目录
为什么需要内存对齐
性能
范围
原子性
结论
数据模型
C++ 的内存对齐
具名要求
平凡类
标准布局类
平凡类与标准布局类总结
标准布局类的内存对齐
普通的标准布局类
带有位域的标准布局类
手动指定对齐大小的标准布局类
非标准布局类的内存对齐
GLSLang 的内存对齐
buffer 的布局修饰
location
使用 GLM 与 GLSLang 传递数据
众所周知,运行的程序是需要内存占用的,在编码时假定栈上的空间是连续的,且定义的所有变量都连续分布在栈上。
实际上,虽然变量是连续分布在栈上的,但编译器会根据不同类型与对齐方式,将变量重新排列,达到最优情况。
#include <stdio.h>
#define print_position(type, n) \
type n; \
printf(#n ": %p\n", &n);
int main(void) {
print_position(int, a); // a: 0x7ffe84765408
print_position(double, b); // b: 0x7ffe84765410
print_position(char, c); // c: 0x7ffe84765407
print_position(float, d); // d: 0x7ffe8476540c
}
本文主要集中在结构体的对齐。
为什么需要内存对齐
性能
现代处理器拥有多级缓存,而数据必须通过这些缓存;支持单字节读取会将内存吞吐量和执行执行单元吞吐量紧密绑定 (称为 cpu-bound,CPU 绑定)。这与 PIO 被 DMA 超越 在硬件驱动上有很多相似的原因。
CPU 总是读取一个字长的大小 (32bit 处理器为 4 bytes),当访问未对齐的地址时 – 如果 CPU 支持的话,处理器会读入多个字。CPU 将跨字读取程序请求的地址,这将产生 2 倍于请求数据大小的内存读写。因此很容易出现读取 2 字节比读取 4 字节慢的情况。
如果一个两字节的数据在字内没有对齐,那处理器只需要读取一次,并执行一次偏移量计算,这通常只需要一个周期。
另外对齐可以更好的确定是否在同一个 cache line 上,某些类型的应用会针对 cache line 进行优化,从而取得更好的性能。
范围
给定任意的地址空间,如果架构认为 2 个最低有效位 (LSB) 总是 0 (如 32bit 机器),那么它可以访问四倍大小的内存 (2 bit 可以表示 4 个不同的状态),或者相同大小的内存但有额外两个标志位。2 个最低有效位意味着 4 字节对齐,地址在增加时只会从第 2 位开始变动,最低两位始终是 00。
这可以影响处理器的物理结构,这意味着地址总线可以少两位,或者 CPU 少两个针脚,亦或者电路板上少走 2 根线。
原子性
CPU 可以原子地操作对齐的字内存,这意味着没有指令可以中断这次操作。这对许多无锁数据结构和其他并发范式的正确操作有着至关重要的作用。
结论
处理器的内存系统比这里描述的复杂得多,这里有一个关于 x86 处理器如何实际寻址 的讨论,对这方面的理解会有些帮助 (许多处理器的工作方式差不多)。
坚持内存对齐还有很多好处,可以在这篇文章中阅读。计算机的主要用途是传输数据,现代内存架构和技术经过数十年的优化,以一种高度可靠的方式促进在更多、更快的执行单元间处理更多数据的输入、输出。
数据模型
C 与其派生语言在很多时候,类型的大小是和平台相关的,因此用数据模型来定义不同平台下的数据大小。
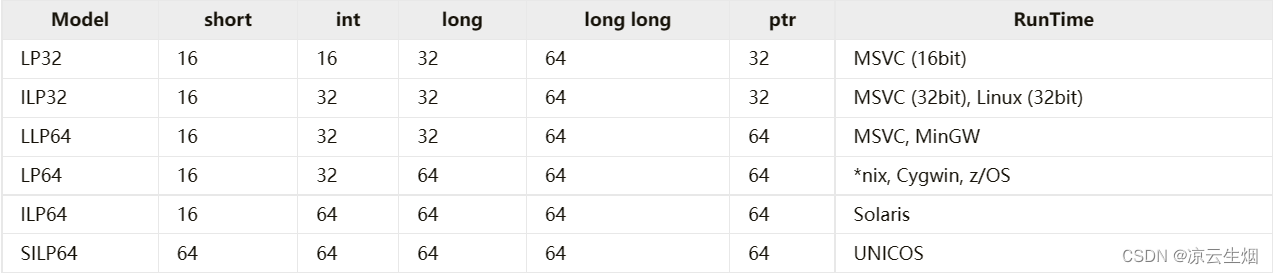
虽然数据模型定义很清楚,但在处理跨平台代码时,数据类型大小的处理是很头疼的。
好在 C / C++ 在 stdint.h 中还提供了更多种类的定长整型,长度主要是 8、16、32 和 64 bit,且提供了不同需求的定长整型 fast 和 least。
- 定长整型,e.g.
