前言
- 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。
- 此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术有限,最终数据清洗结果不够理想,相关CSDN文章便没有发出。
- 从这篇文章开始,这里我将按章节顺序,围绕考研真题展开计算机组成原理总共7章的知识,边学习边整理数据。
请注意,本文中的部分内容来自网络搜集和个人实践,如有任何错误,请随时向我们提出批评和指正。本文仅供学习和交流使用,不涉及任何商业目的。如果因本文内容引发版权或侵权问题,请通过私信告知我们,我们将立即予以删除。
文章目录
- 前言
- 操作系统的定义
- 操作系统功能
- 管理硬件(前五块也就是操作系统的所有内容)
- 知识回顾思维导图
- 特征
- 操作系统的特征思维导图
- 操作系统的启动
- 哈工大版本
- 王道版本
- 操作系统的运行环境(王道)
- 预备知识:程序是如何运行的?
- 内核程序v.s.应用程序
- 特权指令v.s.非特权指令
- CPU的状态
- 操作系统的运行机制思维导图
- 中断与异常
- 中断的作用
- 中断的分类
- 中断和异常思维导图
- 系统调用(广义指令)
- 系统调用与库函数的区别
- 什么功能要用到系统调用?
- 系统调用的过程
- 系统调用思维导图
- 操作系统历史
- 哈工大分两条线讲
- 王道版本
- 操作系统(OS)发展阶段
- OS的发展与分类思维导图
- 操作系统体系结构(新考点)
- 操作系统的内核
- 分层结构
- 模块化
- 宏内核(大内核)
- 微内核
- 外核
- 虚拟机(新考点)
- 第一类VMM
- 第二类VMM
- 考研真题
- 408 - 2023
- 12. 计算程序执行速度和用户CPU时间
- 408 - 2022
- 12. 计算平均CPI和CPU执行时间
- 20. 高级语言程序转换为可执行目标文件的过程
- 408 - 2021
- 12. 计算机浮点运算速度与操作次数的关系
- 未完待续,逐张试卷整理中,会一直更新到2009
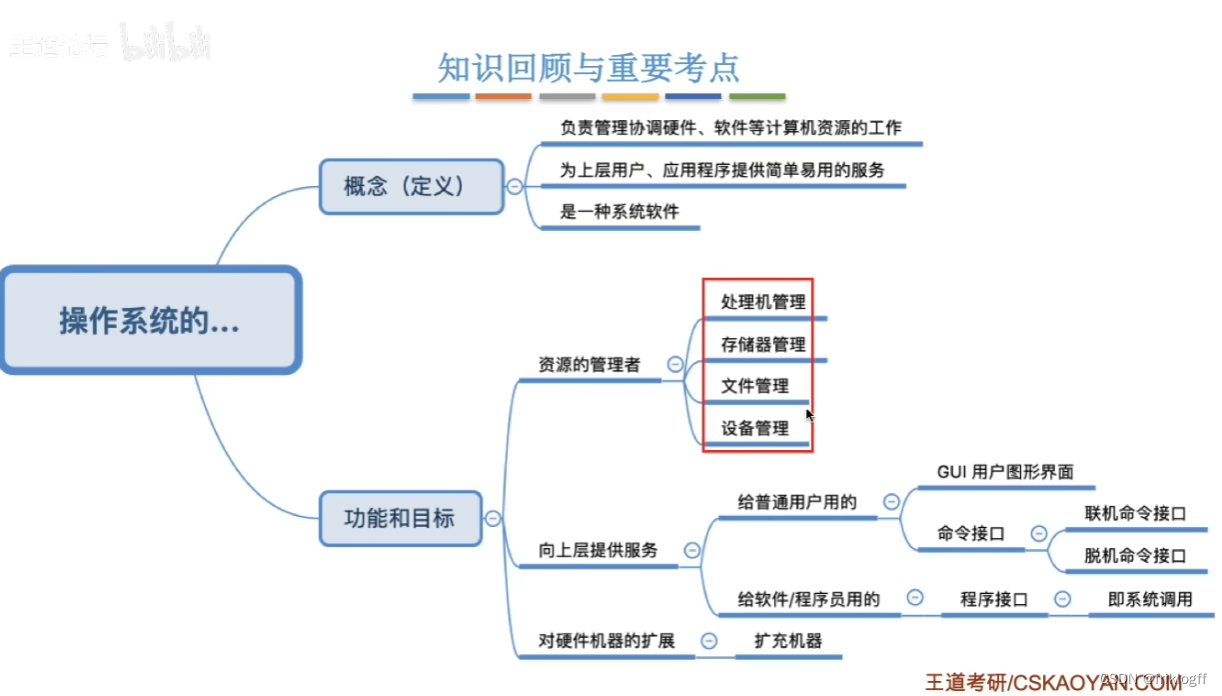
操作系统的定义
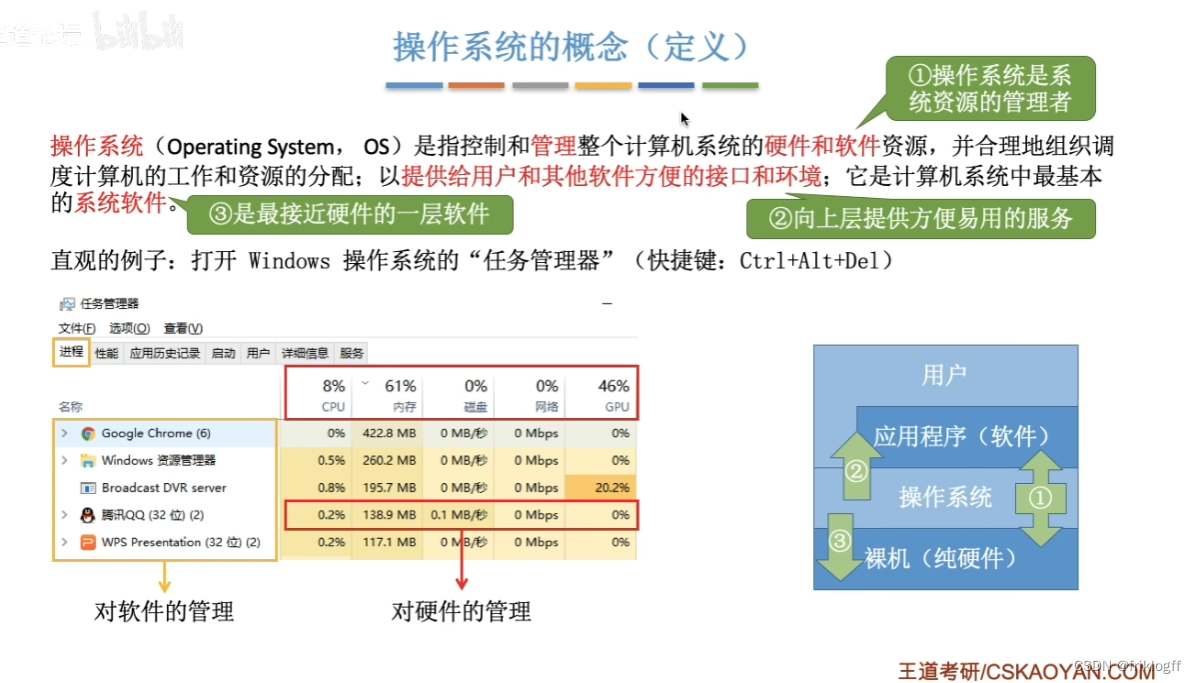
操作系统功能
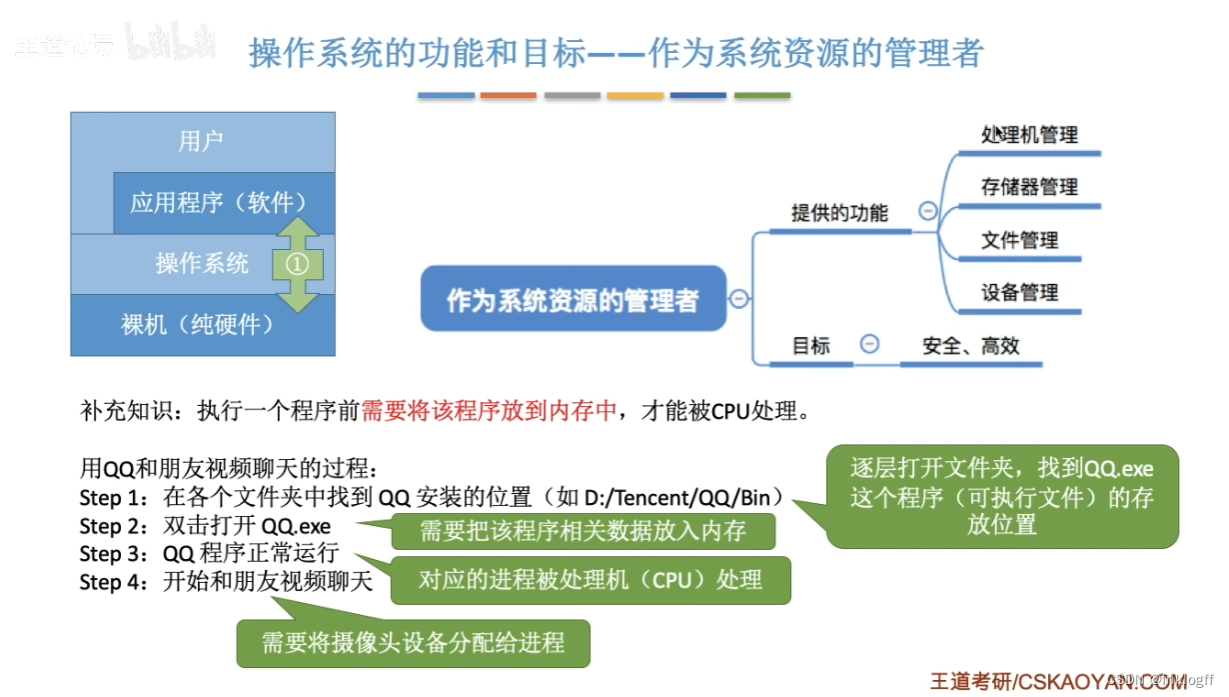
管理硬件(前五块也就是操作系统的所有内容)
-
CPU管理
-
内存管理
-
I/O(终端)管理
-
磁盘管理
-
文件管理
-
网络管理、电源管理、多核管理(不讲,课程高级操作系统讲解)
多进程视图:- CPU管理- 内存管理
文件操作视图:- I/O(终端)管理- 磁盘管理- 文件管理

知识回顾思维导图
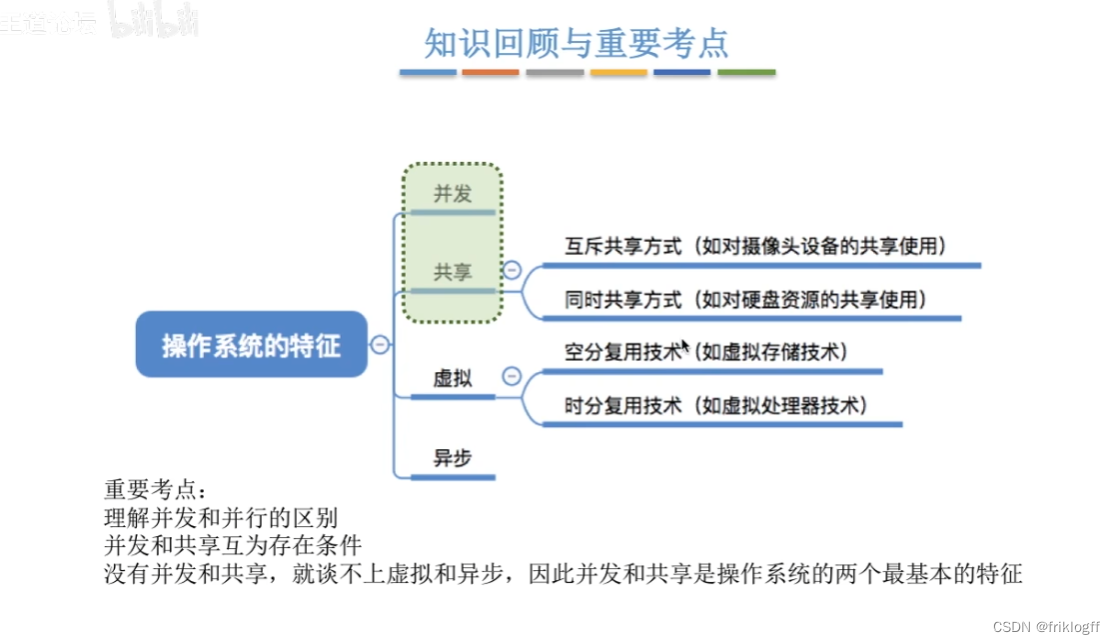
特征
-
并发
-
