批处理操作系统的角度来看,是将操作系统数据段的一部分数据(实际上是应用程序)复制到了一个可以执行代码的内存区域。
注意在第 21 行我们在加载完应用代码之后插入了一条奇怪的汇编指令 fence.i ,它起到什么作用呢?我们知道缓存是存储层级结构中提高访存速度的很重要一环。而 CPU 对物理内存所做的缓存又分成 数据缓存 (d-cache) 和 指令缓存 (i-cache) 两部分,分别在 CPU 访存和取指的时候使用。在取指的时候,对于一个指令地址, CPU 会先去 i-cache 里面看一下它是否在某个已缓存的缓存行内,如果在的话它就会直接从高速缓存中拿到指令而不是通过总线访问内存。通常情况下, CPU 会认为程序的代码段不会发生变化,因此 i-cache 是一种只读缓存。但在这里,OS 将修改会被 CPU 取指的内存区域,这会使得 i-cache 中含有与内存中不一致的内容。因此, OS 在这里必须使用取指屏障指令 fence.i ,它的功能是保证 在它之后的取指过程必须能够看到在它之前的所有对于取指内存区域的修改 ,这样才能保证 CPU 访问的应用代码是最新的而不是 i-cache 中过时的内容。
实现特权级的切换
处理操作系统为了建立好应用程序的执行环境,需要在执行应用程序之前进行一些初始化工作,并监控应用程序的执行,具体体现在:
-
当启动应用程序的时候,需要初始化应用程序的用户态上下文,并能切换到用户态执行应用程序;
-
当应用程序发起系统调用(即发出 Trap)之后,需要到批处理操作系统中进行处理;
-
当应用程序执行出错的时候,需要到批处理操作系统中杀死该应用并加载运行下一个应用;
-
当应用程序执行结束的时候,需要到批处理操作系统中加载运行下一个应用(实际上也是通过系统调用 sys_exit 来实现的)。
这些处理都涉及到特权级切换,因此需要应用程序、操作系统和硬件一起协同,完成特权级切换机制。
特权级切换相关的控制状态寄存器
当从一般意义上讨论 RISC-V 架构的 Trap 机制时,通常需要注意两点:
-
在触发 Trap 之前 CPU 运行在哪个特权级;
-
CPU 需要切换到哪个特权级来处理该 Trap ,并在处理完成之后返回原特权级。
| CSR 名 | 该 CSR 与 Trap 相关的功能 |
|---|---|
| sstatus | SPP 等字段给出 Trap 发生之前 CPU 处在哪个特权级(S/U)等信息 |
| sepc | 当 Trap 是一个异常的时候,记录 Trap 发生之前执行的最后一条指令的地址 |
| scause | 描述 Trap 的原因 |
| stval | 给出 Trap 附加信息 |
| stvec | 控制 Trap 处理代码的入口地址 |
特权级切换
当执行一条 Trap 类指令(如 ecall 时),CPU 发现触发了一个异常并需要进行特殊处理,这涉及到 执行环境切换 。具体而言,用户态执行环境中的应用程序通过 ecall 指令向内核态执行环境中的操作系统请求某项服务功能,那么处理器和操作系统会完成到内核态执行环境的切换,并在操作系统完成服务后,再次切换回用户态执行环境,然后应用程序会紧接着 ecall 指令的后一条指令位置处继续执行.
