目录
unittest的大致构成:
Test Fixture
Test Case-测试用例
Test Suite-测试套件
Test Runner
批量执行脚本
makeSuite()
TestLoader
discover()
用例的执行顺序
忽略用例执行
skip
skipIf
skipUnless
断言
HTML测试报告
错误截图
unittest是python中的单元测试框架
大致作用:
- 提供用例的组织与执行-组织大量的测试用例
- 提供丰富的比较方法-断言
- 提供丰富的日志-总执行时间,失败用例数,成功用例数
unittest的大致构成:
Test Fixture
对一个测试用例环境的搭建与销毁,就是一个Test Fixture(设备,固定之物).通过覆盖setUp()和tearDown()方法来实现
setUp()是测试环境的搭建,比如获取待测浏览器的驱动,或者如果测试中需要访问的数据库,可以在setUp()中建立数据库的连接来进行初始化.
tearDown()进行测试环境的销毁,关闭浏览器,关闭数据库等操作
Test Case-测试用例
一个TestCase的实例就是一个测试用例,测试用例就是一个完整的测试流程,包括测试环境的搭建(setUp),实现测试代码的过程,测试环境的销毁,还原(tearDown())
一个测试用例就是一个完整的测试单元
Test Suite-测试套件
将多个测试用例集合在一起
Test Runner
测试的执行,unittest框架中,通过TextTestRunner类提供的run方法执行testCase或testSuite
感受单元测试
from selenium import webdriver
import unittest
import time
from selenium.webdriver.common.by import By
class Baidu2(unittest.TestCase):
def setUp(self): # 测试环境的构建
print("-----setUp-----呜啦啦")
self.driver = webdriver.Edge()
self.driver.implicitly_wait(30)
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self): # 测试环境的销毁
print("-----tearDown-----")
self.driver.quit()
def test_baidu(self): # 脚本1
driver = self.driver
url = self.url
driver.get(url)
driver.find_element(By.ID, "kw").send_keys("我的世界")
driver.find_element(By.ID, "su").submit()
time.sleep(2)
print(driver.title)
# self.assertNotEqual(driver.title, "百度一下_百度搜索", msg="不相等")
# self.assertTrue("beautiful"=="beauty", msg="Not Equal!")
time.sleep(2)
def test_findB(self): # 脚本2
driver = self.driver
url = self.url
driver.get(url)
driver.find_element(By.ID, "kw").send_keys("B站")
driver.find_element(By.ID, "su").submit()
driver.find_element(By.LINK_TEXT, "哔哩哔哩(b站) - 哔哩哔哩 (゜-゜)つロ 干杯~-bi...").click()
time.sleep(2)
print(driver.title)
time.sleep(2)
if __name__ == "__main__":
# unittest提供的全局main()方法,能够使一个单元测试模块轻松的变成可直接运行的测试脚本
# 在main方法中搜索包含在此模块下的,以test命名的测试方法,并执行他们
unittest.main()在Baidu2这个类中,
- setUp + test_baidu + tearDown -> 第1个Test Case
- setUp + test_findB + tearDown -> 第2个Test Case
尝试将代码跑一下,可以发现.在每次执行被测试代码时,setUp与tearDown都会对应的执行一遍.
批量执行脚本
我们把一个web的每个功能模块都分成一个单元测试,那该怎么将每个模块的单元测试一起执行呢.
就要用到我们上面所提到的Test Suite(测试套件),其是一个集合,集合里装载着Test Case(测试用例)
使用测试套件的大致流程为:
- 创建一个测试套件 suite = unittest,TestSuite() #创建一个实例
- 把多个测试用例放入测试套件中 suite.addTest() #添加测试方法
- 执行测试套件 TextTestRunner的run方法启动suite
其中步骤2的addTest一次只能添加一个测试方法
下面介绍批量执行脚本的三种方式
makeSuite()
由unittest框架中提供的makeSuite()方法,能够把测试用例类内的所有测试用例组成一个TestSuite(测试套件),在使用此方法的时候只要把测试类名传入即可.
