文章目录
- 一.前言
- 1.1 实验内容
- 二.实验过程
- 2.1 实验内容一:掌握基于Kettle的字符串数据清洗
- 2.2 实验内容二:掌握基于Kettle的字段清洗
- 2.3 实验内容三:掌握基于Kettle的使用参照表集成数据
- 2.4 实验心得:
一.前言
需要本文章的源文件下链接自取:【ktr源文件】
https://download.csdn.net/download/weixin_52908342/87346930
1.1 实验内容
本次实验内容如下:
-
掌握基于Kettle的字符串数据清洗
-
掌握基于Kettle的字段清洗
-
掌握基于Kettle的使用参照表清洗
二.实验过程
2.1 实验内容一:掌握基于Kettle的字符串数据清洗
-
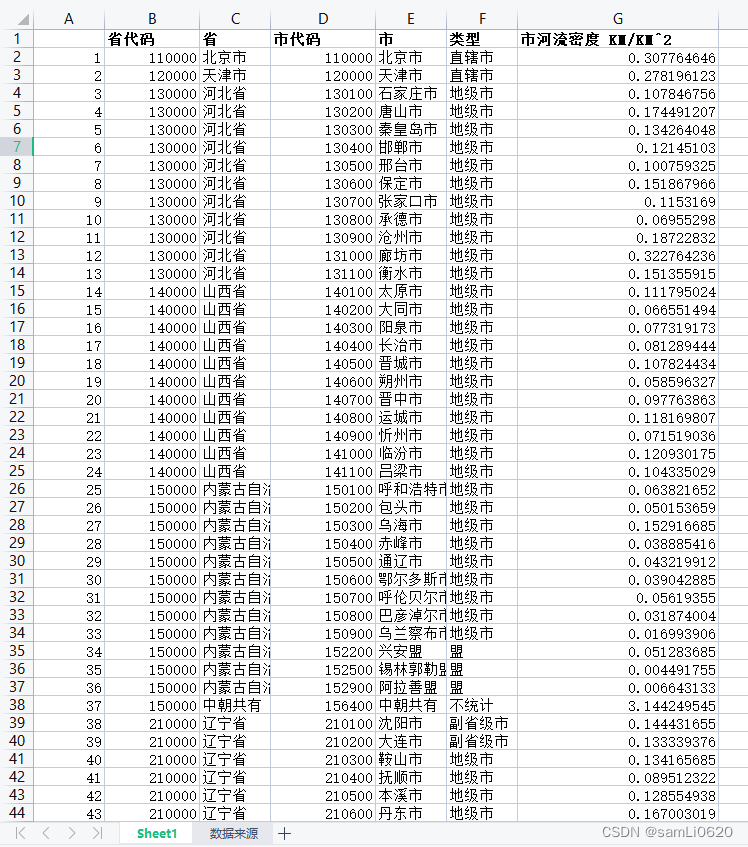
数据清理,就是试图检测和去除数据集中的噪声数据和无关数据,处理遗漏数据,去除空白数据域和知识背景下的白噪声,解决数据的一致性、唯一性问题,从而达到提高数据质量的目的。
-
基于Kettle的字符串数据清洗包括字符串替换(Replace in string)、字符串操作(String operations) 和字符串剪切(Strings cut)。字符串替换和字符串剪切功能相对单一,但由于字符串替换支持正则表达式,所以真正的功能远比字面上表达的强大许多。字符串操作提供了字符串的常规操作,功能丰富