应用程序被切换回来之后需要从发出系统调用请求的执行位置恢复应用程序上下文并继续执行,这需要在切换前后维持应用程序的上下文保持不变。应用程序的上下文包括通用寄存器和栈两个主要部分。由于 CPU 在不同特权级下共享一套通用寄存器,所以在运行操作系统的 Trap 处理过程中,操作系统也会用到这些寄存器,这会改变应用程序的上下文。因此,与函数调用需要保存函数调用上下文/活动记录一样,在执行操作系统的 Trap 处理过程(会修改通用寄存器)之前,我们需要在某个地方(某内存块或内核的栈)保存这些寄存器并在 Trap 处理结束后恢复这些寄存器。
除了通用寄存器之外还有一些可能在处理 Trap 过程中会被修改的 CSR,比如 CPU 所在的特权级。我们要保证它们的变化在我们的预期之内。比如,对于特权级转换而言,应该是 Trap 之前在 U 特权级,处理 Trap 的时候在 S 特权级,返回之后又需要回到 U 特权级。而对于栈问题则相对简单,只要两个应用程序执行过程中用来记录执行历史的栈所对应的内存区域不相交,就不会产生令我们头痛的覆盖问题或数据破坏问题,也就无需进行保存/恢复。
特权级切换的硬件控制机制
当 CPU 执行完一条指令(如 ecall )并准备从用户特权级 陷入( Trap )到 S 特权级的时候,硬件会自动完成如下这些事情:
-
sstatus 的 SPP 字段会被修改为 CPU 当前的特权级(U/S)。
-
sepc 会被修改为 Trap 处理完成后默认会执行的下一条指令的地址。
-
scause/stval 分别会被修改成这次 Trap 的原因以及相关的附加信息。
-
CPU 会跳转到 stvec 所设置的 Trap 处理入口地址,并将当前特权级设置为 S ,然后从Trap 处理入口地址处开始执行。
而当 CPU 完成 Trap 处理准备返回的时候,需要通过一条 S 特权级的特权指令 sret 来完成,这一条指令具体完成以下功能:
-
CPU 会将当前的特权级按照 sstatus 的 SPP 字段设置为 U 或者 S ;
-
CPU 会跳转到 sepc 寄存器指向的那条指令,然后继续执行。
用户栈与内核栈
在 Trap 触发的一瞬间, CPU 就会切换到 S 特权级并跳转到 stvec 所指示的位置。但是在正式进入 S 特权级的 Trap 处理之前,上面 提到过我们必须保存原控制流的寄存器状态,这一般通过内核栈来保存。注意,我们需要用专门为操作系统准备的内核栈,而不是应用程序运行时用到的用户栈。
使用两个不同的栈主要是为了安全性:如果两个控制流使用同一个栈,在返回之后应用程序就能读到 Trap 控制流的历史信息,比如内核一些函数的地址,这样会带来安全隐患。于是,我们要做的是,在批处理操作系统中添加一段汇编代码,实现从用户栈切换到内核栈,并在内核栈上保存应用程序控制流的寄存器状态。
我们声明两个类型 KernelStack 和 UserStack 分别表示内核栈和用户栈,它们都只是字节数组的简单包装:
// os/src/batch.rs
const USER_STACK_SIZE: usize = 4096 * 2;
const KERNEL_STACK_SIZE: usize = 4096 * 2;
#[repr(align(4096))]
struct KernelStack {
data: [u8; KERNEL_STACK_SIZE],
}
#[repr(align(4096))]
struct UserStack {
data: [u8; USER_STACK_SIZE],
}
static KERNEL_STACK: KernelStack = KernelStack { data: [0; KERNEL_STACK_SIZE] };
static USER_STACK: UserStack = UserStack { data: [0; USER_STACK_SIZE] };
常数 USER_STACK_SIZE 和 KERNEL_STACK_SIZE 指出用户栈和内核栈的大小分别为 。两个类型是以全局变量的形式实例化在批处理操作系统的 .bss 段中的。
我们为两个类型实现了 get_sp 方法来获取栈顶地址。由于在 RISC-V 中栈是向下增长的,我们只需返回包裹的数组的结尾地址,以用户栈类型 UserStack 为例:
impl UserStack {
fn get_sp(&self) -> usize {
self.data.as_ptr() as usize + USER_STACK_SIZE
}
}
于是换栈是非常简单的,只需将 sp 寄存器的值修改为 get_sp 的返回值即可。
接下来是Trap上下文(即数据结构 TrapContext ),类似前面提到的函数调用上下文,即在 Trap 发生时需要保存的物理资源内容,并将其一起放在一个名为 TrapContext 的类型中,定义如下:
// os/src/trap/context.rs
#[repr(C)]
pub struct TrapContext {
pub x: [usize; 32],
pub sstatus: Sstatus,
pub sepc: usize,
}
可以看到里面包含所有的通用寄存器 x0~x31 ,还有 sstatus 和 sepc 。那么为什么需要保存它们呢?