并发(进程)
- 多道程序环境,宏观上多道程序同时执行,每个时刻单处理机仅有一道程序执行,微观上程序分时交替执行
-
并行
- 同一时刻完成两种或两种以上工作,需要硬件支持
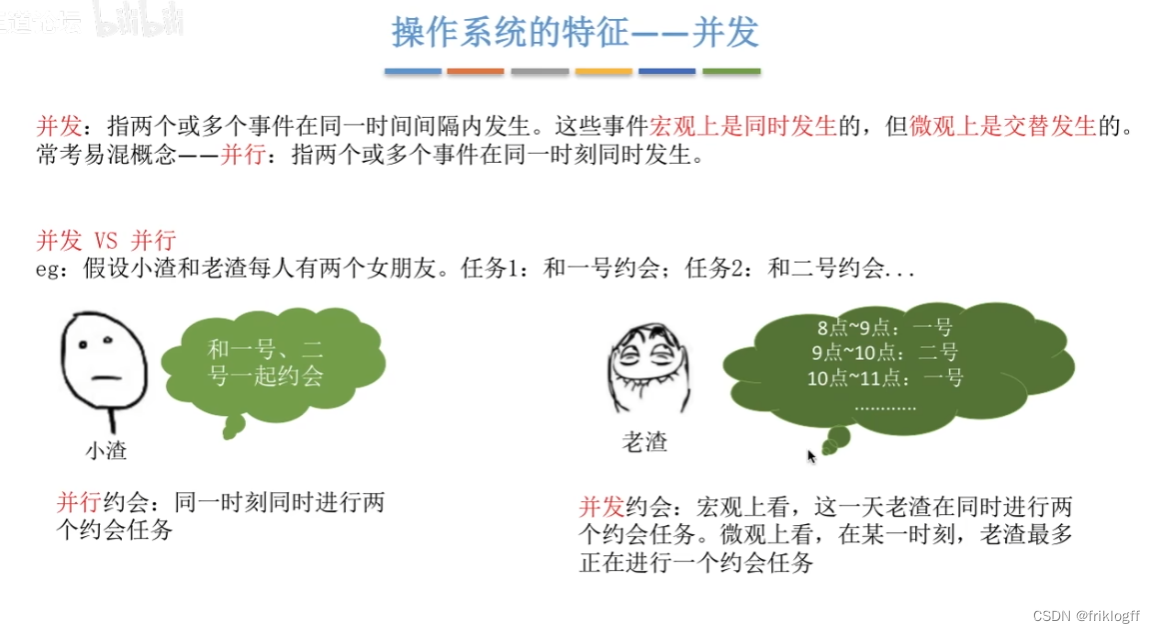

- 同一时刻完成两种或两种以上工作,需要硬件支持
-
-
共享
-
互斥共享方式
- 某些资源在一段时间内只允许一个进程访问该资源
-
同时访问方式
- 一段时间内允许多个进程对资源进行访问,分时共享
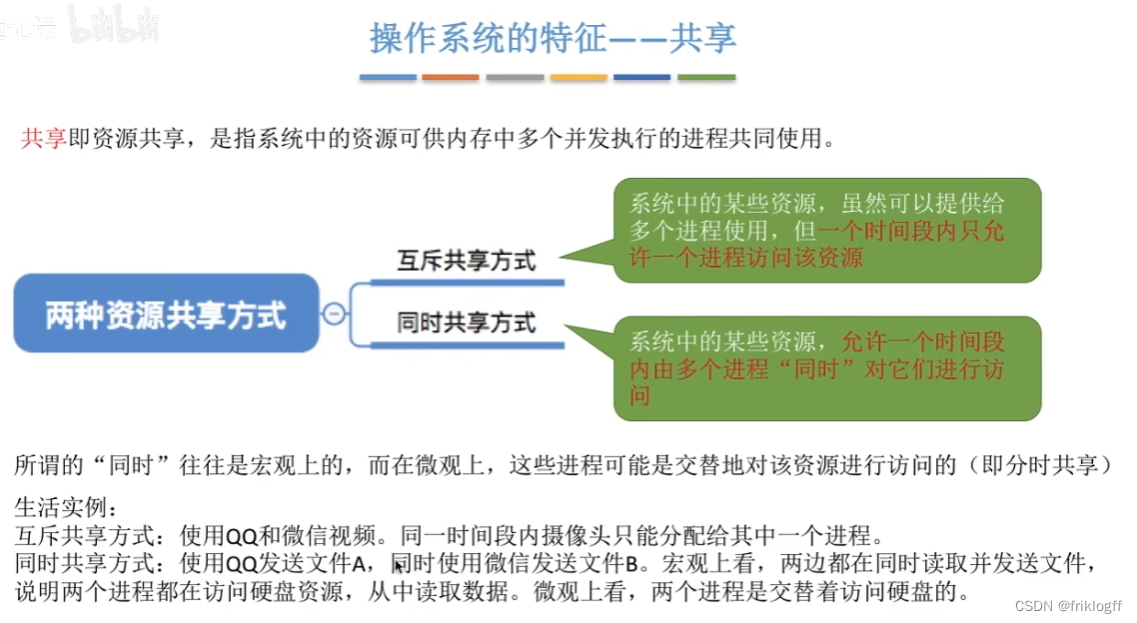
- 一段时间内允许多个进程对资源进行访问,分时共享
-
-
并发和共享的关系
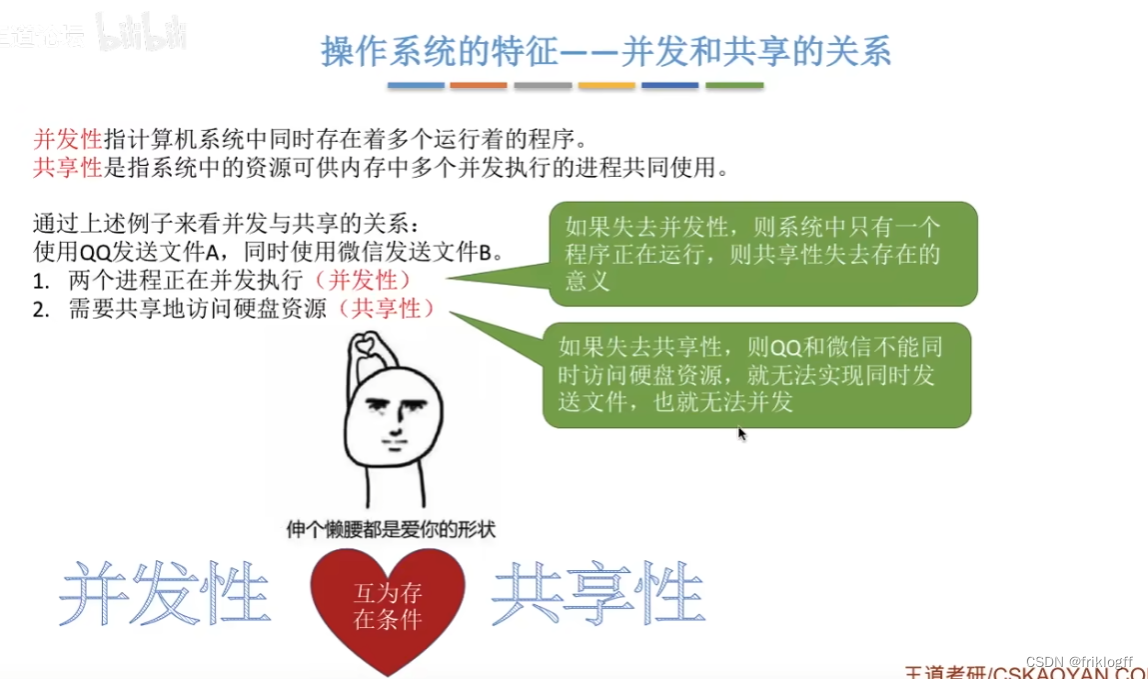
-
虚拟
-
一个物理上的实体变为若干逻辑上的对应物
-
时分复用技术
-
空分复用技术
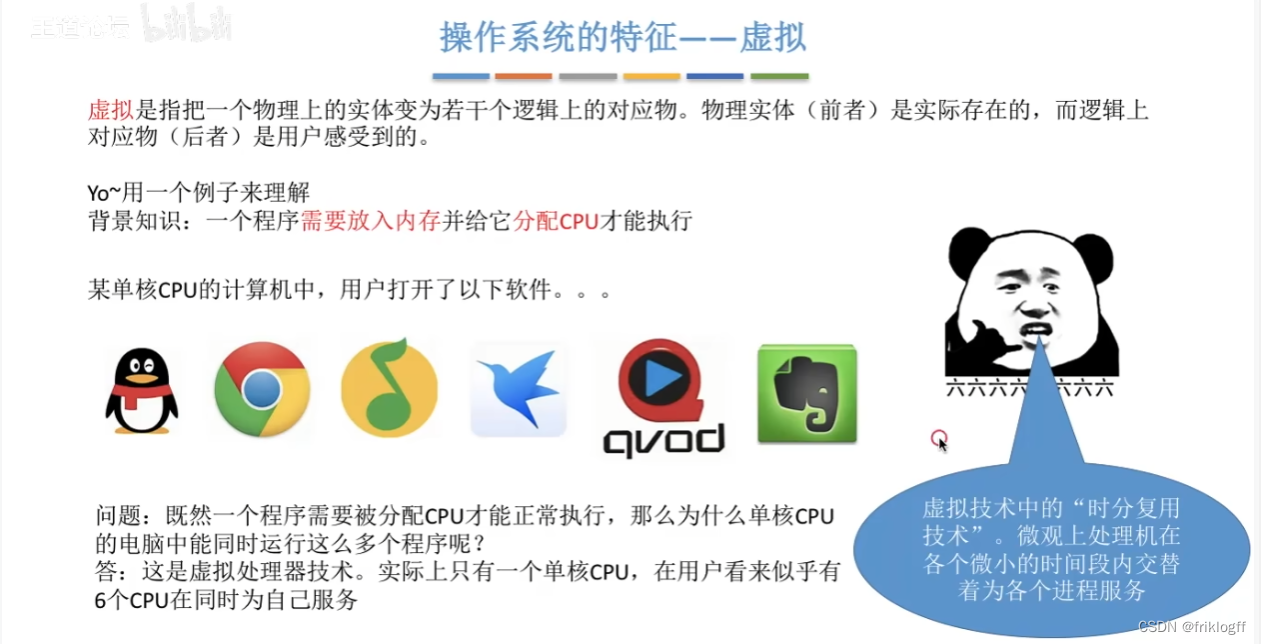
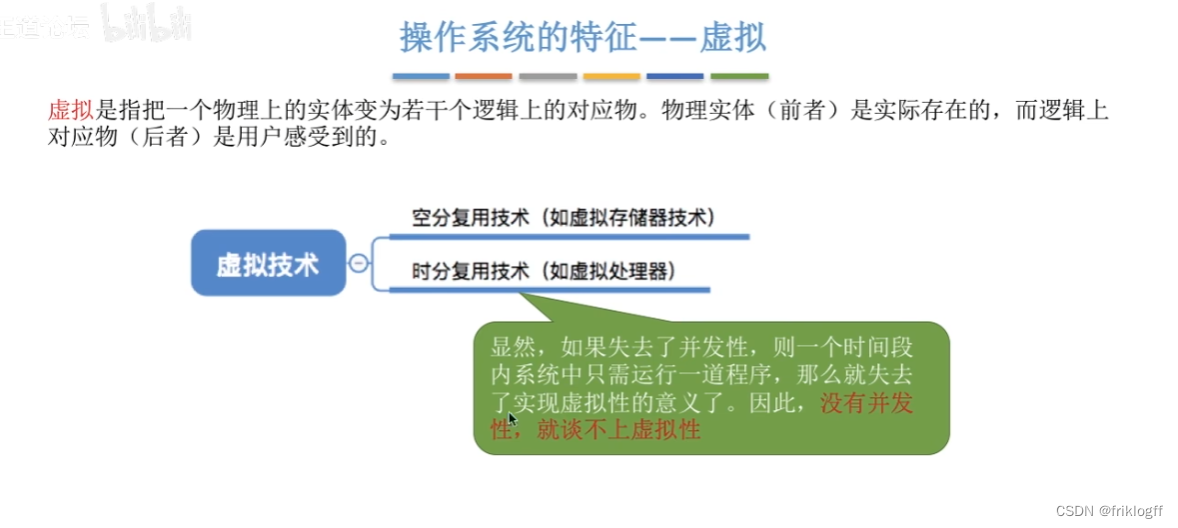
-
-
-
异步
- 由于资源有限,进程的执行不是一贯到底,走走停停,以不可预知的速度前进

- 由于资源有限,进程的执行不是一贯到底,走走停停,以不可预知的速度前进
并发和共享互为存在条件(最基本特征)
操作系统的特征思维导图
操作系统的启动
哈工大版本
-

-
x86 PC为例
-
BIOS映射区:固化在主存ROM中,用于检查RAM、键盘、显示器、软硬磁盘等,并将磁盘第一个扇区读入主存
-
引导扇区代码(bootsect.s一段汇编代码):将操作系统读入内存,转入setup.s执行
- 补充:该程序的主要作用是首先把从磁盘第2个扇区开始的4个扇区的setup模块加载到内存紧接着bootsect后面位置((0x90200)),再把磁盘上setup模块后面的system模块加载到内存0x10000开始的地方
-
setup模块(setup.s汇编代码执行)
-
读硬件参数存储到内存数据结构中,初始化gdt表
-
gdt表(全局描述表):保护模式下,以数组的形式存储全局的段的描述符
-
idt表(中断描述符表):记录了中断号和调用函数之间的关系
-
-
system模块移动到物理内存起始位置处(0x0000),启动保护模式,转跳到0x0000处
-
-
system模块
-
head.s:初始化一些gdt表、idt表、页表
-
main.c:一堆初始化函数
-
-
王道版本
-
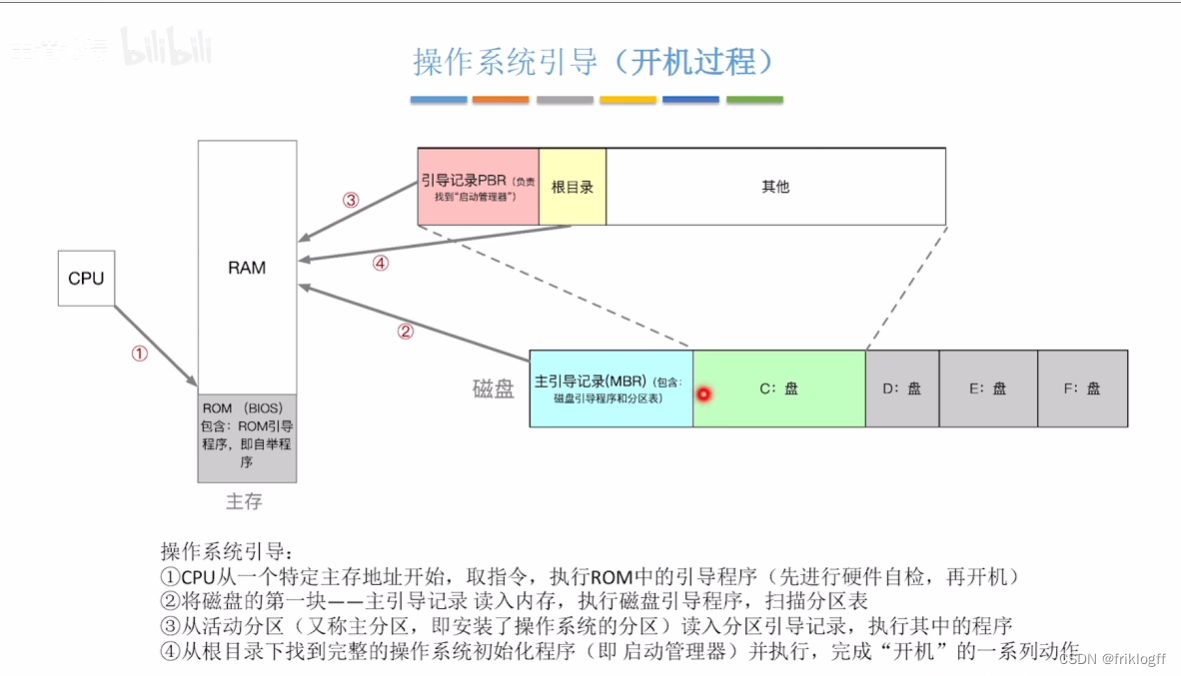
-
CPU执行ROM中引导程序(硬件自检,再开机)
-
磁盘第一块------主引导记录读入内存,执行磁盘引导程序,扫描分区表
-
以活动分区读入分区引导记录,并执行
-
以根目录下找到完整操作系统初始化程序(启动管理器)并执行、开机
-
操作系统的运行环境(王道)
预备知识:程序是如何运行的?