def createSuite1(): # makeSuite
suite1 = unittest.TestSuite() # 创建一个测试套件
# 将MyUnitTest01中的Baidu1类中所有的test方法集合成Suite
# 再将集合成的Suite通过addTest方法添加到我们所创建的Suite实例suite1中
suite1.addTest(unittest.makeSuite(case.MyUnitTest01.Baidu1))
suite1.addTest(unittest.makeSuite(case.MyUnitTest02.Baidu2))
return suite1
if __name__ == "__main__":
suite = createSuite0()
# verbosity表示测试结果的信息复杂度,有0,1,2三个级别,复杂度随级别递增
runner = unittest.TextTestRunner(verbosity=2) # 创建TextTestRunner实例
runner.run(suite)TestLoader
使用TestLoader,测试加载器将测试用例批量的加载到测试套件中
需要用到TestLoader的实例方法:loadTestsFromCase
def createSuite2():
# 使用TestLoader加载器的实例方法,加载Baidu1类中的测试方法以suite类型返回
a = unittest.TestLoader().loadTestsFromTestCase(case.MyUnitTest01.Baidu1)
b = unittest.TestLoader().loadTestsFromTestCase(case.MyUnitTest02.Baidu2)
# 将加载好的两个suite整合一下
thesuite = unittest.TestSuite([a, b])
return thesuitediscover()
上面的两种方式都要提前把类给导入
使用discover就不用添加类了,可以直接根据路径来匹配相应的文件
def createSuite3():
# 根据所给出的路径,找到匹配正则表达式的文件中的test方法,并将找到的所有test方法以suite的形式返回
# top_leve_dir一般设置None,默认值即可
discover = unittest.defaultTestLoader.discover('./case', pattern='MyUnit*.py', top_level_dir=None)
print(discover)
return discover用例的执行顺序
在unittest框架中默认加载测试用例的顺序是根据ASCII码的顺序
在一个模块中,命为TestA的方法会比TestB的方法优先执行.
而在suite中,会根据addTest()添加的顺序来执行
suite1中含有:
- testB
- testA
suite2中含有:
- test9
- test2
------------------------------
suite.addTest(suite2)
suite.addTest(suite1)
------------------------------
则最终的执行顺序为:
test2->test9->testA->testB
忽略用例执行
在unittest中想要把test方法进行跳过,可以使用unittest提供的skip标签
这里介绍三个标签:
- skip([原因])-无条件跳过标签
- skipIf([条件,原因])-有条件跳过标签
- skipUnless([条件,原因])-有条件跳过标签
skip
@unittest.skip("暂时跳过此方法")
def test_hao(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element(By.LINK_TEXT, "hao123").click()
time.sleep(2)skipIf
比skip多了一个参数,布尔值.
如果为true,则跳过
@unittest.skipIf(2 < 1, "满足条件")
def test_hao(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element(By.LINK_TEXT, "hao123").click()
time.sleep(2)skipUnless
与skipIf差不多,但与其相反
如果为false,则跳过
这里就不举例介绍啦~
断言
unittest框架的目的是对代码进行测试,查看结果是否符合我们的预期.
断言就起到了前面后半句的作用,查看结果是否符合我们的期望.
unittest中:
- 如果某一个case的断言不符合预期测试就会立即停止当前正在执行的case并生成错误信息(并不会影响其他case执行),
- 如果断言通过则继续执行下一个case
在unittest的单元测试库中提供了许多断言的方法,下面是一些常用的方法.
