多线程在面试中问的很多,之前没有过系统的学习,现在来进行一个系统的总结学习
文章目录
- 基础
- java多线程实现
- 无参无返回值线程
- 快速创建
- start和run方法的探讨
- run方法
- 线程状态
- 有返回值线程
- 线程池执行
- 小结
- 关于抛出异常的扩展
- 线程方法
- 线程名称
- 获取当前线程
- 线程休眠
- 中断
- 停止
- 优先级
- main线程
- 守护线程
- 礼让线程以及插入线程
- 线程安全问题
- 锁
- synchronized
- 对象锁
- 方法锁
- Lock
- 死锁问题
- 等待唤醒机制
- 经典问题生产者消费者问题
- 生产者唤醒不会唤醒生产者吗
- 阻塞队列实现
- 线程池
- 线程池参数
- 执行过程
- 认为拒绝策略
- 线程池创建
- 执行线程
- 最佳线程池大小
- volatile
- jit优化
- 指令重排序
基础
cpu就像一个小公司一样,人力就类似于执行开销。
进程类似于小公司的一个组,像在win系统中,qq,微信等一个软件就是一个进程。(一个软件的基础执行整体)
线程就像组中的每个人,每个人都可以同时去做不同的事。
有了多线程就相当于可以让程序同时做很多事。
并行与并发:
- 并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
- 并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。就是同一时刻只能做一件事,但是由于其一下做这个事一下做另一个事,在某个时间段就像是同时做一样。这么说这是因为我们感知的时间可能是毫秒,而其每件事做一下的时间在微秒,所以在感知上是同时做。
java多线程实现
在java中和线程打交道最多的就是Thread类了。其线程相关方法在底层基本上用的是native修饰的,也就是说不需要程序员来考虑,由虚拟机提供。
下面是jdk中thread类的类注释对线程的介绍