uint8_t、int16_t。定长整型是编译器可选项,因此可能不存在这个指定的类型。定长整型指定的位长度不可多也不可少,即强制要求位长度匹配。 - 最接近的定长整型,e.g.
int_least16_t、uint_least16_t。最接近的定长整型指可以比指定的位长度可以多但不可以少。比如使用uint_least8_t,但平台不支持uint16_t但支持uint32_t,因此该类型是uint32_t。 - 最快的定长整型,e.g.
int_fast32_t、uint_fast32_t。最快的定长整型指可以比指定的位多但不能少,且在满足指定位长的情况下使用执行最快的整型。比如使用uint_fast8_t,平台支持uint32_t和uint16_t,但最快的是uint32_t,因此该类型使用前者。
最后再说一下,由于指针在不同平台上的大小是不一样的,因此在转换指针位整型时,为了跨平台性,可以选择标准库可选的 intptr_t 和 uintptr_t。
C++ 的内存对齐
本章节数据模型为 LP64 data model
具名要求
平凡类
首先,可平凡复制类型 满足以下所有条件
- 至少有一个未被弃置的
复制构造函数、移动构造函数、复制赋值运算符或移动赋值运算符 - 每个复制构造函数都是平凡的或被弃置的
- 每个移动构造函数都是平凡的或被弃置的
- 每个复制赋值运算符都是平凡的或被弃置的
- 每个移动赋值运算符都是平凡的或被弃置的
- 有一个未被弃置的平凡析构函数
一个 平凡类,满足以下所有条件
- 是一个可平凡复制类型
- 有一个或多个默认构造函数,它们全部都是平凡的或被弃置的,而且其中至少有一个未被弃置
struct A {}; // is trivial
struct B { B(B const&) = delete; }; // is trivial
struct C { C() {} }; // is non-trivial
struct D { ~D() {} }; // is non-trivial
struct E { ~E() = delete; }; // is non-trivial
struct F { private: ~F() = default; } // is non-trivial
struct G { virtual ~G() = default; } // is non-trivial
struct H {
H() = default;
H(const H &) = delete;
H(H &&) noexcept = delete;
H &operator=(H const &) = delete;
H &operator=(H &&) noexcept = delete;
~H() = default;
}; // is non-trivial
struct I { I() = default; I(int) {} }; // is trivial
struct J {
J() = default;
J(const J &) {}
}; // is non-trivial
struct K { int x; }; // is trivial
struct L { int x{0}; }; // is non-trivial
如果你用 gcc 或 clang 编译,会发现编译器显示 E、F 和 H 是平凡类,按照标准,实际上应该不是平凡类,可以在 bugzilla 查看 gcc 和 clang 的 bug 报告。
另外,可平凡复制类可以用 ::memcpy 或 ::memmove 在两个不存在潜在重叠的对象之间互相拷贝。
struct A { int x; };
A a = { .x = 10 }; // C++20
A b = { .x = 20 };
::memcpy(&b, &a, sizeof(A)); // b.x = 10
平凡类可以认为不持有资源,因此可以直接覆盖或丢弃对象,不会造成资源的泄漏。
template <typename T, size_t N>
void destroy_array_element(
typename ::std::enable_if<::std::is_trivial<T>::value>::type (&/* arr */)[N]) {}
template <typename T, size_t N> void destroy_array_element(T (&arr)[N]) {
for (size_t i = 0; i < N; ++i) {
arr[i].~T();
}
}
标准布局类
满足以下所有条件是标准布局类
- 所有非静态数据成员都是标准布局类类型或它们的引用
- 没有虚函数和虚基类
- 所有非静态数据成员都具有相同的可访问性
- 没有非标准布局的基类
- 该类和它的所有基类中的非静态数据成员和位域都在相同的类中首次声明
- 给定该类为 S,且作为基类时集合
M(S)没有元素,其中 M(X) 对于类型 X 定义如下:- 如果 X 是没有 (可能继承来的) 非静态数据成员的非联合体类类型,那么集合 M(X) 为空。
- 如果 X 是首个非静态数据成员 (可能是匿名联合体) 具有 X0 类型的非联合体类类型,那么集合 M(X) 包含 X0 和 M(X0) 中的元素。
