大道三千:最近我修Flink
目前个人理解:
处理有界,无界流的工具
FLINK:
FLINK定义:
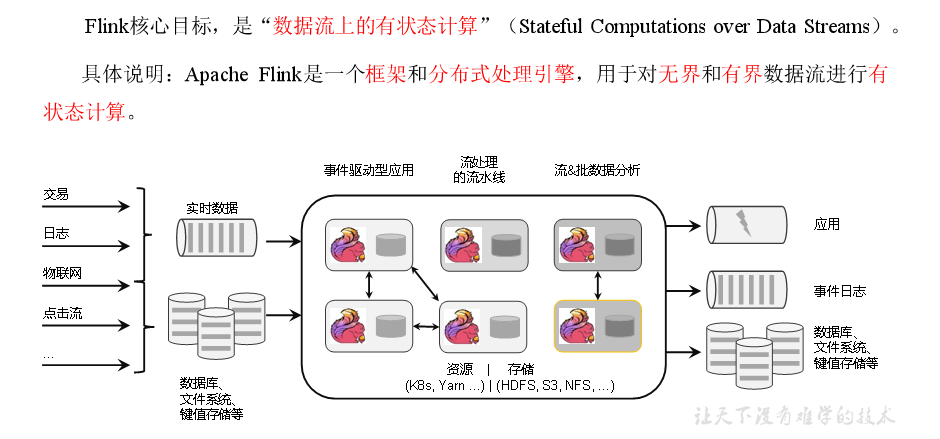
Flink特点

Flink分层API

流的定义
有界数据流(批处理):
有界流:数据结束了,程序也就结束了
知道数据开始以及结束的地方

无界数据流:
特征:读一条,计算一条,输出一次结果
知道数据开始的地方,却不知道结束的地方
(好似长江大河,会一直一直一直产生数据)

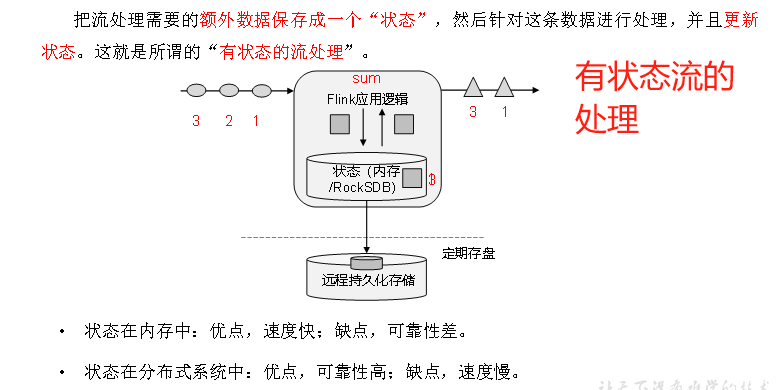
流的状态
个人理解:(有状态流会基于内存保存之前的数据)
如果后续流的操作需要用到之前的数据,这个流时有状态的
如果后续流的操作不需要用到之前的数据,这个流是无状态的


DataSet API:有界流批处理( 已淘汰)

1:创建执行环境
2:读取流(数据)
3:将读取到的数据,转换为方便处理的格式
4:将收集到的数据进行(分组,求和,最大,最小等....)操作
//批处理方式(有界流,因为很明确的知道这个文件在哪里结束)
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override //一行数据 // 数据收集器 out:相当于是一个按照 下面格式收集数据的收集器 格式=out.collect(Tuple2.of(word,1L));
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = line.split(" "); //一行数据按照" "拆分
for (String word : words) { //word = 一行中的每一个字段 如果1改成2,则统计时数目会成2
Tuple2<String, Long> of = Tuple2.of(word, 1L);//每个的那次都转为这种格式
out.collect(of); // 收集器添加数据 (转换格式为 (循环到的字段,1L))
}
}
});
// 4. 按照 word 进行分组 按照第一个字段分组.(字段,1L),就是按照第一个字段分组(A,1),(b,1),(c,1),(d,1),(d,1) 就是按照abcd分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计 根据第二个字段求和,即将每个分组的第二个字段相加,得到该分组的总和
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
DataStream API:流、批一体处理

