【ML】异常检测、PCA、混淆矩阵、调参综合实践(基于sklearn)
- 加载数据
- 可视化数据
- 异常点检测
- PCA降维
- 使用KNN进行分类并可视化
- 计算混淆矩阵
- 调节n_neighbors参数找到最优值
加载数据
数据集:https://www.kaggle.com/datasets/yuanheqiuye/data-class-raw
# 加载数据
import numpy as np
import pandas as pd
data = pd.read_csv('/kaggle/input/data-class-raw/data_class_raw.csv')
X = data.drop(columns=['y'])
y = data.loc[:,'y']
data.head()
输出:
| x1 | x2 | y | |
|---|---|---|---|
| 0 | 0.77 | 3.97 | 0 |
| 1 | 1.71 | 2.81 | 0 |
| 2 | 2.18 | 1.31 | 0 |
| 3 | 3.80 | 0.69 | 0 |
| 4 | 5.21 | 1.14 | 0 |
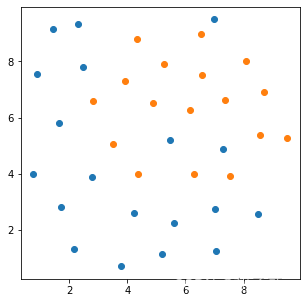
可视化数据
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(5,5))
plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
plt.show()
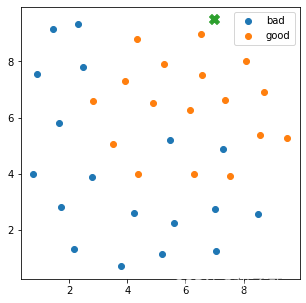
异常点检测
这里只找出了一个分类的,其他分类异常点可以类似处理
# 找出异常点
from sklearn.covariance import EllipticEnvelope
# 这里只找出了y=0点中的异常点,相同方法可以找出y=1中的异常点
X_bad = X.loc[y==0]
X_good = X.loc[y==1]
model = EllipticEnvelope(contamination=0.02).fit(X_bad)
y_predict = model.predict(X_bad)
print(y_predict)
# 输出:[ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 -1]
# 绘图
fig2 = plt.figure(figsize=(5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
plt.scatter(X.loc[:,'x1'][y==0][y_predict==-1],X.loc[:,'x2'][y==0][y_predict==-1],marker='X',s=100)
plt.legend((bad,good),('bad','good'))
plt.show()
PCA降维
经过上一步将异常数据去掉之后,得到处理后的数据集:
https://www.kaggle.com/datasets/yuanheqiuye/data-class-processed
然后进行PCA主成分分析,尝试降维。
# pca降维
# 读取已经处理好的数据
data2 = pd.read_csv('/kaggle/input/data-class-processed/data_class_processed.csv')
data2.head()
X2 = data2.drop(columns=['y'])
y2 = data2.loc[:,'y']
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
X2_norm = StandardScaler().fit_transform(X2)
pca = PCA(n_components=2)
pca.fit(X2_norm)
var_ratio = pca.explained_variance_ratio_
print(var_ratio)
输出:[0.5369408 0.4630592]
两个维度都很关键,不做降维处理。
使用KNN进行分类并可视化
此处先随机取值n_neighbors=10
# 基于KNN进行分类训练
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train,X_test,y_train,y_test = train_test_split(X2,y2,random_state=4,test_size=0.4)
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train,y_train)
y_train_predict = knn.predict(X_train)
y_test_predict = knn.predict(X_test)
from sklearn.metrics import accuracy_score
acc_train = accuracy_score(y_train, y_train_predict)
acc_test = accuracy_score(y_test, y_test_predict)
print('acc_train=',acc_train,'acc_test=', acc_test)
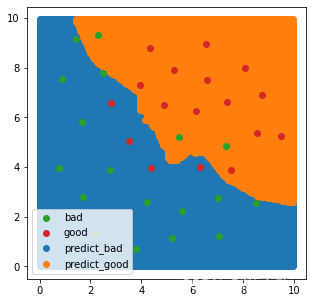
# 可视化分类边界
# 数据准备
xx,yy = np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05))
xy_origin = np.c_[xx.ravel(),yy.ravel()]