- 如果 X 是联合体类型,集合 M(X) 是包含所有 UiU_{i}Ui 的集合与每个 M(UiU_{i}Ui) 集合的并集,其中每个 UiU_{i}Ui 是 X 的第 i 个非静态数据成员的类型。
- 如果 X 是元素类型是 XeX_{e}Xe 的数组类型,集合 M(X) 包含 XeX_{e}Xe 和 M(XeXeXe) 中的元素。
- 如果 X 不是类类型或数组类型,那么集合 M(X) 为空。
struct A { int a; }; // is standard layout
struct B : public A { double b; }; // isn't standard layout
struct C { A a; double b; }; // is standard layout
struct D {
int a;
double b;
}; // is standard layout
struct E {
public: int a;
private: double b;
}; // isn't standard layout
struct F {
public: int fun() { return 0; }
private: double a;
}; // is standard layout
平凡类与标准布局类总结
很明显 C 语言中的所有类型都是标准布局的,但是 C++ 引入了 POD (plain old data) 的概念来表示 C 中这些类型 (C++20 移除了这一概念),即满足以下所有条件的类:
- 平凡类
- 标准布局类
- 所有非静态数据成员都是 POD 类类型
可以这样理解,平凡类规定了一个类型无关心任何资源,即最基础的构造、析构方式;标准布局类规定了一个类型如何布局每个字段的。只要是标准布局类就可以和 C 程序无痛操作,但这个类型可能不是平凡类型,因此将 POD 拆分为两个概念。
最好理解的就是 ::std::vector,它采用 RAII 的方式自己管理资源,有复杂的构造、析构函数,它不是一个平凡类,但它是一个标准布局类,因此完全其完全遵循内存对齐方式,也可以用 memcpy 将其内部的值拷贝下来。
// #include <stdint.h>
// #include <stdlib.h>
// #include <string.h>
// #include <iostream>
// #include <vector>
::std::vector<char> v{'a', 'b', 'c'};
uintptr_t *copy = reinterpret_cast<uintptr_t *>(::alloca(sizeof v));
::memcpy(copy, &v, sizeof v);
for (size_t i = 0, e = sizeof(v) / sizeof(uintptr_t); i < e; ++i) {
::std::cout << copy[i] << ::std::endl;
}
// maybe output:
// 94066226852544
// 94066226852547
// 94066226852547
标准布局类的内存对齐
内存对齐有些规律可循:
- 对象的起始地址能够被其对齐大小整除
- 成员相对于起始地址的偏移量能够被自身的对齐大小整除,否则在前一个成员后面填充字节
- 类的大小能够被其对齐大小整除,否则在最后填充字节
- 如果是空类,按照标准该类的对象必须占有一个字节 (除非 空基类优化),在C中空类的大小是 0 字节
- 默认条件下,类型的对齐大小与其所有字段的对齐大小最大值相同
普通的标准布局类
对于任何标准布局类,都可以轻松用上面的规律判断出类型的大小
struct S {}; // sizeof = 1, alignof = 1
struct T : public S { char x; }; // sizeof = 1, alignof = 1
struct U {
int x; // offsetof = 0
char y; // offsetof = 4
char z; // offsetof = 5
}; // sizeof = 8, alignof = 4
struct V {
int a; // offsetof = 0
T b; // offsetof = 4
U c; // offsetof = 8
double d; // offsetof = 16
}; // sizeof = 24, alignof = 8
struct W {
int val; // offset = 0
W *left; // offset = 8
W *right; // offset = 16
}; // sizeof = 24, alignof = 8
最后要说明一下数组,数组就像是你在这个位置引入了数组长度个该类型的变量。
struct S { int x[4]; }; // sizeof = 16, alignof = 4
struct T {
int a; // offsetof = 0
char b[9]; // offsetof = 4
short c[2]; // offsetof = 14
double *d; // offsetof = 24
}; // sizeof = 32, alignof = 8
struct U {
char x; // offsetof = 0