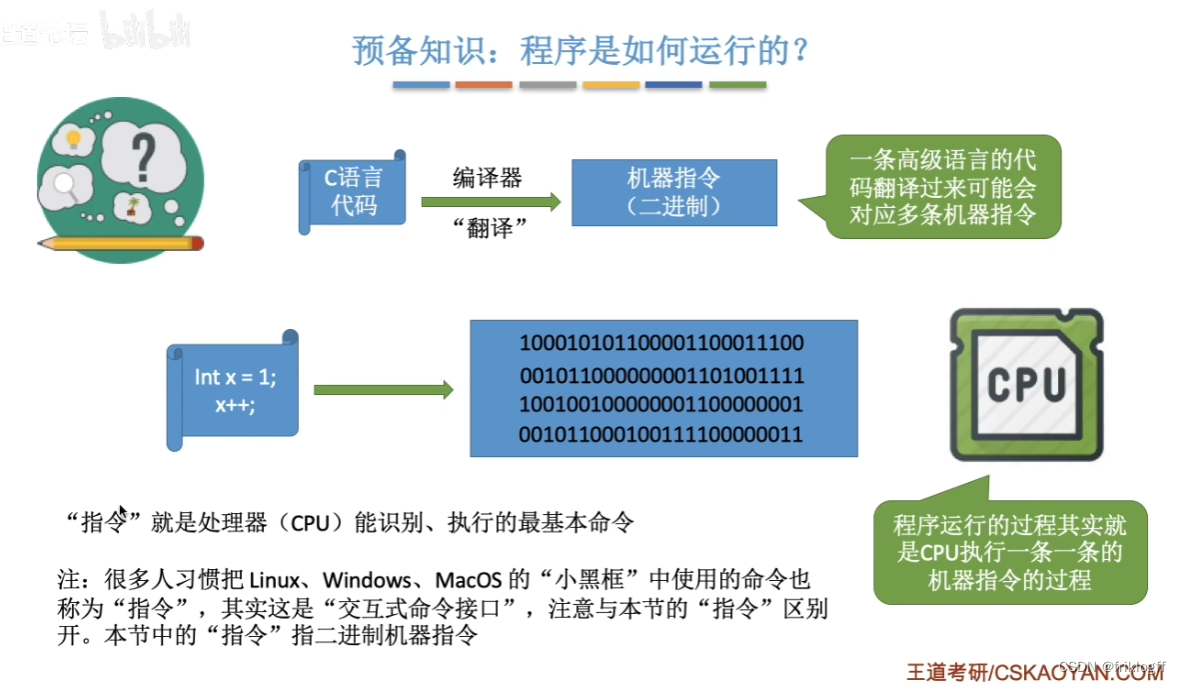
内核程序v.s.应用程序
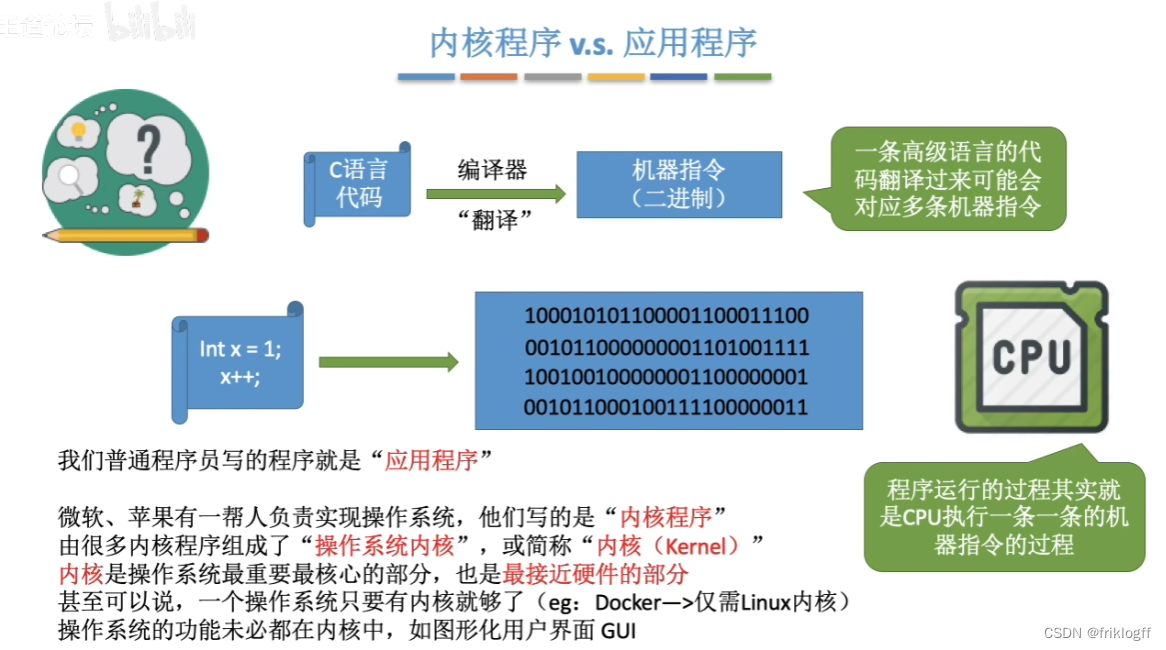
特权指令v.s.非特权指令
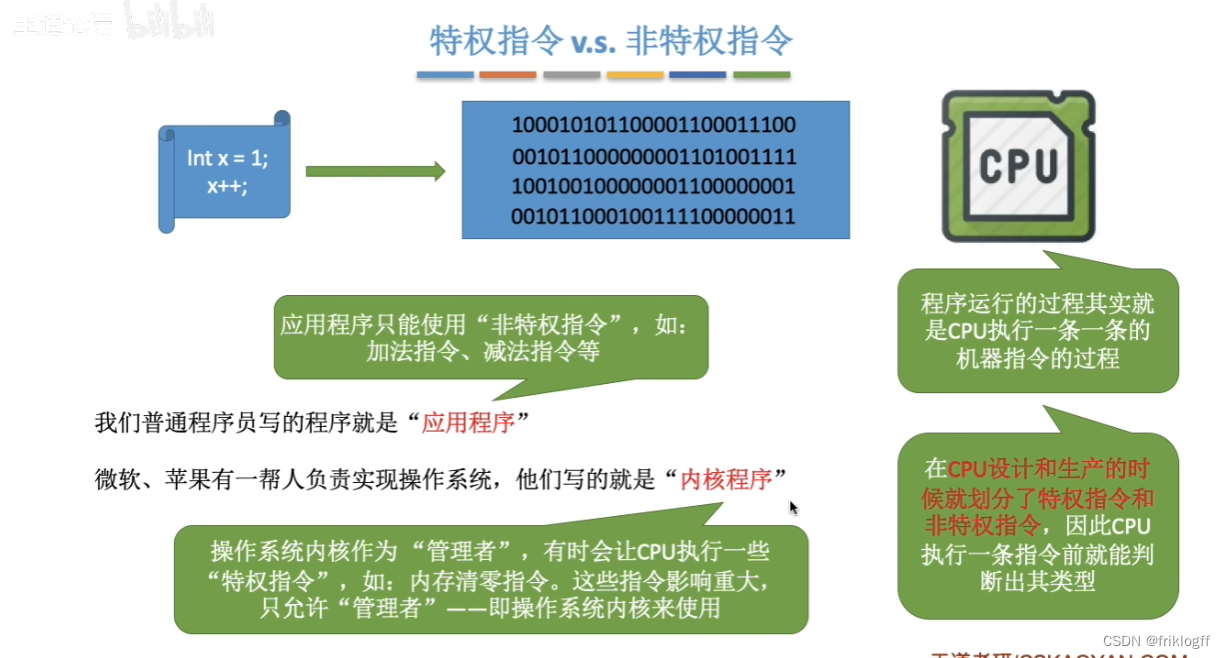
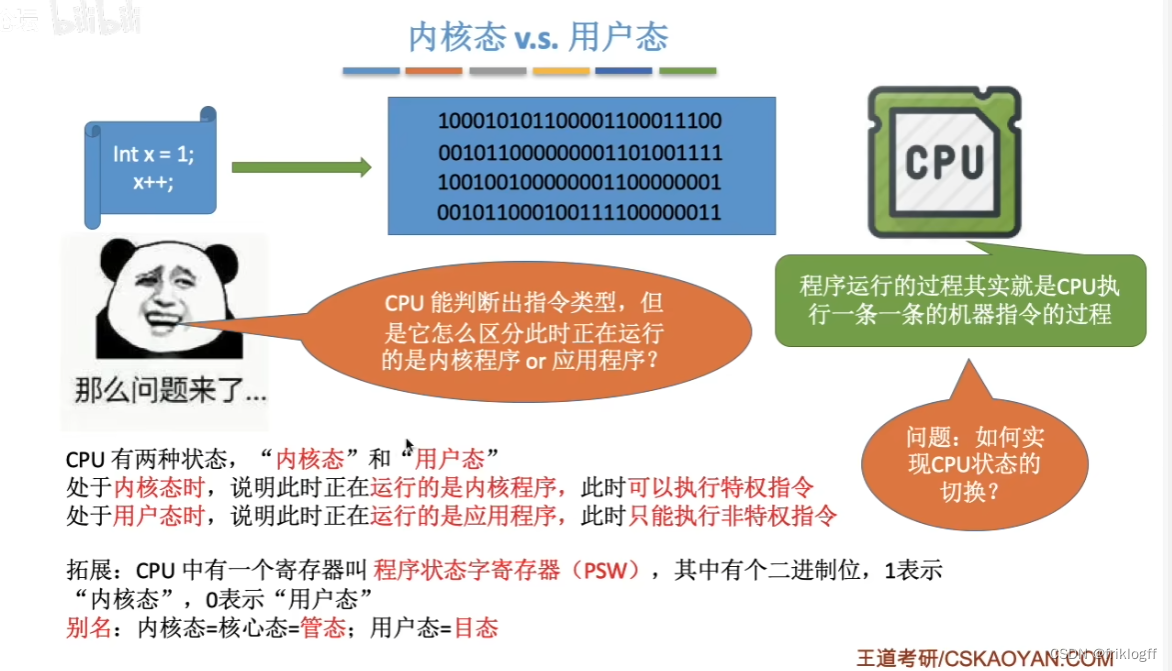
CPU的状态
-
-
内核态(管态/核心态):CPU可以执行特权指令,操作系统内核程序运行在核心态
-
用户态(目态):CPU只能执行非特权指令
-
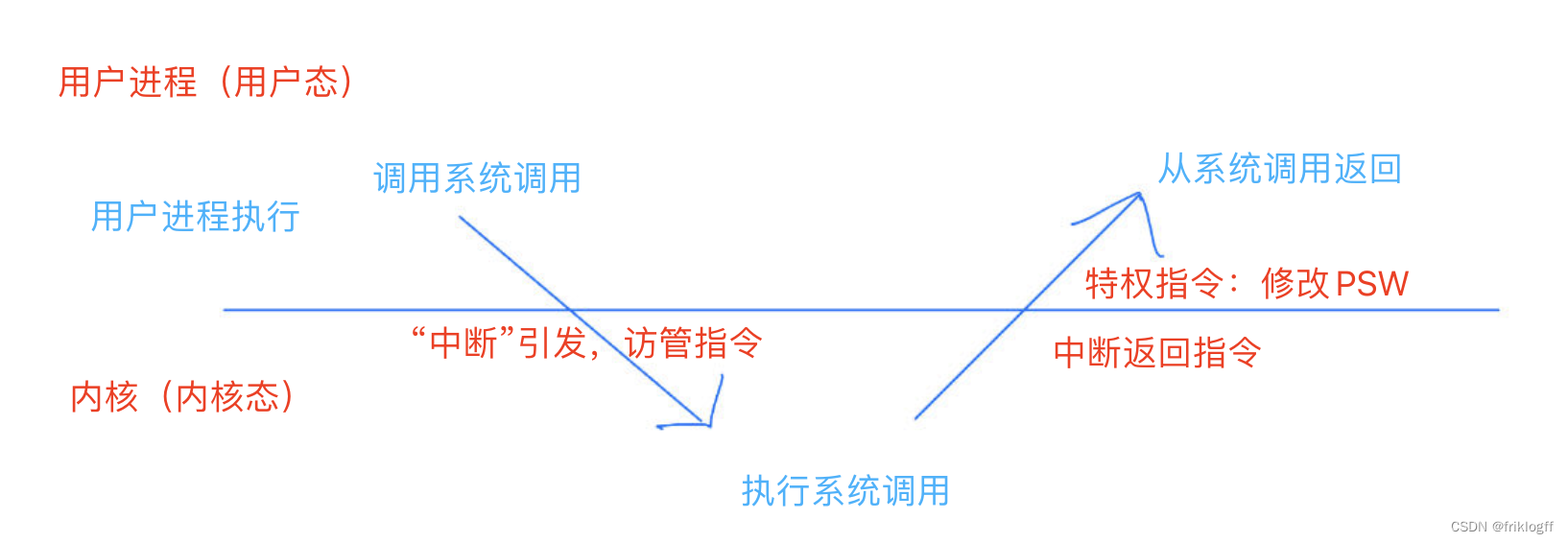
内核态->用户态
- 执行一条特权指令,修改PSW中“用户态”,操作系统主动让出CPU使用权
-
用户态->内核态
- 由“中断”引发(内中断、陷入指令、访管指令、Trap指令),硬件完成,操作系统强行夺回CPU使用权
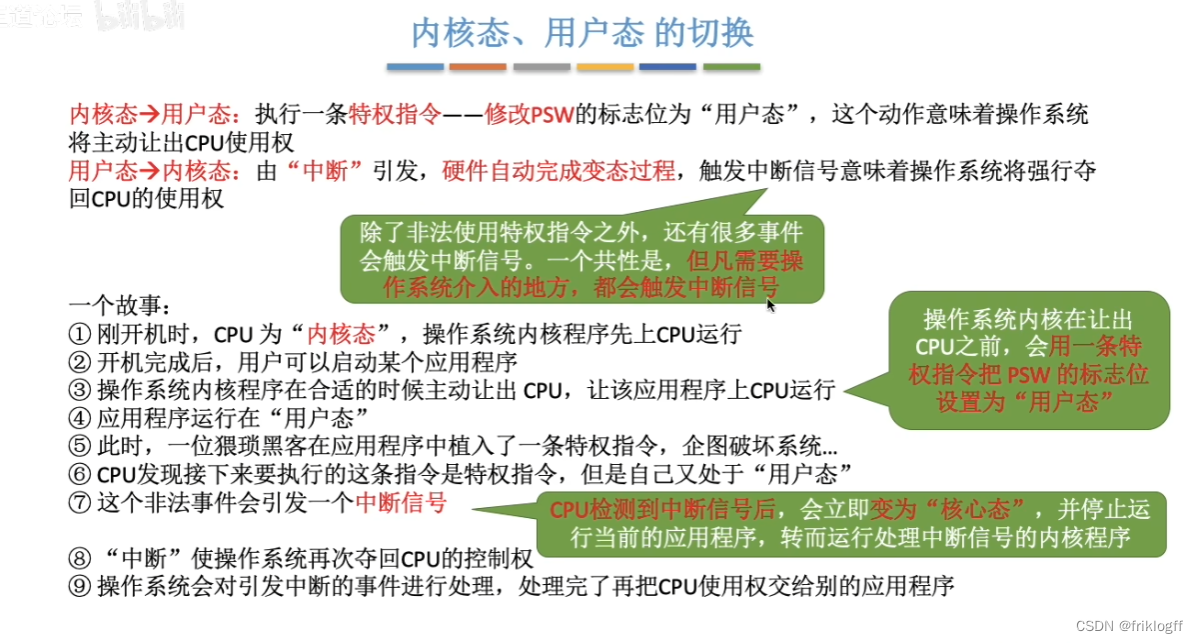
- 由“中断”引发(内中断、陷入指令、访管指令、Trap指令),硬件完成,操作系统强行夺回CPU使用权
-
操作系统的运行机制思维导图

中断与异常
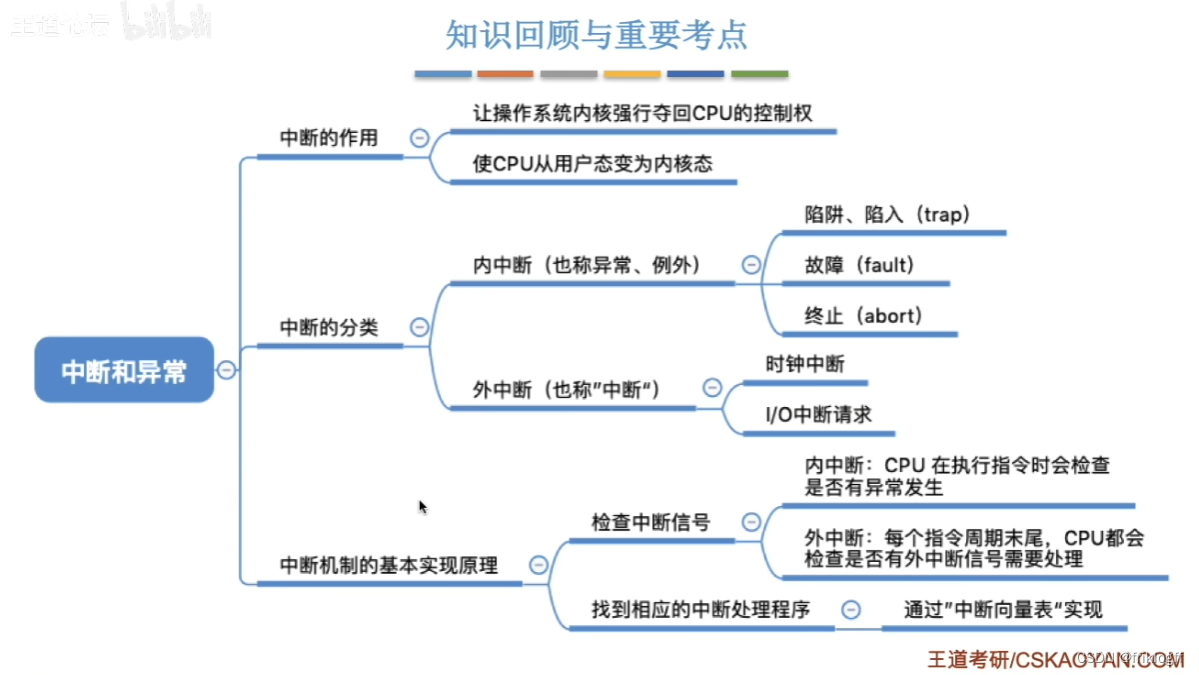
中断的作用

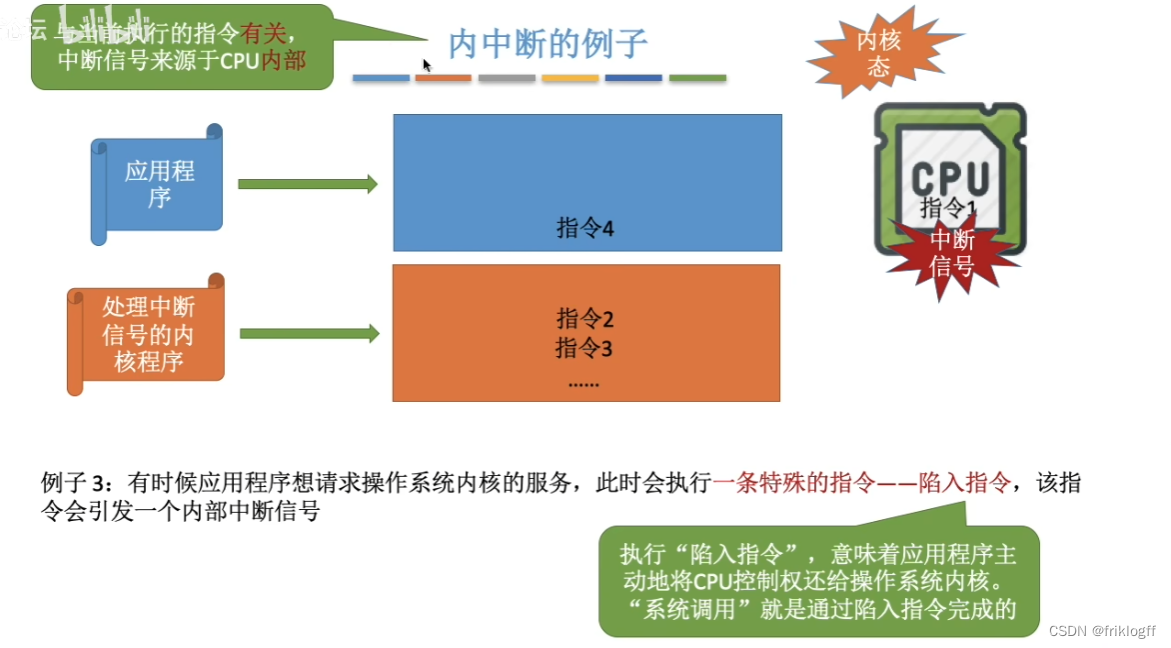
中断的分类
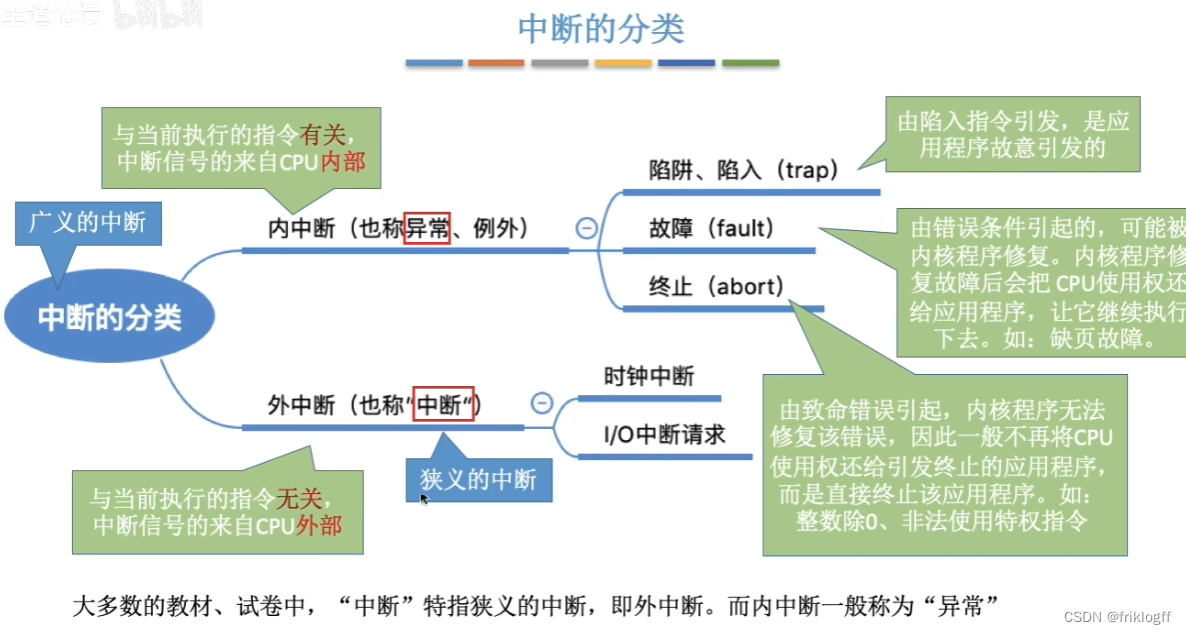
-
异常(内中断)
- 例外、陷入、访管、Trap指令,硬件故障,软件中断
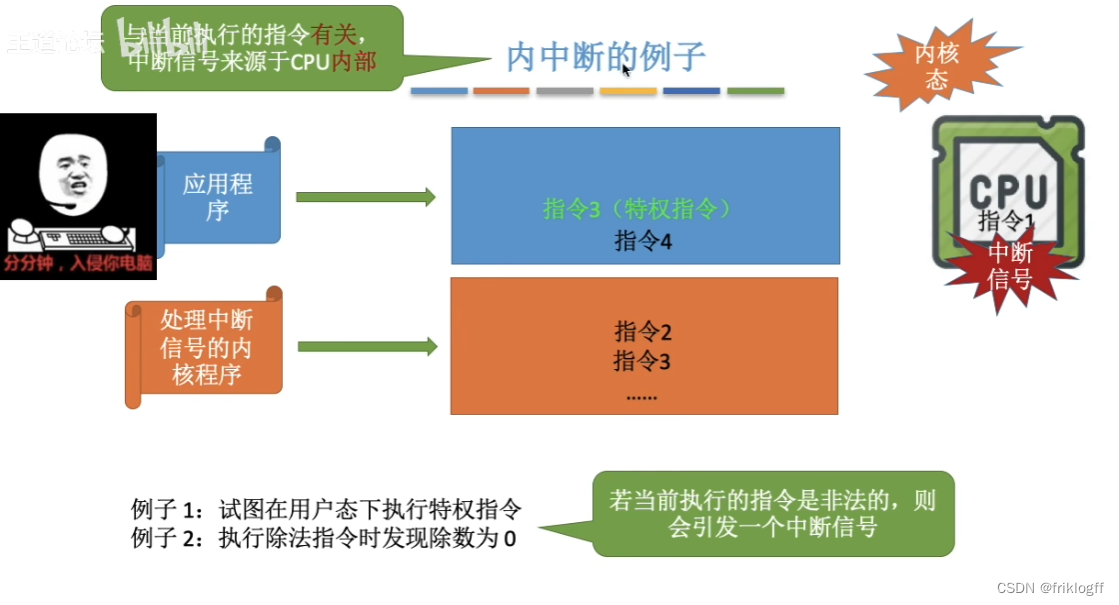
-
中断(外中断)
- 来自CPU执行指令之外的事件发生导致中断(外设请求、人为干预)
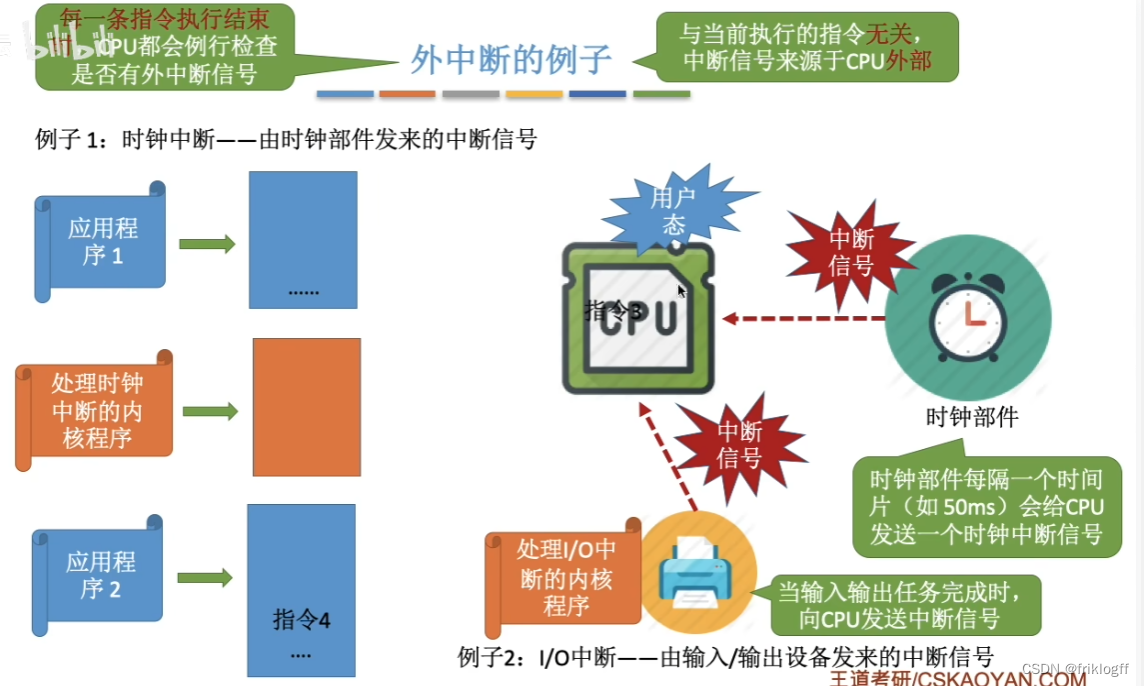
- 来自CPU执行指令之外的事件发生导致中断(外设请求、人为干预)
-
中断处理过程
-
中断隐指令(硬件完成)
-
关中断
-
保存断点
-
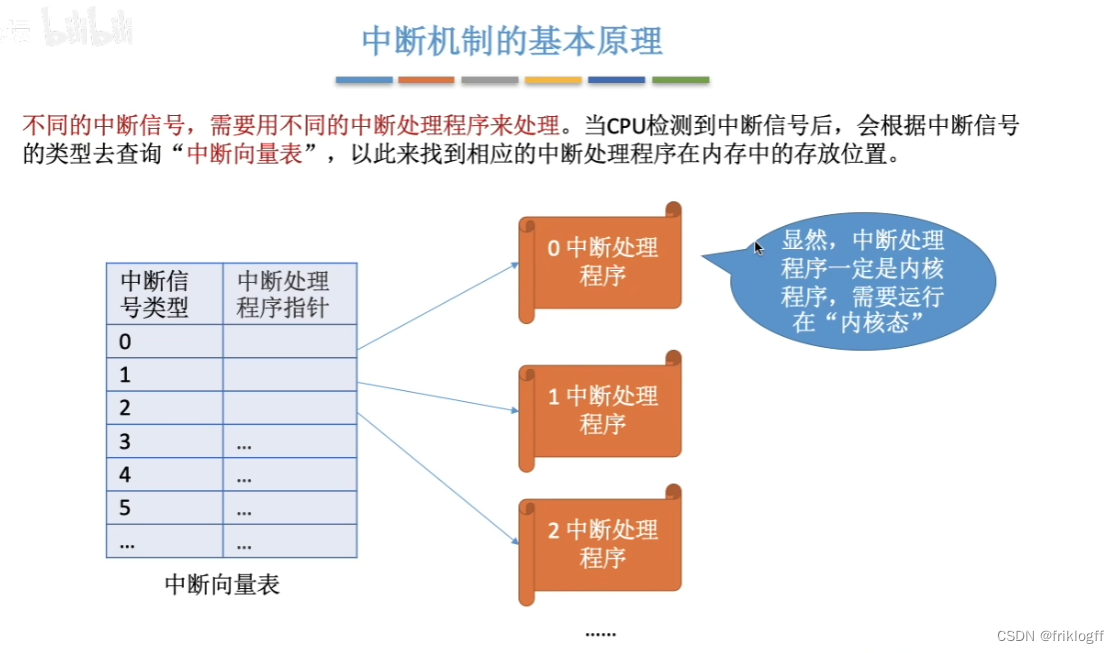
中断服务程序寻址
-
-
中断服务程序(软件实现)
-
保存现场和屏蔽字
-
开中断
-
执行中断服务程序
-
关中断
-
恢复现场和屏蔽字
-
开中断
-
中断返回
-
-
中断和异常思维导图
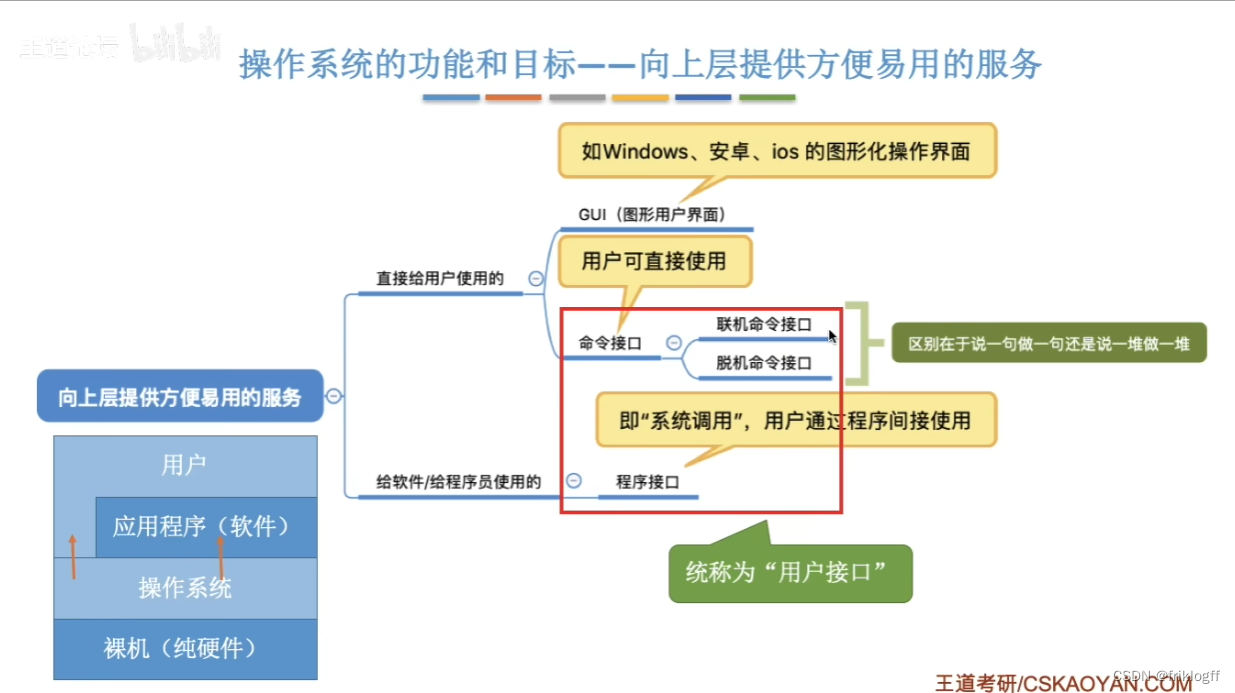
系统调用(广义指令)
-
操作系统接口(哈工大)
-
三种用户使用方式(上层提供服务)
-