无参无返回值线程
在thread类的类注释上有着2中创建多线程的方式。一种是继承Thread类,另一种是重写runable接口然后传递给thread类。
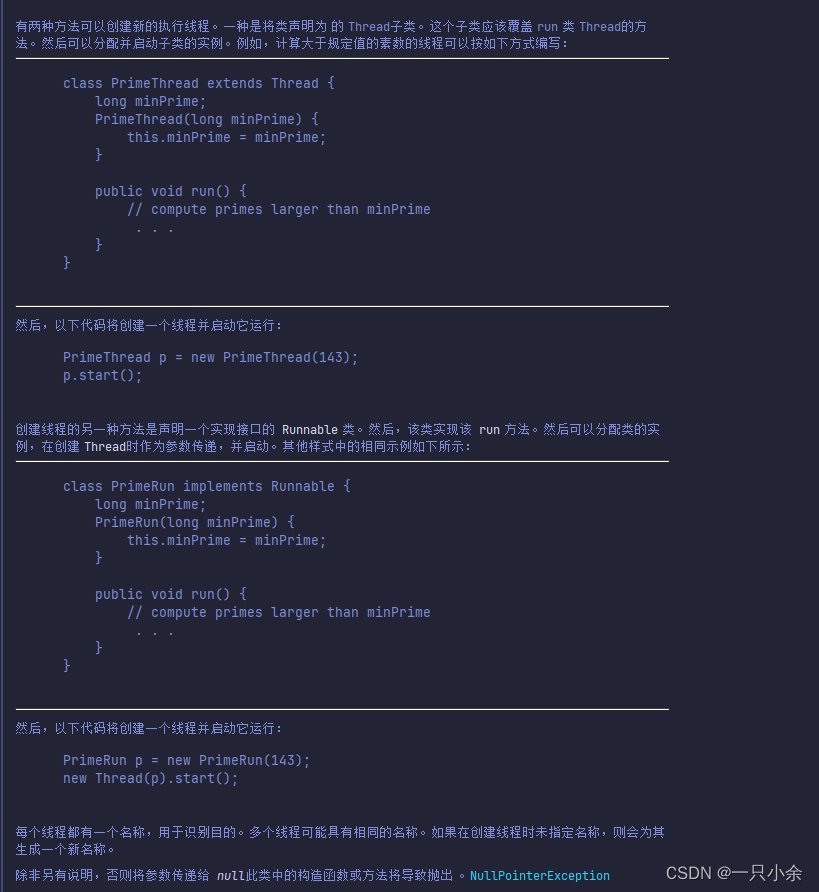
上面写过的就不赘述了。
快速创建
在Runable接口上有着FunctionalInterface的注解,那么我们就可以通过lambda表达式快速的新建一个线程来执行。
start和run方法的探讨
start的方法
多次启动一个线程是不合法的。特别是,线程一旦完成执行,就不能重新启动。
既然是重写的run方法,那直接调用run方法有没有用呢。
查看run方法源码,会发现没线程相关的内容,只是简单的调用方法。
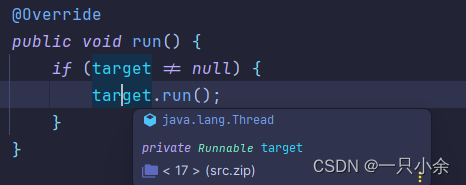
而start方法,会调用一个叫start0的本地方法,由虚拟机去创建线程。
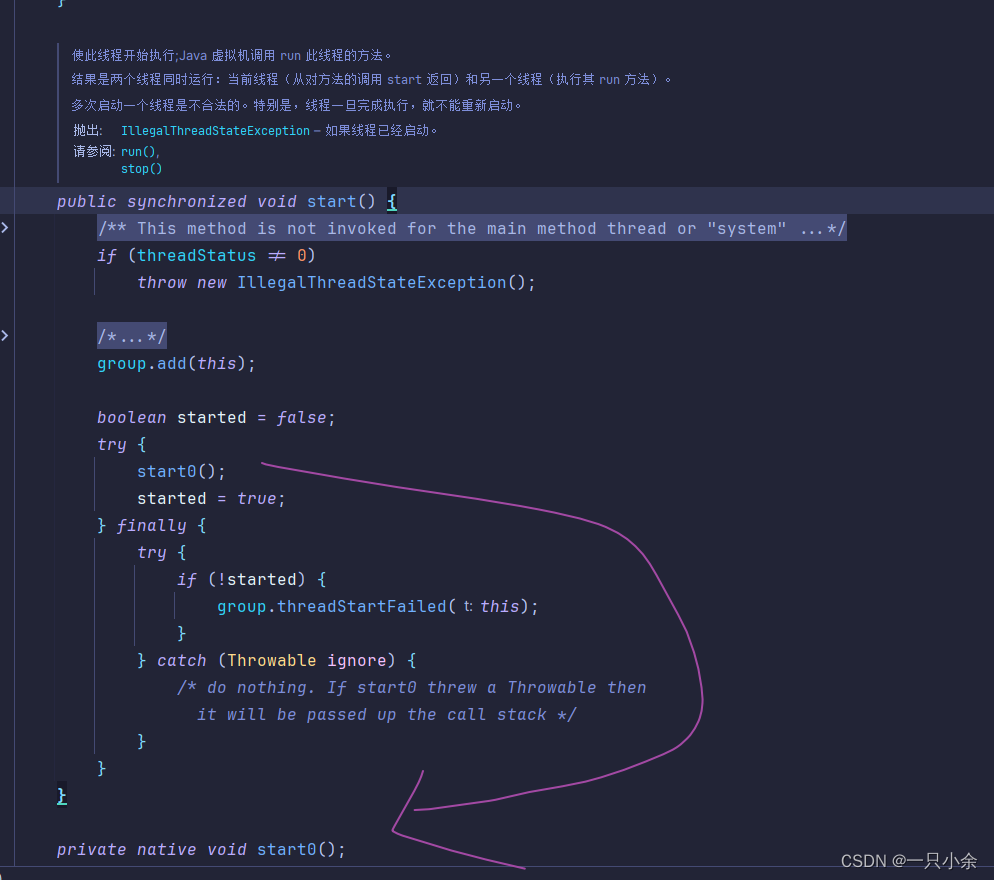
在start方法上我们发现了synchronized关键字,那么说明这个方法是互斥的,不能同时执行。
run方法
所以说Thread有2种方法,如果继承了Thread重写了run方法,就是重写的逻辑,如果没有重写,就需要传递一个target(也就是runable的实现类)
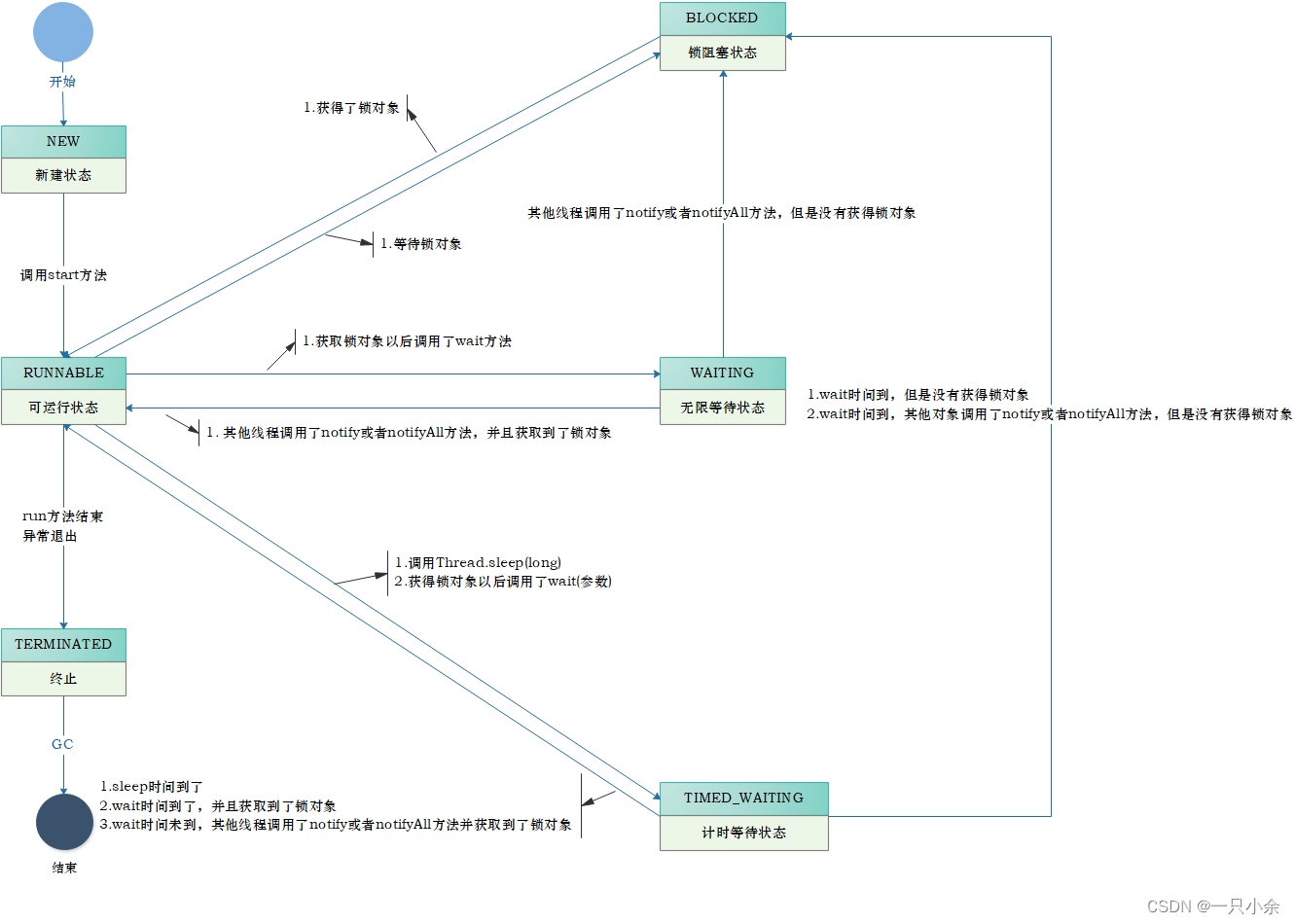
线程状态
threadStatus这个是名字应该是表示的线程的状态。
通过搜索我们发现了其get的方法,深入进入