-
对于通用寄存器而言,两条控制流运行在不同的特权级,所属的软件也可能由不同的编程语言编写,虽然在 Trap 控制流中只是会执行 Trap 处理相关的代码,但依然可能直接或间接调用很多模块,因此很难甚至不可能找出哪些寄存器无需保存。既然如此我们就只能全部保存了。但这里也有一些例外,如 x0 被硬编码为 0 ,它自然不会有变化;还有 tp(x4) 寄存器,除非我们手动出于一些特殊用途使用它,否则一般也不会被用到。虽然它们无需保存,但我们仍然在 TrapContext 中为它们预留空间,主要是为了后续的实现方便。
-
对于 CSR 而言,我们知道进入 Trap 的时候,硬件会立即覆盖掉 scause/stval/sstatus/sepc 的全部或是其中一部分。scause/stval 的情况是:它总是在 Trap 处理的第一时间就被使用或者是在其他地方保存下来了,因此它没有被修改并造成不良影响的风险。而对于 sstatus/sepc 而言,它们会在 Trap 处理的全程有意义(在 Trap 控制流最后 sret 的时候还用到了它们),而且确实会出现 Trap 嵌套的情况使得它们的值被覆盖掉。所以我们需要将它们也一起保存下来,并在 sret 之前恢复原样。
Trap 管理
特权级切换的核心是对Trap的管理。这主要涉及到如下一些内容:
-
应用程序通过 ecall 进入到内核状态时,操作系统保存被打断的应用程序的 Trap 上下文;
-
操作系统根据Trap相关的CSR寄存器内容,完成系统调用服务的分发与处理;
-
操作系统完成系统调用服务后,需要恢复被打断的应用程序的Trap 上下文,并通 sret 让应用程序继续执行。
Trap 上下文的保存与恢复
首先是具体实现 Trap 上下文保存和恢复的汇编代码。
在批处理操作系统初始化的时候,我们需要修改 stvec 寄存器来指向正确的 Trap 处理入口点。
// os/src/trap/mod.rs
global_asm!(include_str!("trap.S"));
pub fn init() {
extern "C" { fn __alltraps(); }
unsafe {
stvec::write(__alltraps as usize, TrapMode::Direct);
}
}
这里我们引入了一个外部符号 __alltraps ,并将 stvec 设置为 Direct 模式指向它的地址。我们在 os/src/trap/trap.S 中实现 Trap 上下文保存/恢复的汇编代码,分别用外部符号 __alltraps 和 __restore 标记为函数,并通过 global_asm! 宏将 trap.S 这段汇编代码插入进来。
Trap 处理的总体流程如下:首先通过 __alltraps 将 Trap 上下文保存在内核栈上,然后跳转到使用 Rust 编写的 trap_handler 函数完成 Trap 分发及处理。当 trap_handler 返回之后,使用 __restore 从保存在内核栈上的 Trap 上下文恢复寄存器。最后通过一条 sret 指令回到应用程序执行。
首先是保存 Trap 上下文的 __alltraps 的实现:
# os/src/trap/trap.S
.macro SAVE_GP n
sd x\n, \n*8(sp)
.endm
.align 2
__alltraps:
csrrw sp, sscratch, sp
# now sp->kernel stack, sscratch->user stack
# allocate a TrapContext on kernel stack
addi sp, sp, -34*8
# save general-purpose registers
sd x1, 1*8(sp)
# skip sp(x2), we will save it later
sd x3, 3*8(sp)
# skip tp(x4), application does not use it
# save x5~x31
.set n, 5
.rept 27
SAVE_GP %n
.set n, n+1
.endr
# we can use t0/t1/t2 freely, because they were saved on kernel stack
csrr t0, sstatus
csrr t1, sepc
sd t0, 32*8(sp)
sd t1, 33*8(sp)
# read user stack from sscratch and save it on the kernel stack
csrr t2, sscratch
sd t2, 2*8(sp)
# set input argument of trap_handler(cx: &mut TrapContext)
mv a0, sp
call trap_handler
-
第 7 行我们使用 .align 将 __alltraps 的地址 4 字节对齐,这是 RISC-V 特权级规范的要求;
-
第 9 行的 csrrw 原型是可以将 CSR 当前的值读到通用寄存器中,然后将通用寄存器 的值写入该 CSR 。因此这里起到的是交换 sscratch 和 sp 的效果。在这一行之前 sp 指向用户栈,sscratch 指向内核栈,现在 sp 指向内核栈, sscratch 指向用户栈。
-
