一、
auto关键字
1.自动识别数据类型
2.auto的初始化
3.auto简化for循环
nullptr的使用
二、类与对象
1.c++中类的定义
2.c语言与c++的比较
3.类的访问限定符以及封装
3.1访问限定符
3.2封装
3.3类的作用域
3.4类的声明与定义分离
🗡CSDN主页:d1ff1cult.🗡
🗡代码云仓库:d1ff1cult.🗡
🗡文章栏目:数据结构专栏🗡
一、
auto关键字
auto的意义:类型名字较长时使用auto来定义比较方便
1.自动识别数据类型
auto关键字可以自动识别数据的类型,我们可以是typeid()name.()函数来查看一个数据的类型
int main()
{
int a = 0;
int b = a;
auto c = a;
auto d = &a;
auto* e = &a;
int& f = a;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
cout << typeid(f).name() << endl;
return 0;
}下面是运行结果
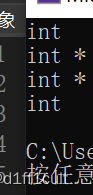
typeid().name()函数可以输出一个数据的类型,我们auto c=a;a是int类型的,那么auto出来的c也是int类型的,auto d=&a,那么这个d的数据类型就是int *。
上面只是auto用法的一个小小小小小的用法。
2.auto的初始化
auto初始化时必须在右边给个值进行初始化,不然auto无法识别数据的类型
auto=x; //对auoto错误的初始化
auto x=1.0;
auto x=1.22;需要注意的是auto不能作为函数的参数,也不能作为一个函数的返回值,与此同时auto也不能用来声明数组
3.auto简化for循环
int main()
{
int array[] = { 1,2,3,4,5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
{
array[i] *= 2;
}
for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)
{
cout << *p << endl;
}
for (auto e : array)
{
cout << e << "";
}
cout << endl;
return 0;
}auto在这里的作用:依次取数组中的数字赋值给e,并且自动判断结束,自动++往后走。
auto简化for循环时 auto e中的e只是数组内容的一份临时拷贝,对e进行操作不会修改数组中的值,如下
int main()
{
for (auto e : array)
{
e++;
cout << e << "";
}
cout << endl;
for (auto e : array)
{
cout << e << "";
}
cout << endl;
return 0;
}
如果想要通过修改e来对数组内容进行修改,可以使用 引用
int main()
{
for (auto &e : array)
{
e++;
cout << e << "";
}
cout << endl;
for (auto e : array)
{
cout << e << "";
}
cout << endl;
return 0;
}eg:c语言为了效率,数组是不能够传参的,一般是使用数组的首元素的地址进行传参的。
nullptr的使用
c语言中的NULL本质上是一个宏定义,#define NULL 0
在c++中 为了弥补这一缺陷,使用了nullptr来替换NULL
二、类与对象
1.c++中类的定义
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号class 为定义类的关键字,ClassName 为类的名字,{} 中为类的主体,注意类定义结束时后面分 号不能省略。
类体中内容称为类的成员:类中的变量称为类的属性或成员变量; 类中的函数称为类的方法或者成员函数。
类的两种定义方式:
1.声明和定义全部放在类体中,需注意:成员函数如果在类中定义,编译器可能会将其当成内联函数处理
//定义一个人
class People
{
public:
void show()
{
cout << _name << "-" << _sex << "-" << _age << endl;
}
public:
char* _name; //姓名
char* _sex; //性别
int _age; //年龄
};2,类声明放在 .h 文件中,成员函数定义放在 .cpp 文件中,注意:成员函数名前需要加类名:: 以此来进入对应的域中
People.h
//人
class People
{
public:
void show();
public:
char* _name; //姓名
char* _sex; //性别
int _age; //年龄
};
People.cpp
void Person::show()
{
cout << _name << "-" << _sex << "-" << _age << endl;
}2.c语言与c++的比较
c++向下兼容所有c语言struct所有的用法
struct同时升级成了类
1、类名就是类型,Stack就是类型,不需要加struct
2、函数的定义都放在了类中
下面这一段是c语言对栈进行初始化
//C语言
struct Stack
{
int* a;
int top;
int capacity;
};
void StackInit(struct Stack* ps);
void StackPush(struct Stack* ps, int x);下面是c++的一段
class Stack
{
private:
int* a;
int top;
int capacity;
public:
void Init()
{
a = 0;
top = 0;
capacity = 0;
}
void Push(int x)
{
//...
}
bool Empty()
{
return top == 0;
}
};
同样都是对栈进行声明以及初始化,但其实c++是比较方便简单的,例如Push()函数,c语言是不支持重名函数的,但是在c++中不同的域中函数的作用不同,我们可以通过调用不同的域中的函数来实现不同的功能
3.类的访问限定符以及封装
3.1访问限定符
C++实现封装的方式: 用类将对象的属性与方法结合在一块,让对象更加完善,通过访问权限选择性的将其接口提供给外部的用户使用。
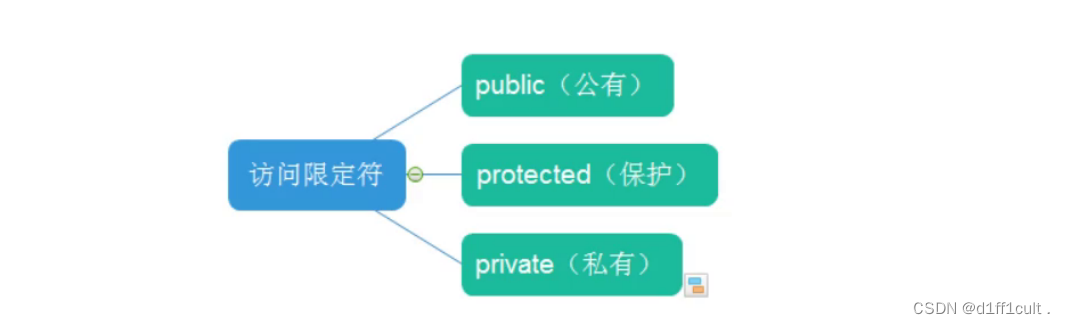
1.public修饰的成员在类外可以直接被访问
2. protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)3.访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
4.如果后面没有访问限定符,作用域就到 },即类结束
5.class的默认访问权限为private,struct为public(因为struct要兼容C)
这里有一道关于struct和class的面试题:
C++ 中 struct 和 class 的区别是什么?
