PostGreSQL手册的简史部分介绍到:被称为PostGreSQL的对象关系型数据库管理系统,由美国加州大学伯克利 分校编写的POSTGRES软件包发展而来。经过十几年的发展,PostGreSQL目前是世界上最先进的开源数据库。
The object-relational database management system now known as PostgreSQL is derived from the POSTGRES package written at the University of California at Berkeley. With decades of development behind it, PostgreSQL is now the most advanced open-source database available anywhere.
不同于传统的关系型数据库,对象关系型数据库(ORDBMS),是面向对象技术与传统关系数据库结合的产物。它基于面向对象编程(OOP)的基本思想,将所有的实体都看成是对象,通过深入分析对象之间的继承、关联关系,将对象进行封装,转换成数据表,并提供了一种“表继承”的机制,来帮助数据库设计者更方便的完成数据库的设计。
表继承
案例引入
假设:目前要为一个城市city建立数据模型,而城市分为两类:省会城市和非省会城市;要求能够快速检索任何特定省份的省会城市。
我们当然可以创建一张表,并使用一个额外的字段来标识这个城市是否为该省份的省会,但问题在于会造成严重的数据冗余。因为:34个省份中,非首都城市的数量要远远大于首都城市的数量。
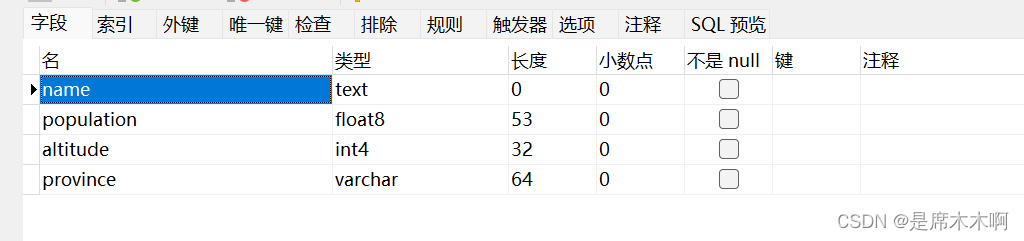
CREATE TABLE cities (
name text,
population float,
altitude int -− in feet,
province_id int,
is_capital boolean
);于是我们尝试创建两张表,一个用来存储省会城市,另一个用来存储非省会城市的数据(PS:)。但是又会提升维护的复杂度,因为两张表的结构相同,但是却定义了两次,从数据库设计者的角度来讲,这种情况是极其糟心的。
CREATE TABLE cities (
name text,
population float,
altitude int -− in feet,
province_id int,
);
CREATE TABLE capitals (
name text,
population float,
altitude int -− in feet,
province_id int
) INHERITS (cities);表继承
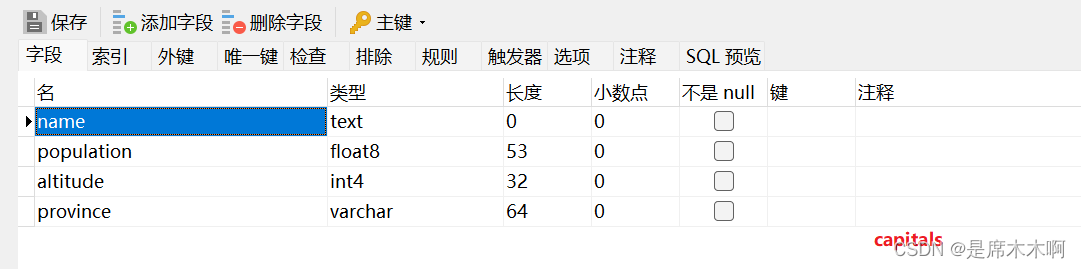
有没有一种折中的办法,就像Java中的面向对象机制-继承特性一样,来减少重复字段的定义呢?答案是有的:因为PostgreSQL实现了表继承,这对数据库设计者来说是一种有用的工具。像下面这样,
---创建数据表
CREATE TABLE myschema.cities (
name text,
population float,
altitude int,
province varchar(64)
);
--创建继承子表
CREATE TABLE myschema.capitals (
) INHERITS (myschema.cities); 在这种情况下,capitals表继承了它的父表cities的所有列。我们只需要将所有的省会城市存储到capitals中,而不用考虑其它的问题,因为继承特性帮助我们完成了表结构的复用。