第 12 行,我们准备在内核栈上保存 Trap 上下文,于是预先分配 字节的栈帧,这里改动的是 sp ,说明确实是在内核栈上。
-
第 13~24 行,保存 Trap 上下文的通用寄存器 x0~x31,跳过 x0 和 tp(x4),原因之前已经说明。我们在这里也不保存 sp(x2),因为我们要基于它来找到每个寄存器应该被保存到的正确的位置。实际上,在栈帧分配之后,我们可用于保存 Trap 上下文的地址区间为 ,按照 TrapContext 结构体的内存布局,基于内核栈的位置(sp所指地址)来从低地址到高地址分别按顺序放置 x0~x31这些通用寄存器,最后是 sstatus 和 sepc 。因此通用寄存器 xn 应该被保存在地址区间。为了简化代码,x5~x31 这 27 个通用寄存器我们通过类似循环的 .rept 每次使用 SAVE_GP 宏来保存,其实质是相同的。注意我们需要在 trap.S 开头加上 .altmacro 才能正常使用 .rept 命令。
-
第 25~28 行,我们将 CSR sstatus 和 sepc 的值分别读到寄存器 t0 和 t1 中然后保存到内核栈对应的位置上。指令的功能就是将 CSR 的值读到寄存器中。这里我们不用担心 t0 和 t1 被覆盖,因为它们刚刚已经被保存了。
-
第 30~31 行专门处理 sp 的问题。首先将 sscratch 的值读到寄存器 t2 并保存到内核栈上,注意: sscratch 的值是进入 Trap 之前的 sp 的值,指向用户栈。而现在的 sp 则指向内核栈。
-
第 33 行令,让寄存器 a0 指向内核栈的栈指针也就是我们刚刚保存的 Trap 上下文的地址,这是由于我们接下来要调用 trap_handler 进行 Trap 处理,它的第一个参数 cx 由调用规范要从 a0 中获取。而 Trap 处理函数 trap_handler 需要 Trap 上下文的原因在于:它需要知道其中某些寄存器的值,比如在系统调用的时候应用程序传过来的 syscall ID 和对应参数。我们不能直接使用这些寄存器现在的值,因为它们可能已经被修改了,因此要去内核栈上找已经被保存下来的值。
注解
RISC-V 中读写 CSR 的指令是一类能不会被打断地完成多个读写操作的指令。这种不会被打断地完成多个操作的指令被称为 原子指令 (Atomic Instruction)。这里的 原子 的含义是“不可分割的最小个体”,也就是说指令的多个操作要么都不完成,要么全部完成,而不会处于某种中间状态。
另外,RISC-V 架构中常规的数据处理和访存类指令只能操作通用寄存器而不能操作 CSR 。因此,当想要对 CSR 进行操作时,需要先使用读取 CSR 的指令将 CSR 读到一个通用寄存器中,而后操作该通用寄存器,最后再使用写入 CSR 的指令将该通用寄存器的值写入到 CSR 中。
当 trap_handler 返回之后会从调用 trap_handler 的下一条指令开始执行,也就是从栈上的 Trap 上下文恢复的 __restore :
# os/src/trap/trap.S
.macro LOAD_GP n
ld x\n, \n*8(sp)
.endm
__restore:
# case1: start running app by __restore
# case2: back to U after handling trap
mv sp, a0
# now sp->kernel stack(after allocated), sscratch->user stack
# restore sstatus/sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
ld t2, 2*8(sp)
csrw sstatus, t0
csrw sepc, t1
csrw sscratch, t2
# restore general-purpuse registers except sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# release TrapContext on kernel stack
addi sp, sp, 34*8
# now sp->kernel stack, sscratch->user stack
csrrw sp, sscratch, sp
sret
-
第 10 行比较奇怪我们暂且不管,假设它从未发生,那么 sp 仍然指向内核栈的栈顶。
-
第 13~26 行负责从内核栈顶的 Trap 上下文恢复通用寄存器和 CSR 。注意我们要先恢复 CSR 再恢复通用寄存器,这样我们使用的三个临时寄存器才能被正确恢复。
-
在第 28 行之前,sp 指向保存了 Trap 上下文之后的内核栈栈顶, sscratch 指向用户栈栈顶。我们在第 28 行在内核栈上回收 Trap 上下文所占用的内存,回归进入 Trap 之前的内核栈栈顶。第 30 行,再次交换 sscratch 和 sp,现在 sp 重新指向用户栈栈顶,sscratch 也依然保存进入 Trap 之前的状态并指向内核栈栈顶。
-
在应用程序控制流状态被还原之后,第 31 行我们使用 sret 指令回到 U 特权级继续运行应用程序控制流。
Trap 分发与处理
Trap 在使用 Rust 实现的 trap_handler 函数中完成分发和处理:
// os/src/trap/mod.rs
#[no_mangle]
pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
let scause = scause::read();
let stval = stval::read();
match scause.cause() {
Trap::Exception(Exception::UserEnvCall) => {
cx.sepc += 4;
cx.x[10] = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]) as usize;
}
Trap::Exception(Exception::StoreFault) |
Trap::Exception(Exception::StorePageFault) => {
println!("[kernel] PageFault in application, kernel killed it.");
run_next_app();
}
Trap::Exception(Exception::IllegalInstruction) => {
println!("[kernel] IllegalInstruction in application, kernel killed it.");
run_next_app();
}
_ => {
panic!("Unsupported trap {:?}, stval = {:#x}!", scause.cause(), stval);
}
}
cx
}
-
第 4 行声明返回值为 &mut TrapContext 并在第 25 行实际将传入的Trap 上下文 cx 原样返回,因此在 __restore 的时候 a0 寄存器在调用 trap_handler 前后并没有发生变化,仍然指向分配 Trap 上下文之后的内核栈栈顶,和此时 sp 的值相同,这里的 并不会有问题;
-
第 7 行根据 scause 寄存器所保存的 Trap 的原因进行分发处理。这里我们无需手动操作这些 CSR ,而是使用 Rust 的 riscv 库来更加方便的做这些事情。要引入 riscv 库,我们需要:
# os/Cargo.toml
[dependencies]
riscv = { git = "https://github.com/rcore-os/riscv", features = ["inline-asm"] }
- 第 8~11 行,发现触发 Trap 的原因是来自 U 特权级的 Environment Call,也就是系统调用。这里我们首先修改保存在内核栈上的 Trap 上下文里面 sepc,让其增加 4。这是因为我们知道这是一个由 ecall 指令触发的系统调用,在进入 Trap 的时候,硬件会将 sepc 设置为这条 ecall 指令所在的地址(因为它是进入 Trap 之前最后一条执行的指令)。而在 Trap 返回之后,我们希望应用程序控制流从 ecall 的下一条指令开始执行。因此我们只需修改 Trap 上下文里面的 sepc,让它增加 ecall 指令的码长,也即 4 字节。这样在 __restore 的时候 sepc 在恢复之后就会指向 ecall 的下一条指令,并在 sret 之后从那里开始执行。
用来保存系统调用返回值的 a0 寄存器也会同样发生变化。我们从 Trap 上下文取出作为 syscall ID 的 a7 和系统调用的三个参数 a0~a2 传给 syscall 函数并获取返回值。 syscall 函数是在 syscall 子模块中实现的。 这段代码是处理正常系统调用的控制逻辑。
-
第 12~20 行,分别处理应用程序出现访存错误和非法指令错误的情形。此时需要打印错误信息并调用 run_next_app 直接切换并运行下一个应用程序。
-
第 21 行开始,当遇到目前还不支持的 Trap 类型的时候,“邓式鱼” 批处理操作系统整个 panic 报错退出。
实现系统调用功能
对于系统调用而言, syscall 函数并不会实际处理系统调用,而只是根据 syscall ID 分发到具体的处理函数:
// os/src/syscall/mod.rs
pub fn syscall(syscall_id: usize, args: [usize; 3]) -> isize {
match syscall_id {
SYSCALL_WRITE => sys_write(args[0], args[1] as *const u8, args[2]),
SYSCALL_EXIT => sys_exit(args[0] as i32),
_ => panic!("Unsupported syscall_id: {}", syscall_id),
}
}
这里我们会将传进来的参数 args 转化成能够被具体的系统调用处理函数接受的类型。它们的实现都非常简单:
// os/src/syscall/fs.rs
const FD_STDOUT: usize = 1;
pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize {
match fd {
FD_STDOUT => {
let slice = unsafe { core::slice::from_raw_parts(buf, len) };
