一、冒泡排序缺点
冒泡排序是一种简单但效率较低的排序算法。冒泡排序通过比较相邻元素并交换位置来实现排序。具体而言,它从数组的第一个元素开始,依次比较相邻的两个元素,如果顺序错误则交换它们的位置,直到整个数组排好序为止。但是冒泡排序算法的时间复杂度为O(n^2),不管数据是否已经有序,都会进行比较。导致大数据量时执行效率低下,这里将探讨两种方式改进冒泡排序算法以降低时间复杂度
二、改进策略
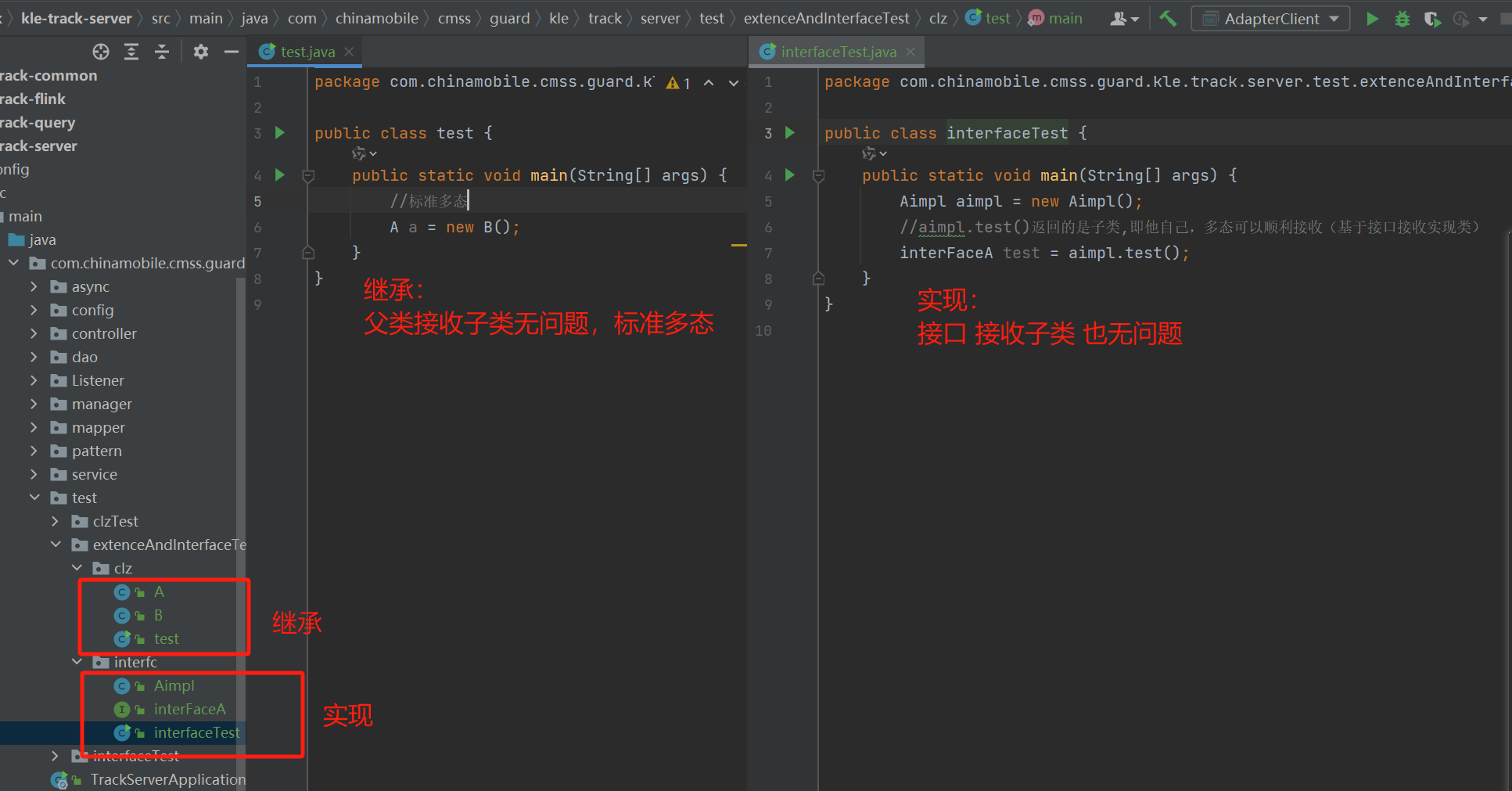
在每一轮的内层循环中,如果没有交换元素,则说明数组已经有序,可以提前退出外层循环,避免不必要的比较操作。实际代码中可以在外层循环中加入是否进行数据交换的判断,直接退出循环,减少时间复杂度。以下是使用matlab编写的冒泡排序算法和改进冒泡排序算法的示例代码:
- 冒泡排序算法函数
%% 冒泡排序函数
function [sortedArr,o] = bubbleSort(arr)
n = length(arr);
o = 0;%时间复杂度
for i = 1:n-1
for j = 1:n-i
o = o + 1;
if arr(j) > arr(j+1)
% 交换元素
temp = arr(j);
arr(j) = arr(j+1);
arr(j+1) = temp;
end
end
end
sortedArr = arr;
end
- 改进冒泡排序算法函数
%% 改进冒泡排序函数
function [sortedArr,o] = mbubbleSort(arr)
n = length(arr);
o = 0;%时间复杂度
for i = 1:n-1
flag = false;
for j = 1:n-i
o = o + 1;
if arr(j) > arr(j+1)
% 交换元素
temp = arr(j);
arr(j) = arr(j+1);
arr(j+1) = temp;
flag = true;
end
end
if flag == false
break;
end
end
sortedArr = arr;
end
- 调用
clc;
clear;
arr = [65, 9,11,12,25,22,34];
%% 常规冒泡排序
[sortedArr,o] = bubbleSort(arr);
disp("***********常规冒泡排序*****************************");
disp("排序前的数组:");
disp(arr);
disp("排序后的数组:");
disp(sortedArr);
disp("时间复杂度:");
disp(o);
%% 改进冒泡排序
[sortedArr,o] = mbubbleSort(arr);
disp("***********改进冒泡排序*****************************");
disp("排序前的数组:");
disp(arr);
disp("排序后的数组:");
disp(sortedArr);
disp("时间复杂度:");
disp(o);
三、性能分析与结论
如图所示为上述两种方式的打印结果