都是通过c语言调用一些操作系统提供的重要函数实现,重要函数即操作系统接口,表现为函数调用,因为由系统提供,称为系统调用
-
命令行:本质是系统初始化完,最后执行的一段死循环等待用户输入的程序
-
图形按钮:基于消息机制
- 消息机制:操作系统实现一个消息队列,应用程序循环调用一个函数,从操作系统将消息拿出来,每取出一个就会调用对应的消息处理函数
-
应用程序
-
-
-
POSIX:IEEE制定的一个标准族
- 统一不同操作系统的系统调用接口:fork、open、EACCES等
-
系统调用的实现
-
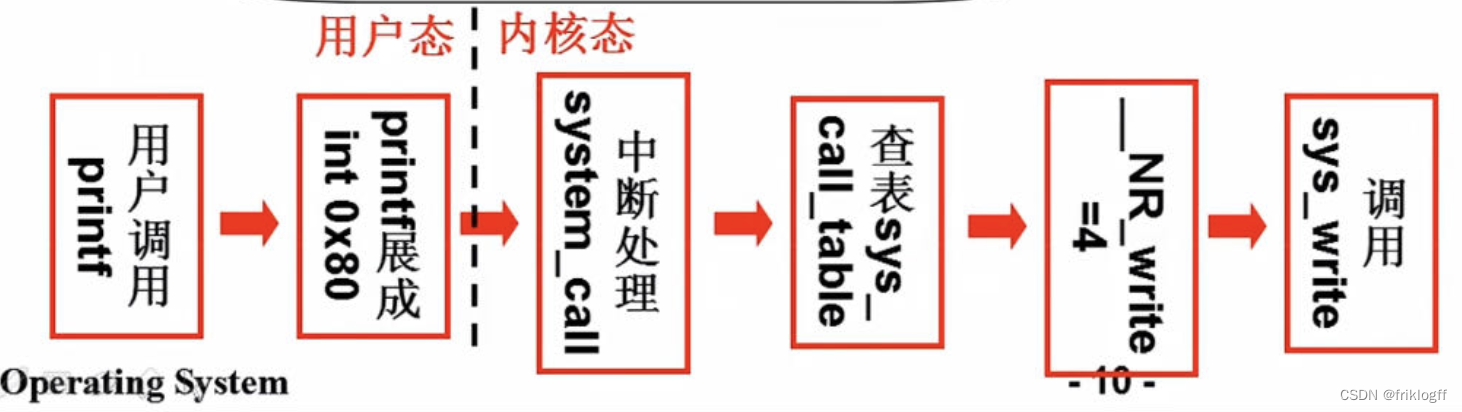
- 用户调用printf,通过库函数变成int 0x80代码,系统在初始化时将int 0x80代码做成一个system call进入内核态,system call中断处理调用system call table去查表,根据传递的系统调用号,最后调用sys_write
-
-
-
系统调用概念
- 用户在程序中调用操作系统子功能,可视为特殊的公共子程序
-
系统调用过程
-
传递系统调用参数
-
执行陷入指令(访管指令/trap指令)主动引发一个内中断
-
执行服务程序
-
返回用户态
-
系统调用与库函数的区别

什么功能要用到系统调用?
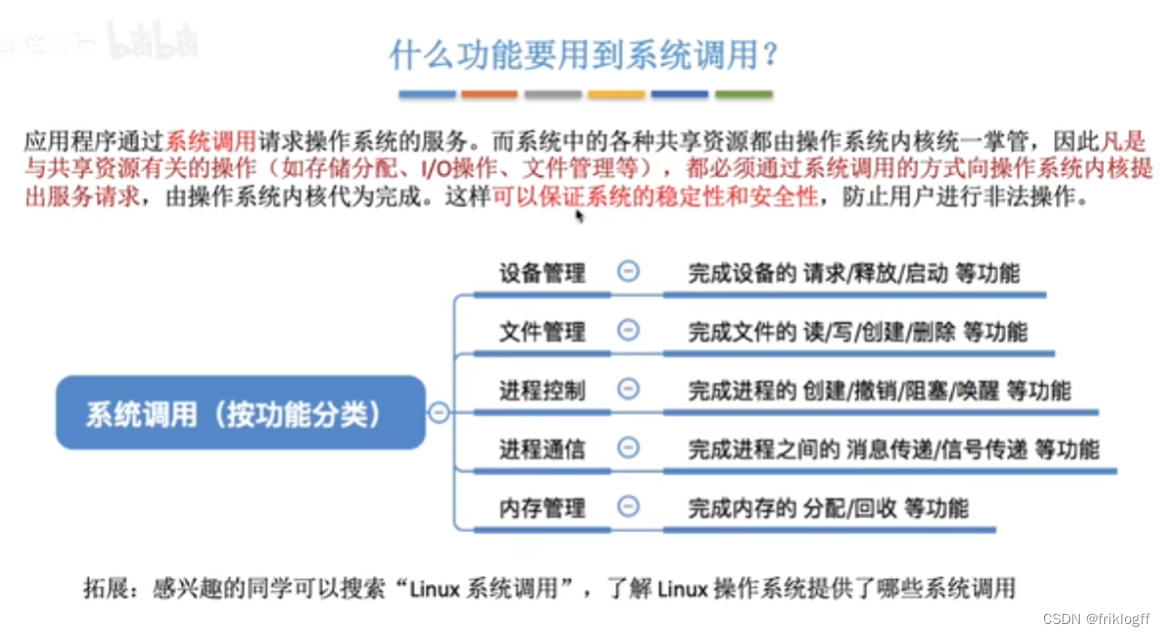
系统调用的过程
系统调用思维导图
操作系统历史
哈工大分两条线讲
-
IBSYS
-
OS/360
-
MULTICS
-
UNIX
-
LINUS
-
System
-
Mac OS
- iOS
-
-
-
-
-
-
CP/M
-
QDOS
-
MS-DOS
- WINDOWS
-
-
王道版本
操作系统(OS)发展阶段
-
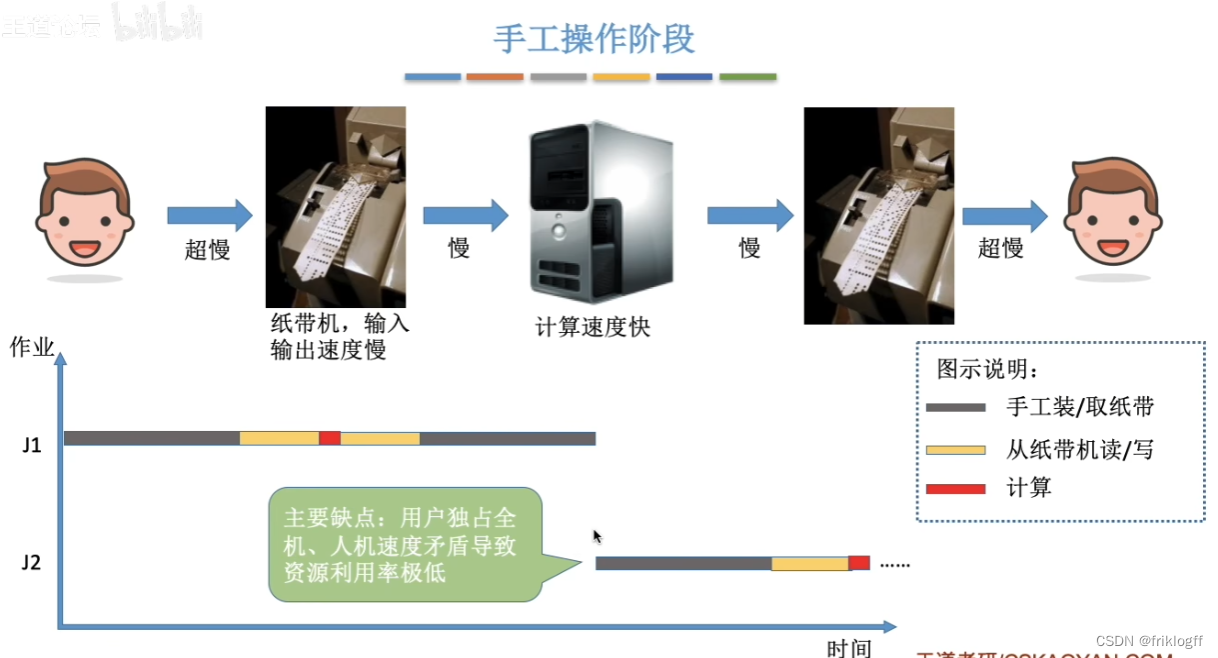
手工操作阶段
-
单道批处理阶段
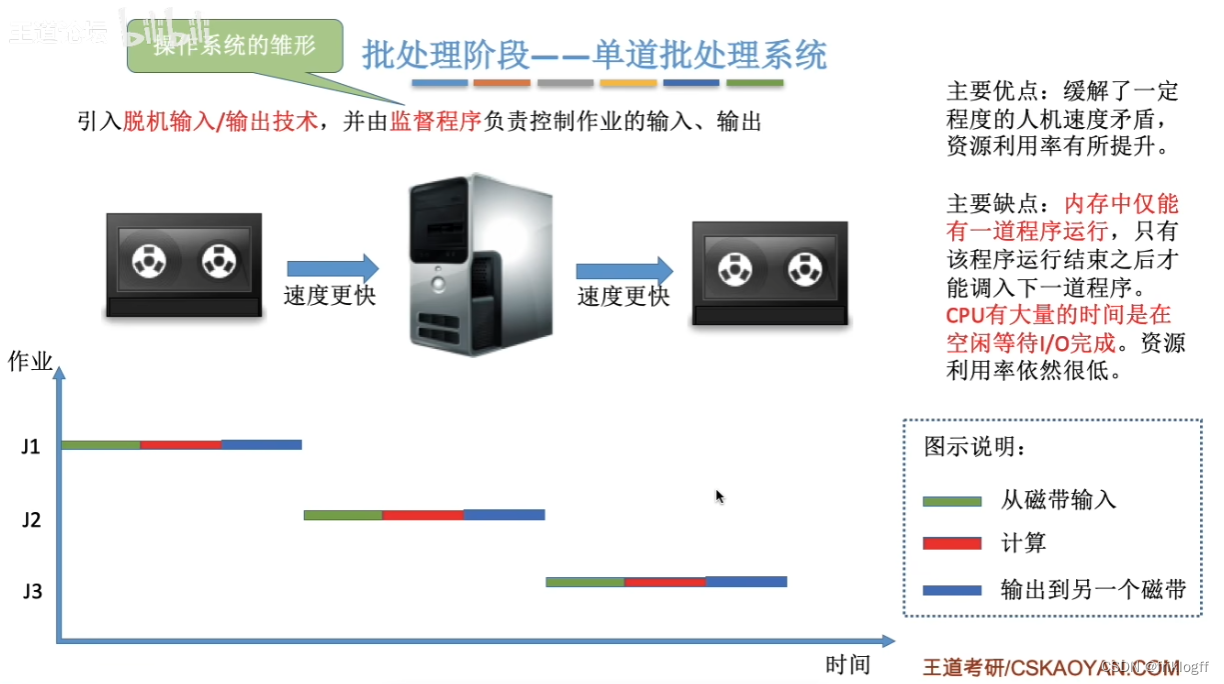
-
多道批处理系统
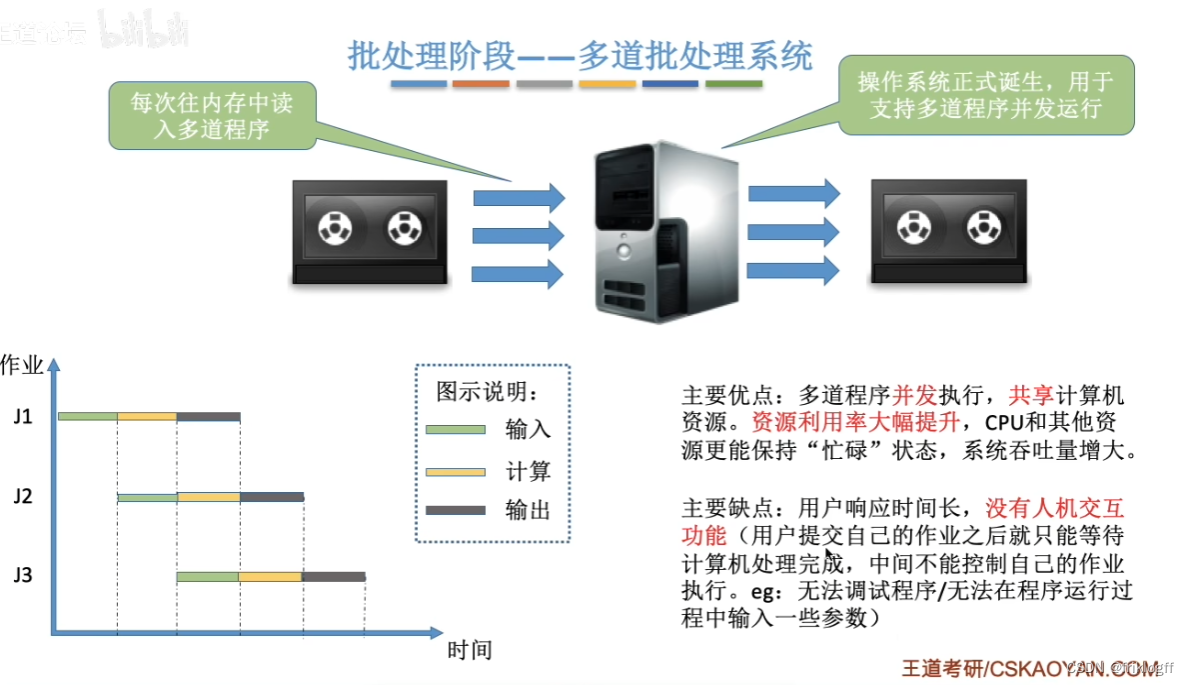
-
分时操作系统
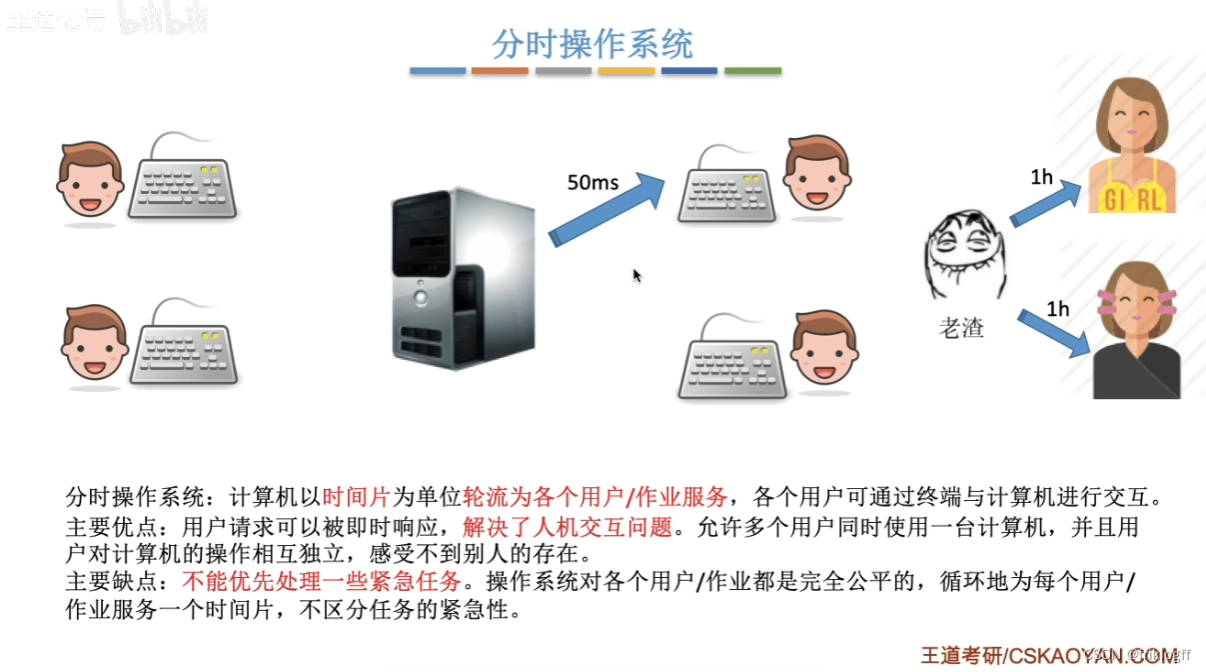
-
实时操作系统
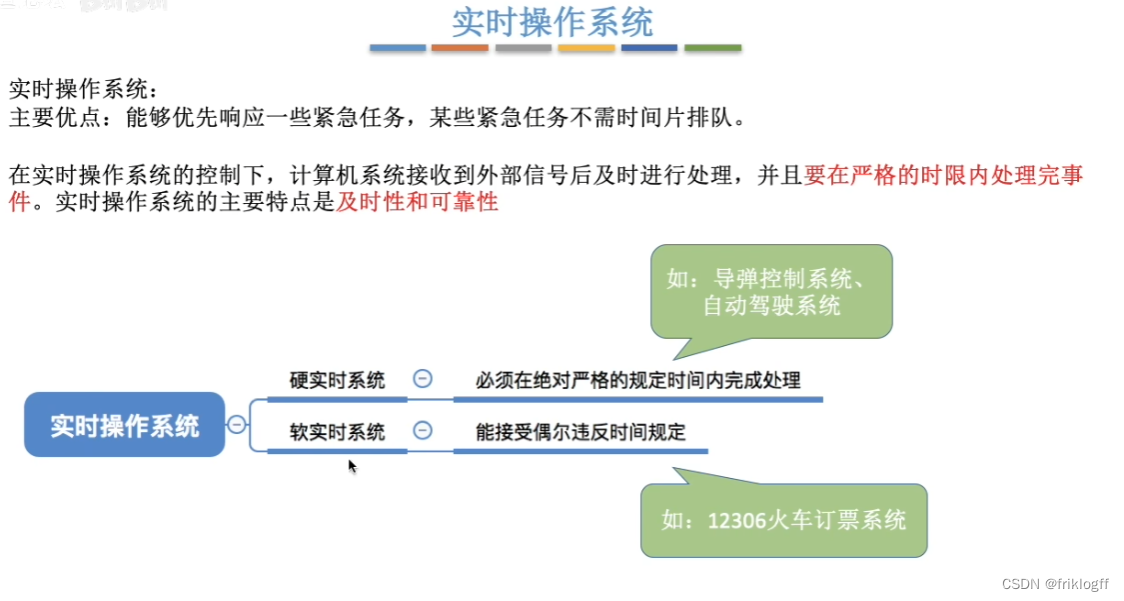
-
网络操作系统
-
分布式计算机系统
-
个人计算机操作系统
- 微型计算机操作系统

- 微型计算机操作系统
-
-
-
-
-
-
-
OS的发展与分类思维导图
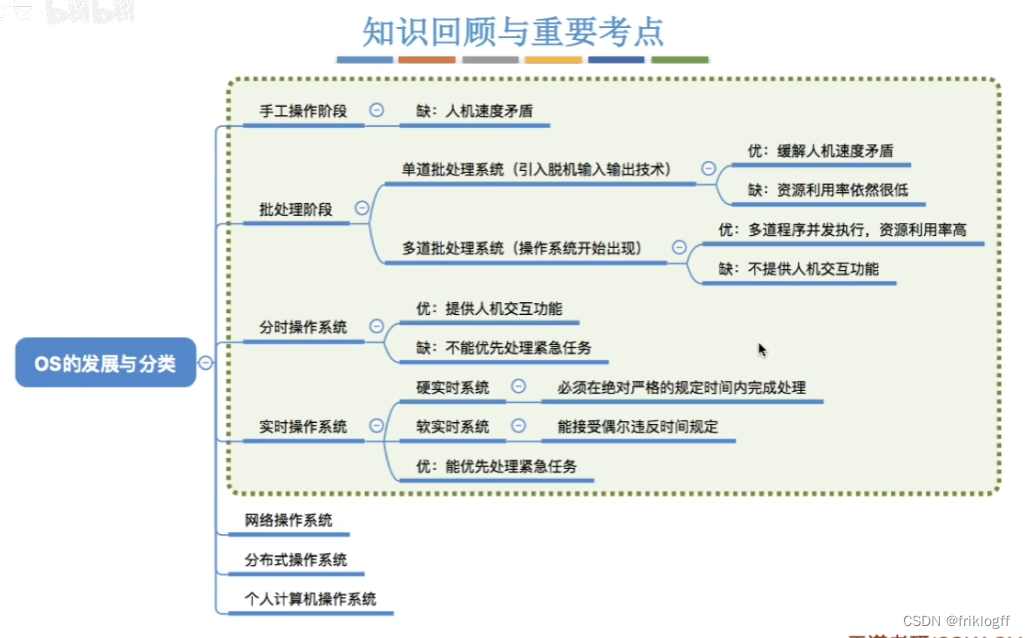