转换(flatMap)、
分组(keyBy)、
求和(sum)、
执行(execute)、
读取文本(readTextFile,有界流)
1:创建流式执行环境(基于StreamExecutionEnvironment)
2:读取文件
3:转换、分组、求和,得到统计结果
4:打印输出
5:执行

//流处理方式 (有界流,因为很明确的知道这个文件在哪里结束),如果不是本地而是网络则是无界流
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineStream = env.readTextFile("input/words.txt");
// 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Integer>> resultList = lineStream.flatM
输入类型,输出类型
ap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override //当前行数据 //要返回的类型
public void flatMap(String line, Collector<Tuple2<String, Integer>> list) throws Exception {
String[] fields = line.split(" ");
for (String field : fields) {
Tuple2<String, Integer> result = Tuple2.of(field, 1);
list.collect(result);
}
}
});
//分组 // 传入的数据类型() 要分组的数据类型
KeyedStream<Tuple2<String, Integer>, String> gropbyDate = resultList.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0; //这里是类型的第一位。如(hello,1),则是根据hello进行分组
}
});
//求和。 以上一个为例子:(hello,1)分组之后,根据1索引即第二位(hello,1)的1进行求和
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = gropbyDate.sum(1);
//打印输出
sum.print();
//执行
env.execute();
}
} // 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}
}).keyBy(data -> data.f0)
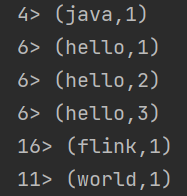
.sum(1);结果:
读取socket(无界流)
事件监听(环境对象.socketTextStream(IP,端口号))
备注:先启动linux 输入命令nc -lk 7777
然后启动代码监听 7777
此时linux输入的数据会被代码抓取到
备注2:跟前两个的区别就是这个是调用的socketTextStream。其他无任何区别
//监听7777端口的数据流
// 这里代码监听了 IP地址192.168.200.130 端口号7777 的操作 。ip地址那里写主机名也行
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
//构建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//拿到数据
DataStreamSource<String> lineStream = env.socketTextStream("192.168.200.130", 7777);
// 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> convert = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] fields = line.split(" ");
for (String field : fields) {
Tuple2<String, Long> of = Tuple2.of(field, 1L);
out.collect(of);
}
}
});
//分组
KeyedStream<Tuple2<String, Long>, Object> gropBy = convert.keyBy(new KeySelector<Tuple2<String, Long>, Object>() {
@Override
public Object getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
//求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = gropBy.sum(1);
//输出
sum.print();
//执行
env.execute();
}
}
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(data -> data.f0)
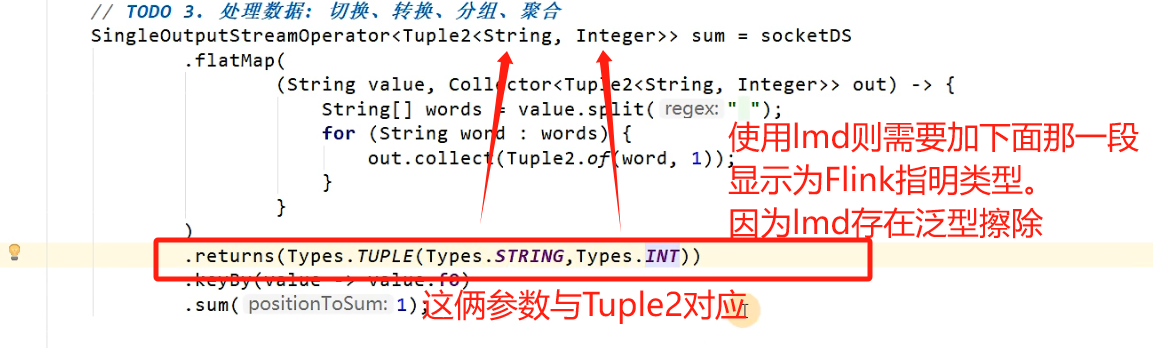
.sum(1);LMD存在泛型擦除,解决方案看这里




![[尚硅谷React笔记]——第7章 redux](https://img-blog.csdnimg.cn/4a8b9927965747748545235cfec7fa6d.png)

![【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]](https://img-blog.csdnimg.cn/img_convert/9512e7ff7193be9616e602a7bfd51f74.jpeg)


![[GKCTF 2021]easycms 禅知cms](https://img-blog.csdnimg.cn/92da5b847be1489da3bed6a93c800a06.png)