char y[1]; // offsetof = 1
short z; // offsetof = 2
}; // sizeof = 4, alignof = 2
你以为这就完了吗?当然不是,C 语言中有个很有意思的用法,即 C99 中出现的 柔性数组声明。将最后一个字段定义为数组,且长度为 0,此时数组底层数据类型将影响类型的对齐大小,但不会影响整个类型的大小。当然对于 C++ 标准并没有支持,全靠编译器自己去扩展。
struct S {
int i; // offset = 0
double d[]; // offset = 8
}; // sizeof = 8, alignof = 8
struct T {
int i; // offset = 0
char c[0]; // offset = 4
}; // sizeof = 4, alignof = 4
带有柔性数组成员的类,需要使用动态分配的方式,因为柔性数组成员无法被初始化。实际上编译器不能确定数组的长度,因此即使给定的额外的空间不足以存放底层类型数据,也由程序员保证访问的正确性,访问溢出的范围将是 UB。
S s1; // sizeof(s1) = 8, length(d) = 1, accessing d is a UB
// S s2 = {1, {3.14}}; // error: initialization of flexible array member is not allowed
S* s3 = reinterpret_cast<S*>(alloca(sizeof(S))); // equivalent to s1
// s4: sizeof(*s4) = 8, length(d) = 6
S *s4 = reinterpret_cast<S *>(alloca(sizeof(S) + 6 * sizeof(S::d[0])));
// s5: sizeof(*s5) = 8, length(d) = 1, accessing d[1] is a UB
S *s5 = reinterpret_cast<S *>(alloca(sizeof(S) + 10));
*s4 = *s5; // copy size = sizeof(S)
带有位域的标准布局类
对于带有位域的标准布局类,也很简单,位域不会跨底层数据存储,也就是说当剩余位不够时,下一个位域字段会存储在下一个底层数据中。而无名位域字段可以起到占位的作用。另外声明位域后,实际会用一个底层数据填充到类里,类的大小与对齐会收到该底层数据的影响。
struct S {
// offsetof = 0
unsigned char b1 : 3, : 2;
// offsetof = 1
unsigned char b2 : 6, b3 : 2;
}; // sizeof = 2, alignof = 1
位域字段的大小可以指定为 0,意味着下一个位域将声明在下一个底层数据中。但实际 0 长度的位域字段并不会为类引入一个底层数据。
struct S { int : 0; }; // sizeof = 1, alignof = 1
struct T {
uint64_t : 0;
uint32_t x; // offsetof = 0
}; // sizeof = 4, alignof = 4
struct U {
// offsetof = 0
unsigned char b1 : 3, : 0;
// offsetof = 1
unsigned char b2 : 2;
}; // sizeof = 2, alignof = 1
手动指定对齐大小的标准布局类
回到本章开始的 5 条规律,实际上自己手动指定对齐时,也是适用的。
#pragma pack(N) 和 gnu::packed 指定排布字段时以打包方式进行,即每个字段都连续排布,字段与字段之间不会产生额外的内存空洞,这样可以减少不必要内存的浪费。
struct [[gnu::packed]] S {
uint8_t x; // offsetof = 0
uint16_t y; // offsetof = 1
}; // sizeof = 3, alignof = 1
struct [[gnu::packed]] T {
uint16_t x : 4;
uint8_t y; // offsetof = 1
}; // sizeof = 2, alignof = 1
struct [[gnu::packed]] alignas(4) U {
uint8_t x; // offsetof = 0
uint16_t y; // offsetof = 1
}; // sizeof = 4, alignof = 4
struct [[gnu::packed]] alignas(4) V {
uint16_t x : 4;
uint8_t y; // offsetof = 1
}; // sizeof = 4, alignof = 4
但是今天的重点是 C++11 引入的 alignas 声明符。实际上它不止可以指定结构体时如何对齐的,还可以指定一个对象是怎么对齐的。指定的对齐大小都必须是 2 的正整数幂,如果指定的对齐方式弱于默认的对齐方式,编译器可能会忽略或报错。
最简单的先从指定结构体的声明说起。
struct alignas(4) S {}; // sizeof = 4, alignof = 4