-
所有工作需要人工干预
-
自动性:作业自动执行
-
操作系统出现
-
交互性强
-
抢占式,优先级高者优先
-
服务于计算机网络,集中式控制方式
- 并行工作,协同完成任务,无主从之分
-
-
-
-
-
-
用户独占全机,资源利用率低
-
顺序性:作业依次执行
-
中断技术,无人机交互
- 及时,可靠,交互性不如分时
-
-
-
CPU等待手工操作,利用率低
-
单道性:仅有一道程序执行
-
宏观上并行,微观上串行
- 硬实时系统:飞机控制系统,导弹系统
-
-
软实时系统:订票系统
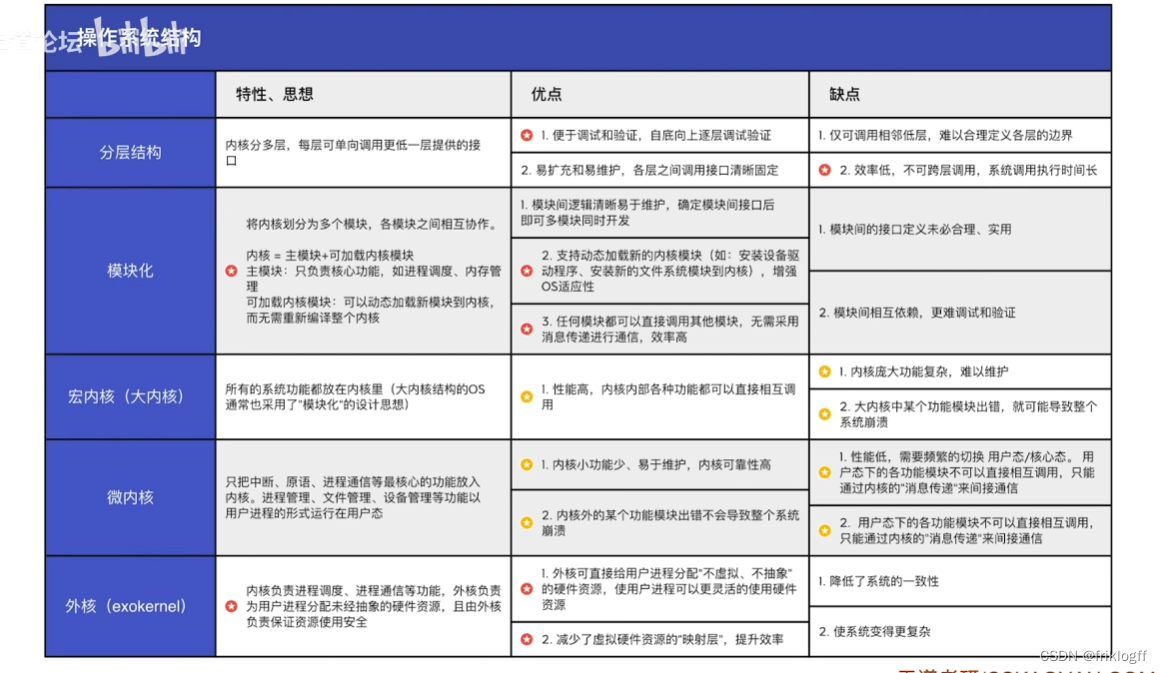
操作系统体系结构(新考点)
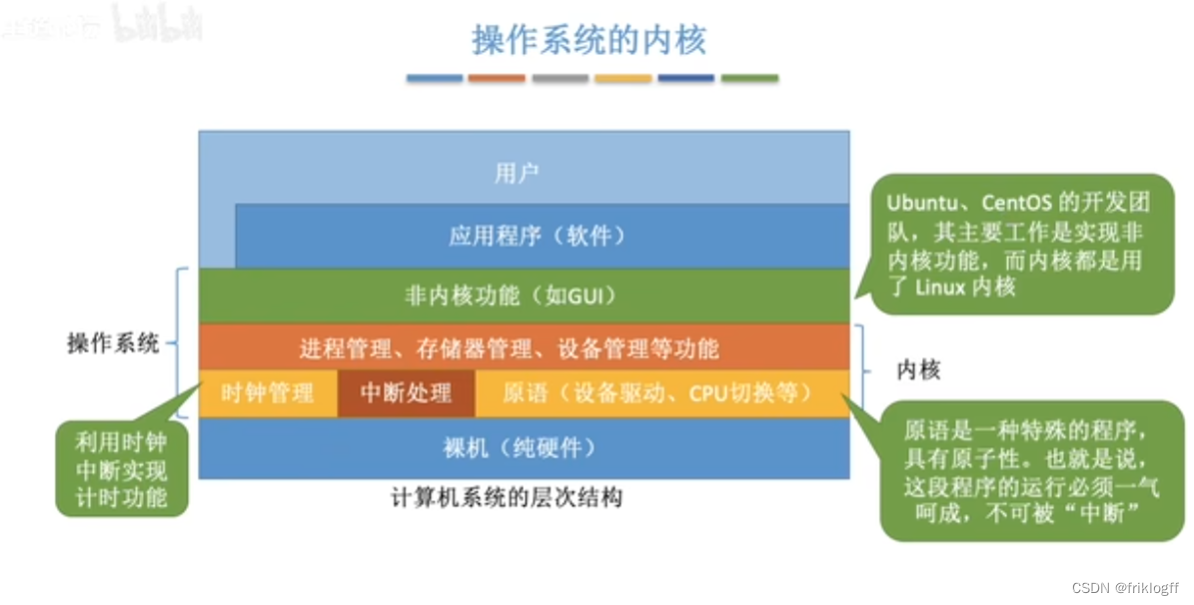
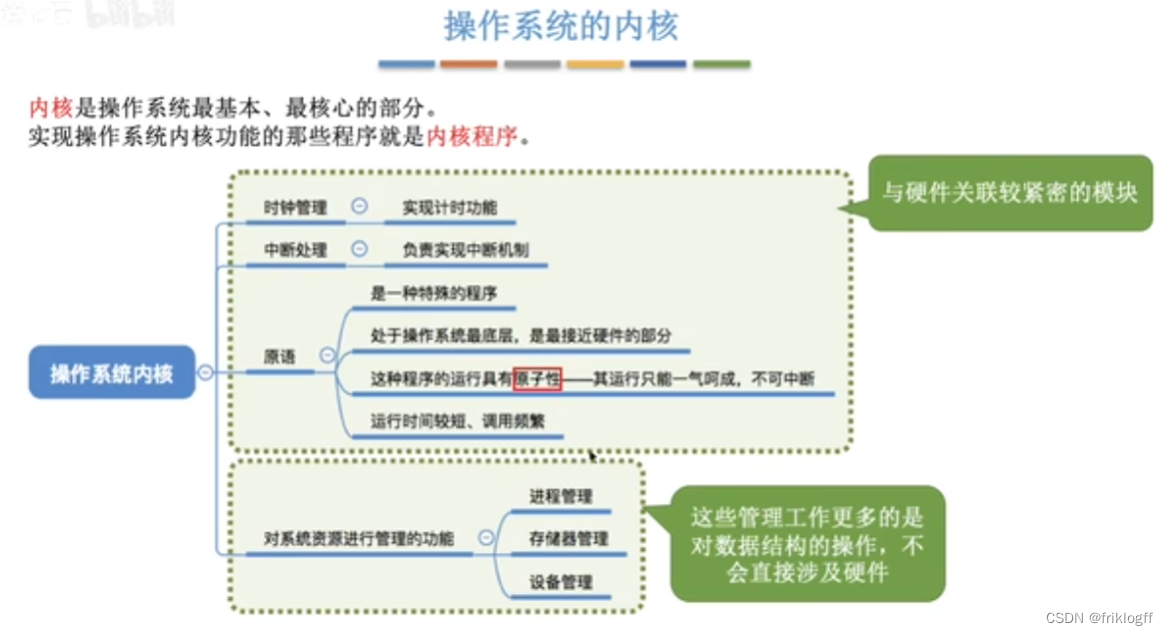
操作系统的内核
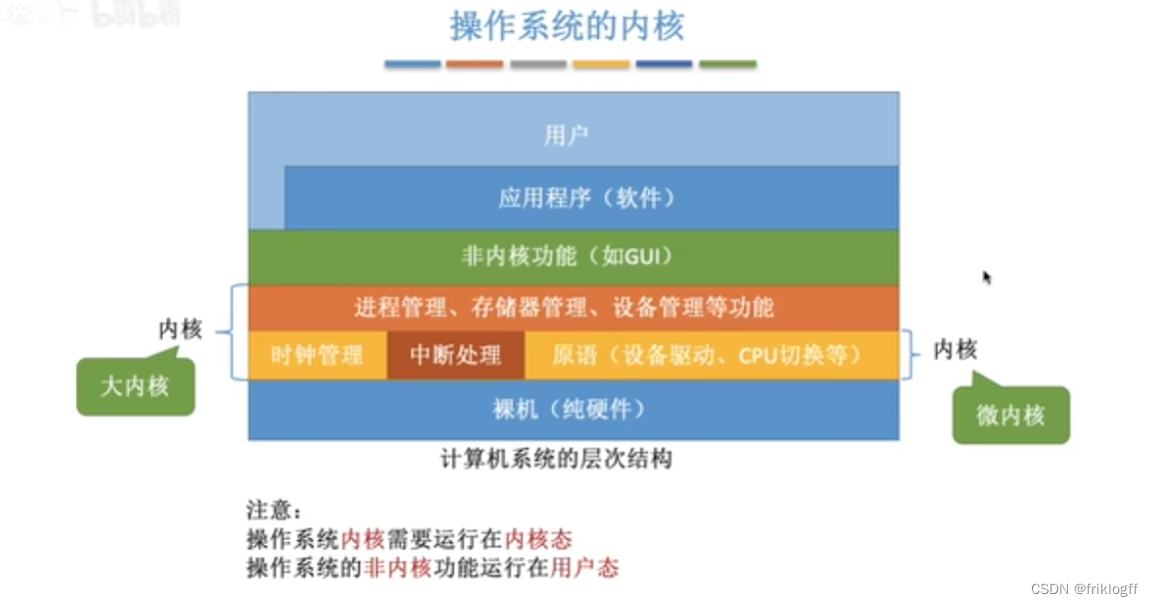
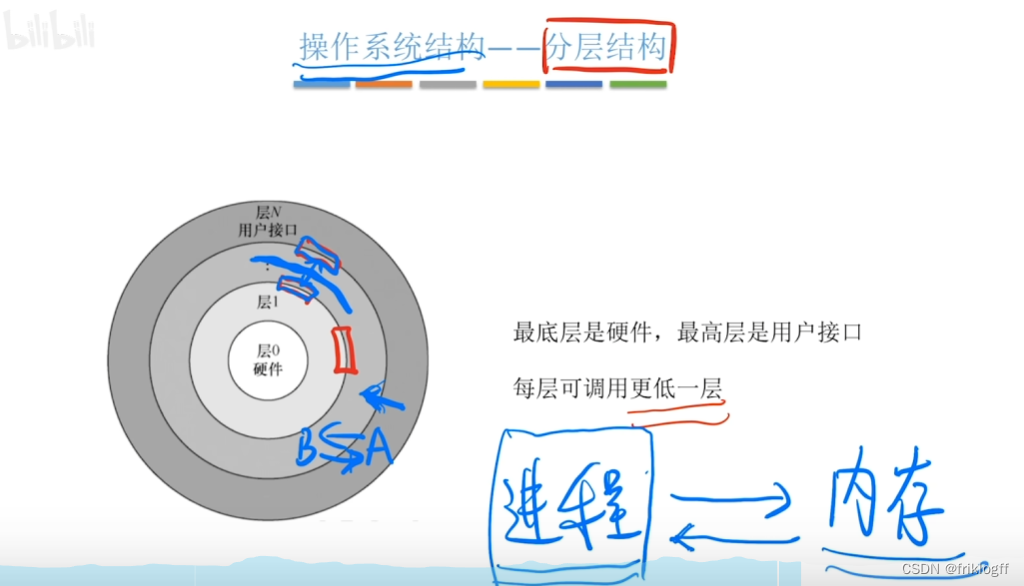
分层结构
-
内核分多层,每层可单向调用更低一层提供的接口
-
便于调试和验证(逐层调试验证),易扩充维护
-
难以定义各层边界,效率低,不可夸层调用
-
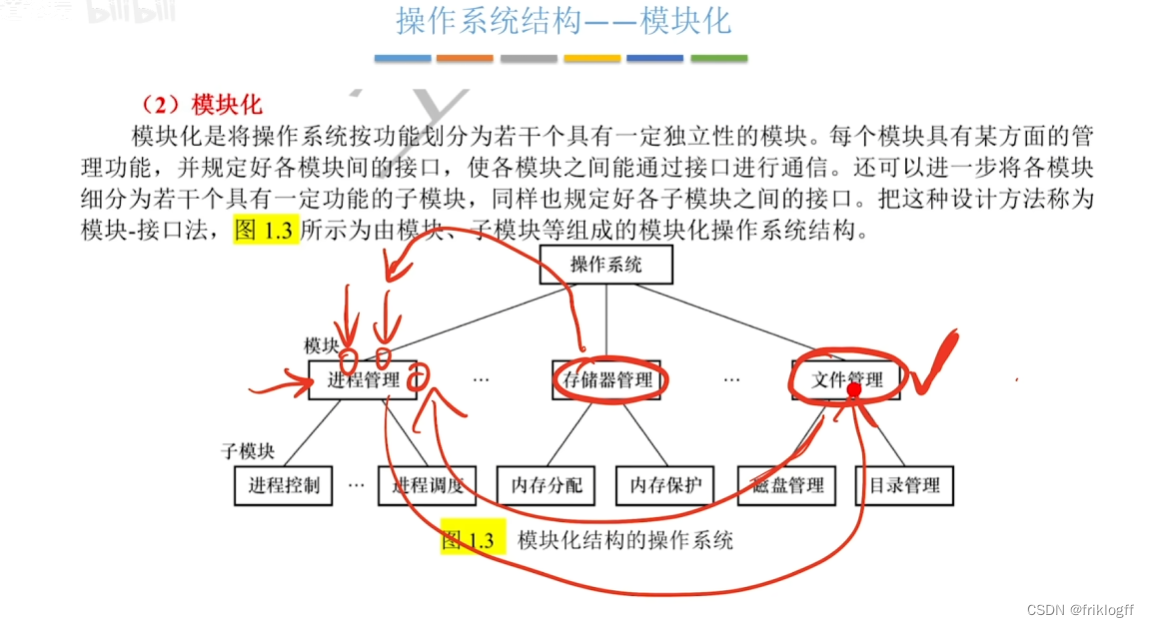
模块化
-
将内核分为多个模块,模块间相互协作,内核=主模块+可加载内核模块
-
易维护,可多模块同时开发;支持动态加载新的内核模块;任何模块可以直接调用其他模块
-
模块间相互依赖,难以调试
-
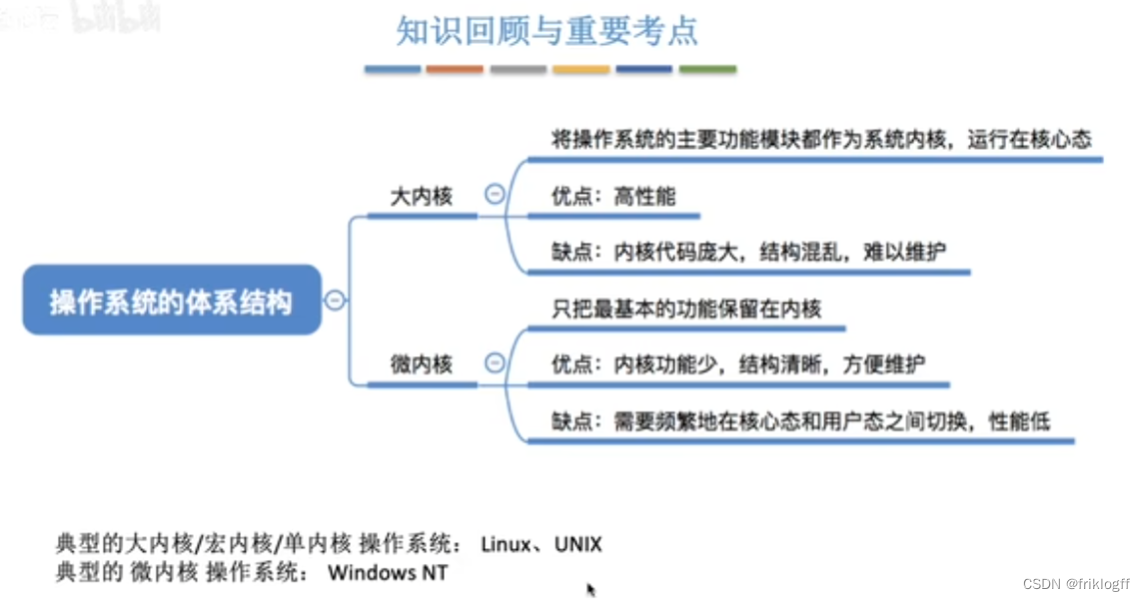
宏内核(大内核)
变态:CPU转态的转换
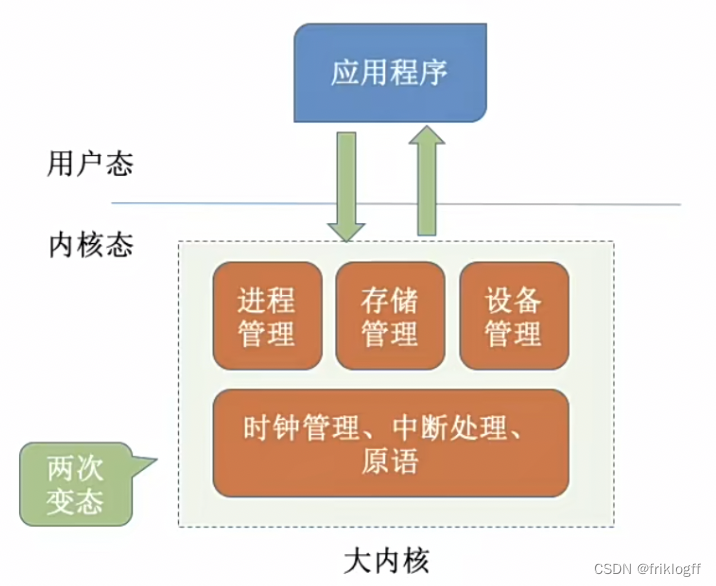
- 所有功能都放在内核中
- 性能高,内核内部功能可以互相直接调用
- 内核功能复杂,难以维护,内核某个功能模块出错,可能导致系统崩溃
微内核

变态:CPU转态的转换
-
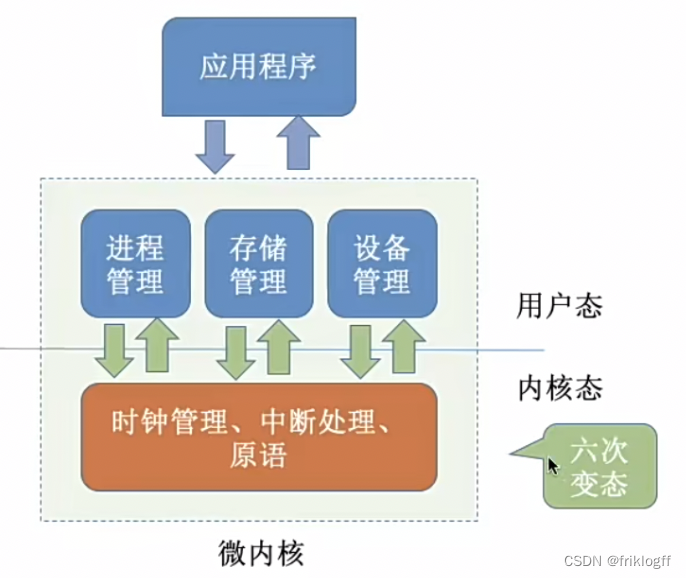
-
只把中断、原语、进程通信等核心功能放入内核。进程管理、文件管理、设备管理等功能以用户进程的形式运行在用户态
-
内核小功能少、易于维护,可靠性高;功能模块崩溃不会导致整个系统崩溃
-
性能低,需要频繁切换用户态/核心态,用户态下各功能模块不可以直接互相调用,只能内核的“消息传递”间接通信
-
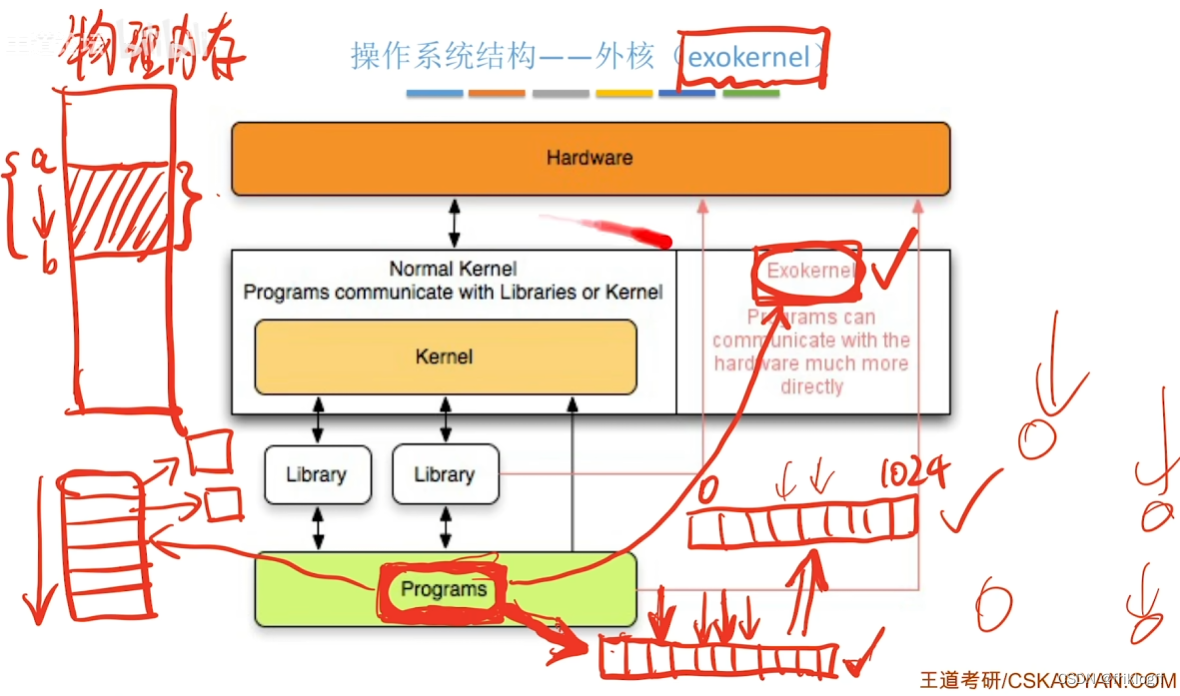
外核