可知,通过改进策略对数组[65, 9,11,12,25,22,34]冒泡排序,可以吧时间复杂度从21降低至15。
实际上针对需要排序的数组对象,冒泡排序的时间复杂度可最高仍然是O(n^2),但在数组有序度比较高时,可以降低时间复杂度,在最好情况下,即数组已经有序时,时间复杂度可达到O(n)。
下面两图是针对同一组数据使用冒泡算法和改进冒泡算法的排序流程图。可以直观的看出两种方式的差异。
-
常规冒泡排序法过程示意

-
改进冒泡排序法过程示意

三、总结
改进冒泡排序算法仍然对于学习和理解基本排序算法有着重要意义。通过深入掌握冒泡排序的原理以及不断进行优化,我们可以更好地理解算法的设计思想,并为今后解决各类排序问题提供参考。然而,冒泡排序仍然不适用于大规模数据的排序,因为时间复杂度和数据的有序程度相关,不完全可控。在实际应用中,我们更倾向于使用其他高效的排序算法,如快速排序或归并排序。



![[尚硅谷React笔记]——第7章 redux](https://img-blog.csdnimg.cn/4a8b9927965747748545235cfec7fa6d.png)

![【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]](https://img-blog.csdnimg.cn/img_convert/9512e7ff7193be9616e602a7bfd51f74.jpeg)


![[GKCTF 2021]easycms 禅知cms](https://img-blog.csdnimg.cn/92da5b847be1489da3bed6a93c800a06.png)