-
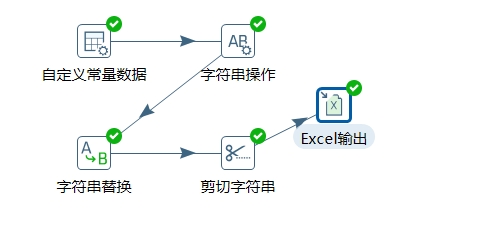
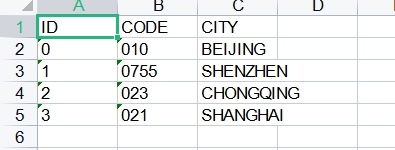
第一步,输入。可以使用“输入自定义常量数据(Data Grid)“步骤作为输入。
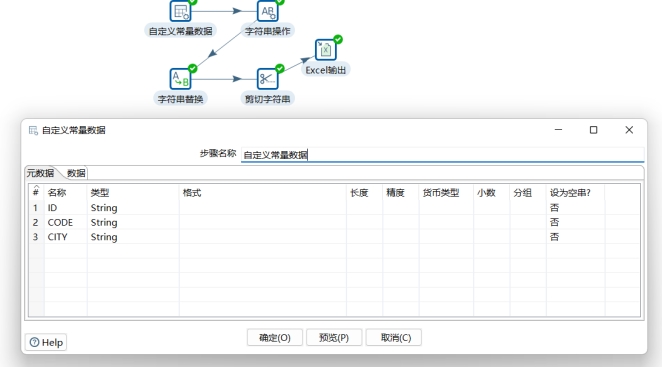
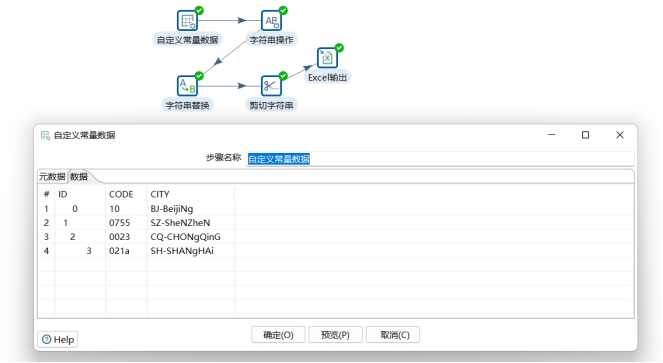
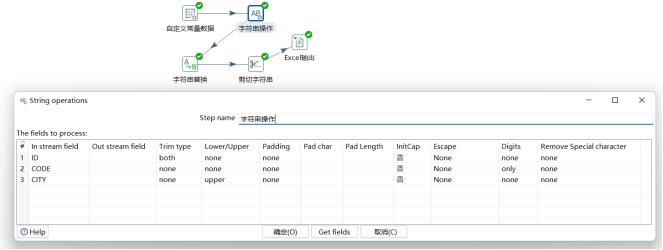
4.第二步,使用“字符串操作”步骤做初步清理。达到以下目标:
-
清除ID字段的前后空白字符
-
提取CODE字段的数字
-
转换CITY字段全部为大写
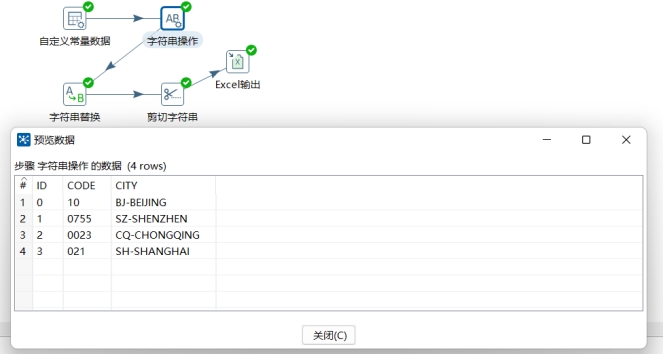
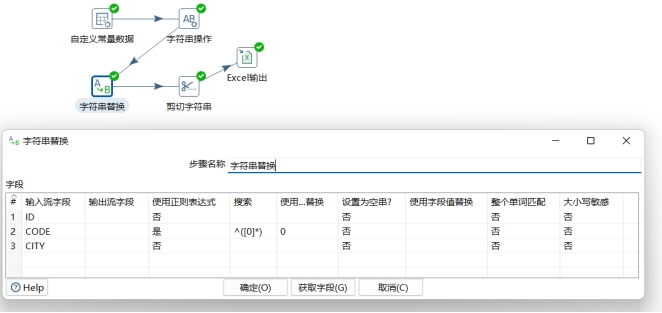
- 第三步,使用“字符串替换”步骤清理CODE字段。使CODE字段全部以一个数字0开始
- 第四步,使用“字符串剪切”步骤清理CITY字段。使CITY字段只包括城市名拼音
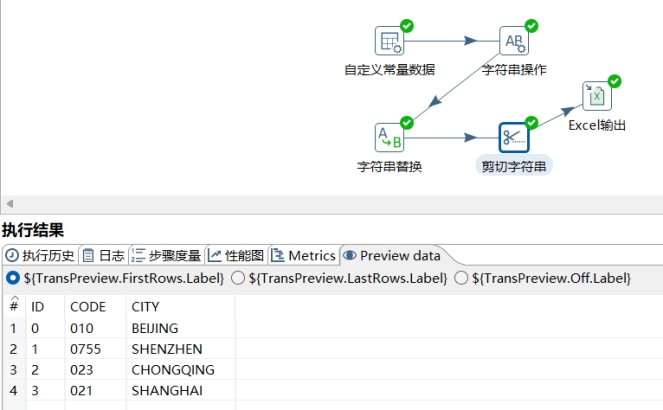
- 第五步,输出清理结果,选用Excel输出步骤
- 点击运行按钮,在弹出的对话框中点击启动按钮。