-
内核负责进程调度、进程通信等功能,外盒负责为用户进程安全分配硬件资源
-
外核可直接给用户进程分配“不虚拟、不抽象”的硬件资源
-
减少虚拟硬件资源的“映射层”,提升效率
-
降低了系统一致性,系统复杂
-
虚拟机(新考点)
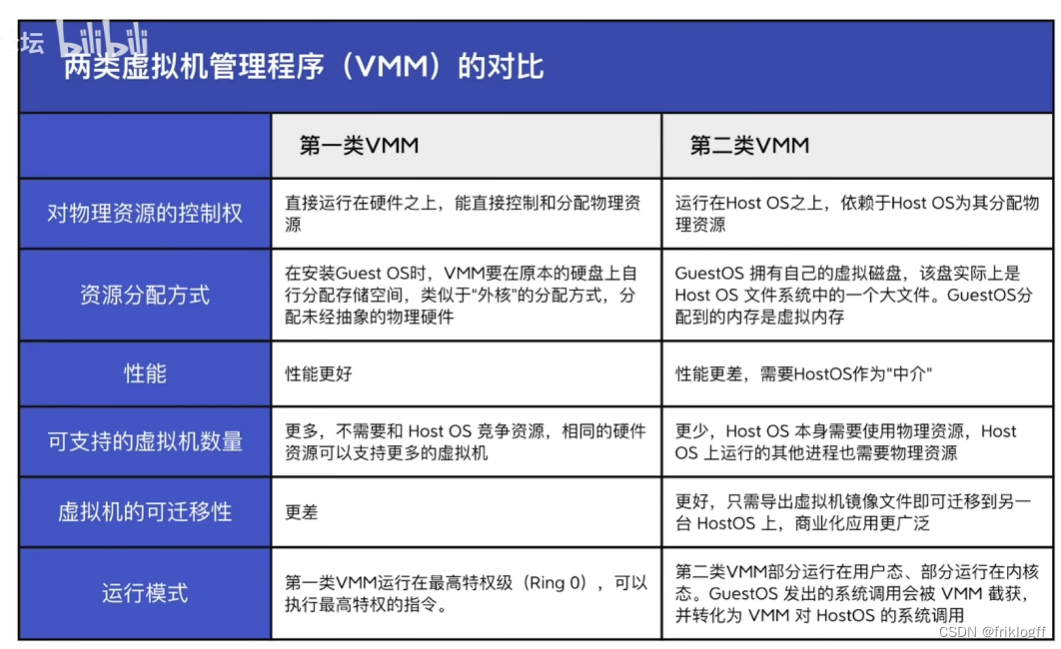
第一类VMM
-
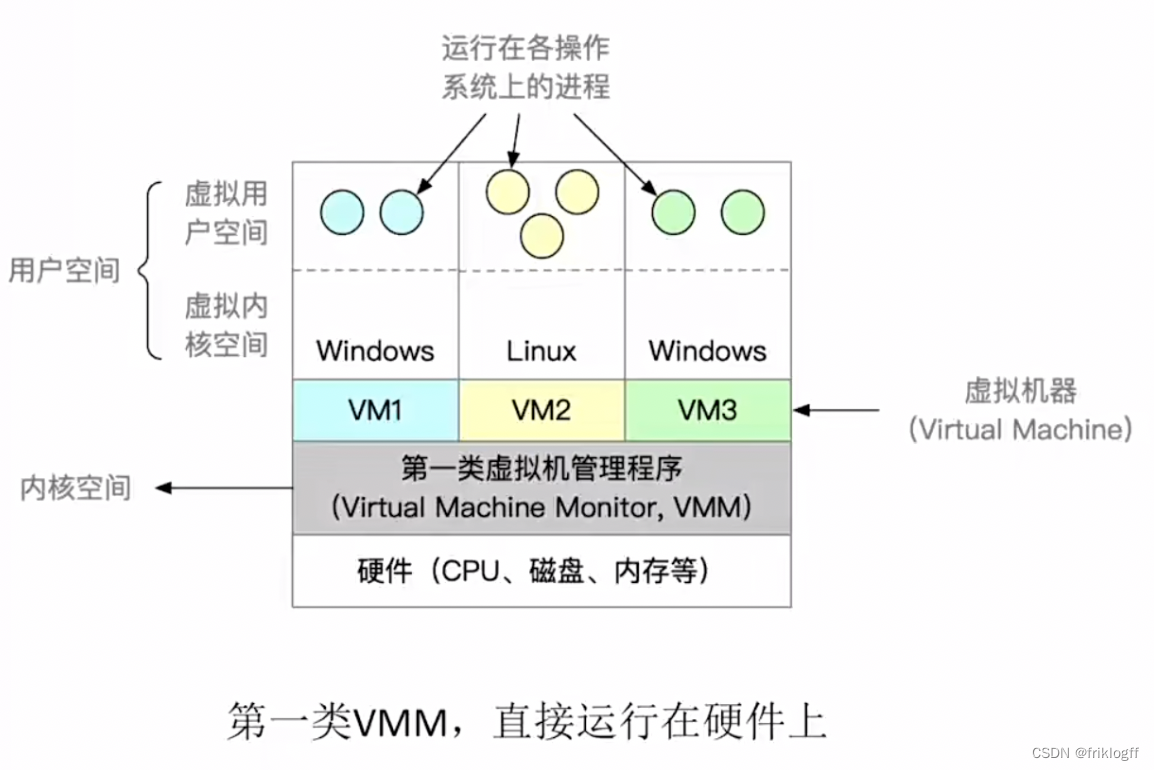
-
安装Guset OS时,VMM要在原本的硬盘上自行分配存储空间
-
性能更好,可迁移性更差
-
第一类VMM运行在最高特权级,可以执行最高特权指令
-
第二类VMM
-
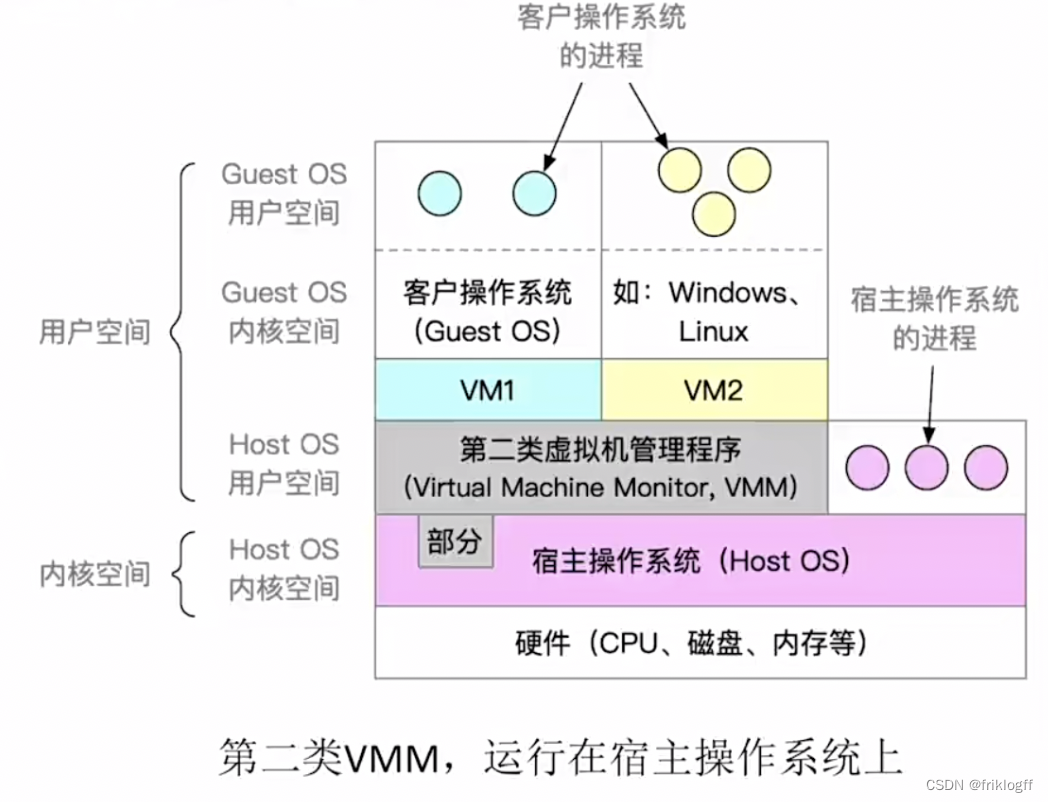
-
拥有自己的虚拟磁盘,实际上上Host OS文件系统中的一个大文件,分配到的是虚拟内存
-
性能差,需要Host OS为中介
-
第二类VMM部分运行在用户态,部分运行在内核态。Guest OS发出系统调用会被VMM截获,转化为VMM对Host OS的系统调用
-
考研真题
408 - 2023
12. 计算程序执行速度和用户CPU时间
若机器M的主频为1.5 Hz,在M上执行程序P的指令条数为5 × 10^5,P的平均CPI为1.2,则P在M上的指令执行速度和用户CPU时间分别为哪个选项?
A. 0.8 GIPS, 0.4 ms
B. 0.8 GIPS, 0.4 us
C. 1.25 GIPS, 0.4 ms
D. 1.25 GIPS, 0.4 us
基础知识
在理解和解析这个问题之前,需要了解以下基础知识:
-
主频(Clock Frequency):主频是计算机处理器(CPU)的时钟频率,通常以赫兹(Hz)为单位表示。它表示CPU每秒钟的时钟周期数。例如,如果主频为1.5 Hz,那么CPU每秒钟将执行1.5亿个时钟周期。
-
指令执行速度(IPS,Instructions Per Second):指令执行速度是计算机在单位时间内执行的指令数。它通常以GIPS(Giga Instructions Per Second)为单位表示。计算指令执行速度需要考虑主频和每条指令的平均CPI(Cycles Per Instruction)。
-
指令条数:指令条数是程序中包含的机器指令的数量。这是一个影响程序执行时间的因素。
-
用户CPU时间:用户CPU时间是指程序在CPU上执行的实际时间,通常以毫秒(ms)为单位表示。它取决于总时钟周期数和主频。
解析:
首先,我们需要计算程序P在机器M上的指令执行速度和用户CPU时间。以下是计算过程:
- 程序P的指令条数为5 × 10^5。