let str = core::str::from_utf8(slice).unwrap();
print!("{}", str);
len as isize
},
_ => {
panic!("Unsupported fd in sys_write!");
}
}
}
// os/src/syscall/process.rs
pub fn sys_exit(xstate: i32) -> ! {
println!("[kernel] Application exited with code {}", xstate);
run_next_app()
}
-
sys_write 我们将传入的位于应用程序内的缓冲区的开始地址和长度转化为一个字符串 &str ,然后使用批处理操作系统已经实现的 print! 宏打印出来。注意这里我们并没有检查传入参数的安全性,即使会在出错严重的时候 panic,还是会存在安全隐患。这里我们出于实现方便暂且不做修补。
-
sys_exit 打印退出的应用程序的返回值并同样调用 run_next_app 切换到下一个应用程序。
执行应用程序
当批处理操作系统初始化完成,或者是某个应用程序运行结束或出错的时候,我们要调用 run_next_app 函数切换到下一个应用程序。此时 CPU 运行在 S 特权级,而它希望能够切换到 U 特权级。在 RISC-V 架构中,唯一一种能够使得 CPU 特权级下降的方法就是执行 Trap 返回的特权指令,如 sret 、mret 等。事实上,在从操作系统内核返回到运行应用程序之前,要完成如下这些工作:
-
构造应用程序开始执行所需的 Trap 上下文;
-
通过 __restore 函数,从刚构造的 Trap 上下文中,恢复应用程序执行的部分寄存器;
-
设置 sepc CSR的内容为应用程序入口点 0x80400000;
-
切换 scratch 和 sp 寄存器,设置 sp 指向应用程序用户栈;
-
执行 sret 从 S 特权级切换到 U 特权级。
它们可以通过复用 __restore 的代码来更容易的实现上述工作。我们只需要在内核栈上压入一个为启动应用程序而特殊构造的 Trap 上下文,再通过 __restore 函数,就能让这些寄存器到达启动应用程序所需要的上下文状态。
// os/src/trap/context.rs
impl TrapContext {
pub fn set_sp(&mut self, sp: usize) { self.x[2] = sp; }
pub fn app_init_context(entry: usize, sp: usize) -> Self {
let mut sstatus = sstatus::read();
sstatus.set_spp(SPP::User);
let mut cx = Self {
x: [0; 32],
sstatus,
sepc: entry,
};
cx.set_sp(sp);
cx
}
}
为 TrapContext 实现 app_init_context 方法,修改其中的 sepc 寄存器为应用程序入口点 entry, sp 寄存器为我们设定的一个栈指针,并将 sstatus 寄存器的 SPP 字段设置为 User 。
在 run_next_app 函数中我们能够看到:
// os/src/batch.rs
pub fn run_next_app() -> ! {
let mut app_manager = APP_MANAGER.exclusive_access();
let current_app = app_manager.get_current_app();
unsafe {
app_manager.load_app(current_app);
}
app_manager.move_to_next_app();
drop(app_manager);
// before this we have to drop local variables related to resources manually
// and release the resources
extern "C" { fn __restore(cx_addr: usize); }
unsafe {
__restore(KERNEL_STACK.push_context(
TrapContext::app_init_context(APP_BASE_ADDRESS, USER_STACK.get_sp())
) as *const _ as usize);
}
panic!("Unreachable in batch::run_current_app!");
}
在高亮行所做的事情是在内核栈上压入一个 Trap 上下文,其 sepc 是应用程序入口地址 0x80400000 ,其 sp 寄存器指向用户栈,其 sstatus 的 SPP 字段被设置为 User 。push_context 的返回值是内核栈压入 Trap 上下文之后的栈顶,它会被作为 __restore 的参数(回看 __restore 代码 ,这时我们可以理解为何 __restore 函数的起始部分会完成 ),这使得在 __restore 函数中 sp 仍然可以指向内核栈的栈顶。这之后,就和执行一次普通的 __restore 函数调用一样了。