可以看到一堆枚举

这里就是线程的状态了,注释上面写的挺清楚的就不赘述了。至于这个的具体数值应该不用探索。

有返回值线程
线程任务
继承callable 泛型就是返回值的类型
import java.util.concurrent.Callable;
import java.util.stream.IntStream;
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = IntStream.range(1, 5000).sum();
System.out.println(sum);
return sum;
}
}
main方法
public static void main(String[] args) {
// 创建callable对象
MyCallable mc = new MyCallable();
// 创建FutureTask对象
FutureTask<Integer> ft = new FutureTask<>(mc);
// 创建线程对象
Thread t = new Thread(ft);
// 启动线程
t.start();
try {
// 获取线程执行结果
System.out.println(111);
Integer sum = ft.get();
System.out.println(222);
System.out.println("1-5000的和为:" + sum);
System.out.println(333);
} catch (Exception e) {
e.printStackTrace();
}
}
执行结果,不过奇怪的是这个真的开了线程吗?执行像是顺序一样。

改变代码
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
Thread.sleep(3000);
int sum = IntStream.range(1, 5000).sum();
System.out.println(sum);
return sum;
}
}
public static void main(String[] args) {
// 创建callable对象
MyCallable mc = new MyCallable();
// 创建FutureTask对象
FutureTask<Integer> ft = new FutureTask<>(mc);
// 创建线程对象
Thread t = new Thread(ft);
FutureTask<Integer> ft2 = new FutureTask<>(()->{
System.out.println("ft2");
return 1;
});
Thread t2 = new Thread(ft2);
t.start();
t2.start();
try {
// 获取线程执行结果
System.out.println(111);
Integer sum = ft.get();
System.out.println(222);
Integer i = ft2.get();
System.out.println(i);
System.out.println("1-5000的和为:" + sum);
System.out.println(333);
} catch (Exception e) {
e.printStackTrace();
}
}
结果可以看出来get应该是有阻塞的作用的。

main方法修改得到
try {
// 获取线程执行结果
System.out.println(111);
try {
Integer sum = ft.get(2000, TimeUnit.MILLISECONDS);
System.out.println("1-5000的和为:" + sum);
}catch (Exception e){
System.out.println("超时");
}
System.out.println(222);
Integer i = ft2.get();
System.out.println(i);
System.out.println(333);
} catch (Exception e) {
e.printStackTrace();
}
结果,可以发现知道超时才会停止阻塞

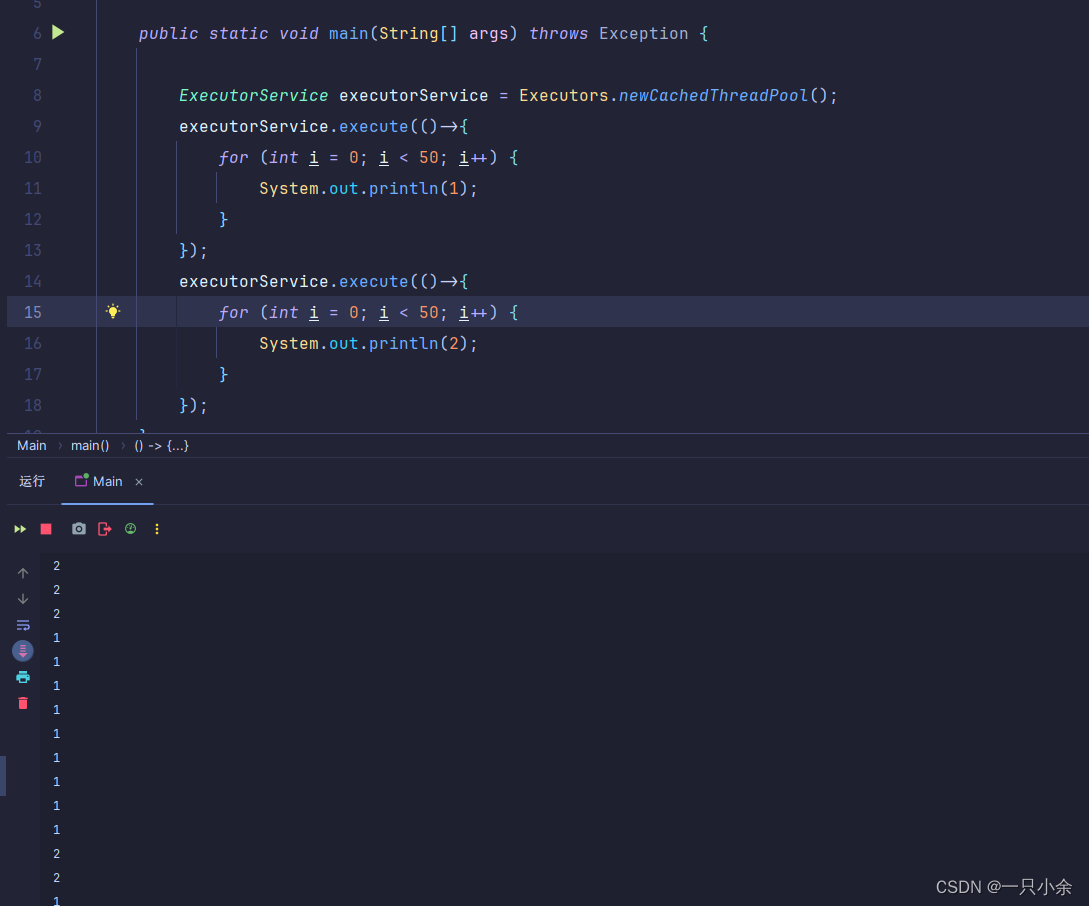
线程池执行
这种方式实现也简单,而且我发现程序是不会停止的,需要使用下面方法才会
executorService.shutdown();
小结
三种方式中
| 方式 | 简介 |
|---|---|
| 继承Thread | 编程简单,扩展性差,无法继承其他类了,无返回值,只有他可以直接获取Thread类的方法。 |
| 实现runable方法 | 复杂一点,但是如果用内部类能简化代码,扩展性好,可以继承其他类,无返回值,不能抛出异常 |
| 实现callable方法 | 有返回值,扩展性好,可以抛出异常。 |
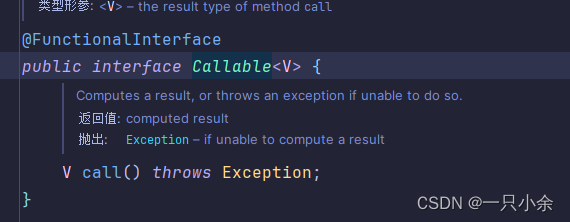
关于抛出异常的扩展
因为都是实现或者重写方法,但是只有callable的方法抛出了Exception异常。
根据java的规则,子类无法抛出比父类更大的异常,所以无法抛出异常。