C++ 需要兼容 C语言,所以C++中struct可以当成结构体使用;
另外C++中struct还可以用来定义类。和class定义类是一样的,区别是struct定义的类默认访问权限是public,class定义的 默认访问权限是private;
3.2封装
封装可以隐藏实现细节,使得代码模块化,使代码和功能独立- 封装是把函数和数据包围起来,对数据的访问只能通过可信任的对象和类进行访问,对不可信的进行信息隐藏。
- 封装本质上是一种管理,让用户更方便使用类。
3.3类的作用域
类定义了一个新的作用域,类的所有成员都在类的作用域中在类体外定义成员时,需要使用 :: 作用域操作符指明成员属于哪个类域。
class Person
{
public:
void PrintPersonInfo();
private:
char _name[20];
char _gender[3];
int _age;
};
// 这里需要指定PrintPersonInfo是属于Person这个类域
void Person::PrintPersonInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}访问时如果不加作用域操作符号,编译器就不知道应该调用哪一个域内的函数。
c++中花括号定义的都是域
3.4类的声明与定义分离
类中成员函数可以在类中直接进行声明与定义同时也可以将声明和定义分开,例如下面
在类中定义时,由于我们已经在对应的域中,所以我们不需要使用::访问,若我们将成员函数的声明与定义分离之后,定义的时候就需要加上这样使用:void Stack::Init(),因为我们不知道这个Init函数究竟是哪一个类中的成员,所以我们需要使用::来限制它的域
//Stack.h文件
class Stack
{
private:
int* a;
int top;
int capacity;
public:
void Init();
void Push(int x);
bool Empty();
};
//Stack.cpp文件
void Stack::Init()
{
a = 0;
top = 0;
capacity = 0;
}
void Stack::Push(int x)
{
//....
}在类中定义的函数默认就是inline,正确的定义方法应该是,长的函数的定义和声明分离,短小的可以直接在类里面定义
3.5成员变量命名规则
class Date
{
public:
void Init(int year)
{
year = year;
}
private:
string year;
};
int main()
{
return 0;
}看到这个函数我们不免发出疑问,调用Init的这个函数中 两个year,哪一个是成员变量,哪一个是函数的形参,这样的写法使得阅读代码的人一个头两个大。所以我们可以在成员变量前加上一个下划线来区分形参和成员变量
class Date
{
public:
void Init(int year)
{
_year = year;
}
private:
int _year;
};3.6内存对齐规则
1,第一个成员在与结构体偏移量为 0 的地址处。
2,其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
注意:对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的对齐数为8
3,结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍
4,如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体 的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
3.7类中对象的存储方式

存储方式:保留成员变量,成员函数存放在公共的代码段
类的大小,根据内存对齐规则可以求得
需要注意的是:一个类的大小就是通过内存对齐规则后求得的大小,特殊的是我们要注意空类的大小,空类比较特殊,编译器给了空类一个字节来唯一标识这个类的对象。
class Date
{
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
//private:
// 声明
int _year;
int _month;
int _day;
};
class A
{
private:
char _ch;
int _a;
};
class B
{};
class C
{
public:
void f()
{};
};
int main()
{
Date d1;
Date d2;
Date d3;
cout << sizeof(d1) << endl;
cout << sizeof(A) << endl;
B b1;
B b2;
cout << sizeof(B) << endl;
cout << sizeof(C) << endl;
// 无成员变量的类,对象大小开一个字节,这个字节不存储有效数据
// 标识定义的对象存在过
return 0;
} 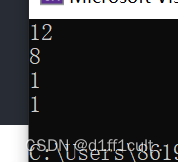
类B与类C的大小都是1。
3.8 this指针
我们先来看下面这样一段代码
class Date
{
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year; // 年
int _month; // 月
int _day; // 日
};
int main()
{
Date d1, d2;
d1.Init(2022, 1, 11);
d2.Init(2023, 1, 12);
d1.Print();
d2.Print();
return 0;
} 
d1.Print()没有传参数,为什么还能打印出d1的内容呢,这一切都要归功于this指针
C++ 编译器给每个“非静态的成员函数“增加了一个隐藏的指针参数,让该指针指向当前对象(函数运行时调用该函数的对象),在函数体中所有“成员变量” 的操作,都是通过该指针去访问。只不过所有的操作对用户是透明的,即用户不需要来传递,编译器自动完成。
3.9this指针的一些性质
1.this指针的类型是const *类型,不能写this相关的实参和形参,不能给this指针赋值
2.只能在成员函数内部使用
3.this指针能在类中显示调用
4.this指针是个形参,存储在栈帧上,不是存储在对象中的