2.2 实验内容二:掌握基于Kettle的字段清洗
-
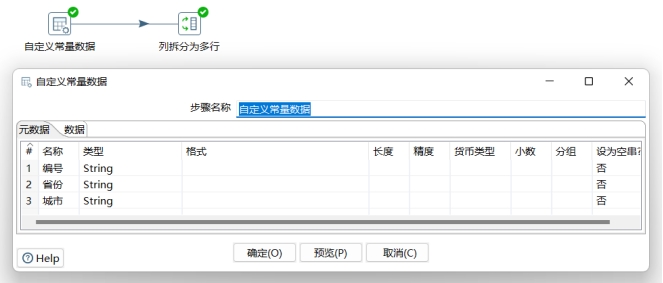
用拆分字段成多行步骤将城市字段拆分成多行
-
新建一个转换field_op,添加一个输入步骤Data Grid,输入如下数据:
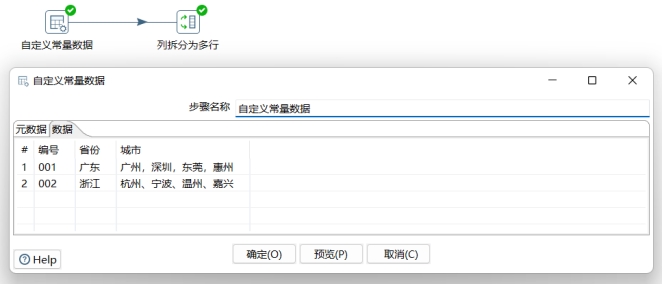
- 新字段设置成“城市NEW”,示例中的数据以“,”分隔,这是一个中文逗号,分隔符可以设置成“,”但是如果既有中文逗号,又有英文逗号, 甚至还有中英文分号,或者顿号,这时怎么办?由于该步骤的分隔符支持正则表达式,不妨将分隔符设成正则形式[,,;;、]
- 预览拆分字段成多行步骤
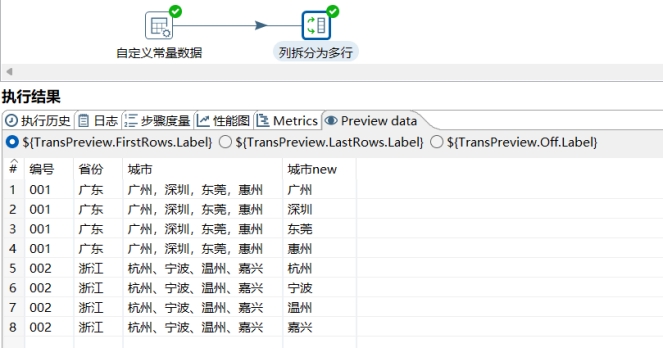
- 点击运行按钮,在弹出的对话框中点击启动按钮。
2.3 实验内容三:掌握基于Kettle的使用参照表集成数据
-
不同系统的很多数据表示都不相同,数据集成时要有统一的表示方式。参照表中可以设置一列标识数据来源系统名的字段——SRC_SYS,但是各个源数据中没有这个标识自己系统名的字段。那么如何处理呢?一种方式是为源数据增加一个记录系统名的字段,只为查询而增加一个字段这一般是不可取的,另一种方式是根据源数据的系统名,过滤参照表。
-
使用参照表集成数据思路:
第一步,一个源数据输入,一个参照数据输入