| 序 号 | 断言方法 | 断言描述 |
| 1 | assertEqual(arg1, arg2, msg=None) | 验证arg1=arg2,不等则fail |
| 2 | assertNotEqual(arg1, arg2, msg=None) | 验证arg1 != arg2, 相等则fail |
| 3 | assertTrue(expr, msg=None) | 验证expr是true,如果为false,则fail |
| 4 | assertFalse(expr,msg=None) | 验证expr是false,如果为true,则fail |
| 5 | assertIs(arg1, arg2, msg=None) | 验证arg1、arg2是同一个对象,不是则fail |
| 6 | assertIsNot(arg1, arg2, msg=None) | 验证arg1、arg2不是同一个对象,是则fail |
| 7 | assertIsNone(expr, msg=None) | 验证expr是None,不是则fail |
| 8 | assertIsNotNone(expr, msg=None) | 验证expr不是None,是则fail |
| 9 | assertIn(arg1, arg2, msg=None) | 验证arg1是arg2的子串,不是则fail |
| 10 | assertNotIn(arg1, arg2, msg=None) | 断言描述验证arg1不是arg2的子串,是则fail |
| 11 | assertIsInstance(obj, cls, msg=None) | 验证obj是cls的实例,不是则fail |
| 12 | assertNotIsInstance(obj, cls,msg=None) | 验证obj不是cls的实例,是则fail |
msg是自己定义给断言如果发生错误显示的信息
HTML测试报告
下载HTMLTestRunner.py,并将其扔到python的lib当中
import unittest
import HTMLTestRunner
import time
import os,sysif __name__ == "__main__":
curpath = sys.path[0] # 获取当前的根目录
print(curpath)
# 取当前时间
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
# 查看是否有文件夹/resultreport,如果没有则创建
if not os.path.exists(curpath + '/resultreport'):
