前言
本文是该专栏的第18篇,后面会持续分享python的数据分析知识,记得关注。
假设现在有个数据分析的需求,如下:
数据表1中有几十万条数据,数据表2中有几万条数据,两张数据表1和2有两个相同的字段phone,现在需要将数据表1和数据表2中,phone字段存在相同的行,保留下来,其余的行删除掉。
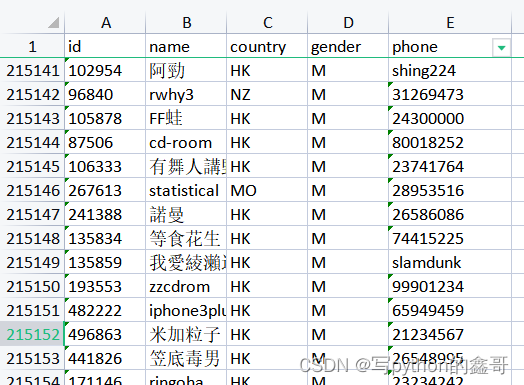
数据表1如下:
数据表2如下:
对比分析两张表,数据表1中的phone字段,有整型也有字符串类型,但数据表2中的phone字段都是整型,使用数据表1中的字符串类型可以不用管,到时之间剔除掉即可。
值得注意的是,数据表2中的phone字段是11位数,数据表1中的phone字段是8位数。
废话不多说,直接跟着笔者使用pandas来操作这个案例如何进行。