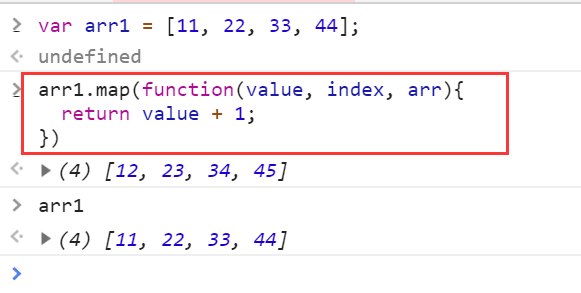
YOLOv5:修改backbone为MobileOne
- 前言
- 前提条件
- 相关介绍
- MobileOne
- YOLOv5修改backbone为MobileOne
- 修改common.py
- 修改yolo.py
- 修改yolov5.yaml配置
- 参考

前言
- 记录在YOLOv5修改backbone操作,方便自己查阅。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
MobileOne
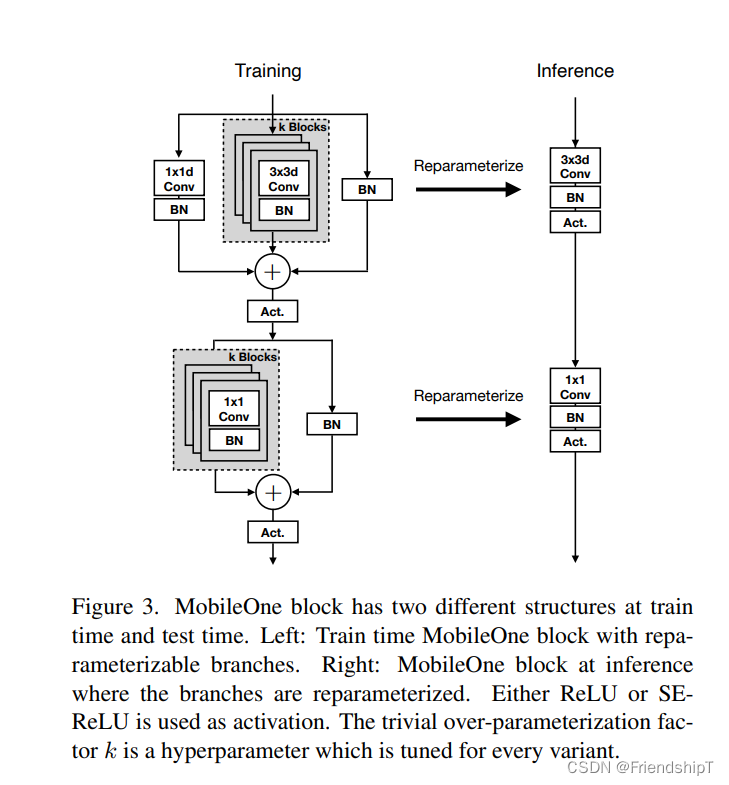
- MobileOne是一种神经网络骨干,专为移动设备设计,可在iPhone12上实现1毫秒以下的推理时间,并在ImageNet上实现75.9%的top-1准确率。它针对延迟进行了优化,这是移动设备的关键指标,并在高效架构中提供了最先进的性能,同时在移动设备上快得多。论文作者确定并分析了最近高效神经网络中的架构和优化瓶颈,并提供了缓解这些瓶颈的方法。论文还表明,当在移动设备上部署时,他们的模型可以推广到多个任务 - 图像分类、目标检测和语义分割,并且在延迟和准确性方面与现有高效架构相比有显着的改进。
- MobileOne最大的不同点在于:
- 使用了过参数化
- 使用了与MobileNet类似的深度可分离卷积结构
- 过参数化是指模型的可调权重数过多,导致模型过于复杂,完美地拟合训练数据,但对测试数据的预测效果不佳。
- 重参数化是一种将神经网络的结构转换为更简单的结构,以减少计算复杂度和存储复杂度的方法。具体而言,重参数化方法使用数学变换将一个复杂的神经网络结构转化为一个更简单的结构,在保持一定精度的情况下增加模型推理时的速度。这些方法在神经网络压缩中得到了广泛应用。
- 重参数化常用方法如下:
- 卷积层与BN层的合并
- 多分支相加
- 1×1卷积与K×K卷积的重参数化
- 通道拼接
- AveragePooling
- 多尺度卷积
- 论文地址:https://arxiv.org/abs/2206.04040
- 官方源代码地址:https://github.com/apple/ml-mobileone
- 有兴趣可查阅论文和官方源代码地址。
YOLOv5修改backbone为MobileOne
修改common.py
将以下代码,添加进common.py。
############## MobileOne ##############
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc, kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=in_channels, bias=True,
padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,
bias=True)
else:
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_{k_idx}',
DepthWiseConv(in_channels, 3, stride=stride)