struct SS {
S s; // offsetof = 0
S *t; // offsetof = 8
}; // sizeof = 16, alignof = 8
struct alignas(SS) T {
S s; // offsetof = 0
char t; // offsetof = 4
short u; // offsetof = 6
short v; // offsetof = 8
}; // sizeof = 16, alignof = 8
struct alignas(1) U : public S {}; // error or ignore
// struct alignas(5) V : public S {}; // error
struct alignas(4) W : public S {};
alignas 的应用主要为了获取更好的性能,或者匹配 SIMD 指令。
非标准布局类的内存对齐
对于访问限定造成的非标准布局类,我们不能假定其按照标准布局进行布局,其行为依赖于编译器。在 C++11 标准中,只保证了在同一访问性的变量按声明顺序排布,但不保证不同访问性的变量的排布顺序。
struct S {
public: int s;
int t;
private: int u;
public: int v;
};
也就是说,上面这个示例中,只保证了 &S::s < &S::t < &S::v,但不会保证 &S::s < &S::u。或者说,在内存中,可能出现 s, t, u, v 的顺序,也可能出现 u, s, t, v 的顺序。
当然不止访问性导致的顺序问题,在不同类中声明的字段也会造成顺序问题。也就是说,我们不能假定基类中声明的变量,其位置一定先于派生类中声明的变量。
struct S { int s; };
struct T { int t; };
struct U : public S, T { int u; };
也就是说,上面这个示例中,不能保证 &U::s < &U::u。但是标准保证,在派生类指针转换到基类指针时,会自动计算基类字对象的偏移量。但不保证 U 的对象首地址就是 S 的字对象首地址。
U *up = reinterpret_cast<U *>(alloca(sizeof(U)));
S *ssp = static_cast<S *>(up); // offset adjustment
T *stp = static_cast<T *>(up); // offset adjustment
S *rsp = reinterpret_cast<S *>(up); // no offset adjustment
T *rtp = reinterpret_cast<T *>(up); // no offset adjustment
最后再来说一下虚类的内存对齐,这是很有意思的一个问题。标准并没有规定如何实现虚函数,但大部分的编译器都采用虚表的方式实现,即在对象中插入一个虚函数表的指针。但是需要注意的是,虚表一个对象中仅存在,基类子对象中不会有虚表。
struct S {
bool s; // offsetof = 0
}; // sizeof = 1, alignof = 1
struct T {
virtual ~T() = default;
int t;
};
struct U : public S, T {
virtual ~U() = default;
int u;
};
在编译器的实现中,很可能先排布虚基类,再排布非虚基类,因此在不同的排布方式其类大小与布局是无法确定的。
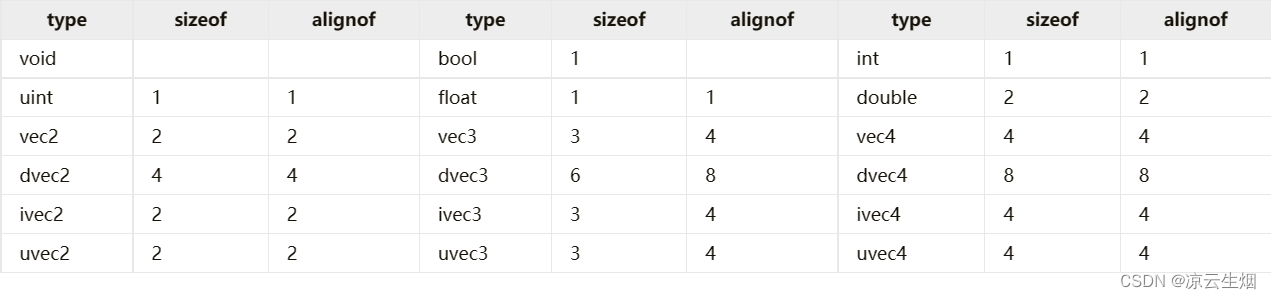
GLSLang 的内存对齐
GLSL 4.60, Vulkan binding
在 GLSLang 中,一个字长为 4 bytes。而 GLSLang 中的对齐,也和 C / C++ 中很相似,因此在标准布局类的内存对齐中介绍的对齐方式,和这里是基本一致的。另外 GLSLang 中基础类型的大小都是字长的倍数,因此之后 sizeof 的结果单位默认为 word。
buffer 的布局修饰
buffer 作为可读可写的全局对象,其布局由实现定义,除非手动指定布局。uniform 是一种特殊的全局 buffer,只可读,默认 std140 布局且无法修改;push_constant 是一种特殊的 uniform,其存储在寄存器,大小约为 16 words,实现可以使用 uniform 代替实现,当超出大小时同样将超出部分存储在 uniform buffer 中,默认布局为 std430,可以修改布局。
在 buffer 中,默认矩阵都是列主矩阵 (column_major),可以在布局中对其进行修改
layout(binding = 0, column_major) buffer CMTest {
// matrix stride = 16
mat2x3 cm; // is equalent to 2-elements array of vec3
};
layout(binding = 1, row_major) buffer RMTest {
// matrix stride = 8
mat2x3 rm; // is equalent to 3-elements array of vec2