- P的平均CPI为1.2。
- 机器M的主频为1.5 Hz。
计算程序P的总时钟周期数:
总时钟周期数 = 指令条数 × 平均CPI = 5 × 10^5 × 1.2 = 6 × 10^5
机器M的主频为1.5 Hz,这意味着每秒有1.5 × 10^9 个时钟周期。
现在,计算指令执行速度(IPS,Instructions Per Second):
指令执行速度 = 主频 / 平均CPI = (1.5 × 10^9) / 1.2 = 1.25 × 10^9 IPS = 1.25 GIPS
最后,计算用户CPU时间:
用户CPU时间 = 总时钟周期数 / 主频 = (6 × 10^5) / (1.5 × 10^9) = 0.4 × 10^(-3) 秒 = 0.4 ms
所以,程序P在机器M上的指令执行速度为1.25 GIPS,用户CPU时间为0.4毫秒(ms)。因此,答案是选项C:1.25 GIPS, 0.4 ms。
408 - 2022
12. 计算平均CPI和CPU执行时间
问题: 某计算机主频为1GHz,程序P运行过程中,共执行了10000条指令,其中,80%的指令执行平均需1个时钟周期,20%的指令执行平均需10个时钟周期。程序P的平均CPI(Cycles Per Instruction)和CPU执行时间分别是多少?
A. 2.8,28μs
B. 28,28μs
C. 2.8,28ms
D. 28,28ms
解答:
基础知识:
-
CPI(Cycles Per Instruction): CPI 表示每条指令执行所需的平均时钟周期数。它是衡量计算机性能的一个重要指标。公式为:
[CPI = \frac{\text{总时钟周期数}}{\text{执行的指令数}}]
-
CPU执行时间: CPU执行时间表示程序运行所需的时间,通常以秒为单位。
按照题意,程序P的指令总数为10000,其中80%的指令CPI为1,20%的指令CPI为10。首先计算平均CPI:
平均CPI = (80% × 1 + 20% × 10) = 2.8
计算机主频为1GHz,即1 × 10^9 Hz。现在可以计算CPU执行时间:
CPU执行时间 = 10000 × 2.8 / (1 × 10^9) = 28μs
所以,程序P的平均CPI是2.8,CPU执行时间是28μs。
正确答案是 A. 2.8,28μs。
20. 高级语言程序转换为可执行目标文件的过程
问题: 将高级语言源程序转换为可执行目标文件的主要过程是什么?
A. 预处理→编译→汇编→链接
B. 预处理→汇编→编译→链接
C. 预处理→编译→链接→汇编
D. 预处理→汇编→链接→编译