如何查询被继承的表
在PostgreSQL中,一个表可以从0个或者多个其他表继承,而对一个表的查询则可以引用一个表的所有行或者该表的所有行加上它所有的后代表。默认情况是后一种。
我们分别向cities父级表、capitals子级表中添加几条测试数据,
--添加数据
INSERT INTO myschema.cities(name,population,altitude,province)
VALUES ('洛阳',125,500,'河南省'),
('平顶山',100,600,'河南省'),
('焦作',180,550,'河南省')
---为继承子表添加数据
INSERT INTO myschema.capitals(name,population,altitude,province)
VALUES ('郑州市',125,500,'河南省')
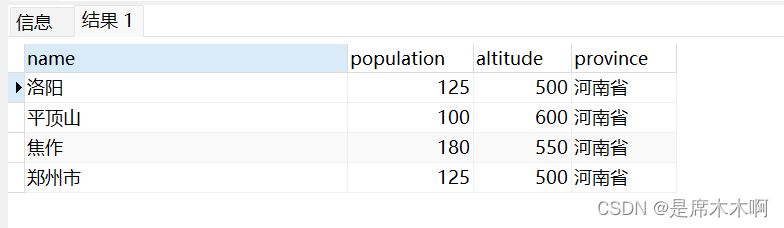
SELECT name,population,altitude,province FROM myschema.cities查询结果默认包含:父级表和继承子表中的所有记录,

上面的查询操作等同于:
SELECT name,population,altitude,province
FROM myschema.cities*其中: *显式指定包括所有后代表,这也是PG数据库的默认行为。
如何仅查询父级表
PostGreSQL数据库提供了ONLY关键字,用于:表明该查询应该只针对cities父级表,而不包括其后代。
PS:其它命令(SELECT, UPDATE 和 DELETE)都支持ONLY关键字。
SELECT name,population,altitude,province FROM ONLY myschema.cities如下所示,这次的查询结果仅仅是cities中的记录,

如何判断结果行属于哪一张表
现在,我们可能存在疑惑:假如我们查询了一张父级表,那么,我们如何知晓结果中的每一行来自于父级表还是子级表呢?
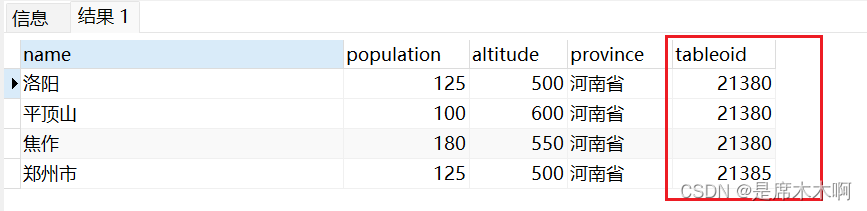
PostGreSQL数据库的设计者显然也考虑到了这个问题:在每个表里我们都有一个tableoid 系统属性可以告诉你源表是谁,
SELECT name,population,altitude,province,tableoid
FROM myschema.cities*查询结果如下,
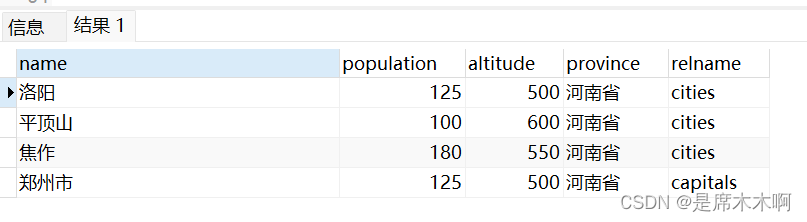
通过tableoid字段,我们可以对记录进行分类。那么如何通过tableoid字段拿到具体的表名称呢?只需要通过和pg_class做一个连接,就可以看到实际的表名字
--和pg_class表做连接查询
SELECT name,population,altitude,province,pg_class.relname
FROM myschema.cities* LEFT JOIN pg_class
ON pg_class.oid = myschema.cities.tableoid
其它使用细节
①所有父表的检查约束和非空约束都会自动被所有子表继承。 不过其它类型的约束(唯一、主键、外键约束)不会被继承。
②一个子表可以从多个父表继承,这种情况下它将拥有所有父表字段的总和, 并且子表中定义的字段也会加入其中。
③任何存在子表的父表都不能被删除,同样,子表中任何从父表继承的字段或约束也不能被删除或修改。 如果你想删除一个表及其所有后代,最简单的办法是使用CASCADE选项删除父表。