线程方法
线程名称
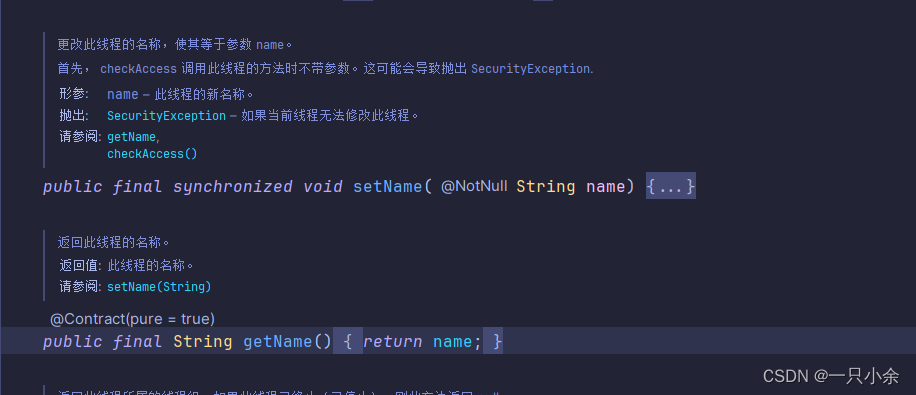
如果没有设置名字,会有默认名称,默认为Thread-加上匿名线程编号,从0开始

其次构造也可以起名称,且都不能传递null
获取当前线程

线程休眠
这个睡眠的2个参数的方法就有意思了,他的处理只是millis+1,所以额外在哪里去了,随机是吧。

中断
如果不是正常运行状态则直接中断线程
如果是wait/join/sleep/LockSupport.park等方法调用产生的阻塞状态时,调用interrupt方法,会抛出异常InterruptedException,同时会清除中断标记位,自动改为false。

查看线程是否中断

停止
强制停止,已经弃用

一般使用代码标志位判断,即在代码中用某个变量作为是否停止的标记。
优先级
设置和获取

可以发现其是有最大和最小值的,最大1最小10默认5,越大优先级越高,抢到cpu的执行权能概率更高

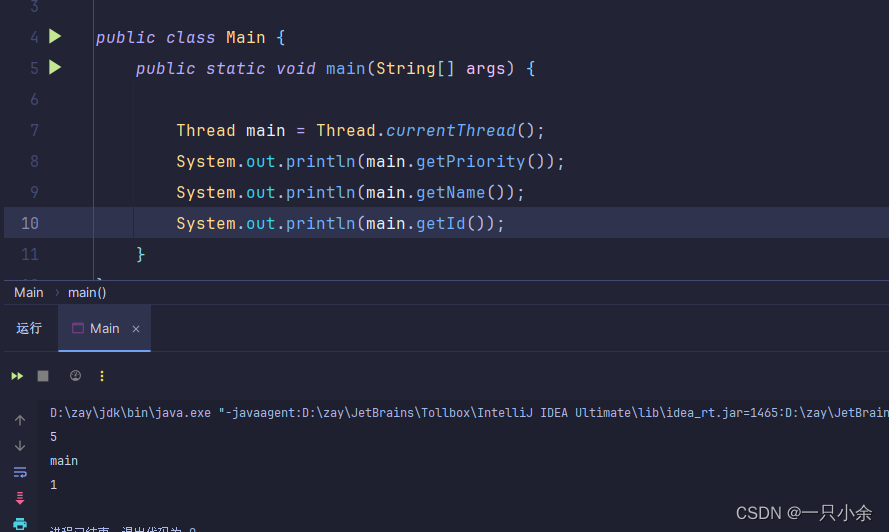
main线程
额外的我们来看看main线程的消息,优先级5,名称name,id为1
守护线程
守护线程,当其他非守护线程的结束后守护线程会陆续结束
当不设置守护的时候
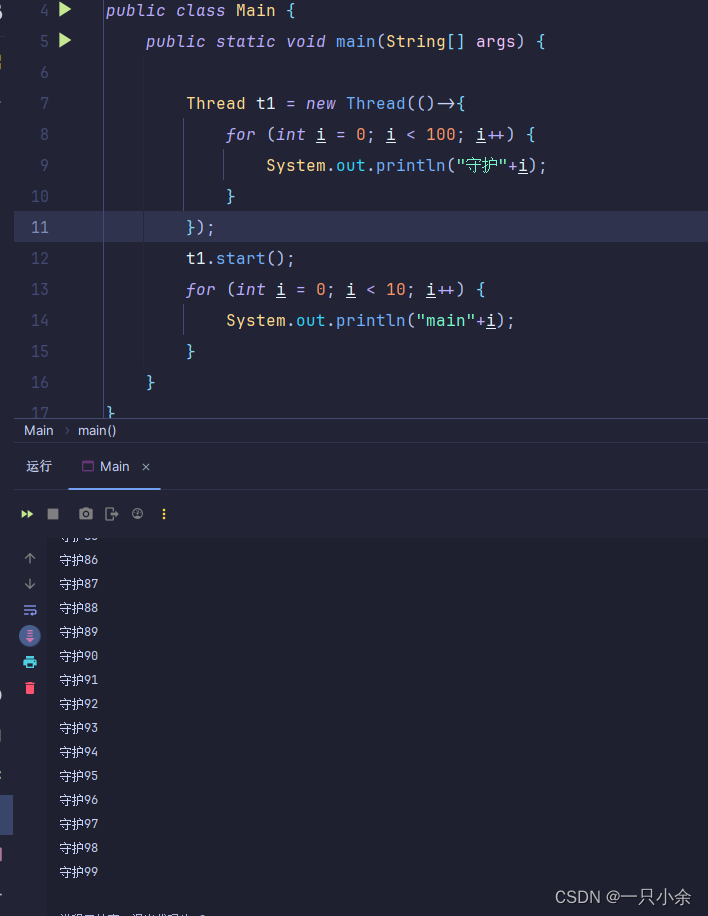
当设置为守护的时候,t1线程没有打印到99