};
packed 与 CPU 上的概念是一致的,尽可能紧凑的排布字段,节省内存,而不考虑对齐。但 SPIRV 禁止使用 packed 与 shared 的布局方式。
在 GLSLang 的布局中,其偏移量同样是对齐大小的整数倍。std140 布局有以下规律
- 标量类型其对齐大小与自身大小相同
- 二元或四元向量,其基础类型大小若为 N,则向量大小与对齐大小相同,对齐大小为 2N2N2N 或 4N4N4N。特别地,三元向量的大小为 3N3N3N,但对齐大小为 4N4N4N
- 数组中的每个元素填充到 4 words 的倍数
- 结构体变量的对齐大小填充到 4 words 的倍数
- C 列 R 行的列主矩阵,等价于一个有 C 个 R 元向量的数组;类似的,有 N 个元素的列主矩阵的数组,等价于一个有 N×CN \times CN×C 个 R 元向量的数组
- C 列 R 行的行主矩阵,等价于一个有 R 个 C 元向量的数组;类似的,有 N 个元素的行主矩阵的数组,等价于一个有 N×RN \times RN×R 个 C 元向量的数组
struct S {
vec2 v;
};
layout(binding = 0, std140) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
vec3 v1; // offsetof = 16
uint u; // offsetof = 19
S s; // offsetof = 20
float f2; // offsetof = 24
vec2 v2; // offsetof = 26
dvec3 dv; // offsetof = 32
} bo; // sizeof = 40, alignof = 8
对于 std430 布局,不再有 std140 中的将数组和结构体元素对齐填充到 4 words 的要求,也就是说,std430 更为紧凑,且更接近我们在 CPU 中的布局。
struct S {
vec2 v;
};
layout(binding = 0, std430) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
vec3 v1; // offsetof = 12
uint u; // offsetof = 15
S s; // offsetof = 16
float f2; // offsetof = 18
vec2 v2; // offsetof = 20
dvec3 dv; // offsetof = 24
} bo; // sizeof = 32, alignof = 8
虽然默认的布局方式已经很好了,不过有时也可能会手动的修改以下字段的偏移量。这时候需要使用 offset。但是编译器不会检查手动设置的偏移量是否与其他字段存在重叠。
layout(binding = 0, std430) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
layout(offset = 48) uint u; // offsetof = 12
vec2 v; // offsetof = 14
layout(offset = 0) int i; // offset = 0
} bo;
align 的使用也和前面说的 CPU 上的用法差不多
layout(binding = 0, std430) buffer BufferObject {
vec2 a; // offsetof = 0
layout(align = 16) float b; // offsetof = 4
} bo; // sizeof = 8, alignof = 4
location
location 相当于每个 shader 数据传输的一个存储点,location 根据编号进行匹配,其匹配上一个 shader 的 in 与下一个 shader 的 out。同一个 location 不能在 shader 中声明多次,in 与 out 是完全不同的 location。
layout(location = 0) in vec2 i;
// layout(location = 0) in vec2 i2; // error
layout(location = 0) out vec2 o; // okay
location 大小为 4 words。声明的每个变量占据一个 location,当变量大小大于 4 words 时,将顺延占据下一个 location。
layout(location = 0) in dvec4 dv;
// location = 1, occupied by dv
// layout(location = 1) in vec4 v; // error
layout(location = 2) in vec4 v;
而数组每个元素占据一个 location,并且元素占据的 location 值是依次递增的,因此
layout(location = 0) in float a[2];
// location = 1, occupied by a[1]
layout(location = 2) in float f1;
layout(location = 3) in mat2 m[2]; // cxr matrix is equialent to c-elements array of r-vector