# 因为训练的时候指定了列名,此处也指定,否则会有警告
xy = pd.DataFrame(xy_origin, columns=['x1', 'x2'])
xy_predict = knn.predict(xy)
# 画图
fig2 = plt.figure(figsize=(5,5))
predict_bad = plt.scatter(xy.loc[:,'x1'][xy_predict==0],xy.loc[:,'x2'][xy_predict==0])
predict_good = plt.scatter(xy.loc[:,'x1'][xy_predict==1],xy.loc[:,'x2'][xy_predict==1])
bad = plt.scatter(X2.loc[:,'x1'][y2==0],X2.loc[:,'x2'][y2==0])
good = plt.scatter(X2.loc[:,'x1'][y2==1],X2.loc[:,'x2'][y2==1])
plt.legend((bad,good,predict_bad,predict_good),('bad','good','predict_bad','predict_good'))
plt.show()
计算混淆矩阵
混淆矩阵图:

from sklearn.metrics import confusion_matrix
m = confusion_matrix(y_test,y_test_predict)
print(m)
TN = m[0][0]
FP = m[0][1]
FN = m[1][0]
TP = m[1][1]
print('TN=',TN,'FP=',FP,'FN=',FN,'TP=',TP)
输出:
[[4 2]
[3 5]]
TN= 4 FP= 2 FN= 3 TP= 5
# 准确率:整体样本中预测正确样本的比例 accuracy = (TP+TN)/(TP+TN+FP+FN)
accuracy = (TP+TN)/(TP+TN+FP+FN)
print(accuracy)
# 召回率:正样本中预测真确的比例 recall = TP/(TP+FN)
recall = TP/(TP+FN)
print('recall=',recall)
# 特异度:负样本中预测为负的比例 specificity = TN/(TN+FP)
specificity = TN/(TN+FP)
print('specificity=',specificity)
# 精确度: 预测结果为正的样本中,预测正确的比例 Precition = TP/(TP+FP)
precition = TP/(TP+FP)
print('precition=',precition)
# F1: 综合precition和recall的一个判断指标 F1 = 2 * precition * recall/(precition+recall)
F1 = 2*precition*recall/(precition+recall)
print('F1=',F1)
输出:
accuracy= 0.6428571428571429
recall= 0.625
specificity= 0.6666666666666666
precition= 0.7142857142857143
F1= 0.6666666666666666
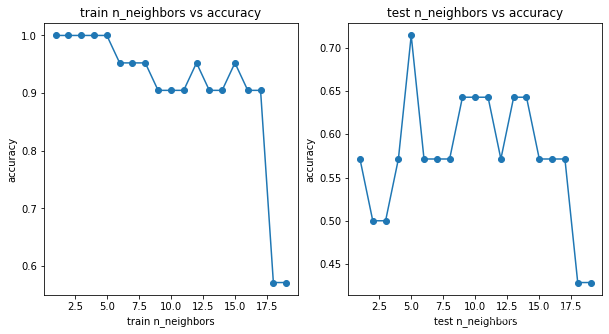
调节n_neighbors参数找到最优值
# 尝试不同的n_neighbors,通过准确度来判断选用什么类型的值
accuary_train_arr = []
accuary_test_arr = []
for i in range(1,20):
knn_i = KNeighborsClassifier(n_neighbors=i)
knn_i.fit(X_train,y_train)
y_i_train_predict = knn_i.predict(X_train)
y_i_test_predict = knn_i.predict(X_test)
accuary_i_train = accuracy_score(y_train, y_i_train_predict)
accuary_i_test = accuracy_score(y_test, y_i_test_predict)
accuary_train_arr.append(accuary_i_train)
accuary_test_arr.append(accuary_i_test)
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.plot(range(1,20),accuary_train_arr)
plt.scatter(range(1,20),accuary_train_arr)
plt.xlabel('train n_neighbors')
plt.ylabel('accuracy')
plt.title('train n_neighbors vs accuracy')
plt.subplot(122)
plt.plot(range(1,20),accuary_test_arr)
plt.scatter(range(1,20),accuary_test_arr)
plt.xlabel('test n_neighbors')
plt.ylabel('accuracy')
plt.title('test n_neighbors vs accuracy')
plt.show()
由下图可知:在neighbors=5的情况下取到最好的accuracy

![[JavaEE] 线程与进程的区别详解](https://img-blog.csdnimg.cn/2a11da931ec84cef8442db590421d00a.png)