注意守护线程也不是马上就结束了而是其他非守护线程执行完后陆续结束。
礼让线程以及插入线程
这2
礼让线程,让出cpu的执行权。但是让出后其仍然可以争取cpu的执行权,所以还有可能是其本身继续执行。
谁礼让就执行下面代码就可以了
Thread.yield();
插入线程
让其他线程插入到线程之前,我们来在守护线程的案例上进行。
开始的守护互相抢
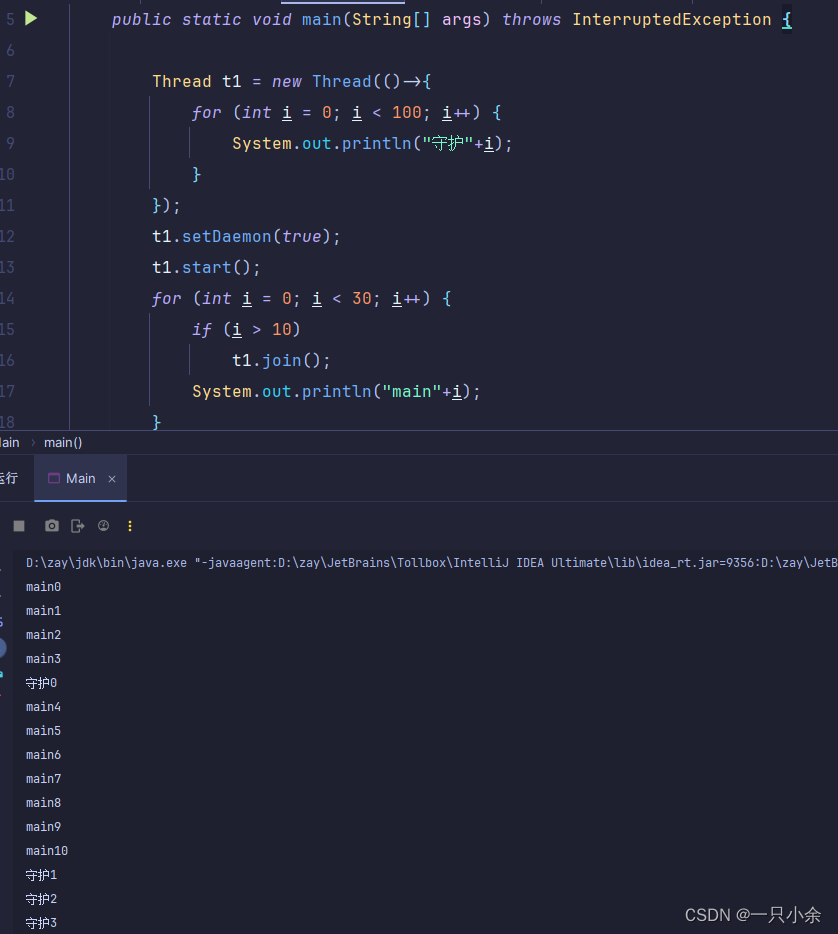
插入后直到守护线程执行完才继续执行