)
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_{k_idx}',
PointWiseConv(in_channels, out_channels)
)
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_{k_idx}')(inputs)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_{k_idx}')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
class MobileOne(nn.Module):
# MobileOne
def __init__(self, in_channels, out_channels, n, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super().__init__()
self.m = nn.Sequential(*[MobileOneBlock(in_channels, out_channels, k, stride, deploy) for _ in range(n)])
def forward(self, x):
x = self.m(x)
return x
############## mobileone ##############
修改yolo.py
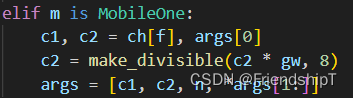
elif m is MobileOne:
c1, c2 = ch[f], args[0]
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, n, *args[1:]]
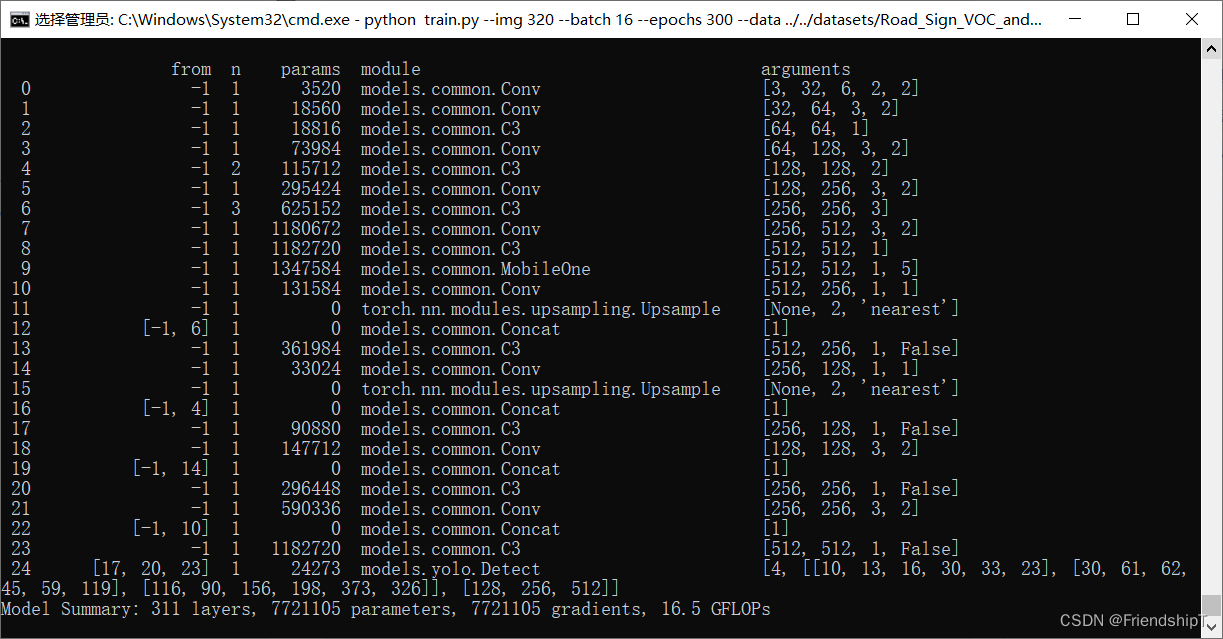
修改yolov5.yaml配置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, MobileOne, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
参考
[1] Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, Oncel Tuzel, Anurag Ranjan. MobileOne: An Improved One millisecond Mobile Backbone. 2023
[2] https://github.com/apple/ml-mobileone
[3] https://github.com/ultralytics/yolov5.git
[4] https://arxiv.org/abs/2206.04040
[5] https://zhuanlan.zhihu.com/p/560894077
[6] https://zhuanlan.zhihu.com/p/550626959
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目