解答:
基础知识:
将高级语言源程序转换为可执行目标文件的主要过程通常包括以下步骤:
-
预处理(Preprocessing): 在这个阶段,预处理器根据预处理指令(如宏定义、条件编译等)对源代码进行处理。预处理器会展开宏定义、包含头文件等,生成经过预处理的源代码。
-
编译(Compilation): 在这个阶段,编译器将预处理后的源代码转换为汇编代码。编译器对代码进行词法分析、语法分析、语义分析,生成相应的中间代码或汇编代码。
-
汇编(Assembly): 在这个阶段,汇编器将汇编代码转换为机器码指令。汇编器将汇编代码中的每条指令翻译成机器码表示。
-
链接(Linking): 在这个阶段,链接器将各个源文件编译生成的目标文件及所需的库文件合并在一起,生成最终的可执行目标文件。链接器会解析符号引用关系,将函数和变量的引用与其定义进行匹配,并进行地址重定位等操作,使得程序能够正确地执行。
因此,正确的过程是:预处理→编译→汇编→链接,选项A是正确的。
答案是 A. 预处理→编译→汇编→链接。
拓展
例如gcc编译器将hello.c转换为可执行目标文件hello的过程如下:
对应的命令如下:
预处理:gcc -E hello.c -o hello.i
编译:gcc –S hello.i –o hello.s
汇编:gcc –c hello.s –o hello.o
链接:gcc hello.o –o hello
408 - 2021
12. 计算机浮点运算速度与操作次数的关系
问题:2017 年公布的全球超级计算机 TOP 500 排名中,我国“神威·太湖之光”超级计算机蝉联第一,其浮点运算速度为93.0146 PFLOPS,说明该计算机每秒钟内完成的浮点操作次数约为?
A. 9.3×10^13次
B. 9.3×10^15次
C. 9.3 千万亿次
D. 9.3 亿亿次
答案:D
基础知识:
PFLOPS(PetaFLOPS)表示每秒钟完成的浮点操作次数达到了10^15次。根据题目中提供的数据,神威·太湖之光超级计算机的浮点运算速度为93.0146 PFLOPS~每秒9.3×10次浮点运算,因此每秒钟完成的浮点操作次数约为9.3×10^16次。






![[java/力扣110]平衡二叉树——优化前后的两种方法](https://img-blog.csdnimg.cn/ac5f043c9c894051bb5062d8f5c8ee8d.png)


![[2021]不确定成本下的处理分配](https://img-blog.csdnimg.cn/540d6cbac2c64788b427c5b56d1dc5b2.png)