线程安全问题
当线程穿插的时候很容易出现问题,如
1.if(i>1)
2. i--
就这样简单的代码,当i=1的时候,a线程执行1通过,b线程执行1通过,此时2个代码都会执行i–操作。
这就是多线程导致的不安全,其原因是判断和执行不能保证原子性。所以我们一般可以使用加锁的方式。
锁
锁一般分为2种
- 乐观锁:认为冲突不一定会时刻发生,对于数据冲突保持一种乐观态度。
具体解决:通过一些业务的校验来判断是否成功。
如上面对i的校验,判断的时候记录i的值为1,然后在执行减减操作的时候判断i是否等于1,如果等于1才执行(当然判断和执行的时候必须保证其原子性)。
在数据库里面就可以这么写
update table set i = i - 1 where i = 1;
- 悲观锁:认为冲突一定会发生,对于数据冲突保持一种悲观态度。
执行的时候每次都会加锁,保证其执行完后下一个进程才能执行。
synchronized
对象锁
线程同步机制的语法是:
synchronized(){
// 线程同步代码块
}
小括号种代表加锁的对象,而且执行起来明显速度更慢了
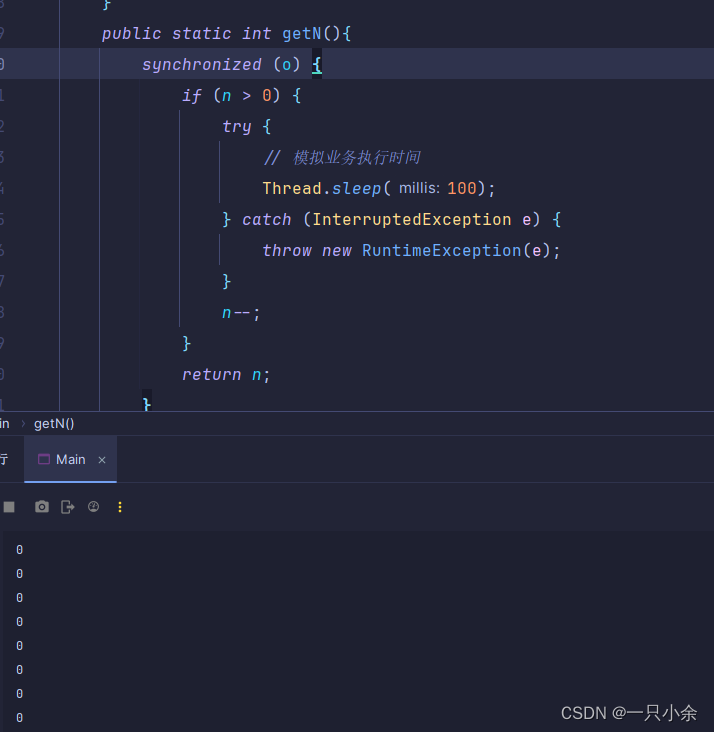
速度慢了10倍


如果开的锁不一样则没有意义,只有相同锁的才会互斥。
方法锁
加在方法上,表示每次只有一个可以调用这个方法,
这里,synchronized加锁的对象为当前静态方法所在类的Class对象。
如果表示具体方法,synchronized加锁的对象就是这个方法所在实例的本身。即一个对象一个锁。
Lock
lock和synchronized差不多,不过一个对象就相当于一把锁。