第二步,过滤参照表,根据源数据的系统名过滤参照数据
第三步,查询过滤后的参照数据,获取性别的统一表示符
最后,预览查询步骤的结果,根据需要自行添加输出
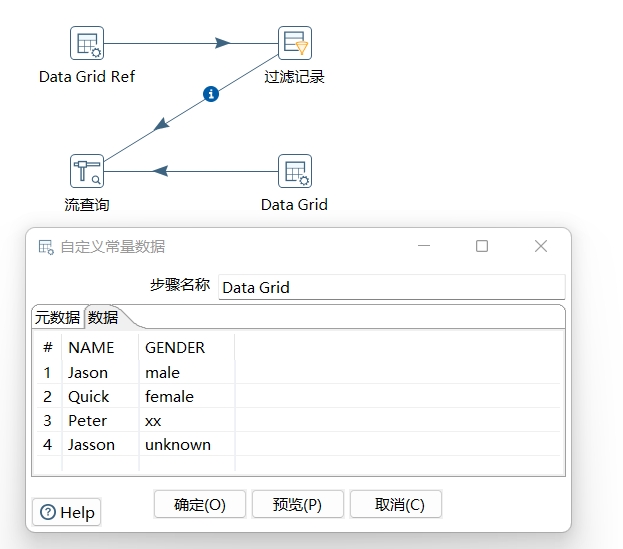
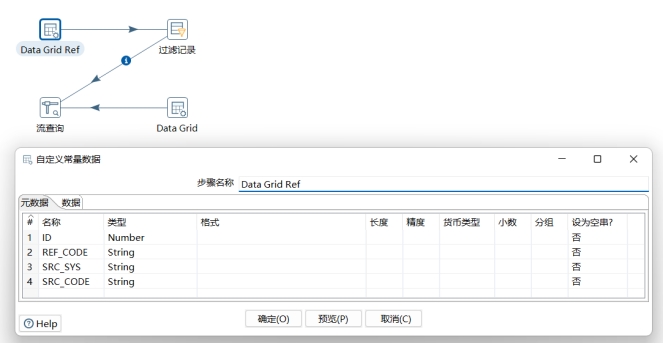
- 第一步,新建转换ref_op_1。创建两个Data Grid,分别命名为“Data Grid”和”Data Grid Ref“:Data Grid:作为源数据,输入示例数据;Data Grid Ref:输入参照数据,如图:
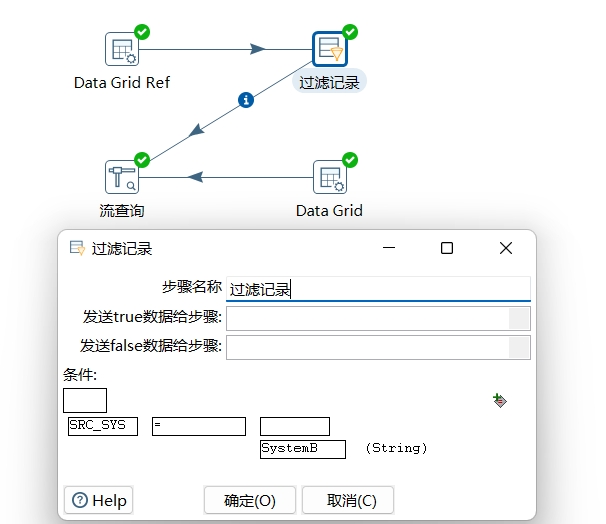
- 第二步,过滤参照表。使用过滤记录(Filter rows)步骤过滤参照表的数据。过滤条件设“SRC_SYS = SystemB”,筛选出SystemB的参照数据
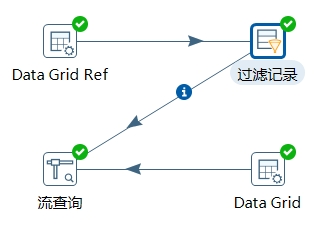
- 第三步,查询参照表。使用流查询(Stream lookup)步骤查询参照表
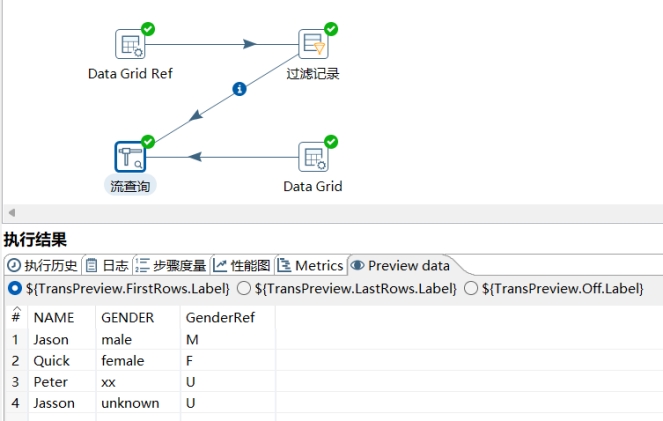
- 最后,预览查询结果:
2.4 实验心得:
本次实验收获很大,掌握了基于Kettle的字符串数据清洗,掌握基于Kettle的字段清洗,掌握基于Kettle的使用参照表清洗。