// location = 4, occupied by m[0]
// location = 5, occupied by m[1]
// location = 6, occupied by m[1]
layout(location = 7) in float f2;
一个一个指定 location 实在是太麻烦了,因此可以使用 block 来指定第一个变量的初始 location 值,然后让其他变量的 location 值自动递增。
layout(location = 3) in block {
float a[2]; // location = 3
mat2 m; // location = 5
vec2 v; // location = 7
layout(location = 0) mat2 m2; // location = 0
bool b; // location = 2
// vec3 v3; // error
layout(location = 8) vec3 v3; // location = 8
};
也可以用 struct 来递增 location,但区别是无法在 struct 中指定 location。
layout(locaton = 3) in struct {
vec3 a; // location = 3
mat2 b; // location = 4, 5
// layout(location = 6) vec2 c; // error
};
之前说过 location 的大小是 4 words,如果一个 location 只用其中的一部分存储变量显然是低效的,component 可以指定变量在 location 的偏移量。但是需要注意的是, component 偏移后剩余部分必须能存储该变量。
layout(location = 0, component = 0) in float x; // l = 0, c = 0
layout(location = 0, component = 1) in float y; // l = 0, c = 1
layout(location = 0, component = 2) in float z; // l = 0, c = 2
layout(location = 1) in vec2 a; // l = 1, c = 0
// layout(location = 1, component = 2) in dvec3 b; // error
layout(location = 2, component = 0) in float b; // l = 2, c = 0
layout(location = 2, component = 1) in vec3 c; // l = 2, c = 1
如果指定了数组的 component,则数组的每个元素依然顺序递增占据每个 location,但每个 location 的起始位置都是指定的 component。
layout(location = 0, component = 2) in float f[6]; // every element c = 2
// layout(location = 2, component = 0) in vec4 v; // error
layout(location = 1, component = 0) in vec2 v; // l = 1, c = 0
// f[1] at location 1, component 2
使用 GLM 与 GLSLang 传递数据
写这篇文章的起因完全是因为在 host 和 device 之间传递数据时,遇到了一个对齐相关的 bug。
struct PCO {
uint32_t time; // offsetof = 0
::glm::vec2 extent; // offsetof = 4
}; // sizeof = 12, alignof = 4
layout(push_constant) uniform PCO {
int time; // offsetof = 0
vec2 extent; // offsetof = 2
}; // sizeof = 4, alignof = 2
在反复检查代码没有问题后,尝试交换 time 字段与 extent 字段,结果程序能正常运行。很明显 host 的对齐与 device 是不一致的。由于 SPIRV 无法使用 packed 来压缩内存大小,因此只能手动实现对齐。
通过之前的学习,在此列出几种比较优雅的解决这个问题的方法。
- 利用位域产生空洞,强迫结构体与 glsl 中布局一致
- 指定字段与 glsl 中的对齐大小一致
struct PCO {
uint32_t time; // offsetof = 0
uint32_t : 1, : 0;
::glm::vec2 extent; // offsetof = 8
}; // sizeof = 16, alignof = 4
struct PCO {
uint32_t time; // offsetof = 0
alignas(8)::glm::vec2 extent; // offsetof = 8
}; // sizeof = 16, alignof = 8