所以说不能把lock变成局部变量,一人一把锁没有意义。

死锁问题
互相枪锁,这部分在数据库原理的挺多的。a占有1资源,b占有2资源,而a想抢占2资源,b想占1资源导致a,b都无法执行下去。
互相不在继续执行

等待唤醒机制
等待唤醒不是在Thread类中而是在Object里面定义的

notify随机唤醒一个
notifyAll唤醒所有,一起抢cpu
wait阻塞,让活动在当前对象的线程无限等待(释放之前占有的锁)
经典问题生产者消费者问题
生产者不断的产生食物,知道满
消费者不断的消耗食物,直到空
static final ArrayList<Integer> list = new ArrayList<>(10);
public static void main(String[] args) throws Exception {
Thread producer = new Thread(() -> {
while (true) {
synchronized (list) {
try {
if (list.size() == 10) {
System.out.println("List is full");
list.wait();
}
Thread.sleep(100);
list.add(1);
System.out.println("Added 1");
list.notifyAll();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
Thread consumer = new Thread(() -> {
while (true) {
synchronized (list) {
try {
if (list.isEmpty()) {
System.out.println("List is empty");
list.wait();
}
Thread.sleep(100);
list.remove(0);
System.out.println("Removed 1");
list.notifyAll();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
producer.start();
consumer.start();
}
执行结果
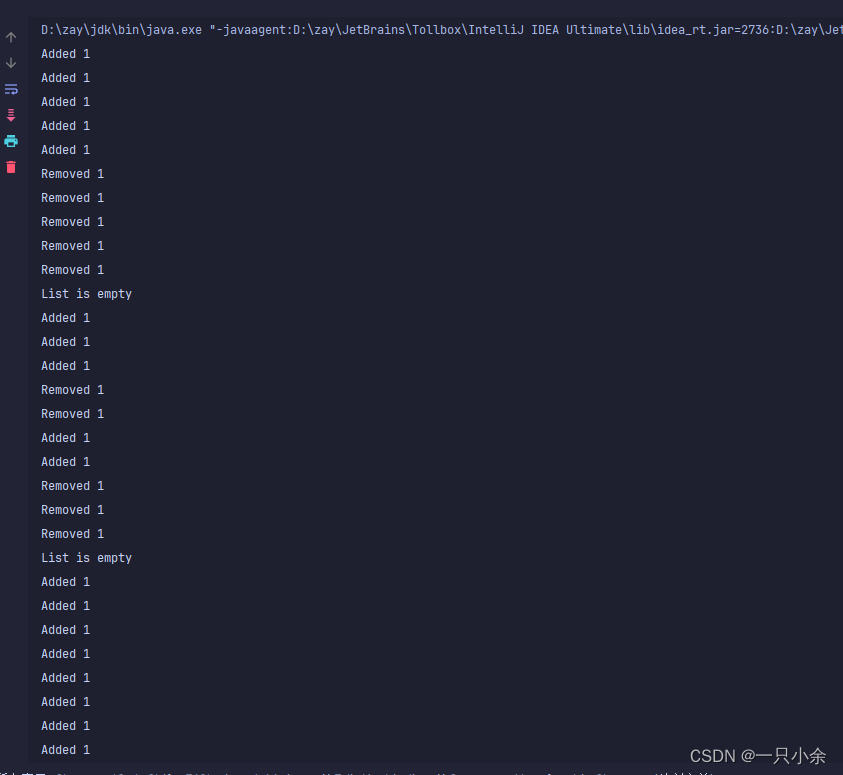
生产者唤醒不会唤醒生产者吗
这里只有2个线程一个生产者一个消费者,最后的notifyAll会唤醒另一个,但是如果没满/没空的时候,他还是会去争抢锁的。
多生产者消费者线程呢?
如果有多个生产者线程,每个生产者线程都调用notifyAll()方法,那么会唤醒所有等待在同一个对象上的消费者线程和生产者线程。也就是说,所有等待在该对象上的线程都会被唤醒。如果只想唤醒消费者线程,可以考虑使用不同的对象来进行等待和唤醒操作。
阻塞队列实现
static final ArrayBlockingQueue<Integer> list = new ArrayBlockingQueue<>(10);
public static void main(String[] args) throws Exception {
Thread producer = new Thread(() -> {
while (true) {
try {
list.put(1);
Thread.sleep(100);
System.out.println("Added 1");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread consumer = new Thread(() -> {
while (true) {
try {
Thread.sleep(100);
list.poll();
System.out.println("Removed 1");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
producer.start();
consumer.start();
}
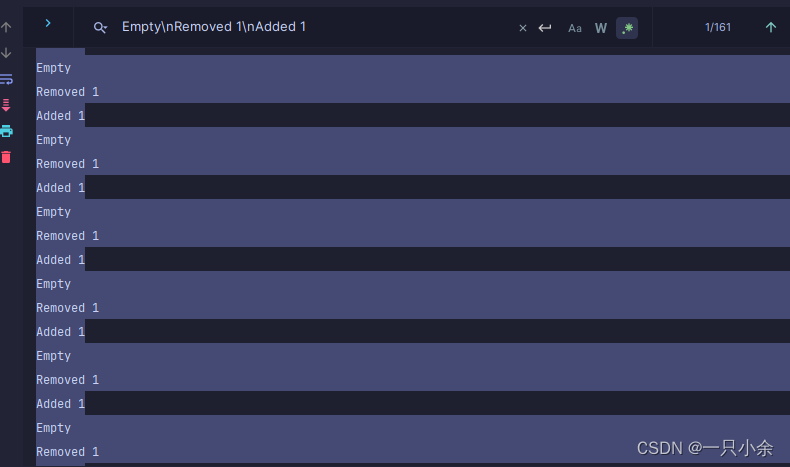
执行结果
线程池
如果不使用线程池,那么每次都会新建一个线程执行完后销毁,非常的浪费资源。
这就是线程池存在的必要了。
线程池里最开始是没有的,来一个线程创建一个,执行完后也不会销毁,会执行后面的。当然配置有挺多的。
线程池参数
- 核心线程数:常驻的线程数量,创建后不销毁
- 最大线程数量:线程池的线程数量可以超过核心线程数但是不能超过最大线程数量,但是超过核心线程数的临时线程,如果线程空闲将会被销毁
- 空闲时间:空闲超过多久后销毁
- 空闲时间单位
- 阻塞队列
- 创建线程的方式
- 认为拒绝策略:过多的处理方案
执行过程
先创建核心线程数,多出的放到阻塞队列,阻塞队列满了后,后面来的会创建临时线程进行处理。(所以先提交的不一定先执行)如果还是满了就会按照认为拒绝策略方案进行
认为拒绝策略
- AbortPolicy:丢弃任务并抛出异常,默认策略
- DiscardPolicy:丢弃任务不抛出异常
- DiscardOldestPolicy:抛弃等待时间最长的任务,然后加入
- CallerRunsPolicy:直接执行run方法
线程池创建
我们在上面使用了Executors创建的线程池,这样方便。
我们来学习一下。
Executors是通过其静态方法来创建线程池,其内部是通过ThreadPoolExecutor的全参构造进行的,所以学习了ThreadPoolExecutor的构造其他的看一眼源码就知道了。
这些就是上面讲到的线程池参数
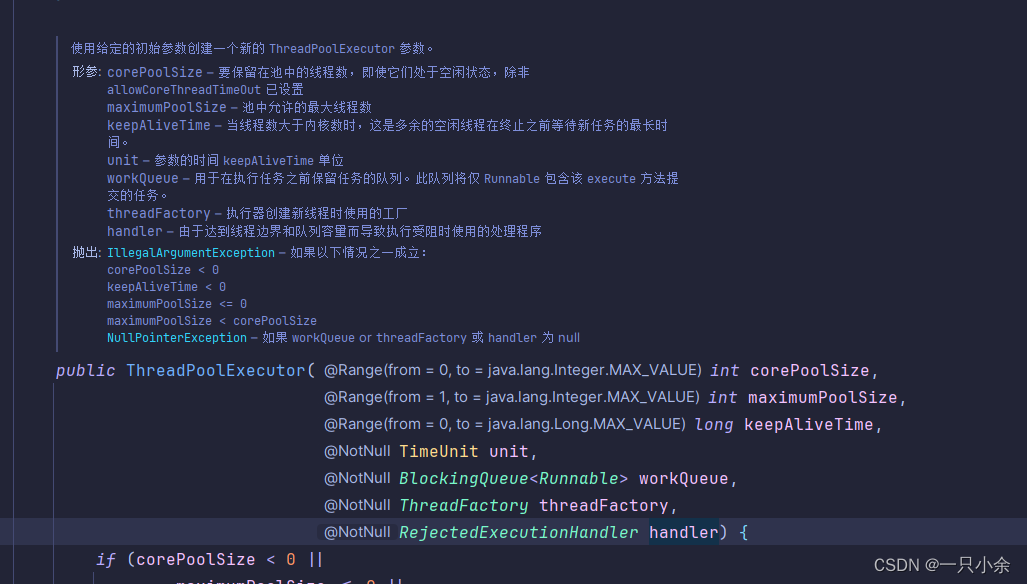
newFixedThreadPool,fixed固定,创建的是固定大小的线程池,没有临时线程,LinkedBlockingQueue最大为int的最大整数,AbortPolicy为默认拒绝策略
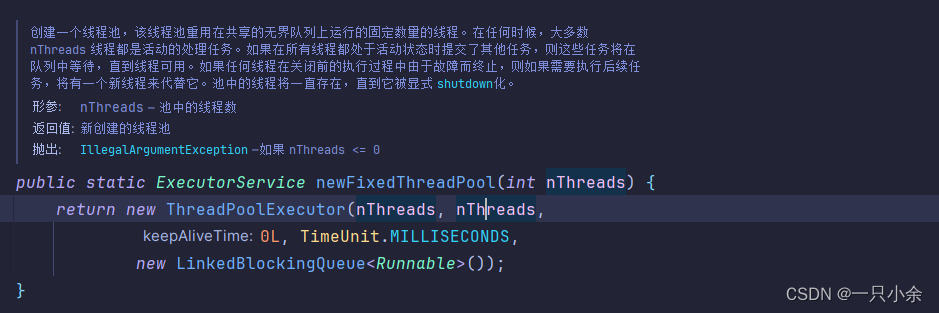
工厂采用的是默认的,采用new Thread,优先级为5的

