1.链上数据处理面临的挑战
区块链数据公司,在索引以及处理链上数据时,可能会面临一些挑战,包括:
-
海量数据。随着区块链上数据量的增加,数据索引将需要扩大规模以处理增加的负载并提供对数据的有效访问。因此,它导致了更高的存储成本;缓慢的指标计算和增加数据库服务器的负载。
-
复杂的数据生产流程。区块链技术是复杂的,建立一个全面和可靠的数据索引需要对底层数据结构和算法有深刻的理解。这是由区块链实现方式的多样性所决定的。举一个具体的例子,以太坊中的 NFT 通常是在遵循 ERC721 和 ERC1155 格式的智能合约中进行创建的,而像Polkadot 上通常是直接在区块链运行时间内构建的。对于用户来说,不管是任何形式的存在,这些数据应该被视为 NFT 的交易,需要被存储,并且处理为可读状态,方便分析以及进行计算。
-
集成能力。为了给用户提供最大的价值,区块链索引解决方案可能需要将其数据索引与其他系统集成,如分析平台或 API。这很有挑战性,需要在架构设计上投入大量精力。
随着区块链技术的使用越来越广泛,存储在区块链上的数据量也在增加。这是因为更多的人在使用该技术,而每笔交易都会给区块链增加新的数据。此外,区块链技术的使用已经从简单的资金转移应用,如涉及使用比特币的应用,发展到更复杂的应用,包括智能合约之间的相互调用。这些智能合约可以产生大量的数据,从而造成了区块链数据的复杂性和规模的增加。随着时间的推移,这导致了更大、更复杂的区块链数据。
本文中,我们将以 Footprint Analytics 的技术架构演变作为分析案例,探索 Iceberg-Trino 如何解决链上数据面临的挑战。
Footprint Analytics 拥有最全面的链上数据索引仓库,目前涵盖 22 个公链,17 个 NFT 市场,超过 1900 个 GameFi 项目,以及超过 66 万个 NFT 收藏。当我们谈及 22 条公链底层数据时,不同与其他行业,区块链的数据大部分都是交易数据,而非单纯传统行业的日志数据,22 条公链大概数量级行数大概是 200 亿以上,而这些是经常需要被查询的数据。
在过去几个月中,我们经历了以下三次大的系统版本升级,以满足不断增长的业务需求:
2. 架构 1.0 Bigquery
在 Footprint Analytics 初创阶段,我们使用 Bigquery 作为存储和查询引擎。Bigquery 是一款优秀的产品,它提供的动态算力,和灵活的 UDF 语法帮助我们解决了很多问题。
不过 Bigquery 也存在着一些问题:
-
数据没有经过压缩,存储费用过高,特别是我们需要存储将近 20 条区块链的原始数据;
-
并发能力不足:Bigquery 同时运行的 Query 只有 100 条,不能为 Footprint Analytics 提供高并发查询;
-
非开源产品,绑定 Google 一家供应商。
所以我们决定探索新架构。
3. 架构 2.0 OLAP
我们对最近很火热的 OLAP 产品非常感兴趣,OLAP 让人印象深刻的地方就是其查询反应速度,仅需亚秒级响应时间即可返回海量数据下的查询结果,对高并发的点查询场景也支持比较好。
我们挑选了其中一款 OLAP 数据库,Doris 进行了深入的尝试。
但是很快,我们碰到了以下问题:
-
不支持 Array JSON 等数据类型
-
在区块链的数据中,数组 Array 是个很常见的类型,例如 evm logs 中的 topic 字段,无法对 Array 进行计算处理,会影响我们计算很多指标。
-
-
DBT 支持有限,不支持 merge 语法来 update data
-
DBT 是数据工程师比较典型的处理ETL/ELT 的工具,尤其是Footprint Analytics 团队。merge and update这也是很常见的需求,我们需要对一些新探索的数据进行更新操作。
-
也就是说,我们无法在 Doris 上完成我们的数据生产流程,所以我们退而求其次,让 OLAP 数据库解决我们的部分问题,作为查询引擎,提供快速且高并发的查询能力。
很遗憾的是,该方案 无法将 Bigquery 作为 Data Source替换掉,我们必须把不断地把 Bigquery 上的数据进行同步,同步程序的不稳定性给我们带来了非常多的麻烦,因为在使用存算分离的架构,当其查询压力过大时,也会影响写入程序的速度,造成写入数据堆积,同步无法继续进行吗,我们需要有固定的人员来处理这些同步问题。
我们意识到,OLAP 可以解决我们所面临的几个问题,但不能成为 Footprint Analytics 的全套解决方案,特别是在数据处理以及生产方面。我们的问题更大更复杂,我们可以说,OLAP 作为一个查询引擎对我们来说是不够的。
4. 架构 3.0 Iceberg + Trino
在 Footprint Analytics 架构 3.0 的升级中,我们从头开始重新设计了整个架构,将数据的存储、计算和查询分成三个不同的部分。从 Footprint Analytics 早期的两个架构中吸取教训,并从其他成功的大数据项目中学习经验,如 Uber、Netflix 和 Databricks。