os.makedirs(curpath + '/resultreport')
# 创建报告文件的名称: 根目录+resultreport(报告文件夹)+时间+html格式文件
filename = curpath + '/resultreport/' + now + 'resultreport.html'
# 写入创建的html文件中
# 打开文件,模式为二进制写wb,文件变量名为fp
with open(filename, 'wb') as fp:
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u'测试报告',description=u'用例执行情况',verbosity=2)
suite = createSuite1()
# verbosity表示测试结果的信息复杂度,有0,1,2三个级别,复杂度随级别递增
runner.run(suite)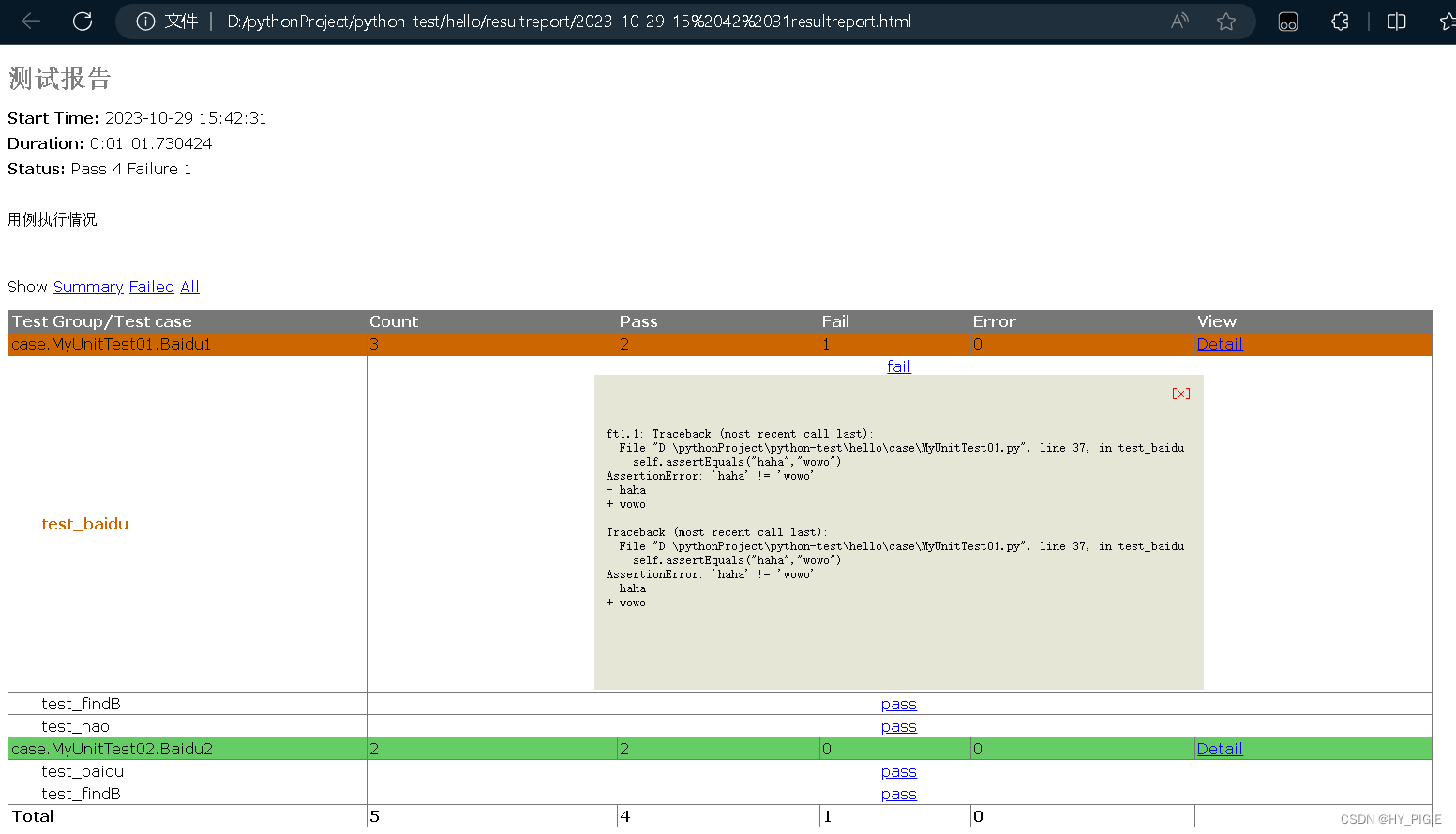
错误截图
在断言没通过的时候,我们可以设置自动截图来查看当时的web情况如何,这样就能方便我们对测试用例的观察
def savescreenshot(driver, file_name):
if not os.path.exists('./image'):
os.makedirs('./image')
cur = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
# 截图保存
driver.get_screenshot_as_file('./image/'+cur+'-'+file_name)
time.sleep(1)def test_baidu(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element(By.ID, "kw").send_keys("蜡笔小新")
driver.find_element(By.ID, "su").submit()
time.sleep(2)
try:
self.assertEquals("haha", "wowo")
except:
savescreenshot(driver, 'wow.png')
time.sleep(2)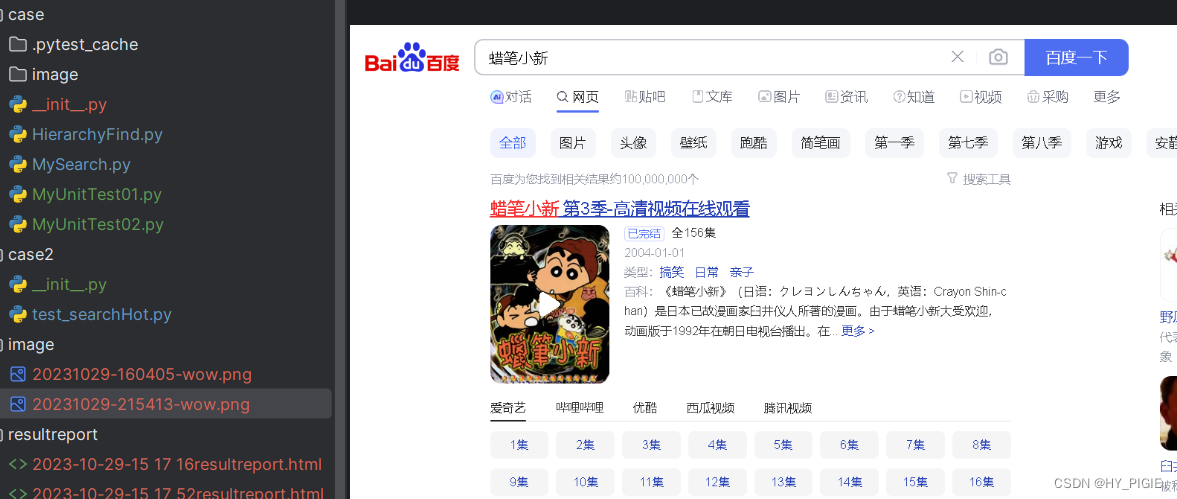










![[java/力扣110]平衡二叉树——优化前后的两种方法](https://img-blog.csdnimg.cn/ac5f043c9c894051bb5062d8f5c8ee8d.png)