这里还能指定工厂
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
这样的不能够自定义,所以我们如果想要自定义线程池就使用ThreadPoolExecutor的全参构造就可以了。
执行线程
Executors创建的采用sumbit执行

ThreadPoolExecutor而是使用execute方法

最佳线程池大小
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目 * cpu利用率
比如平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到: ((0.5+1.5)/0.5)*8=32。
时间可以使用thread dump等压测工具
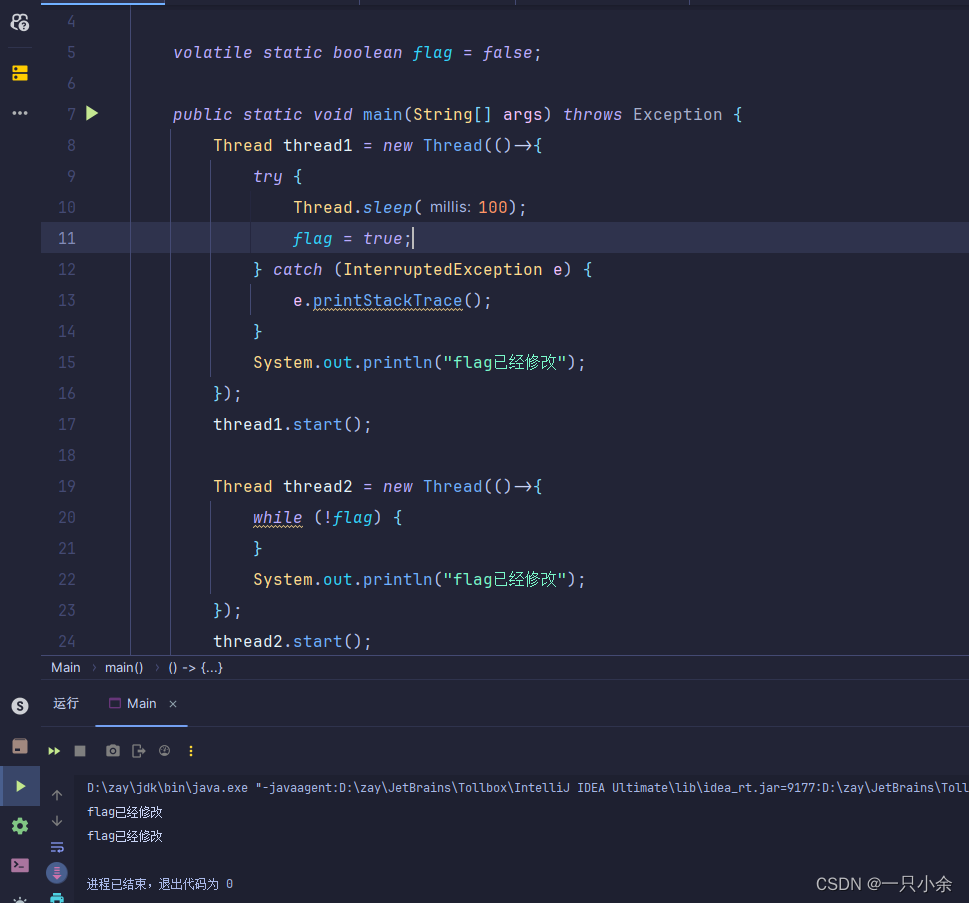
volatile
用于修饰共享变量,一旦一个共享变量(类成员变量,静态变量)被volatile修饰后。就被线程所共享,且不会被指令重排序。
jit优化
如果被修饰了,那么当其被线程调用的时候不会被jit优化。
如下面情况即使被修改了,代码也没有停止,没有跳出线程2的循环。

被修饰后,直接就跳出了。
指令重排序
指令是可能被优化重新排序的如下面情况。
a = 10;
b = 1;
a = 100;
那么其很有可能被优化为
a = 10;
a = 100;
b = 1;
因为第一种,需要从内存存储a移动到b在回到a。而第二种只有一次。很显然第二种更高。
但是有时候我们是不需要其执行重排序的。
如我们想要通过a的值判断代码执行到哪里了,那么我们肯定就不希望其进行重排序。
volatile关键字,
- 会在写操作的时候阻止上方的指令到其下方。
在写操作时,volatile关键字会阻止上方的指令重排序到其下方。这是为了确保写操作对其他线程的读操作的可见性。如果写操作的指令重排序到其下方,其他线程可能会读取到旧的值,导致可见性问题。 - 读操作阻止下方的到上方。
在读操作时,volatile关键字会阻止下方的指令重排序到其上方。这是为了确保读操作读取的是最新的值。如果读操作的指令重排序到其上方,读取到的值可能是旧的值,导致可见性问题。
所以一般volatile变量
- 如果是写一般放最后
- 如果是读一般放前面