4.1. 数据湖的引入
我们首先把注意力转向了数据湖,这是一种新型的结构化和非结构化数据的存储方式。数据湖非常适合链上数据的存储,因为链上数据的格式范围很广,从非结构化的原始数据到结构化的抽象数据,都是 Footprint Analytics 特色亮点。我们期望用数据湖来解决数据存储的问题,最好还能支持主流的计算引擎,如 Spark 和 Flink,这样随着 Footprint Analytics的发展,与不同类型的处理引擎整合起来能更容易,更具备拓展性。
Iceberg 可以与 Spark,Flink,Trino 等计算引擎都有着非常良好的集成,我们可以为我们的每一个指标选择最合适的计算方式。例如:
-
需要复杂计算逻辑的,选择 Spark;
-
需要实时计算的,选择 Flink;
-
使用 SQL 就能胜任的简单 ETL 任务,选择 Trino。
4.2. 查询引擎
有了 Iceberg 解决了存储和计算的问题,我们接下来就要思考,如何选择查询引擎。实际上可以选的方案不多,备选的有:
-
Trino: SQL Query Engine
-
Presto: SQL Query Engine
-
Kyuubi:Serverless Spark SQL
在深度使用之前,我们考虑最多的是,未来的查询引擎必须要兼容我们当前的架构。
-
要支持将 Bigquery 作为 Data Source
-
要支持 DBT,我们要很多指标是依赖 DBT 完成生产的
-
要支持 BI 工具 metabase
基于以上个点,我们选择了 Trino,Trino 对 Iceberg 的支持非常完善,而且团队执行力非常强,我们提了一个 BUG,在第二天就被修复,并且在第二周就发布到了最新版本中。这对同样要求高执行响应速度的 Footprint Analytics 团队,无疑是最佳选择。
4.3 性能测试
选定了方向之后,我们对 Trino+Iceberg 这个组合做了个性能测试,以确定其性能是否能满足我们的需求,结果出乎我们依赖,查询速度不可思议地快。
要知道,在各大 OLAP 的宣传文章中,Presto + Hive 可是常年作为最差的对比项存在的,Trino + Iceberg 的组合完全刷新了我们的认知。
下面是我们的测试结果:
case 1: join big table
一个 800 GB 的 table1 join 另一个 50 GB 的 table2 并做复杂业务计算
case2: 大单表做 distinct 查询
测试用的 sql : select distinct(address) from table group by day

相同配置下,Trino+Iceberg 组合速度大约是 Doris 的 3 倍。
除此之前,还有一个惊喜,因为 Iceberg 底层可以使用 Parquet、ORC 等 data format,会对数据进行压缩存储,Icberg 的 table 存储空间只需要其他数据仓库的 1/5 左右。
同样一个 table,在三个数据库中的存储大小分别是:

注:以上测试都是我们实际生产中碰到的个别业务例子,结论不严谨,仅供参考。
4.4 升级效果
性能测试报告给了我们足够的性能,我们团队使用了大概 2 个月时间来完成迁移,这个是我们升级之后的架构图:
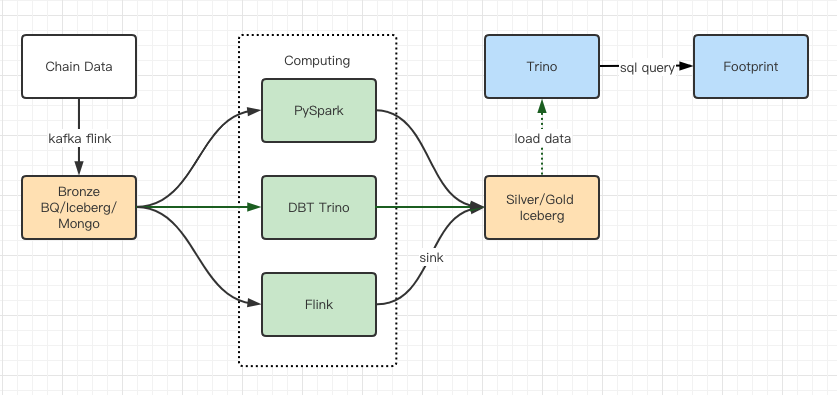
-
丰富的计算引擎让我们可以应对各种计算需求;
-
Trino 可以直接查询 Iceberg,我们再也不用处理数据同步问题;
-
Trino + Iceberg 让人惊艳的性能,让我们可以开放所有 Bronze 数据给到用户。
总结
自2021年8月推出以来,Footprint Analytics 团队在不到一年半的时间里完成了三次架构升级,这得益于其为加密货币用户带来最佳数据库技术优势的强烈愿望和决心,以及在实施和升级其底层基础设施和架构方面的扎实执行。
-
Footprint Analytics 架构升级3.0为其用户买到了全新的体验,让来自不同背景的用户在更多样化的使用和应用中获得洞察力。
-
与 Metabase 商业智能工具一起构建的 Footprint 便于分析师获得已解析的链上数据,完全自由地选择工具(无代码或编写代码 )进行探索,查询整个历史,交叉检查数据集,在短时间内获得洞察力。
-
整合链上和链下的数据,在 web2 和 web3 之间进行分析。
-
通过在 Footprint 的业务抽象之上建立/查询指标,分析师或开发人员可以节省80% 的重复性数据处理工作的时间,并专注于有意义的指标,研究和基于其业务的产品解决方案。
-
从Footprint Web 到 REST API 调用的无缝体验,都是基于 SQL 的。
-
对关键信号进行实时提醒和可操作的通知,以支持投资决策。